Introduction
As the demand for diverse hardware accelerators grows, the need for a robust and adaptable deep learning framework becomes increasingly critical. While working through this integration, several challenges have surfaced in the PyTorch ecosystem, potentially affecting various hardware vendors. This blog aims to highlight these issues and propose solutions to enhance PyTorch’s adaptability, portability, and resilience across different hardware platforms.
Improve Users’ Code Portability via Accelerator Autoloading
Currently, users face additional work when running their code on different accelerators. One such task is manually importing modules for out-of-tree devices. This requires users to not only understand the different usage patterns between accelerators but also make their code aware of these differences. If you have projects originally running on GPU/CPU and want to migrate to other accelerators, this can lead to significant work and potential frustration.
Examples of extra import:
# Case 1: Use HPU
import torch
import torchvision.models as models
import habana_frameworks.torch # <-- extra import
model = models.resnet50().eval().to("hpu")
input = torch.rand(128, 3, 224, 224).to("hpu")
output = model(input)
# Case 2: Use torch_npu
import torch
import torch_npu # <-- extra import
print(torch.ones(1, 2, device='npu'))
As a high-level machine learning framework, PyTorch’s ability to shield users from device differences is a competitive feature. Accelerator Autoloading allows users to continue using the familiar PyTorch device programming model without explicitly loading or importing device-specific extensions.
How does it works?
Utilize Python’s plugin architecture to enable automatic loading of device extensions via entry points in the PyTorch package.
Python entry points provide a standardized way for Python packages to expose and discover components or plugins within an application. Via definition in accelerator’s package setup.py , PyTorch can automatically initialize accelerator modules when calling import torch , which gives users consistent experience between different backend devices.
From device perspective, only need to claim following setup in setup.py (as example of torch_npu )
// setup.py
entry_points={
'torch.backends': ['torch_npu = torch_npu:_autoload', ],
}
When import torch is invoked, the accelerator module will be loaded automatically. This provides users with a consistent programming experience across out-of-tree devices, eliminating the need to be aware of differences between CUDA, HPU, and NPU.
# Case 1: Use HPU
import torch
import torchvision.models as models
model = models.resnet50().eval().to("hpu")
input = torch.rand(128, 3, 224, 224).to("hpu")
output = model(input)
# Case 2: Use torch_npu
import torch
print(torch.ones(1, 2, device='npu'))
Device Integration Optimization
What is PrivateUse1?
In PyTorch, the dispatcher is a crucial component of the framework’s backend that manages how operations are routed to the appropriate device-specific implementation. Dispatch keys are an integral part of this system, serving as identifiers that represent various execution contexts—such as the device (CPU, CUDA, XPU), layout (dense, sparse), and autograd functionality. These keys ensure that operations are directed to the correct implementation.
PrivateUse1 is a customizable device dispatch key, similar to CUDA/CPU/XPU, etc.), reserved for out-of-tree devices. It provides developers with a way to extend PyTorch’s functionality without modifying the core framework, allowing for the integration of new devices, hardware accelerators, or other specialized computing environments.
Why do we need PrivateUse1?
Internally, dispatch keys are represented as bit masks, each bit represents whether a certain key is active. This bit mask representation is efficient for quick lookup and combination of keys, but it inherently limits the number of distinct keys (typically to 64 or fewer).
The current implementation of BackendComponent dispatch keys in PyTorch has encountered a critical bottleneck, which restricts the addition of new backends and, as a result, limits the expansion of the PyTorch ecosystem.
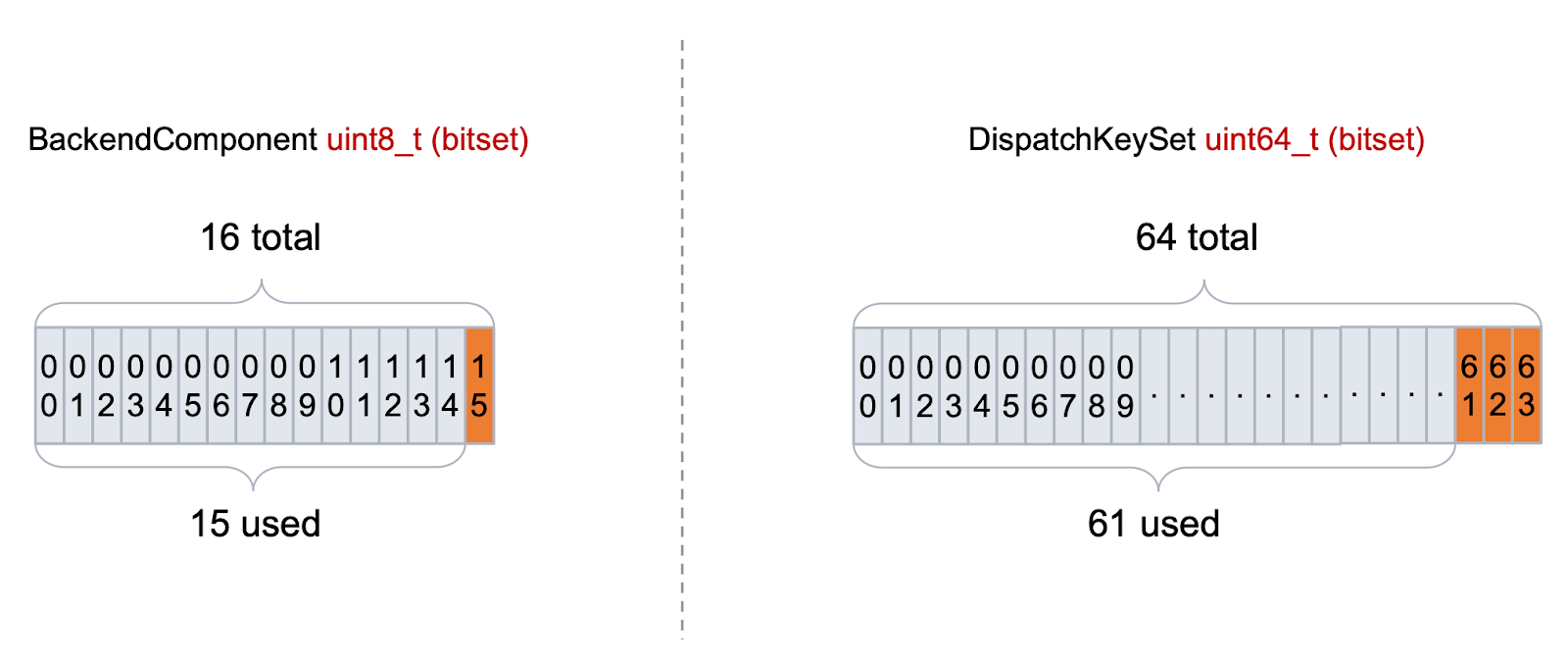
In response to this challenge, a series of optimizations have been applied to the PrivateUse1 mechanism to enhance its capacity.
- PrivateUse1 integration mechanismInitially reserved as fallback options, PrivateUse1, along with PrivateUse2 and PrivateUse3, were designed to be activated only when existing key resources became scarce.PrivateUse1 is now being developed to match the robustness and versatility of established keys like CUDA and CPU. Achieving this required a deep integration across critical PyTorch modules. This integration wasn’t just a simple switch—it involved significant updates to core components such as AMP (Automatic Mixed Precision), Autograd, Distributed Training, Checkpointing, DataLoader, Optimization, and Quantization, etc.
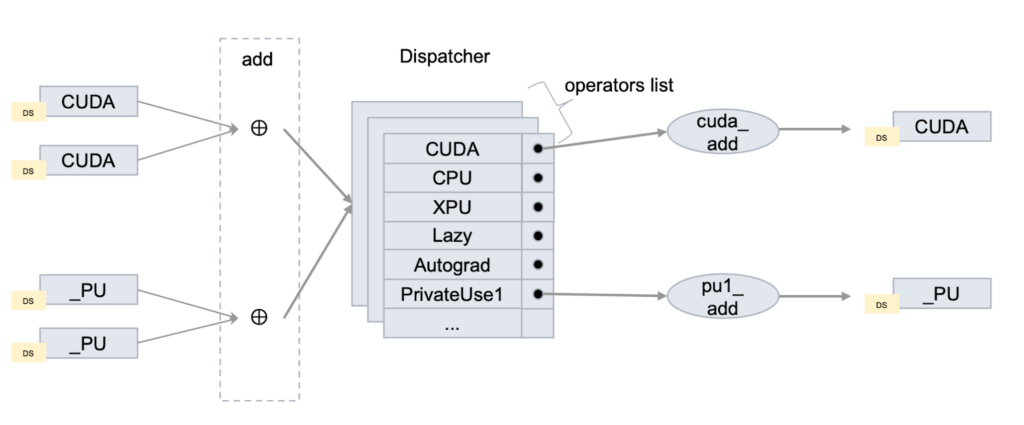
The activation of PrivateUse1 was a massive collaborative effort, culminating in over 100 pull requests aimed at making it from a placeholder to a fully operational dispatch key.
- PrivateUse1 UT/CI Quality AssuranceWhile unit tests are essential for ensuring quality during the development of the PrivateUse1 mechanism, they are not sufficient on their own to prevent new pull requests from inadvertently affecting existing functionality or compatibility of out-of-tree devices.To mitigate this risk, the community has added the
pytorch_openregmodule to the test suite. This module leverages a CPU backend to simulate interactions with accelerators, creating a controlled environment for rigorous testing. After implemented, this will enable automatic execution of device-generic test cases whenever relevant code is updated, allowing us to quickly detect and address any potential issues affecting the PrivateUse1 integration mechanism. - Comprehensive DocumentationBy providing comprehensive and easy-to-understand documentation, we aim to lower the barrier to entry for developers and encourage wider adoption of the PrivateUse1 mechanism in the PyTorch ecosystem. This documentation includes:
- Step-by-step guides for integrating new backends using PrivateUse1
- Clear explanations of PrivateUse1’s functionality and benefits
- Code examples and best practices for efficient implementation
These enhancements aim to improve the robustness and reliability of the PrivateUse1 mechanism, facilitating better integration of new backends and expanding the capabilities of PyTorch.
Compatibility Between Upstream and Downstream
Device-Generic Unit Tests
Most unit tests in PyTorch focus on CPU and CUDA devices, which limits participation from users with other hardware. To address this, a plan to modify PyTorch’s unit testing framework, enabling better support for non-CUDA devices. This plan includes removing existing device restrictions, implementing dynamic data type loading, and generalizing decorators to accommodate a broader range of devices. Additionally, we aim to enforce the use of universal device code and expand distributed testing to support non-NCCL backends.
Through these improvements, we hope to significantly increase test coverage and pass rates for non-CUDA devices, integrating them into PyTorch’s continuous integration process. Initial changes have already been implemented, paving the way for new hardware support and creating a reference template for other devices.
Ensuring Robust Device Integration through Automated Testing
To uphold the high standards of quality assurance in PyTorch, an independent build repository and daily continuous integration (CI) workflows have been established, focusing on smoke and integration testing.
The pytorch-integration-tests repository automates the testing of PyTorch’s device-specific functionalities, ensuring that they operate correctly and efficiently across a variety of hardware platforms(NPUs and other specialized devices). In repository we are trying to make a fully automated system that continuously validates PyTorch’s compatibility with different hardware backends.
- Automated Integration Tests: Run automated tests across different devices using GitHub Actions. This automation ensures that every change in the codebase is thoroughly tested against multiple hardware platforms, catching potential issues early in the development process.
- Reusable Workflows: Workflows in this repository are modular and reusable, which streamlines the testing process. Developers can easily adapt these workflows to new devices or testing scenarios, making the system both flexible and scalable as PyTorch evolves.
- Awareness of Out-of-Tree Devices: The repository displays the existence and behavior of all out-of-tree devices, keeping the community informed. This approach minimizes the risk of accidentally breaking downstream functionalities and provides fast feedback on changes.
Efforts to enhance multi-device integration are pivotal for its adaptability in the evolving deep learning landscape. These initiatives not only benefit current users but also lower entry barriers for new hardware vendors and developers, fostering innovation in AI and machine learning. As PyTorch continues to evolve, its commitment to flexibility, robustness, and inclusivity positions it as a leading framework capable of meeting the diverse needs of the deep learning community.