
We are thrilled to introduce depyf, a new project to the PyTorch ecosystem designed to help users understand, learn, and adapt to torch.compile!
Motivation
torch.compile is a cornerstone of PyTorch 2.x, offering a straightforward path to accelerate machine learning workflows with just a single line of code for both training and inference. The mere inclusion of @torch.compile can dramatically enhance the performance of your code. However, identifying the optimal insertion point for torch.compile is not easy, not to mention the complexity of adjusting various knobs for maximum efficiency.
The intricacies of the torch.compile stack, encompassing Dynamo, AOTAutograd, Inductor, and more, present a steep learning curve. These components, essential for deep learning performance optimization, can be daunting without a solid foundation in the subject.
Note: For an introductory example of how torch.compile works, please refer to this walk-through explanation.
A common tool: TORCH_COMPILE_DEBUG
To demystify torch.compile, the common approach involves leveraging the TORCH_COMPILE_DEBUG environment variable. While it provides more information, deciphering the output remains a formidable task.
For example, when we have the following code:
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
main()
And run it with TORCH_COMPILE_DEBUG=1 python test.py , we will get a directory named torch_compile_debug/run_2024_02_05_23_02_45_552124-pid_9520 , under which there are these files:
.
├── torchdynamo
│ └── debug.log
└── torchinductor
├── aot_model___0_debug.log
├── aot_model___10_debug.log
├── aot_model___11_debug.log
├── model__4_inference_10.1
│ ├── fx_graph_readable.py
│ ├── fx_graph_runnable.py
│ ├── fx_graph_transformed.py
│ ├── ir_post_fusion.txt
│ ├── ir_pre_fusion.txt
│ └── output_code.py
├── model__5_inference_11.2
│ ├── fx_graph_readable.py
│ ├── fx_graph_runnable.py
│ ├── fx_graph_transformed.py
│ ├── ir_post_fusion.txt
│ ├── ir_pre_fusion.txt
│ └── output_code.py
└── model___9.0
├── fx_graph_readable.py
├── fx_graph_runnable.py
├── fx_graph_transformed.py
├── ir_post_fusion.txt
├── ir_pre_fusion.txt
└── output_code.py
The generated files and logs often raise more questions than they answer, leaving developers puzzled over the meaning and relationships within the data. Common puzzles for TORCH_COMPILE_DEBUG include:
- What does
model__4_inference_10.1mean? - I have one function but three
model__xxx.pyin the directory, what is their correspondence? - What are those
LOAD_GLOBALstuff indebug.log?
A better tool: depyf comes to rescue
Let’s see how depyf can help developers to resolve the above challenges. To use depyf , simply execute pip install depyf or follow the project page https://github.com/thuml/depyf to install the latest version, and then surround the main code within with depyf.prepare_debug .
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
import depyf
with depyf.prepare_debug("depyf_debug_dir"):
main()
After executing python test.py , depyf will produce a directory named depyf_debug_dir (the argument of the prepare_debug function). Under the directory, there would be these files:
.
├── __compiled_fn_0 AFTER POST GRAD 0.py
├── __compiled_fn_0 Captured Graph 0.py
├── __compiled_fn_0 Forward graph 0.py
├── __compiled_fn_0 kernel 0.py
├── __compiled_fn_3 AFTER POST GRAD 0.py
├── __compiled_fn_3 Captured Graph 0.py
├── __compiled_fn_3 Forward graph 0.py
├── __compiled_fn_3 kernel 0.py
├── __compiled_fn_4 AFTER POST GRAD 0.py
├── __compiled_fn_4 Captured Graph 0.py
├── __compiled_fn_4 Forward graph 0.py
├── __compiled_fn_4 kernel 0.py
├── __transformed_code_0_for_torch_dynamo_resume_in_toy_example_at_8.py
├── __transformed_code_0_for_toy_example.py
├── __transformed_code_1_for_torch_dynamo_resume_in_toy_example_at_8.py
└── full_code_for_toy_example_0.py
And there are two obvious benefits:
- The long and difficult-to-understand
torchdynamo/debug.logis gone. Its content is cleaned up and shown as human-readable source code, infull_code_for_xxx.pyand__transformed_code_{n}_for_xxx.py. It is worth to note, that the most tedious and difficult job ofdepyfis to decompile the bytecode insidetorchdynamo/debug.loginto Python source code, freeing developers from intimidating internals of Python. - The correspondence between function names and computation graphs are respected. For example, in
__transformed_code_0_for_toy_example.py, we can see a function named__compiled_fn_0, and we will immediately know its corresponding computation graphs are in__compiled_fn_0_xxx.py, because they share the same__compiled_fn_0prefix name.
Starting with full_code_for_xxx.py , and following the functions involved, users will have a clear view of what torch.compile does to their code.
One more thing: step-through debuggability
Stepping through code line by line using debuggers is a great way to understand how code works. However, under TORCH_COMPILE_DEBUG , those files are only for users’ information, and cannot be executed with the data users concern.
Note: By “debug”, we mean the process of inspecting and improving a program, rather than correcting buggy code.
A standout feature of depyf is its capability to facilitate step-through debugging for torch.compile: all of the files it generates are linked with runtime code objects inside Python interpreter, and we can set breakpoints in these files. The usage is simple, just add one context manager with depyf.debug() , and it should do the trick:
# test.py
import torch
from torch import _dynamo as torchdynamo
from typing import List
@torch.compile
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
def main():
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
if __name__ == "__main__":
import depyf
with depyf.prepare_debug("depyf_debug_dir"):
main()
with depyf.debug():
main()
Just one caveat: the workflow of debugging torch.compile deviates from standard debugging workflow. With torch.compile, many codes are dynamically generated. Therefore, we need to:
- launch the program
- when the program exits
with depyf.prepare_debug("depyf_debug_dir"), code will be available indepyf_debug_dir. - when the program enters
with depyf.debug(), it will automatically set a breakpoint internally, so that the program is paused. - navigate to
depyf_debug_dirto set breakpoints. - continue to run the code, and debuggers will hit these breakpoints!
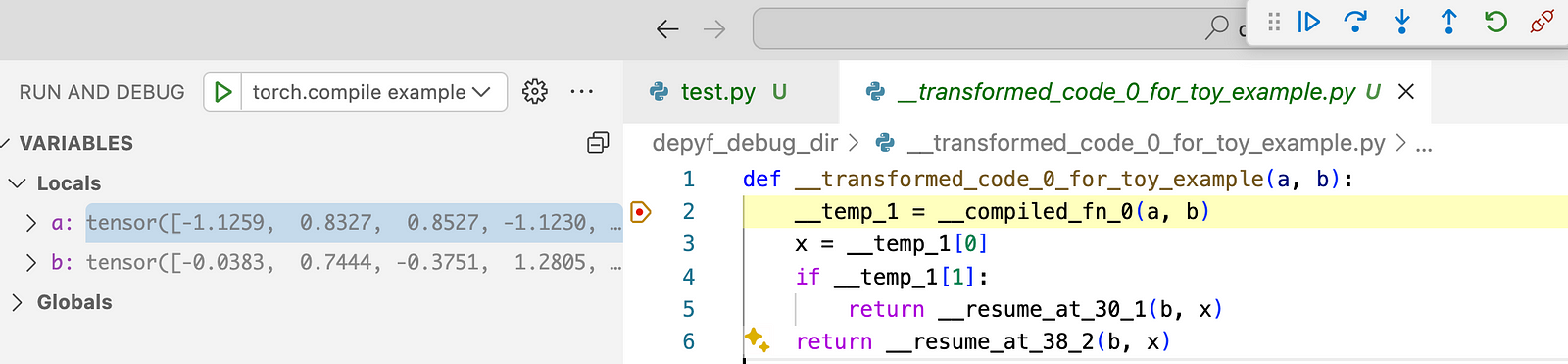
Here is a screenshot of what it looks like. All code and tensor variables are live, and we can inspect any variable, and step through the code, as in our daily debugging workflow now! The only difference is that we are debugging torch.compile generated code rather than human-written code.
Conclusion
torch.compile serves as an invaluable tool for accelerating PyTorch code effortlessly. For those looking to delve deeper into torch.compile, whether to leverage its full potential or to integrate custom operations, the learning curve can be very steep though. depyf is designed to lower this barrier, offering a user-friendly experience to understand, learn, and adapt to torch.compile.
Do explore depyf and experience its benefits firsthand! The project is open-source and readily available at https://github.com/thuml/depyf. Installation is straightforward via pip install depyf. We hope depyf can enhance everyone’s development workflow with torch.compile.