ExecuTorch support for Ethos-U85
In the rapidly evolving landscape of machine learning, PyTorch has emerged as a leading framework for model development, given its flexibility and comprehensive ecosystem. Arm has worked with Meta to introduce support for Arm platforms in ExecuTorch, that further simplifies this process, making it seamless to deploy PyTorch models on edge devices.
The Arm Ethos-U85 NPU is the highest performing Ethos NPU addressing the growing demand for running advanced AI inference workloads at the edge, including transformer-based networks like LLMs. Arm offers reference designs, including the Corstone-320 IoT reference design platform, around the Ethos-U to accelerate and simplify the chip development cycle. The reference design platform includes, among many items, a Fixed Virtual Platform (FVP) that simulates an entire system, enabling cutting edge embedded software development and neural network deployment for the Ethos-U85.
Today, Arm is extending the support for developers building IoT edge applications, by supporting ExecuTorch beta on Ethos-U85. Leveraging ExecuTorch, developers can now efficiently land their natively developed PyTorch models to enable intelligent and responsive IoT solutions built on Arm.
With this package now available, thousands of developers looking to create Edge AI applications, can start their model and application development months before the platforms arrive on the market.
Getting started with ExecuTorch on Ethos-U85
A full development environment has been provided in the public ExecuTorch GitHub repository. This provides an integrated and tested development flow with all necessary components.
The three simple steps are:
- Set up ExecuTorch
- Set up the Arm Build environment
- Compile and Run models on the arm_executor_runner
You can then build on this flow for compiling and running models, to capture runtime behavior from the Ethos-U85 driver, such as cycle count information.
To make the process easier for end users, we have also added scripts to the ExecuTorch repository:
- Set up ExecuTorch
- setup.sh: Download the necessary software.
- run.sh: to compile and run the model on the Corstone-320 FVP
To build other models, you can use the ahead of time compiler script aot_arm_compiler.py, which takes a PyTorch program (nn.module) to an ExecuTorch program (.pte flatbuffer file). To write custom applications which use ExecuTorch you can follow the application flow in the example executor_runner application.
We support approximately 40 core ATen operators and already support end-to-end deployment of models such as Mobilenetv2. Ongoing efforts to support further operators will enable more PyTorch models every week .
As more functionality is added, it will be demonstrated through the tutorial materials for Ethos-U on pytorch.org
How this deployment flow works in more detail
Leveraging the extensibility of ExecuTorch and the expressiveness of Arm’s Tensor Operator Set Architecture (TOSA), we have enabled Ethos-U support in ExecuTorch. The Ethos-U compiler, Vela, has been enhanced with a TOSA front-end, making it possible to compile models for all products in the Ethos-U family. Combining these components into a cohesive workflow involves the following steps.
- Converting a PyTorch model into a deployable ExecuTorch program (AOT flow)
- Compile the ExecuTorch program into an executable, which can be deployed on Corstone-320 (runtime flow)
The ExecuTorch Ahead of time (AOT) flow
The process begins by converting a PyTorch model into a quantized TOSA representation using the PyTorch dynamo export flow. This allows us to generate an Ethos-U set of machine instructions, known as a command stream, utilizing the Vela compiler TOSA frontend. The command stream is bundled into an ExecuTorch program, represented by a flatbuffer file (.pte). This file contains everything the ExecuTorch runtime needs to perform inference using Ethos-U hardware.
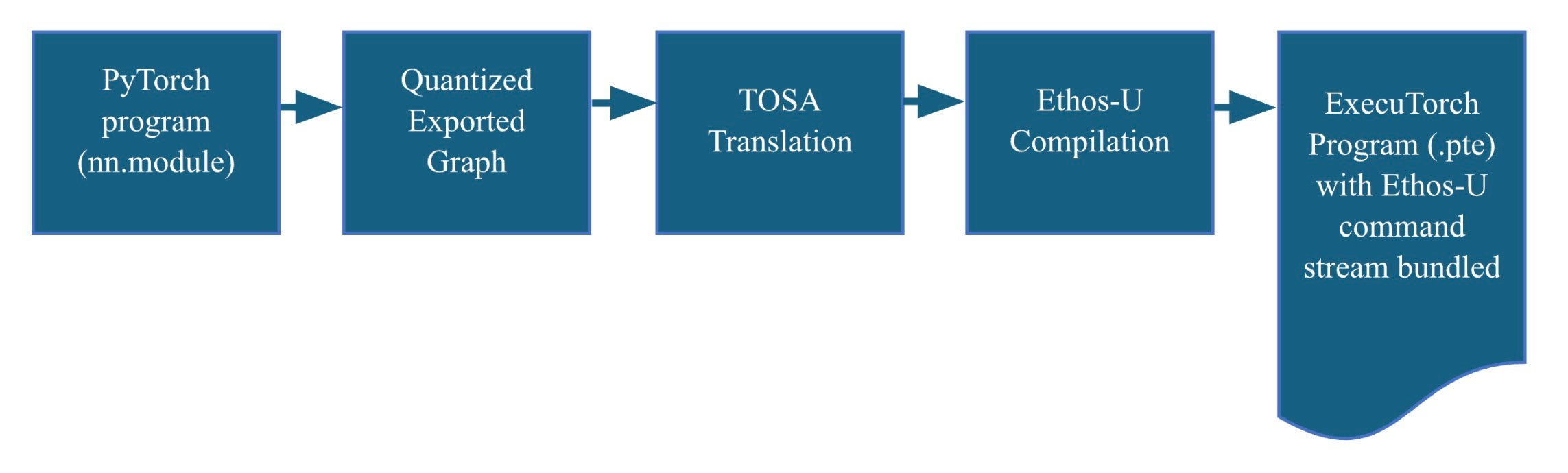
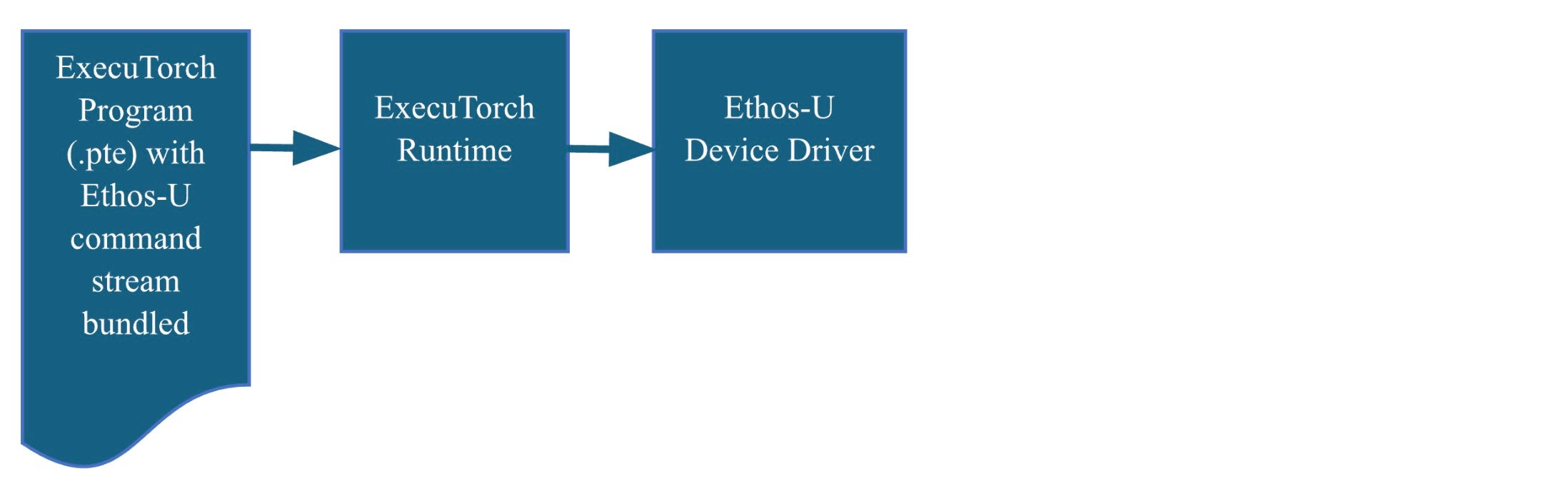
The ExecuTorch Runtime flow
The ExecuTorch runtime, written in C/C++, is designed to support multiple backends. We have extended it to include support for the Ethos-U device driver. Following this flow will produce a self-contained compiled executable. Deploying the executable on the Corstone-320 FVP is straightforward and requires only the appropriate flags when calling the FVP.
Ethos-U85 and Corstone-320
The Ethos-U family of NPUs offers high performance and energy-efficient solutions for edge AI. The Ethos-U55 (also supported by ExecuTorch) is widely deployed in many Cortex-M heterogeneous systems, while the Ethos-U65 extends the applicability of the Ethos-U family to Cortex-A-based systems and increases the performance.
Ethos-U85 further extends the Ethos-U product line, supporting current and future workloads on the edge using transformer-based networks. Ethos-U85 delivers a 4x performance uplift and 20% higher energy efficiency compared to its predecessor, with up to 85% utilization on popular networks. Notable feature of Ethos-U85 includes;
- configurations from 128 to 2048 MACs/cycle, delivering up 4 TOP/s at 1GHz
- Compatible with Cortex-A and Cortex-M based systems
- Native support for major neural networks though support for TOSA
- Full hardware acceleration of all major neural networks
- For a full list of features, see the Ethos-U85 Technical Overview
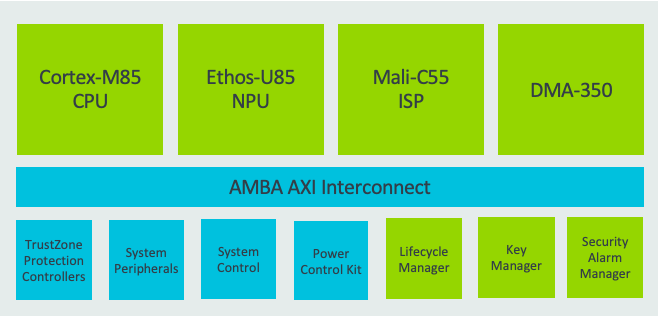
A typical compute subsystem design with Ethos-U85
What’s next
We are adding new operator support every week, extending ExecuTorch core ATen operator coverage, and enabling a wider range of models to run on Ethos-U. Our ongoing efforts focus on improving performance to ensure models run as optimally as possible on Ethos-U.
The ExecuTorch delegate framework supports fallback to running operators not supported by Ethos-U on the CPU using reference kernel implementations. We will work towards optimal performance on Cortex-M CPUs using CMSIS-NN, providing the best possible support for fallback operators and ensuring optimal performance for devices without Ethos-U capability.
The package above with the Corstone-320 FVP are more steps to simplify application development, so please, go ahead, check out the code and build process and send us feedback. Meanwhile we will be busy making weekly releases to enable more features, models and to extract the maximum performance out of the hardware.