PyTorch is one of the most widely used and most powerful deep learning frameworks for training and deploying complex neural networks. It has never been easier to train and deploy AI applications, and low-cost, high-performance, energy-efficient hardware, tools, and technology for creating optimized workflows are more accessible than ever. But data science, machine learning, and devops can be deep topics unto themselves, and it can be overwhelming for developers with one specialty to see how they all come together in the real world, or even to know where to get started.
To that end, we at Arm have collaborated with our friends at GitHub to decompose the basic elements of real world MLOps pipelines that use PyTorch models and create a simplified workflow and MLOps tutorial that anyone with a GitHub and a Docker Hub account can leverage.
MLOps Overview
The software development lifecycle for machine learning applications typically starts from training data, which is used to train sophisticated neural networks (NNs) that are optimized, integrated into software images, and then deployed onto compute clusters and even fleets of devices in the field. These devices are typically continuously collecting data and are managed by cloud services, which actively monitor performance of the ML algorithm(s) and feedback data for retraining in the next iteration of the lifecycle – enabling continuous improvement of the algorithms, as well as supporting deployment of new AI features.
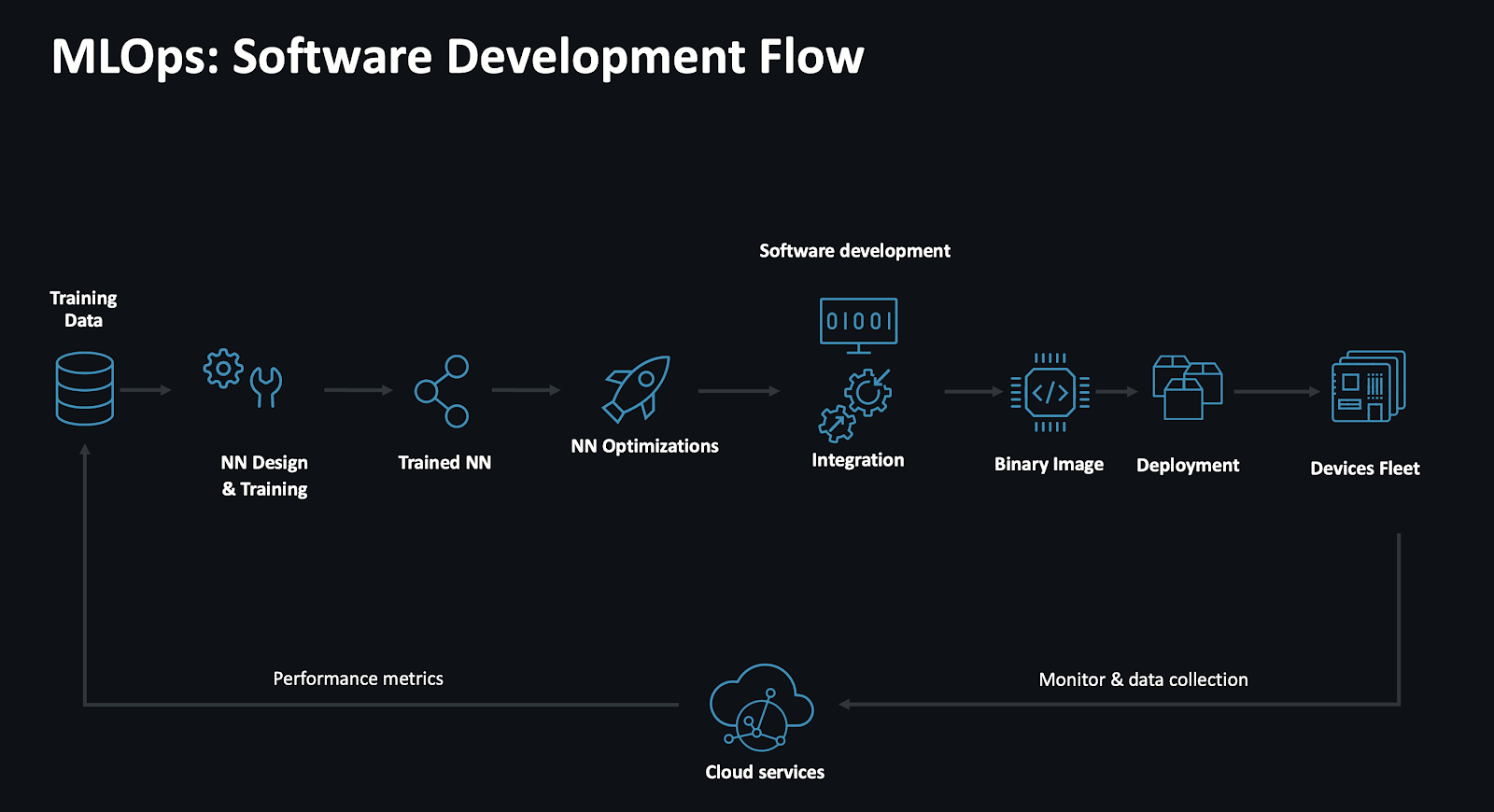
Example of a typical ML software development lifecycle.
Scott Arbeit from GitHub recently published an excellent blog that highlights the importance of MLOps in machine learning and describes automation via simplified GitHub actions for several key tasks including:
- Data preprocessing: cleaning and preparation of data for training.
- Model training and validation: automatic execution of training scripts when new data is pushed or when changes are made to the model code.
- Deployment: automatic packaging and deployment of models to production environments upon successful training and validation.
- Monitoring and alerts: workflows to monitor model performance and send alerts if certain thresholds are breached.
The article also describes a conceptual efficient MLOps pipeline that takes advantage of new, low-cost Arm Runners natively integrated into GitHub Actions to train and validate PyTorch models. It also uses containerization for consistent deployment across different environments.
Our team at Arm put GitHub’s ideas and conceptual workflow into practice and created a tutorial to help you get started today.
Optimizing Your PyTorch MLOps Workflow
A new Arm Learning Path unpacks each of the key phases described in Scott’s blog, and demonstrates each key task in detail, providing prescriptive instructions and code examples to leverage several aspects of the PyTorch framework to implement each phase.

Key ML tasks to setup and automate with GitHub Actions.
With this learning path you will be able to take advantage of the following strategies with a real-world object detection use case to make your own streamlined MLOps workflow:
- Containerization: Package your PyTorch model and its dependencies into a Docker container to help ensure consistent performance across different environments.
- Efficient Data Loading: Optimize data loading pipelines to help minimize I/O bottlenecks and maximize GPU utilization.
- Model Optimization: Explore techniques like model quantization, pruning, and knowledge distillation to help reduce model size and improve inference speed.
- Leverage PyTorch’s Ecosystem: Utilize libraries like TorchVision to help streamline common deep learning tasks.
- Monitor and Profile: Monitor resource utilization and identify potential bottlenecks to further optimize your workflow.
An End-to-End MLOps Workflow
The best part of this learning path is not just that it takes you through each task in detail, but it brings it all together into a unified automated workflow.
With GitHub Actions, you can build an end-to-end custom MLOPs workflow that combines and automates the individual workflows for each ML task. To demonstrate this, the repository contains a workflow in a boilerplate .yml file that automates the individual steps.
You can run an MLOps workflow using GitHub Actions natively for managing all the steps in your ML application’s lifecycle.

A successful run of this MLOps workflow in GitHub Actions.
Try It Yourself!
Our Arm team has battle-tested this tutorial in the field and delivered the tutorial as a workshop at GitHub Universe 2024 earlier this year. Now it’s time for you to take it for a spin and get hands-on with PyTorch and MLOps.
Try the Arm Learning Path Here!
By the end of this tutorial, you can:
- Set up a new GitHub Arm-runner to natively build an arm64 image to take advantage of the lowest-cost, most power efficient compute available.
- Train and test a PyTorch ML model with the German Traffic Sign Recognition Benchmark (GTSRB) dataset.
- Compare the performance of two trained PyTorch ML models; one model compiled with OpenBLAS (Open Basic Linear Algebra Subprograms Library) and oneDNN (Deep Neural Network Library), and the other model compiled with Arm Compute Library (ACL).
- Containerize a ML model and push the container to DockerHub.
- Automate each task into a single MLOps pipeline Using GitHub Actions.
Combining the power of PyTorch with the simplicity of GitHub Actions and the efficiency of native Arm Runners significantly helps you accelerate your deep learning development and deployment processes. Following the best practices outlined in this blog post helps you achieve optimal performance and cost-effectiveness for your PyTorch projects.
We’d love to see what you create based on this example. If you have created your own Arm Learning Path, you are invited to share it here.