
Scientific Machine Learning (SciML) is reshaping how complex physical and scientific systems are modelled and simulated. As researchers tackle increasingly sophisticated problems, the need for flexible and scalable tools has grown rapidly.
PINA is an open-source Python library designed to make SciML development fast, intuitive, and scalable. Built natively on PyTorch and PyTorch Lightning, and fully compatible with PyTorch Geometric, PINA provides a unified framework for tackling diverse scientific challenges—from learning solutions to partial differential equations and constructing machine learning force fields, to simulating dynamics or modelling object deformations. By combining the power of PyTorch with SciML-focused tools, PINA empowers researchers and engineers to develop, experiment, and deploy advanced neural network models with great efficiency.
To view the PyTorch Ecosystem, see the PyTorch Landscape and learn more about how projects can join the PyTorch Ecosystem.
About
PINA organizes Scientific Machine Learning workflows into a clear sequence of stages, providing structure without limiting flexibility. Instead of offering a loose collection of utilities, it introduces a coherent framework that helps users specify problems, build models, and train them efficiently.
The modular design keeps projects reproducible and easy to extend. Each stage can be customized, replaced, or combined with external PyTorch components, allowing PINA to adapt naturally to both research exploration and production pipelines.
There are four main stages: problem definition, model design, solver selection, and training. What follows is an overview of how each component shapes the SciML process.
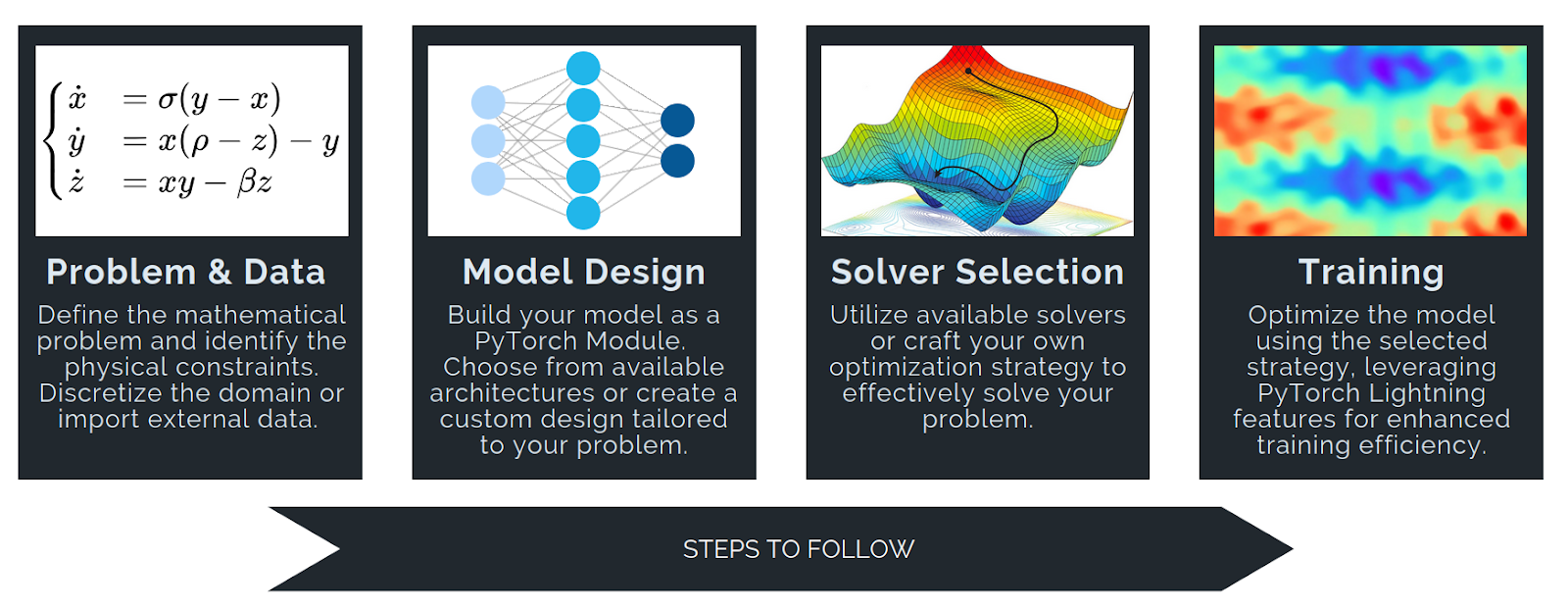
Problem & Data. At the core of this workflow lies the problem definition phase, where users formalise the mathematical description of their system, including physical, symmetry, or supervised constraints, together with the input and output points that characterise the problem. This stage accommodates a wide range of formulations: data can be provided as standard tensors, tensors with labels, samplable domains, or graph-structured inputs. Moreover, users may introduce soft constraints to be minimized, including physics-based losses and other application-specific penalties.
Model Design. In PINA, the model represents the trainable component that maps input variables – such as spatial coordinates, time, or parameters – to one or more output quantities, typically realized as a neural network architecture. The model design stage allows for full flexibility: users can choose from a wide range of built-in architectures, including graph-based models that work seamlessly with PyTorch Geometric, or integrate any custom PyTorch nn.Modules.
Solver Selection. The solver bridges the problem definition and the model by providing the optimization strategy and loss formulation needed to drive learning. It serves as the engine that connects the abstract mathematical formulation to the model’s learnable parameters. Regarding solver selection, PINA offers a suite of strategies, including Physics-Informed Neural Networks (PINNs) and their extensions, supervised solvers, generative approaches, and ensemble methods, each designed to address distinct problem formulations.
Training. Finally, training in PINA is powered by PyTorch Lightning, inheriting its modularity, scalability, and performance features. Native support for multi-device and data-parallel training enables efficient execution on large datasets and computationally demanding problems, both in research and industrial contexts. This lets users train complex SciML models without writing custom boilerplate, while keeping full compatibility with PyTorch workflows and infrastructure.
Owing to its flexible design, PINA adapts to diverse workflows – offering both high-level automation and low-level control. Its capabilities encompass a wide range of applications, spanning physics-based modelling, reduced-order modelling, equation discovery, robotics, chemical property prediction, and more.
Call to action
You can start digging into PINA easily by:
- Installation: Simply use
pipto install PINA - Learning the Basics: Dive into our series of tutorials to learn how to solve your problems.
- Documentation: Want to know more about PINA API? Check our documentation!
As an open-source project, PINA thrives on community contributions! Here’s how you can get involved:
- Report Issues: Open an issue to suggest improvements or report bugs.
- Add Features: Submit a Pull Request to contribute new desired features.
- Assist with Maintenance: Help with project upkeep by working on a good first issue.
Conclusion
PINA offers a cohesive SciML workflow built natively on PyTorch, unifying domains, constraints, differential operators, and flexible model architectures in a single framework that reduces boilerplate and streamlines experimentation across scientific applications. Its modular design makes Scientific Machine Learning more accessible, scalable, and adaptable—whether you’re modelling physical systems, developing reduced-order models, or exploring data-driven scientific discovery.
Key strengths include:
- Native PyTorch integration: works seamlessly with PyTorch and PyTorch Lightning.
- Support for varied data types: tensors, labelled tensors, samplable domains, and graphs.
- Built-in scientific tooling: domains, differential operators, soft constraints, and physics-based losses.
- Modular workflow: clear separation of problem, model, solver, and training.
- Graph compatibility: direct support for PyTorch Geometric.
- Broad applicability: physics-based modelling, ROM, equation discovery, robotics, chemistry, and more.
If PINA proves useful in your work, consider citing the JOSS paper and supporting the project on GitHub with a star.