
We’re delighted to announce that LMCache has officially become a PyTorch Ecosystem project, joining the growing family of open source tools advancing AI inference.
To view the PyTorch Ecosystem, see the PyTorch Landscape and learn more about how projects can join the PyTorch Ecosystem.
Running inference for large language models (LLMs) is far less resource-intensive than training them, but once the queries start coming in, costs can escalate quickly. When response time and accuracy are critical to the success of your project, there are no shortcuts.
This is where LMCache shines. Developed from breakthrough research by a team at the University of Chicago, LMCache is the first and most efficient open source Key-Value caching (KV caching) solution. It extracts and stores KV caches generated by modern LLM engines (vLLM and SGLang) and shares the KVcaches across engines and queries.
LMCache exposes KV caches in the LLM engine interface, transforming LLM engines from individual token processors to a collection of engines with KV cache as the storage and communication medium. It supports both cache offloading (prefix reuse across queries) and prefill–decode (PD) disaggregation (cross-engine cache transfer).
LMCache’s high performance and wide adoption stem from the following contributions:
- Optimized KV cache data movement with performance optimizations, including batched data movement operations, compute and I/O pipelining.
- Modular KV cache connector component, decoupling LMCache from the rapid evolution of inference engines;
- First-class control API, such as pinning, lookup, cleanup, movement, and compression, for flexible cache orchestration across GPU, CPU, storage, and network layers.
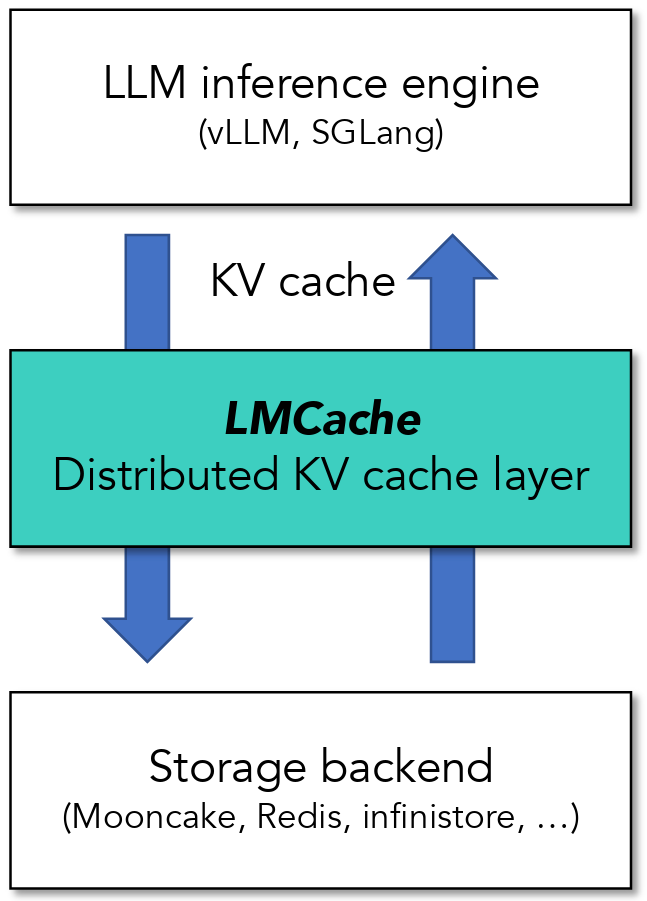
LMCache sits between LLM Inference Engines and storage backends
Evaluation shows that combining LMCache with vLLM achieves up to 15× improvement in throughput across workloads such as multi-round question answering (a typical chatbot, for example) and document analysis (including RAG).
With a rapidly growing community, LMCache has seen strong adoption by enterprise inference systems, offering valuable insights for future KV caching solutions. The source code is available on GitHub: https://github.com/LMCache/LMCache
If your serving engine of choice is vLLM, setup is simple:
pip install lmcache vllm
vllm serve Qwen/Qwen3-4B-Instruct-2507 \
--kv-transfer-config \
'{"kv_connector":"LMCacheConnectorV1", "kv_role":"kv_both"}'
Your LMCache-augmented vLLM server is now up and running!
You can find a lot more details about LMCache through the following resources:
Have questions? Join the conversation on LMCache’s Slack. We would love to hear from you.