Intel announces a major enhancement for distributed training in PyTorch 2.8: the native integration of the XCCL backend for Intel® GPUs (Intel® XPU devices). This provides support for Intel® oneAPI Collective Communications Library (oneCCL) directly into PyTorch, giving developers a seamless, out-of-the-box experience to scale AI workloads on Intel hardware.
Seamless Distributed Training on Intel® GPUs
Prior to this release, PyTorch lacked a built-in method for distributed training on Intel GPUs, preventing users from taking full advantage of advanced features. The introduction of the native XCCL backend in PyTorch 2.8 closes this gap. The integration of XCCL followed a transparent, community-driven process guided by a public RFC to ensure the design aligned with PyTorch’s core principles of usability and reliability.
This integration was essential to:
- Provide a Seamless User Experience: For most developers, distributed training on Intel GPUs now simply works, mirroring the straightforward experience on other hardware. This removes previous barriers to entry and simplifies workflows.
- Guarantee Feature Parity: Ensure that state-of-the-art PyTorch features, such as Fully Sharded Data Parallelism v2 (FSDP2), work seamlessly on Intel hardware.
- Future-Proof the Ecosystem: Allow Intel hardware to benefit immediately from all future distributed advancements in PyTorch.
How to Use the XCCL Backend
The primary goal of this feature was to provide a distributed API for users on XPU devices that is straightforward and consistent with existing backends like NCCL and Gloo. To ensure reliability, a major effort was undertaken to restructure tests to be backend-agnostic, resulting in a high unit test pass rate for XCCL.
Using the new backend is straightforward. To explicitly initialize the process group with XCCL, you can specify it as the backend.
# No extra imports needed! import torch import torch.distributed as dist # Check if the XPU device and XCCL are available if torch.xpu.is_available() and dist.is_xccl_available(): # Initialize with the native 'xccl' backend dist.init_process_group(backend='xccl', ...)
For an even smoother experience, PyTorch 2.8 automatically selects XCCL as the default backend when running on Intel XPU devices.
# On XPU devices, PyTorch 2.8 will automatically activate the XCCL backend dist.init_process_group(...)
Proven Success with XCCL
The impact of native XCCL support on PyTorch has been both immediate and significant.
Seamless Ecosystem Integration: TorchTitan
Frameworks built on PyTorch now work on Intel GPUs with few modifications, if any. For example, TorchTitan, a platform for large-scale training of generative AI models, functions seamlessly and out-of-the-box with the XCCL backend. Using TorchTitan, we successfully pre-trained Llama3 models using advanced multi-dimensional parallelism (FSDP2 with Tensor Parallelism) on XPU devices. The models demonstrated excellent convergence and scaled to 2K ranks, matching the competition.
Argonne National Laboratory: AI for Science using the Aurora Supercomputer
The Aurora exascale supercomputer at the U.S. Department of Energy’s (DOE) Argonne National Laboratory as of June 2025, came in second place on the HPL-MxP benchmark for AI performance [1,2]. It features 10,624 compute nodes, with each node hosting six Intel GPUs.
As part of our ongoing collaboration with Argonne, we leveraged PyTorch’s native large-scale distributed training capabilities to enable scientists to use Aurora for tackling today’s most challenging problems, from climate modeling and drug discovery to cosmology and fundamental physics.
Case Study 1: CosmicTagger Model
We enabled the XCCL backend for the CosmicTagger model, a U-Net-based segmentation model used to analyze neutrino data. The results were outstanding:
- The model achieved 99% scaling efficiency for scale-up (multiple devices within a single node) distributed training using Distributed Data Parallel (DDP).
- It reached convergence with about 78% accuracy, on average, using test datasets for both Float32 and BFloat16 precisions.
- The model achieved almost 92% scaling efficiency for scale-out (multiple devices across multiple nodes) distributed training up to 2,048 Aurora nodes (24,576 ranks) for FP32-precision weak-scaling runs (see Figure 1).

Figure 1: Scale-out efficiency results for CosmicTagger model up to 2,048 Aurora nodes (24,576 ranks).
* Scaling efficiency measures how well performance scales in distributed training. Scaling efficiency for scale-up configuration is calculated as throughput per rank using several ranks for training within a node, normalized with respect to the lowest throughput rank using the same number but independently executing ranks in parallel. Scaling efficiency for scale-out multi-node training is calculated as per-rank throughput using several nodes normalized with respect to the per-rank throughput using a single node.
Case Study 2: LQCD-su3-4d Model
The LQCD-su3-4d model is used in high-fidelity physics simulations to solve the quantum chromodynamics (QCD) theory of quarks and gluons. We enabled the XCCL backend for this model with PyTorch’s DDP and successfully trained it on up to 2,048 Aurora nodes (24,576 ranks) for FP64 precision, achieving over 89% scale-out efficiency for weak-scaling runs (see Figure 2).

Figure 2: Scale-out efficiency results for LQCD-su3-4d model up to 2,048 Aurora nodes (24,576 ranks).
Case Study 3: Llama3 Model Pre-training
To support Argonne’s ambitious AuroraGPT project [3], we have started pre-training Large Language Models on Aurora using TorchTitan. Figure 3 shows a convergence study for a Llama3-8B model using FSDP2 with the XCCL backend running on a single Aurora node (12 ranks), demonstrating stable training and successful checkpointing.
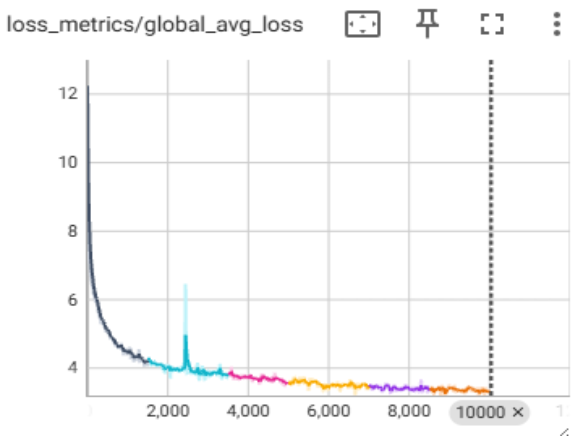
Figure 3: Llama3-8b convergence study on a single Aurora node.
Case Study 4: Scaling Llama3 8B Pre-training to 2K ranks
Llama 3 8B model pre-training was scaled to 2K ranks on the C4 dataset using multi-dimensional parallelism available in TorchTitan (see Figure 4). The hyper-parameters and model available in TorchTitan were used without any change. TP was used within the nodes, and FSDP across the nodes.
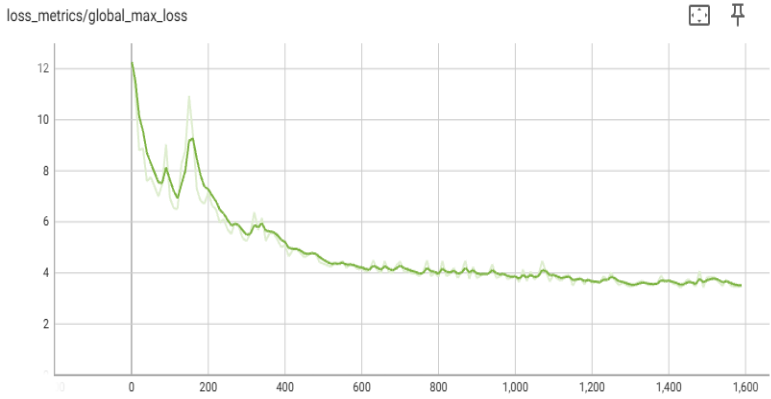
Figure 4: Llama3-8b convergence study on 2K ranks on Aurora.
Get Started Today!
Native XCCL support is available now in PyTorch 2.8. Update your environment and take your distributed training on Intel hardware to the next level.
Please note: In PyTorch 2.8, native XCCL support is available for Intel® Data Center GPUs on Linux systems.
For more details, check out the official documentation:
- PyTorch Distributed Overview: https://pytorch.org/docs/stable/distributed.html
- is_xccl_available check: https://pytorch.org/docs/stable/distributed.html#torch.distributed.distributed_c10d.is_xccl_available
References:
[1] Aurora supercomputer at Argonne National Laboratory: https://www.anl.gov/aurora
[2] HPL-MxP benchmark results: https://hpl-mxp.org/results.md
[3] AuroraGPT project at Argonne National Laboratory: https://auroragpt.anl.gov/
Performance varies by use, configuration, and other factors. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.