In this post, we announce torchforge: A PyTorch-native agentic RL library that lets you focus on algorithms—not infra.
First, let’s start with why we decided to solve this problem:
Reinforcement Learning has become essential to frontier AI – from instruction following and reasoning to complex research capabilities, RL is how we train models to improve through feedback. Instead of just learning from static datasets, models learn by trying actions and receiving rewards that guide them toward better behavior. But there’s a problem: the infrastructure complexity of RL often dominates the actual research.
The classical RL training loop looks like this:
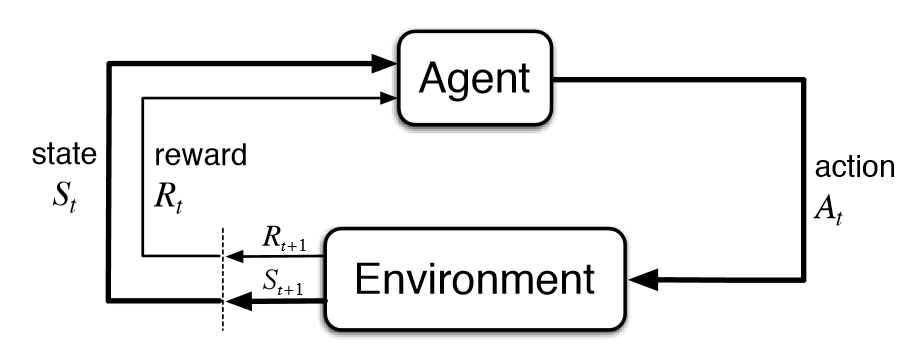
An agent takes an action in an environment, which yields a reward. The reward is used to update the agent’s behavior – or, its policy (the strategy that determines what actions to take). In the Large Language Model (LLM) use case, the policy is the model itself, and updating it means updating its parameters to improve response quality.
While this seems simple in theory, in practice we run into distributed infrastructure challenges:
- Scale: Many modern models are too large to fit on a single GPU (and sometimes hosts!), so we need to shard their weights. Different workloads (i.e. training, inference) often require different sharding strategies.
- Performance bottlenecks: In RL for LLMs, the reward is often derived from the output of the policy model. This requires running autoregressive generation, which can be costly. If we fully block our training on generations, it will severely impact our throughput, slowing down training speeds.
- Tools and environments: In Reinforcement Learning with Verifiable Rewards (RLVR – where rewards come from objective verification like code execution or math checking), we often want to verify our policy model generations for some notion of correctness (e.g. checking if our math was correct, or if our code passes unit tests). Alternatively, we may want to teach our model to use various tools as part of the training process. In both cases, the varying latency can substantially impact the system’s end-to-end performance.
- Weight Synchronization: In disaggregated setups, when training produces new policy weights, they need to propagate to all inference replicas. For a 70B parameter model across 16 replicas, this means moving hundreds of gigabytes of model weights. Traditional networking makes this prohibitively slow – a single update can take minutes, completely bottlenecking your training iteration speed.
In practice, we wind up with a system like this:
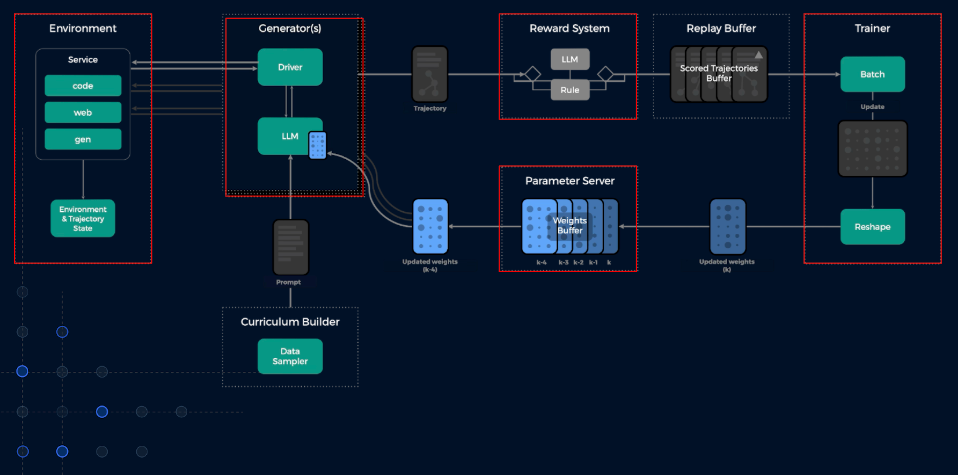
Figure 1: Visualizing a Fully Asynchronous RL System
In order to address the aforementioned performance bottlenecks, it is often necessary to allow some degree of “off-policyness” (i.e. we allow the rollout loop to generate trajectories based on slightly stale weights). This necessitates the existence of a weight store abstraction, which, together with a replay buffer, intermediates trainer workers and policy workers.
Asynchrony alone is not sufficient. With different workers having different performance profiles, the ability to scale up or down different components to eliminate bottlenecks is crucial for achieving peak performance.
Existing frameworks often require explicit movement, resharding, and complex control flow to manage RL loops with asynchrony at scale. Our goal with torchforge is to abstract away these concerns so that researchers can focus on algorithms without being bogged down by infrastructure.
Torchforge is designed to:
- Express RL as pseudocode while seamlessly scaling across GPU clusters
- Support any degree of asynchrony – from fully synchronous PPO to fully async off-policy training
- Separate infrastructure from algorithms so you focus on what matters
- Compose naturally – mix and match components for different RL approaches
Built on proven foundations:
- Monarch – PyTorch-native distributed framework for coordination and fault tolerance
- torchtitan – Meta’s production-grade LLM training platform
- vLLM – High-throughput, memory-efficient inference engine
This post walks through torchforge from the ground up: the composable API that lets you write RL like pseudocode, the Monarch primitives that abstracts out infra complexity and make it scalable, the production components (vLLM, torchtitan) that deliver performance and validation from real deployments on hundreds of GPUs. By the end, you’ll understand both what makes torchforge different and how to start using it for your own RL research.
A Note on Experimental Status
Both Monarch and torchforge are experimental and under active development. APIs may change as we learn from early adopters and refine our approach. We’re committed to supporting early users through these changes, but if you’re building production systems, please reach out to discuss stability expectations.
RL as Pseudocode
Here’s what generating a single episode looks like in torchforge:
async def generate_episode( dataloader, policy, reference_model, reward, replay_buffer ): # Sample a prompt from the dataset prompt, target = await dataloader.sample.route() # Generate response using the policy (vLLM inference) response = await policy.generate.route(prompt) # Compute reference model log probabilities for KL penalty input_ids = torch.cat([response.prompt_ids, response.token_ids]) ref_logits = await reference_model.forward.route(input_ids) ref_logprobs = compute_logprobs(ref_logits, response.token_ids) # Evaluate the response quality reward_value = await reward.evaluate_response.route( prompt=prompt, response=response.text, target=target ) # Store the episode for training await replay_buffer.add.route( Episode( prompt_ids=response.prompt_ids, response_ids=response.token_ids, response_text=response.text, reward=reward_value, ref_logprobs=ref_logprobs ) )
This is actual RL logic – sampling prompts, generating responses, computing rewards, calculating reference logprobs for KL penalties. The kind of code you’d write in pseudocode when designing an algorithm.
Notice what we don’t have here:
- No retry logic or failure handling
- No resource allocation or version management
- No synchronization logic
Now watch what happens when we compose this into continuous, asynchronous training:
async def async_rl_loop(num_rollout_loops: int): """Async RL: continuous rollouts, continuous training.""" # Start multiple concurrent rollout generators rollout_tasks = [ asyncio.create_task(continuous_rollouts()) for _ in range(num_rollout_loops) ] # Start continuous training training_task = asyncio.create_task(continuous_training()) await asyncio.gather(*rollout_tasks, training_task) async def continuous_rollouts(): """Generate rollouts continuously using latest policy.""" while True: await generate_episode( dataloader, policy, reference_model, reward, replay_buffer ) async def continuous_training(): """Train continuously on available experience.""" training_step = 0 while True: # Sample from replay buffer at current training version batch = await replay_buffer.sample.route( curr_policy_version=training_step ) if batch is None: await asyncio.sleep(0.1) # Wait for more experience else: inputs, targets = batch loss = await trainer.train_step.route(inputs, targets) training_step += 1 # Push updated weights and broadcast to policy replicas await trainer.push_weights.route(training_step) await policy.update_weights.fanout(training_step)
Multiple rollout generators run simultaneously (tuned by `num_rollout_loops`). Training happens continuously as soon as experience is available. This is fully asynchronous, off-policy RL, enabling maximum throughput.
Async training is great for throughput, but maybe you’re implementing PPO or another on-policy algorithm that needs strict data collection guarantees. The exact same `generate_episode()` function still works – just compose it differently:
async def synchronous_rl(batch_size: int): """Synchronous on-policy RL: collect batch, then train.""" version = 0 while True: # Collect a full batch with current policy version for _ in range(batch_size): await generate_episode( dataloader, policy, reference_model, reward, replay_buffer ) # Sample the batch we just collected batch = await replay_buffer.sample.route( curr_policy_version=version, batch_size=batch_size ) # Train on the complete batch inputs, targets = batch loss = await trainer.train_step.route(inputs, targets) # Push updated weights and broadcast to policy await trainer.push_weights.route(version + 1) await policy.update_weights.fanout(version + 1) version += 1
What changed here is the coordination pattern. We collect a complete batch before training, and weight updates happen in lockstep with data collection. But the rollout generation logic and RL code stay the same.
This is the power of torchforge! You can write your rollout logic once, and compose it into any paradigm. On-policy, off-policy, or anywhere in between.
But the simplicity doesn’t come for free. Behind these APIs, there is a sophisticated infrastructure layer that handles complexities like fault tolerance, weight synchronization, distributed coordination,etc. None of this complexity leaks into your code, but it’s all working underneath to make this experience possible.
So how does it actually work?
The Foundation: Monarch
Torchforge builds heavily on top of Monarch, a PyTorch-native distributed programming framework based on scalable actor messaging.
What Monarch gives us is a single controller programming model that makes distributed RL workloads tractable. Let’s understand why this matters.
The SPMD Problem
Figure 1 showed a typical RL training setup for LLMs. You have generator workers generating text, trainer workers updating weights, reward evaluators scoring outputs, and a replay buffer coordinating between them. Each connection represents data movement, coordination, or synchronization that need to be managed.
In actual deployments, models are often too large to fit on a single GPU – meaning that your generators and trainers need to be sharded across multiple devices.
Modeling the data flow between these components becomes complicated because these workloads are typically expressed as SPMD jobs (Single Program, Multiple Data) – a programming paradigm where control is defined at the replica level. In an SPMD programming model, data and control flow are hard to reason about. You have to think about many ranks simultaneously, coordinate collective operations for fast data movement, and manage the complexity of which rank is communicating with which other rank.
The Monarch Approach
Thanks to Monarch’s mesh-centric, actor-based messaging model, we can model this workload elegantly.
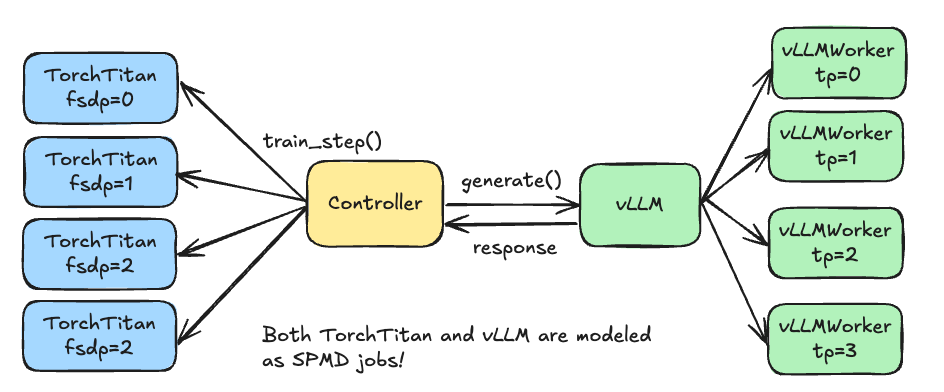
Figure 2: Monarch actors wrap sharded components, enabling coordination at the logical level rather than per-rank
Instead of reasoning about individual ranks and collective operations, you program at the logical component level. Generators, trainers, and reward models are ActorMeshes (collections of actors). You express communication between components naturally: “generator, run inference on this prompt” or “trainer, here’s a batch to train on.”
Monarch’s single controller orchestrates everything. You write coordination logic as a single Python program, calling methods on actors and passing data between them. The controller handles the complexity of mapping these logical operations to distributed execution – which ranks communicate, how collectives are coordinated, how RDMA transfers happen.
Importantly, the underlying components themselves are often SPMD jobs – vLLM for inference uses tensor parallelism, torchtitan for training uses FSDP. Monarch doesn’t replace these; it orchestrates them. This makes it easy to integrate existing ecosystem components that already work well at scale. You get the benefits of proven SPMD implementations (performance, scalability) with a simpler programming model on top (single controller coordination).
There is a whole world of distributed systems design decisions that enables Monarch to scale to thousands of GPUs while simultaneously enabling fault tolerance and fast data movement – however, we won’t dive into that here. For readers interested in the deep technical details – how the single controller architecture works, how actor failures are handled, and how RDMA integration enables high-bandwidth transfers – we recommend checking out our Monarch blog post.
For this post, we’ll focus on the specific pieces that torchforge builds on top of Monarch: a lightweight service abstraction on top of distributed actors, and TorchStore: an efficient, distributed in-memory key-value store with RDMA-based data transfers.
Services
Torchforge introduces Services – a higher-level abstraction built on top of Monarch actors. Services handle all the operational complexity of managing distributed actors: spawning replicas across nodes, fault tolerance, load balancing, and intelligent routing.
In torchforge, components can be created as services with simple resource specifications:
# Create a policy service with 16 replicas, each using 8 GPUs policy = PolicyActor.options( hosts=1, procs=8, with_gpus=True, num_replicas=16 ).as_service() # Create a lightweight coding environment service # For RL on coding tasks - execute generated code safely coder = SandboxedCoder.options( procs=1, with_gpus=False, num_replicas=16 ).as_service() # Create a reward model service reward = RewardActor.options( hosts=1, procs=4, with_gpus=True, num_replicas=4 ).as_service()
The `.options()` API lets you specify the shape and scale of each service. The policy service above creates 16 replicas, each spanning 8 GPUs – giving us 128 total GPUs for inference with automatic load balancing across replicas.
The coding environment is a different kind of service – lightweight, CPU-only, created ephemerally with your job. No separate Kubernetes deployment needed. Just spawn 16 replicas for parallel code execution during rollouts, and they shut down when your job finishes.
Service Adverbs
Services provide basic adverbs that operate at the replica level:
# route() - load balanced request to one replica response = await policy.generate.route(prompt) result = await coding_env.execute.route(code_string) # fanout() - broadcast to ALL replicas await policy.update_weights.fanout(version)
These adverbs are what you’ve been seeing throughout the RL code. When you call `policy.generate.route(prompt)`, torchforge:
- Picks an available policy replica (e.g. with round robin)
- Routes the request to that replica’s actors
- Returns the response
- Automatically routes around failed replicas
Stateful Operations
Use sticky sessions when you need consistency:
async with policy.session(): # All calls in this context hit the same replica # Crucial for maintaining KV cache state across turns response1 = await policy.generate.route(prompt1) response2 = await policy.generate.route(prompt2)
Fault Tolerance
If a replica fails during a rollout, Services will detect it, mark it unhealthy, and route subsequent requests to healthy replicas. The failed replica gets restarted automatically. Your RL code never sees the failure.
Why This Matters for RL
These service abstractions solve critical RL infrastructure challenges that typically force you to write distributed systems code instead of RL algorithms:
Load balancing across rollouts: In async RL, you have multiple `continuous_rollouts()` tasks running concurrently, each generating episodes. Services automatically distribute these rollouts across available replicas. No manual load balancing logic, no worker pools to manage – just call `.route()` and torchforge will handle selecting the replica.
Heterogeneous scaling: Different components need different resources. Your policy service might need 16 replicas x 8 GPUs for high-throughput vLLM inference. Your reward model might need 4 replicas x 4 GPUs. Your coding environment might need 16 lightweight CPU-only replicas. Services let each component scale independently based on its bottleneck.
Ephemeral infrastructure: Services are created with your job and torn down when finished. Whether you want to try a new reward model, or add new environments between runs, it’s as simple as changing your Python code. No standing deployments need to be maintained, and no additional infrastructure needs to be provisioned ahead of time.
Fault tolerance keeps training running: RL training can run for hours or days. Hardware failures are inevitable. Without service-level fault tolerance, a single GPU failure means restarting your entire job and losing progress. With services, failed replicas restart automatically, and healthy replicas keep processing rollouts. Your training continues uninterrupted.
No infrastructure in your RL code: Look back at the `generate_episode()` and training loop code. There’s no worker management, no retry logic, no failure handling, no load balancing code. Services handle all of this at the infrastructure layer, so your RL algorithms stay clean.
Services solve the control plane problem – routing requests, managing replicas, handling failures. But distributed RL has another critical challenge: the data plane.
Every training step produces a new checkpoint – potentially tens of billions of parameters that need to move from your trainer to all your policy replicas. With 16 policy replicas running vLLM inference, you need to broadcast a 70B parameter model 16 times. Do this slowly, and weight synchronization becomes your bottleneck. Do this wrong, and you corrupt checkpoints or run out of memory.
This is where TorchStore comes in.
TorchStore: Data Plane
When faced with the weight-sync challenge, developers generally have two reasonable options:
1. Design a system that solves for resharding via a web of interconnected p2p operations.
- This approach requires managing a complex network of distributed collectives, which is not only tedious but also hard to generalize. Additionally, users must also manage additional checkpoint copies in memory at once in the case of off policy training, while simultaneously accounting for different distributed topologies with a finite amount of DRAM/VRAM.
2. Use a combination of a distributed checkpointer (dcp), and a Network Filesystem.
- The UX here is the best case scenario – users can just call “save” and “load”, and not concern themselves with the particulars of transportation or with resharding across different distributed topologies, since this is largely handed off to NFS. In practice, network filesystems are not generally designed to be used as transport buffers, and there is both a large associated infrastructure cost and performance bottlenecks associated with this approach.
Torchstore was born from this simple observation – we should be able to combine the UX of utilizing central storage (such as NFS), and the performance of in-memory p2p operations. Given the advent of Monarch, we also now have the right primitives to design such a system.
To be specific – TorchStore is a distributed, in-memory key-value store optimized for PyTorch tensors built on top of Monarch primitives. Torchstore seeks to provide users the following qualities:
- Best possible UX for this niche, utilizing simple DTensor based APIs
- Best possible performance, limited as closely as possible to hardware costs
- Completely flexible storage arrangement. Store your tensors however you’d like – co-located with your trainers/generators, on their own storage tier, sharded/non-sharded – and change your mind with minimal code changes.
Here it is in action:
import torchstore as ts from torch.distributed._tensor import distribute_tensor, Replicate, Shard from torch.distributed.device_mesh import init_device_mesh async def place_dtensor_in_store(): device_mesh = init_device_mesh("cpu", (4,), ...) tensor = torch.arange(4) dtensor = distribute_tensor( tensor, device_mesh, placements=[Shard(1)] ) # Stores this rank's 'shard' of the dtensor await ts.put("my_tensor", dtensor) async def fetch_dtensor_from_store() device_mesh = init_device_mesh("cpu", (2,2), ...) tensor = torch.rand(4) dtensor = distribute_tensor( tensor, device_mesh, placements=[Replicate(), Shard(0)] ) # Uses the local dtensor information to fetch the correct inplace await ts.get("my_tensor", dtensor) if __name__ == "__main__": ts.initialize() run_in_parallel(place_dtensor_in_store, world_size=4) run_in_parallel(fetch_dtensor_from_store, world_size=4) ts.shutdown()
In practice, torchforge immediately gains two large advantages in the TorchStore integration. Native DTensor support means regardless of weight sharding on the trainer side, any arbitrary tensor slice can be requested during generation – encapsulating a large part of resharding and avoiding the need for a bespoke integration in torchforge. Additionally, the integration takes advantage of the large amount of CPU ram available to store copies of weights, allowing GPUs to keep running uninterrupted. This allows us to completely decouple training and generation, removing the need for a costly trainer/generator synchronization during the training loop – an important step towards completely asynchronous workloads.
TorchStore’s generic support for distributed storage also makes it a prime candidate for a host of other use cases in the data plane for RL. For example, future optimizations could take advantage of Torchstore primitives to implement different replay strategies for generator outputs, or as part of larger fault tolerant solutions.
The RL Stack: Proven Components, Simple Coordination
Torchforge made a conscious decision not to reinvent the wheel. We don’t build our own inference engine or training framework – there are already excellent, battle-tested solutions for these problems.
One lens to view torchforge is as an efficient composition of proven components. vLLM handles high-throughput inference. torchtitan manages scalable training. Custom environments execute code or interact with tools. These components bring efficiency, scalability, and proven performance.
Torchforge’s role is coordination: making these components work together seamlessly so you can express your RL algorithm naturally. The components handle the heavy lifting. Torchforge handles the orchestration, and your RL code stays clean.
Integrating vLLM and TorchTitan
Torchforge currently integrates vLLM for inference and TorchTitan for training. These integrations are evolving – we’re working towards cleaner boundaries and upstream contributions to make Monarch support native in these frameworks.
vLLM for inference provides PagedAttention, continuous batching, and proven throughput at scale. We integrate directly with vLLM’s engine, giving you access to customize generation strategies, memory management, or inference logic as your research demands.
TorchTitan for training, brings production-grade training infrastructure – FSDP, pipeline parallelism, tensor parallelism, and optimizations proven at scale. The integration provides direct access to training step logic and sharding strategies, enabling experimentation without framework constraints.
Today, these integrations give you direct access to component code. This is both a feature (you can customize deeply) and a work-in-progress (we’re refining the patterns). As we stabilize these integrations, we’ll share best practices for building custom components.
The key insight remains – torchforge coordinates components at the logical level. Whether they’re proven frameworks like vLLM and TorchTitan, or custom implementations you build yourself, torchforge handles the orchestrations so you can focus on your RL algorithm.
Extensible Environments
RL often requires interacting with environments beyond just text generation – executing code, using tools, running simulations. Torchforge makes these environments first-class citizens through the same service abstraction.
Our first environment integration is sandboxed code execution. For RL on coding tasks, you need to safely execute generated code and evaluate the results:
# Lightweight CPU-only service for parallel execution coder = SandboxedPythonCoder.options( procs=1, with_gpus=False, num_replicas=16 ).as_service()
Then in your RL code:
async def generate_episode(): prompt = await dataloader.sample.route() code = await policy.generate.route(prompt) stdout, stderr = await coder.execute.route(code) reward = stderr == "" # e.g., 1 if the code ran successfully await replay_buffer.add.route(Episode(...))
Services make environments ephemeral – spawn them with your job, scale them independently, teardown when finished. The same coordinate primitives for services work for environments just as they do for policy and reward models.
Towards Agentic Workflows
These extensible environments are a foundational step towards agentic RL workflows. Agents need to interact with tools, execute code, query APIs, and navigate complex environments, all while learning from outcomes.
The coding environment demonstrates the pattern: wrap a Python component in an actor, turn it into a service, and it composes naturally with your RL stack. This same approach extends to other environment types – including emerging frameworks like HuggingFace’s Open Environments for standardized tool and environment interfaces.
This is just the starting point. As RL moves toward more agentic capabilities, we’re excited to collaborate with the community on building the next generation of environment integrations. If you’re working on agents, tools, or interactive environments, we’d love to hear from you.
Partnership / Validation Story
We’re grateful to our collaborators at the Stanford Scaling Intelligence Lab and Coreweave for their invaluable support in this project. Stanford’s team integrated their weak verifier project, Weaver, enabling torchforge to train models that hill climb on challenging reasoning benchmarks such as MATH and GPQA. We also extend our thanks to CoreWeave, who provided a robust 512 H100 GPU cluster for our large-scale training runs—delivering a smooth and efficient experience that made this level of experimentation possible.
Next Steps
Torchforge is at the beginning of its journey. We’ve built the foundation – composable primitives, clean APIs and integration of proven components – but there’s much more to do.
Smoothing sharp edges: Early adopters will hit rough patches – incomplete documentation, unclear error messages, API inconsistencies. We’re committed to rapid iteration based on feedback from real usage.
Expanding environment support: The coding sandbox is our first environment integration. We’re collaborating with HuggingFace and Prime Intellect on the Open Environments initiative to standardize tool and environment interfaces, making it easier to plug diverse environments into RL training workflows.
Scaling to Mixture-of-Experts: Current work focuses on dense models, but torchforge was designed with supporting large-scale MoE models in mind. We’re continuing to work on scaling torchforge up and improving upon its performance.
If you’re building RL systems and the infrastructure complexity is getting in the way of your research, try torchforge. If you hit issues, tell us. If you want to integrate a new component or environment, let’s figure it out together. The framework gets better as more people use it, break it, and help shape it.
Get started at our GitHub page.
Acknowledgments
Thank you to the whole torchforge team for making this work possible including:
Alanna Burke, Allen Wang, Evan Smothers, Lucas Pasqualin, Davide Testuggine, Philip Bontrager, Jafar Taghiyar, Alireza Shamsoshoara, Calvin Pelletier, Daniel Vega-Myhre, Danielle Pintz, Danning Xie, Davide Italiano, Evan Smothers, Felipe Melle, Gayathri Aiyer, Hamid Shojanazeri, Hossein Kavianhamedani, Howard Huang, Jack Khuu, James Sun, Jana van Greunen, Jeffery Wan, Jiani Wang, Jennifer Wang, Joe Cummings, John Myles White, Kai Li, Kai Wu, Kiuk Chung, Mathias Reso, Michael Suo, Pradeep Fernando, Rithesh Baradi, Sanyam Bhutani, Saurabh Mishra, Svetlana Karslioglu, Tianyu Liu, Victoria Dudin, Vidhya Venkat, Yunlu Li, Yuxuan Hu, Joe Spisak
And a very big thank you to our collaborators at Stanford and Coreweave:
- Stanford: Azalia Mirhoseini, Jon Saad-Falcon, Aakanksha Chowdhery, Hangoo Kang, Bradley Brown, Simon Guo
- Coreweave: Urvashi Chowdhary, Deok Filho, Aaron Batilo, Matthew Lu, Tara Madhyastha, Ravi Solanki, Susanne Seitinger