Language Identification is the process of identifying the primary language from multiple audio input samples. In natural language processing (NLP), language identification is an important problem and a challenging issue. There are many language-related tasks such as entering text on your phone, finding news articles you enjoy, or discovering answers to questions that you may have. All these tasks are powered by NLP models. To decide which model to invoke at a particular point in time, we must perform language identification.
This article presents an in-depth solution and code sample for language identification using Intel® Extension for PyTorch, which is a version of the popular PyTorch AI framework optimized for use on Intel® processors, and Intel® Neural Compressor, which is a tool to accelerate AI inference without sacrificing accuracy.
The code sample demonstrates how to train a model to perform language identification using the Hugging Face SpeechBrain* toolkit and optimize it using the Intel® AI Analytics Toolkit (AI Kit). The user can modify the code sample and identify up to 93 languages using the Common Voice dataset.
Proposed Methodology for Language Identification
In the proposed solution, the user will use an Intel AI Analytics Toolkit container environment to train a model and perform inference leveraging Intel-optimized libraries for PyTorch. There is also an option to quantize the trained model with Intel Neural Compressor to speed up inference.
Dataset
The Common Voice dataset is used and for this code sample, specifically, Common Voice Corpus 11.0 for Japanese and Swedish. This dataset is used to train an Emphasized Channel Attention, Propagation and Aggregation Time Delay Neural Network (ECAPA-TDNN), which is implemented using the Hugging Face SpeechBrain library. Time Delay Neural Networks (TDNNs), aka one-dimensional Convolutional Neural Networks (1D CNNs), are multilayer artificial neural network architectures to classify patterns with shift-invariance and model context at each layer of the network. ECAPA-TDNN is a new TDNN-based speaker-embedding extractor for speaker verification; it is built upon the original x-vector architecture and puts more emphasis on channel attention, propagation, and aggregation.
Implementation
After downloading the Common Voice dataset, the data is preprocessed by converting the MP3 files into WAV format to avoid information loss and separated into training, validation, and testing sets.
A pretrained VoxLingua107 model is retrained with the Common Voice dataset using the Hugging Face SpeechBrain library to focus on the languages of interest. VoxLingua107 is a speech dataset used for training spoken language recognition models that work well with real-world and varying speech data. This dataset contains data for 107 languages. By default, Japanese and Swedish are used, and more languages can be included. This model is then used for inference on the testing dataset or a user-specified dataset. Also, there is an option to utilize SpeechBrain’s Voice Activity Detection (VAD) where only the speech segments from the audio files are extracted and combined before samples are randomly selected as input into the model. This link provides all the necessary tools to perform VAD. To improve performance, the user may quantize the trained model to integer-8 (INT8) using Intel Neural Compressor to decrease latency.
Training
The copies of training scripts are added to the current working directory, including create_wds_shards.py – for creating the WebDataset shards, train.py – to perform the actual training procedure, and train_ecapa.yaml – to configure the training options. The script to create WebDataset shards and YAML file are patched to work with the two languages chosen for this code sample.
In the data preprocessing phase, prepareAllCommonVoice.py script is executed to randomly select a specified number of samples to convert the input from MP3 to WAV format. Here, 80% of these samples will be used for training, 10% for validation, and 10% for testing. At least 2000 samples are recommended as the number of input samples and is the default value.
In the next step, WebDataset shards are created from the training and validation datasets. This stores the audio files as tar files which allows writing purely sequential I/O pipelines for large-scale deep learning in order to achieve high I/O rates from local storage—about 3x-10x faster compared to random access.
The YAML file will be modified by the user. This includes setting the value for the largest number for the WebDataset shards, output neurons to the number of languages of interest, number of epochs to train over the entire dataset, and the batch size. The batch size should be decreased if the CPU or GPU runs out of memory while running the training script.
In this code sample, the training script will be executed with CPU. While running the script, “cpu” will be passed as an input parameter. The configurations defined in train_ecapa.yaml are also passed as parameters.
The command to run the script to train the model is:
python train.py train_ecapa.yaml --device "cpu"
In the future, the training script train.py will be designed to work for Intel® GPUs such as the Intel® Data Center GPU Flex Series, Intel® Data Center GPU Max Series, and Intel® Arc™ A-Series with updates from Intel Extension for PyTorch.
Run the training script to learn how to train the models and execute the training script. The 4th Generation Intel® Xeon® Scalable Processor is recommended for this transfer learning application because of its performance improvements through its Intel® Advanced Matrix Extensions (Intel® AMX) instruction set.
After training, checkpoint files are available. These files are used to load the model for inference.
Inference
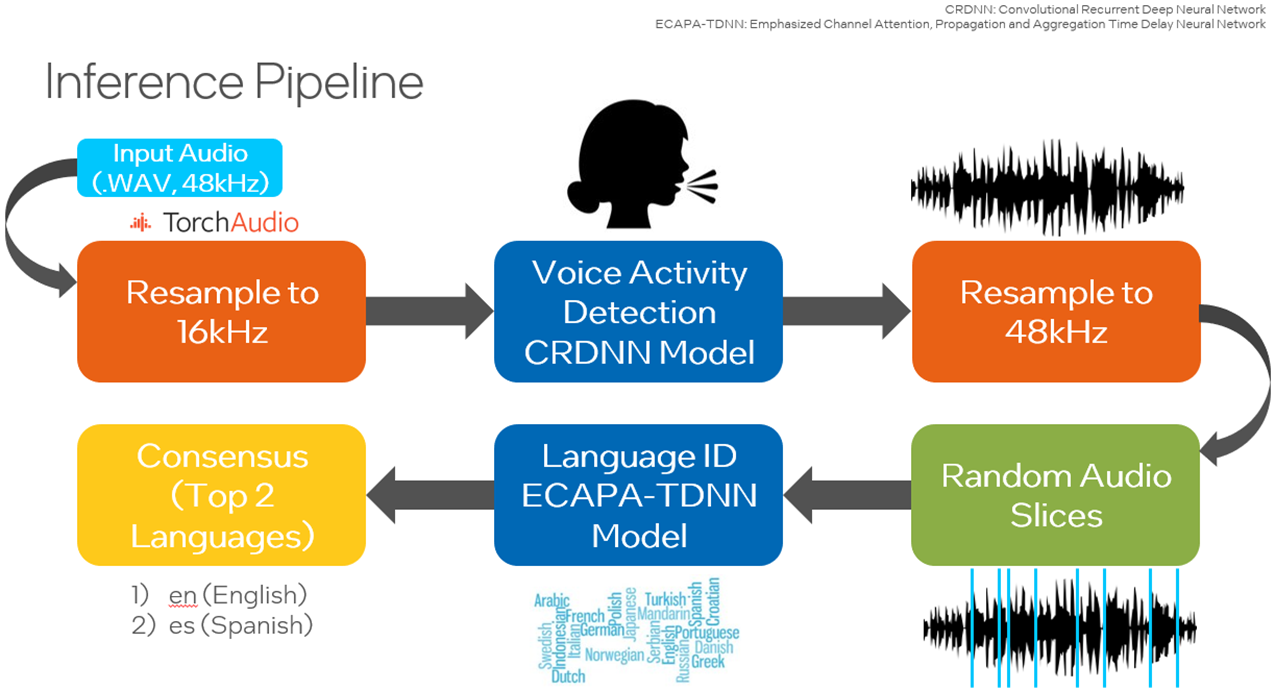
The crucial step before running inference is to patch the SpeechBrain library’s pretrained interfaces.py file so that PyTorch TorchScript* can be run to improve the runtime. TorchScript requires the output of the model to be only tensors.
Users can choose to run inference using the testing set from Common Voice or their own custom data in WAV format. The following are the options the inference scripts (inference_custom.py and inference_commonVoice.py) can be run with:
| Input Option | Description |
| -p | Specify the data path. |
| -d | Specify the duration of wave sample. The default value is 3. |
| -s | Specify size of sample waves, default is 100. |
| –vad | (`inference_custom.py` only) Enable VAD model to detect active speech. The VAD option will identify speech segments in the audio file and construct a new .wav file containing only the speech segments. This improves the quality of speech data used as input into the language identification model. |
| –ipex | Run inference with optimizations from Intel Extension for PyTorch. This option will apply optimizations to the pretrained model. Using this option should result in performance improvements related to latency. |
| –ground_truth_compare | (`inference_custom.py` only) Enable comparison of prediction labels to ground truth values. |
| –verbose | Print additional debug information, like latency. |
The path to the data must be specified. By default, 100 audio samples of 3-seconds will be randomly selected from the original audio file and used as input to the language identification model.
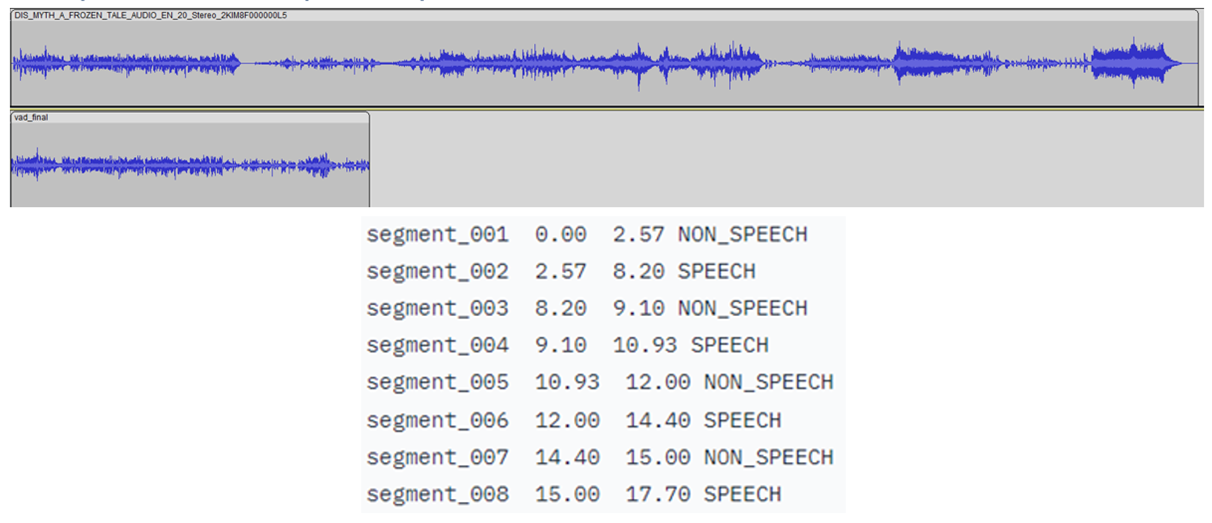
A small Convolutional Recurrent Deep Neural Network (CRDNN) pretrained on the LibriParty dataset is used to process audio samples and output the segments where speech activity is detected. This can be used in inference with the --vad option.
From the figure below, the timestamps where speech will be detected is delivered from the CRDNN model, and these are used to construct a new, shorter audio file with only speech. Sampling from this new audio file will give a better prediction of the primary language spoken.
Run the inference script yourself. An example command of running inference:
python inference_custom.py -p data_custom -d 3 -s 50 --vad
This will run inference on data you provide located inside the data_custom folder. This command performs inference on 50 randomly selected 3-second audio samples with voice activity detection.
If you want to run the code sample for other languages, download Common Voice Corpus 11.0 datasets for other languages.
Optimizations with Intel Extension for PyTorch and Intel Neural Compressor
PyTorch
The Intel extension expands PyTorch with up-to-date features and optimizations for an extra performance boost on Intel hardware. Check out how to install Intel Extension for PyTorch. The extension can be loaded as a Python module or linked as a C++ library. Python users can enable it dynamically by importing intel_extension_for_pytorch.
- The CPU tutorial gives detailed information about Intel Extension for PyTorch for Intel CPUs. Source code is available at the master branch.
- The GPU tutorial gives detailed information about Intel Extension for PyTorch for Intel GPUs. Source code is available at the xpu-master branch.
To optimize the model for inference using Intel Extension for PyTorch, the --ipexoption can be passed in. The model is optimized using the plug-in. TorchScript speeds up inference because PyTorch is run in graph mode. The command to run with this optimization is:
python inference_custom.py -p data_custom -d 3 -s 50 --vad --ipex --verbose
Note: The --verbose option is required to view the latency measurements.
Auto-mixed precision such as bfloat16 (BF16) support will be added in a future release of the code sample.
Intel Neural Compressor
This is an open-source Python library that runs on CPUs or GPUs, which:
- Performs model quantization to reduce the model size and increase the speed of deep learning inference for deployment.
- Automates popular methods such as quantization, compression, pruning, and knowledge distillation across multiple deep-learning frameworks.
- Is part of the AI Kit
The model can be quantized from float32 (FP32) precision to integer-8 (INT8) by running the quantize_model.py script while passing in the path to the model and a validation dataset. The following code can be used to load this INT8 model for inference:
from neural_compressor.utils.pytorch import load
model_int8 = load("./lang_id_commonvoice_model_INT8", self.language_id)
signal = self.language_id.load_audio(data_path)
prediction = self.model_int8(signal)
Note that the original model is required when loading the quantized model. The command to quantize the trained model from FP32 to INT8 by using quantize_model.py is:
python quantize_model.py -p ./lang_id_commonvoice_model -datapath $COMMON_VOICE_PATH/commonVoiceData/commonVoice/dev
What’s Next?
Try out the above code sample by upgrading the hardware to a 4th Generation Intel Xeon Scalable Processor with Intel AMX and identify up to 93 different languages from Common Voice datasets.
We encourage you to learn more about and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow. Also, visit AI & ML page covering Intel’s AI software development resources for preparing, building, deploying, and scaling your AI solutions.
For more details about the new 4th Gen Intel Xeon Scalable processors, visit Intel’s AI Solution Platform portal where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.
Useful resources
- Intel AI Developer Tools and resources
- oneAPI unified programming model
- Official documentation – Intel® Optimization for TensorFlow*
- Official documentation – Intel® Neural Compressor
- Accelerate AI Workloads with Intel® AMX