As part of PyTorch 2.0 release, an accelerated implementation of the attention mechanism as part of the “Better Transformer” project (and known in PyTorch as Accelerated Transformers) has been added natively into PyTorch as torch.nn.functional.scaled_dot_product_attention. This implementation leverages fused kernels from FlashAttention and Memory-efficient attention, and supports both training and inference.
We also release a notebook showcasing an example of this integration here
After seeing 20-30% speedups at inference for diffusion models, we went ahead and implemented an integration with 🤗 Transformers models through the 🤗 Optimum library. Similar to the previous integration for encoder models, the integration replaces modules from Transformers with efficient implementations that use torch.nn.functional.scaled_dot_product_attention. The usage is as follow:
from optimum.bettertransformer import BetterTransformer
from transformers import AutoModelForCausalLM
with torch.device(“cuda”):
model = AutoModelForCausalLM.from_pretrained(“gpt2-large”, torch_dtype=torch.float16)
model = BetterTransformer.transform(model)
# do your inference or training here
# if training and want to save the model
model = BetterTransformer.reverse(model)
model.save_pretrained(“fine_tuned_model”)
model.push_to_hub(“fine_tuned_model”)
Summarizing our findings below about torch.nn.functional.scaled_dot_product_attention:
- It is most useful to fit larger models, sequence length, or batch size to train on a given hardware.
- Memory footprint savings on GPU during training range from 20% to 110%+.
- Speedups during training range from 10% to 70%.
- Speedups during inference range from 5% to 20%.
- Standalone, for small head dimensions,
scaled_dot_product_attentionspeedups go up to 3x, memory savings go as high as 40x (depending on the sequence length).
You may be surprised by the wide range of memory savings and speedups. In this blog post, we discuss our benchmarks, where this feature shines and upcoming improvements in future PyTorch releases.
In the next release of transformers you will just need to install the proper version of optimum and run:
model = model.to_bettertransformer()
To convert your model using the BetterTransformer API. You can already try this feature out by installing transformers from source.
Benchmark and usage with 🤗 Transformers
torch.nn.functional.scaled_dot_product_attention is usable with any architecture that uses standard attention, and namely replaces the boiler-plate code:
# native scaled_dot_product_attention is equivalent to the following:
def eager_sdpa(query, key, value, attn_mask, dropout_p, is_causal, scale):
scale_factor = 1 / math.sqrt(Q.size(-1)) if scale is None else scale
attn_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0) if is_causal else attn_mask
attn_mask = attn_mask.masked_fill(not attn_mask, -float('inf')) if attn_mask.dtype==torch.bool else attn_mask
attn_weight = torch.softmax((Q @ K.transpose(-2, -1) * scale_factor) + attn_mask, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p)
return attn_weight @ V
In the 🤗 Optimum integration with Transformers models, the following architectures are supported for now: gpt2, gpt-neo, gpt-neox, gptj, t5, bart, codegen, pegasus, opt, LLaMA, blenderbot, m2m100. You can expect this list to be extended in the near future!
To validate the benefits from the native scaled dot-product attention, we ran inference and training benchmarks, whose results are presented below.
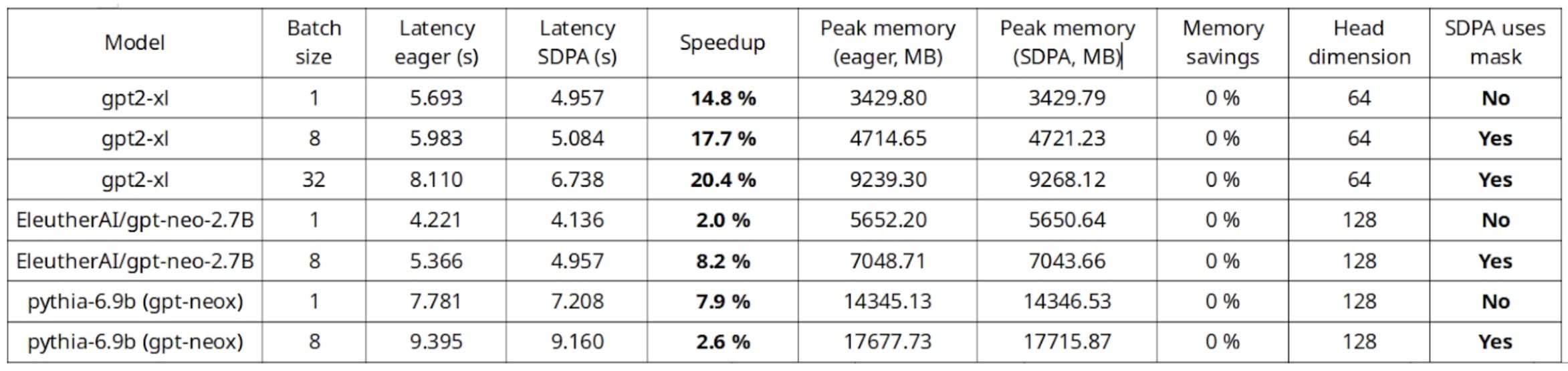 Inference benchmark on a single A10G GPU, AWS g5.4xlarge instance
Inference benchmark on a single A10G GPU, AWS g5.4xlarge instance
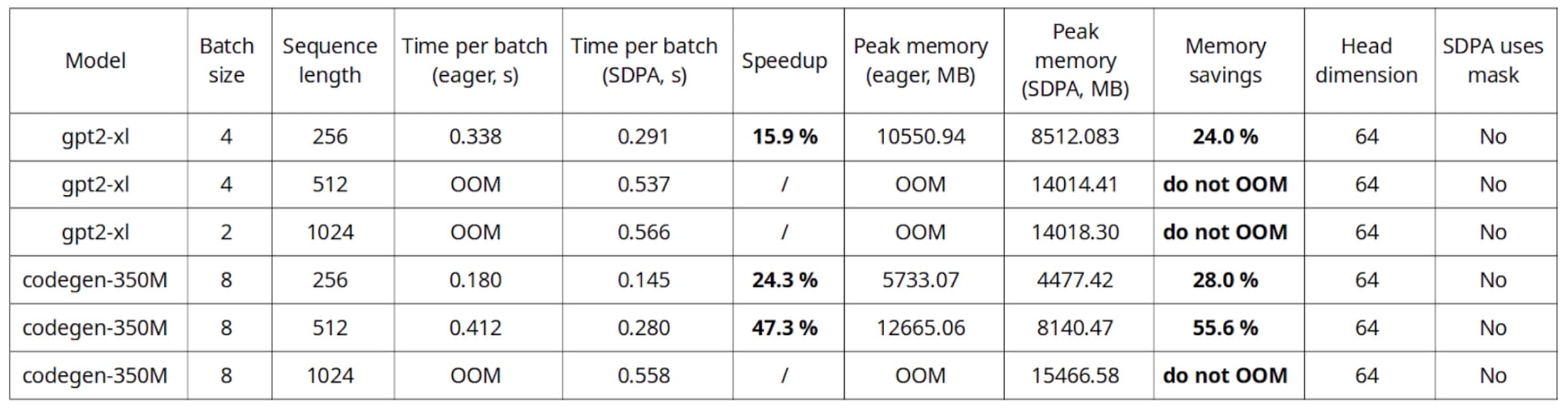 Training benchmark on a single A10G GPU, AWS g5.4xlarge instance
Training benchmark on a single A10G GPU, AWS g5.4xlarge instance
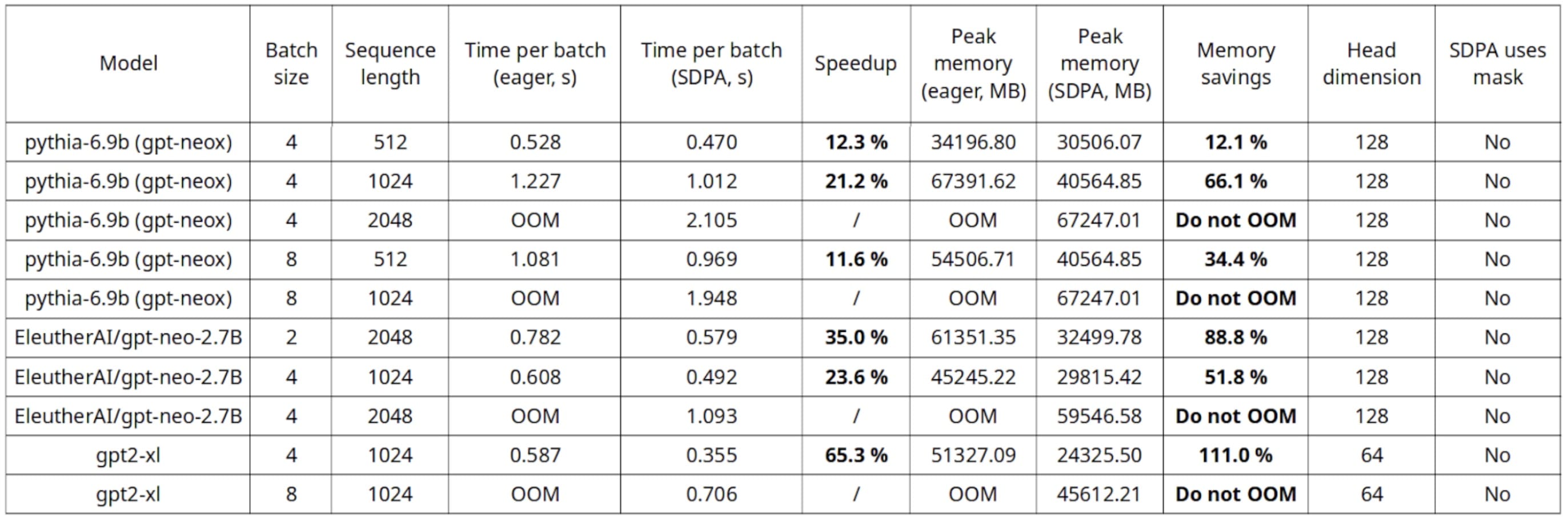 Training benchmark on a single A100-SXM4-80GB, Nvidia DGX
Training benchmark on a single A100-SXM4-80GB, Nvidia DGX
Out of this benchmark, the most interesting finding is that native SDPA allows for the usage of longer sequence lengths and batch sizes without running into out of memory issues. Moreover, up to 20% speedups can be seen during inference, and even larger during training.
As seen on the training benchmarks, it appears that smaller head dimension brings higher speedups and memory savings, which we will discuss in the following section.
The implementation supports multi-GPU settings as well, thanks to 🤗 Accelerate library by passing device_map=”auto” to the from_pretrained method. Here are some results for training on two A100-SXM4-80GB.
 Training benchmark on two A100-SXM4-80GB, Nvidia DGX, using 🤗 Accelerate library for distributed training
Training benchmark on two A100-SXM4-80GB, Nvidia DGX, using 🤗 Accelerate library for distributed training
Note that some kernels support only the sm_80 compute capability (which is the one from A100 GPUs), which limits usability on a wide range of hardware, notably if the head dimension is not a power of two. For example, as of PyTorch 2.0.0 during training, opt-2.7b (headim=80) and gpt-neox-20b (headdim=96) can not dispatch to a kernel using flash attention, unless run on an A100 GPU. Better kernels may be developed in the future: https://github.com/pytorch/pytorch/issues/98140#issuecomment-1518101895
Flash Attention, Memory-efficient attention & math differences
The native scaled_dot_product_attention relies on three possible backend implementations: flash attention, memory-efficient attention, and the so-called math implementation which provides a hardware-neutral fallback for all PyTorch platforms.
When fused kernels are available for a given problem size, flash-attention or memory-efficient attention will be used, effectively allowing for a lower memory footprint, as in the memory-efficient attention case O(N) memory allocations are done on the GPU global memory instead of the classic O(N^2) for the traditional eager attention implementation. With flash attention, a reduced number of memory accesses (read and writes) is expected, hence both giving speedups and memory savings.
The “math” implementation is simply an implementation using the PyTorch’s C++ API. Interesting to note in this implementation is that the query and key tensors are scaled individually for numerical stability, thus launching two aten::div operations instead of possibly only one in an eager implementation that does not contain this optimization for numerical stability.
Head dimension influence on speedups, memory savings
Benchmarking torch.nn.functional.scaled_dot_product_attention, we notice a decrease in the speedup / memory gains as the head dimension increases. This is an issue for some architectures like EleutherAI/gpt-neo-2.7B, that has a relatively large head dimension of 128, or EleutherAI/gpt-j-6B (and derived models as PygmalionAI/pygmalion-6b) that has a head dimension of 256 (that actually currently do not dispatch on fused kernels as the head dimension is too large).
This trend can be seen in the figures below, where torch.nn.scaled_dot_production is benchmarked standalone versus the above eager implementation. Moreover, we use the torch.backends.cuda.sdp_kernel context manager to force the usage of respectively math, flash attention, and memory-efficient attention implementation.
 Using memory-efficient attention SDP kernel (forward-only), A100
Using memory-efficient attention SDP kernel (forward-only), A100
 Using math (without dropout), A100
Using math (without dropout), A100
 Using flash attention SDP kernel (without dropout), A100
Using flash attention SDP kernel (without dropout), A100
 Using memory-efficient attention SDP kernel (without dropout), A100
Using memory-efficient attention SDP kernel (without dropout), A100
We see that for the same problem size, be it for inference-only or training, the speedup decreases with higher head dimension, e.g. from 3.4x for headdim=8 to 1.01x for headdim=128 using flash attention kernel.
The reduced memory saving is expected with larger head dimensions. Recall the standard attention computation:
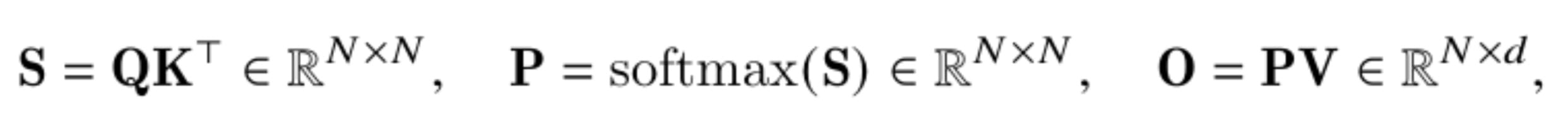
Due to the intermediate computations, the global memory footprint is 2 * N * N + N * d in this standard step by step computation. Memory-efficient attention proposes to iteratively update the softmax renormalization constant and moving its computation at the very end, allowing for only a constant output memory allocation N * d.
Thus, the memory saving ratio is 2 * N / d + 1, which decreases with larger head dimension.
In flash attention, the tradeoff is between the head dimension d and the shared memory size M of a GPU streaming multiprocessor, with a total number of memory accesses of O(N² * d²/M). Thus, the memory accesses scale quadratically in the head dimension, contrary to the standard attention that scales linearly. The reason is that in flash attention, for larger head dimension d, the key and value K, V need to be split into more blocks to fit into shared memory, and in turn each block needs to load the full query Q and output O.
Thus, the highest speedups for flash attention are in a regime where the ratio d² / M is small enough.
Current limitations as of PyTorch 2.0.0
Absence of a scale argument
As of PyTorch 2.0.0, torch.nn.functional.scaled_dot_product_attention has no scale argument and uses the default square root of the hidden size sqrt(d_k).
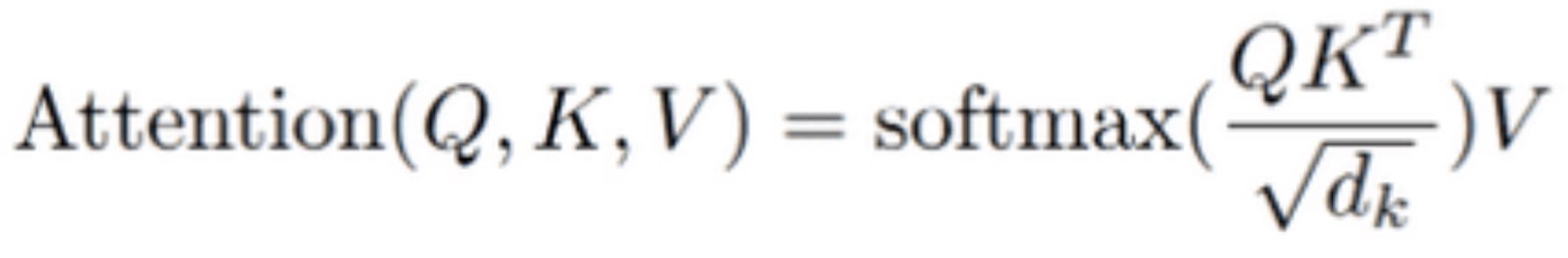
However, some architectures as OPT or T5 do not use a scaling in the attention, which as of Pytorch 2.0.0 forces it to artificially rescale before the scaled_dot_product_attention call. This introduces an unnecessary overhead, as an additional multiplication is necessary, on top of unneeded divisions in the attention.
A fix for this issue has been merged in PyTorch repository.
Support of flash attention / memory-efficient attention with custom mask
As of PyTorch 2.0.0, when passing a custom attention mask, flash attention and memory-efficient attention can not be used. In this case, scaled_dot_product_attention automatically dispatches to the C++ implementation.
However, as we have seen, some architectures require a custom attention mask, as T5 that uses positional bias. Moreover, in the case of a batch size larger than one where some inputs may be padded, a custom attention mask also needs to be passed. For this latter case, an alternative would be to use NestedTensor, which SDPA supports.
This limited support for custom masks thus limits the benefits from SDPA in these specific cases, although we can hope for an extended support in the future.
Note that xformers, from which PyTorch’s SDPA partially takes inspiration, currently supports arbitrary attention masks: https://github.com/facebookresearch/xformers/blob/658ebab39545f180a6075385b3897921623d6c3b/xformers/ops/fmha/cutlass.py#L147-L156 . HazyResearch implementation of flash attention also supports an equivalent implementation of padding, as a cumulative sequence length array is used along with packed query/key/values – similar in essence to NestedTensor.
In conclusion
Using torch.nn.functional.scaled_dot_product_attention is a free-lunch optimization, both making your code more readable, uses less memory, and is in most common cases faster.
Although the implementation in PyTorch 2.0.0 has still minor limitations, inference and training already massively benefit from SDPA in most cases. We encourage you to use this native implementation be it to train or deploy your PyTorch models, and for 🤗 Transformers models as a one-line transformation!
In the future, we would like to adapt the API to enable users to use SDPA in encoder-based models as well.
We thank Benjamin Lefaudeux, Daniel Haziza and Francisco Massa for their advice on the head dimension influence, as well as Michael Gschwind, Christian Puhrsch and Driss Guessous for their feedback on the blog post!
Benchmark reproduction
The benchmark presented in this post was done using torch==2.0.0, transformers==4.27.4, accelerate==0.18.0 and optimum==1.8.0.
The benchmarks can be easily reproduced using the scripts for inference, training for 🤗 Transformers models, and standalone SDPA.