Introduction
Hybrid models that combine the capabilities of full attention layers with alternatives—such as Mamba or linear attention—have gained more and more traction, especially in long-context large language model (LLM) serving scenarios. By leveraging linear attention, the KV cache memory consumption per request is bounded to a constant, and prefill latency can scale linearly with input length. This characteristic aligns well with real-world workloads, such as those in RAG queries, agentic tools, and thinking/reasoning patterns.
However, the in-place state updates preclude the ability to roll back cache entries for partial sequence matches, which complicates the implementation of many widely adopted features, such as prefix caching and speculative decoding. The request-level state storage required by Mamba states also imposes new challenges and demands on memory management and PD (prefill-decode) disaggregation.
This article discusses how SGLang has adapted to and optimized for the aforementioned challenges.
What are State Space Models?
State space models (SSMs), and more generally linear RNNs and linear attention, such as Mamba, selectively compress tokens and context into a recurrent state. This recurrent state is of fixed size and is updated in place. By utilizing SSMs, memory consumption can be maintained at a constant level, and computational complexity scales linearly with sequence length, rather than quadratically. However, the purely linear structure is inherently limited by finite-state capacity, posing challenges for handling long-context or achieving strong recall capabilities.
To achieve a trade-off between efficiency and capacity, hybrid models have been proposed. These models interleave quadratic Attention layers with SSM layers at fixed intervals. As a result, hybrid models achieve strong performance across various tasks while preserving most of the efficiency advantages offered by SSM layers.
| Attention | SSM | |
| Computational Complexity | O(N^2) | O(N) |
| Memory Consumption | O(N) | O(1) |
Memory Management
Design of Hybrid State Management
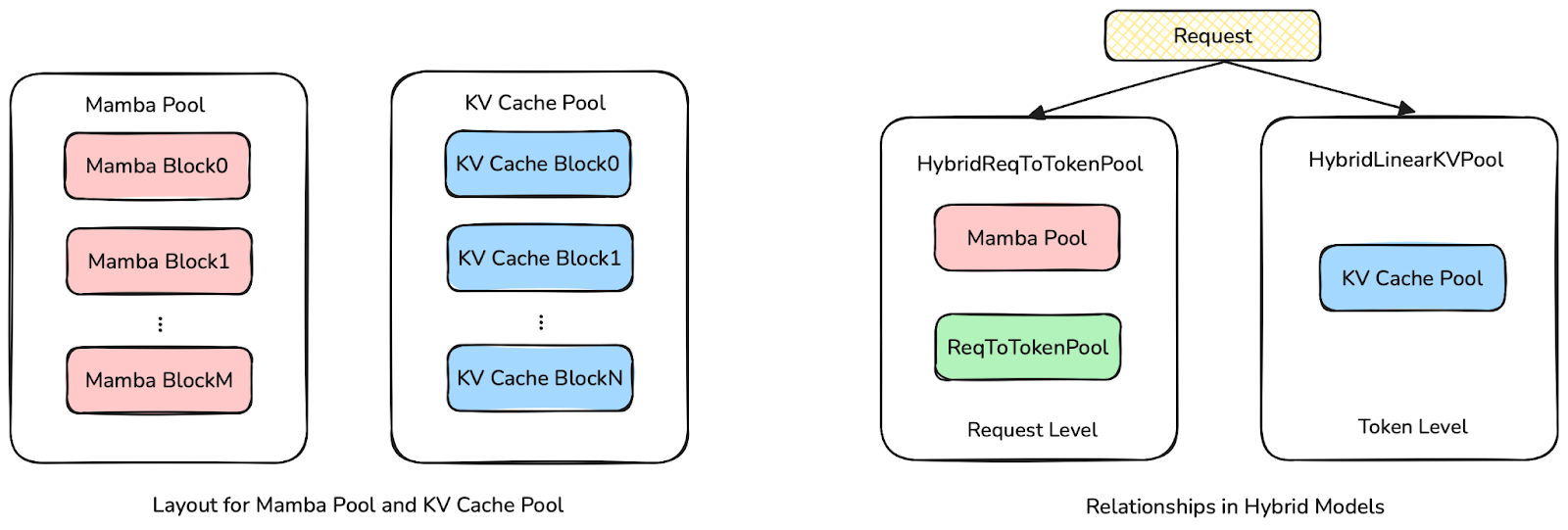
In SGLang, hybrid linear models separate the memory pool into two parts: Mamba pool and KV cache pool. Both Mamba pool and KV cache pool memory sizes are fixed, hence the risk of CUDA out-of-memory errors is eliminated. Users can adjust the size ratio between Mamba pool and KV cache pool by changing server argument –mamba-full-memory-ratio according to workload.
The main difference between Mamba pool and KV cache pool is that the former allocates Mamba state at the request level and the latter allocates at the token level. We use HybridReqToTokenPool to bind a Mamba state and a request so that the lifespan of requests and Mamba states are aligned. In addition, we use HybridLinearKVPool to map logical layer id to actual layer index in KV cache pool, so we do not need to allocate KV cache in linear layers, and memory size can be largely saved.
Elastic Memory Pool
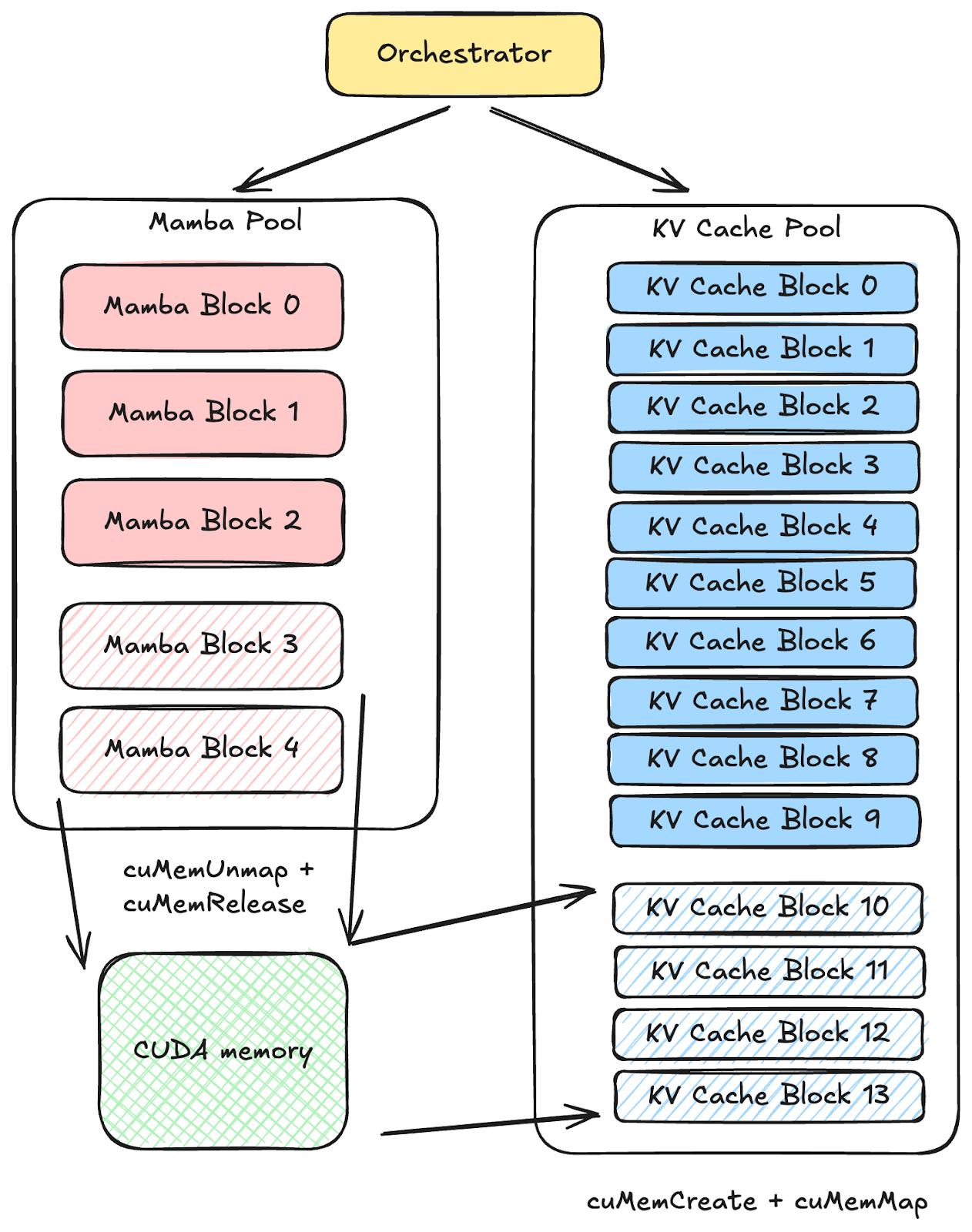
Hybrid models integrate diverse attention types, each maintaining its own memory pool with a dedicated allocator for GPU memory management. To maximize memory utilization and optimize inference performance, the ratios between memory pools must be configured according to workload characteristics. However, manually setting these ratios is nontrivial, and fluctuating workloads may render predefined ratios suboptimal during runtime. To address this, we propose an elastic memory pool that dynamically adjusts pool sizes under a fixed total GPU memory budget.
The elastic memory pool comprises resizable tensors and a centralized control module:
Resizable Tensors via CUDA Virtual Memory Management:
- A virtual address space is pre-allocated with oversubscribed capacity. A torch.Tensor is created within this space and reshaped to match the KV cache requirements.
- To expand a memory pool, physical CUDA memory pages are mapped to the appropriate virtual addresses, activating the corresponding KV cache blocks.
- To shrink a pool, idle KV cache blocks are disabled, and their physical pages are unmapped to free memory.
Centralized Control Module:
- During initialization, all memory pools register with the control module.
- At runtime, if a memory pool exhausts its capacity, it requests expansion. The control module identifies the most underutilized pool, issues a shrink command, and authorizes the requester to expand upon successful shrinkage.
With the Elastic Memory Pool in place, the system can dynamically adjust the allocation ratio between the Mamba pool and the KV Cache pool based on workload demands, maximizing GPU memory utilization to enable larger-batch inference.
Optimizations and Adaptions
Prefix Caching
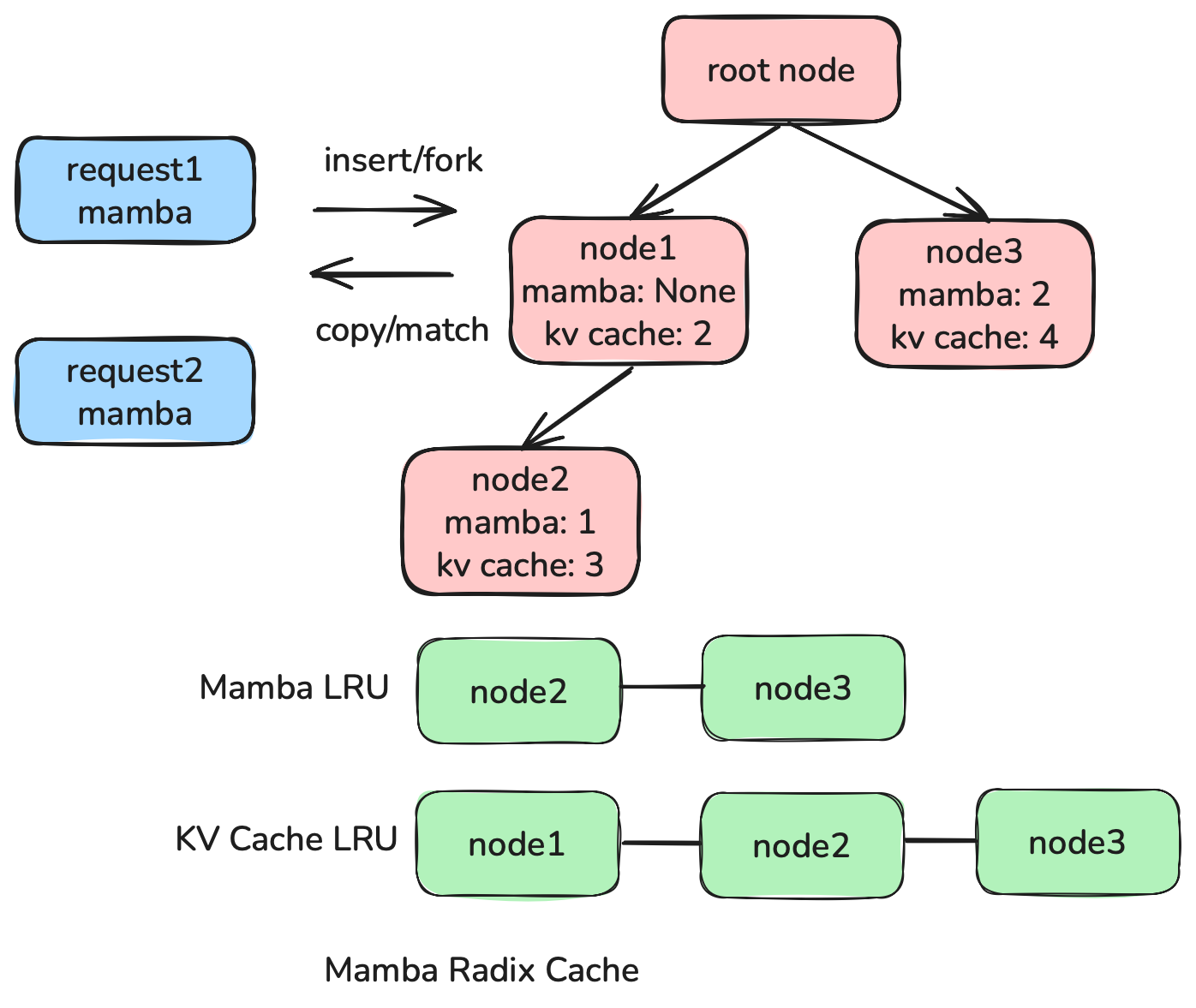
Prefix caching is a widely used optimization method in full attention models, which can save redundant computations across requests. However, the following properties about Mamba state make the prefix cache complicated: 1) SSM states are updated in-place, so a request’s states cannot be rolled back to represent its prefixes. 2) SSM states are orders of magnitude larger than the KVs of a single token. 3) Most of SSM states’ forward kernels exhibit “all or nothing” reusability.
SGLang supports prefix cache for hybrid linear models by implementing a hybrid radix tree named MambaRadixCache. It mainly separates match / insert / evict parts:
- match: MambaRadixCache will return the best node where Mamba state value is not None and the key is the prefix of input. It needs to copy the Mamba state from the radix tree.
- insert: KV cache and Mamba states will be inserted into MambaRadixCache after chunked prefill or decoding stages. It needs to fork a checkpoint of Mamba state from a request.
- evict: MambaRadixCache keeps two LRU lists to maintain Mamba states and KV cache timestamps individually. KV cache must be evicted from leaves to root node and Mamba states can be evicted from any node.
By integrating MambaRadixCache, hybrid linear models can use prefix caching without modifying linear attention kernels.
Speculative Decoding
For simplicity, we illustrate everything using the most basic linear-attention update,
Sₜ = Sₜ₋₁ + vₜ kₜᵀ,
to keep the blog easy to follow. In real systems, the update is a bit more complex.
Why does standard speculative decoding not work for SSMs?
- SSM states update in-place, so rejected tokens cannot be rolled back.
- The Eagle-Tree attention mask is incompatible with how SSM states are maintained.
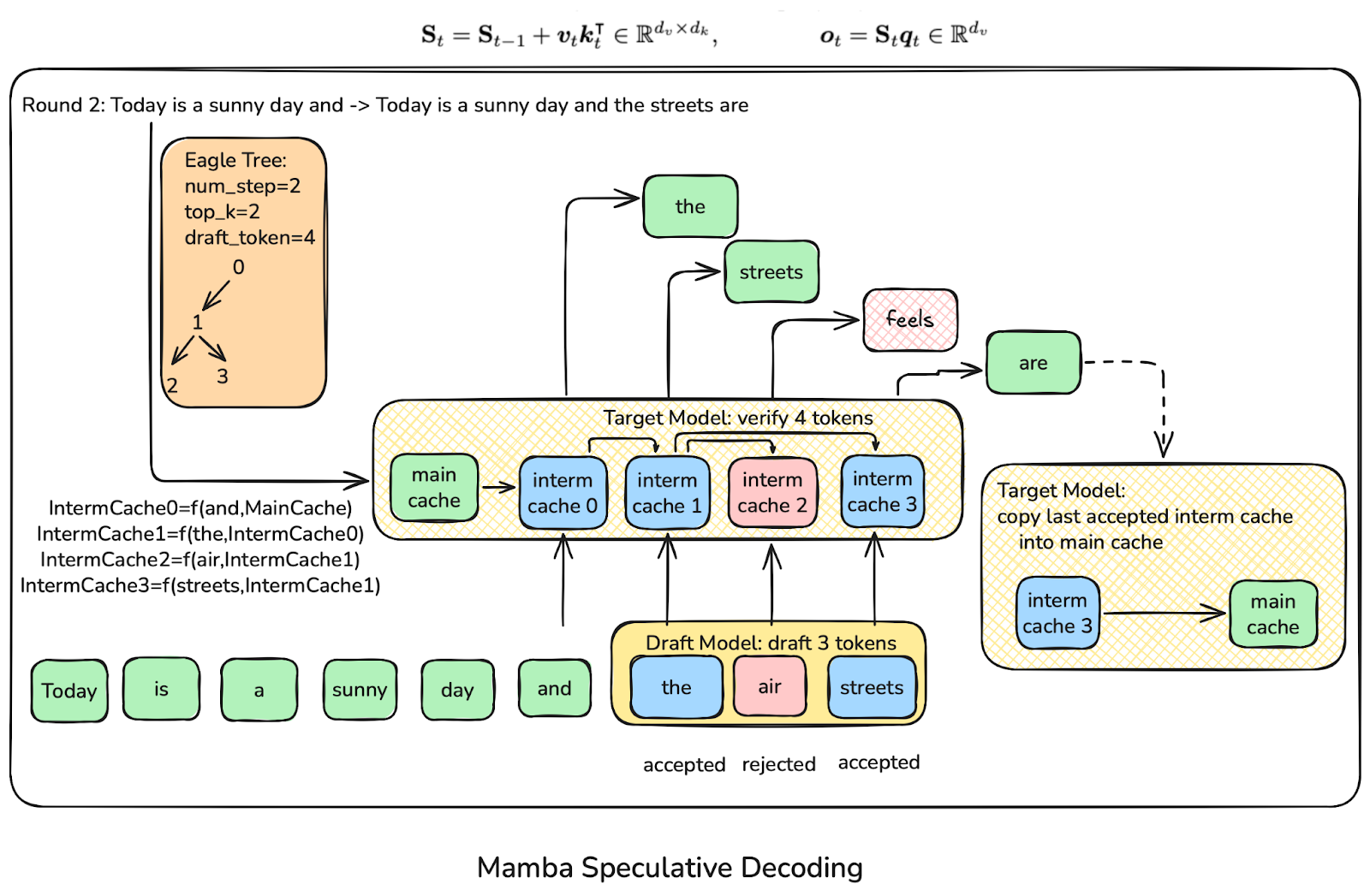
SGLang’s solution: one independent Mamba cache slot per draft token
- Each draft token receives a private cache slot with its own SSM state
- “the” → slot 1
- “air” → slot 2
- “streets” → slot 3
- When a sequence of draft tokens is accepted, simply promote the last accepted slot to become the new main state.
(Example: after accepting “the streets are”, slot 3 becomes the main SSM state.)
EAGLE-Tree with Top-K > 1
- Precompute parent indices before verification.
- For each drafted token:
- Trace its parent using these indices.
- Apply the recurrent update Snew = Sparent + vnew knewᵀ
Prefill and Decode disaggregation
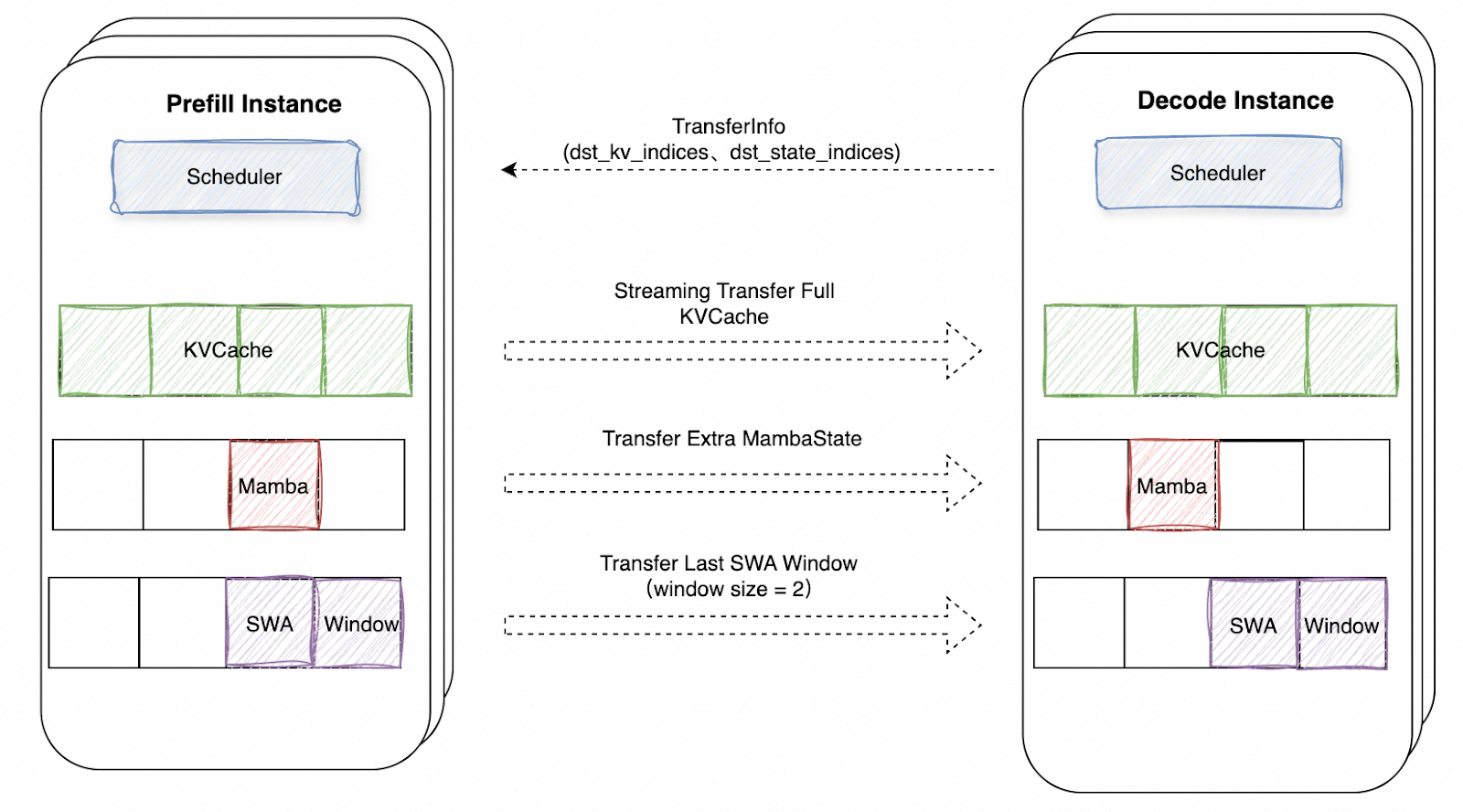
SGLang’s PD-disaggregation architecture supports hybrid models by extending the transfer protocol with a dedicated state transfer channel. Beyond standard paged KV cache transfers, the system transmits model-specific states (e.g., Mamba conv/temporal states, SWA sliding windows) through a parallel data path.
Mamba Integration Details:
- Mamba models maintain two separate memory pools: a paged KV pool for full attention layers and a Mamba pool for linear layers storing conv and temporal states.
- When a new request arrives, it first undergoes prefix matching via the MambaRadixTree. If a cache hit occurs, the matched MambaState is copied into a new Mamba memory region to serve as the current request’s Mamba buffer, where the prefill inference continues to proceed. Upon prefill completion, the prefill instance transfers the final Mamba state as a single contiguous block to the decode instance, using the ‘dst_state_indices’ to identify the destination slot. Unlike paged KV transfers that can be streamed incrementally, Mamba states are transmitted atomically.
- The decode instance pre-allocates both KV page slots and a dedicated Mamba slot, ensuring the received states are stored in the correct memory location for subsequent decode steps.
To integrate a new hybrid pool for disaggregated serving, only three steps are required upon current PD implementation:
- expose state buffer pointers, sizes, and item lengths for transfer registration;
- define state_indices preparation logic in both prefill and decode workers to specify which pool slots to transfer—this can be a single index per request (e.g., Mamba), page indices for windowed data (e.g., SWA), or full sequence indices (e.g., NSA);
- register a unique state_type identifier in the KV manager and add corresponding transfer handling in the backend.
Benchmark
Benchmarks were performed in SGLang v0.5.5, the latest released version. The server ran on H200 GPUs with Qwen3-Next-80B-A3B-Instruct-FP8.
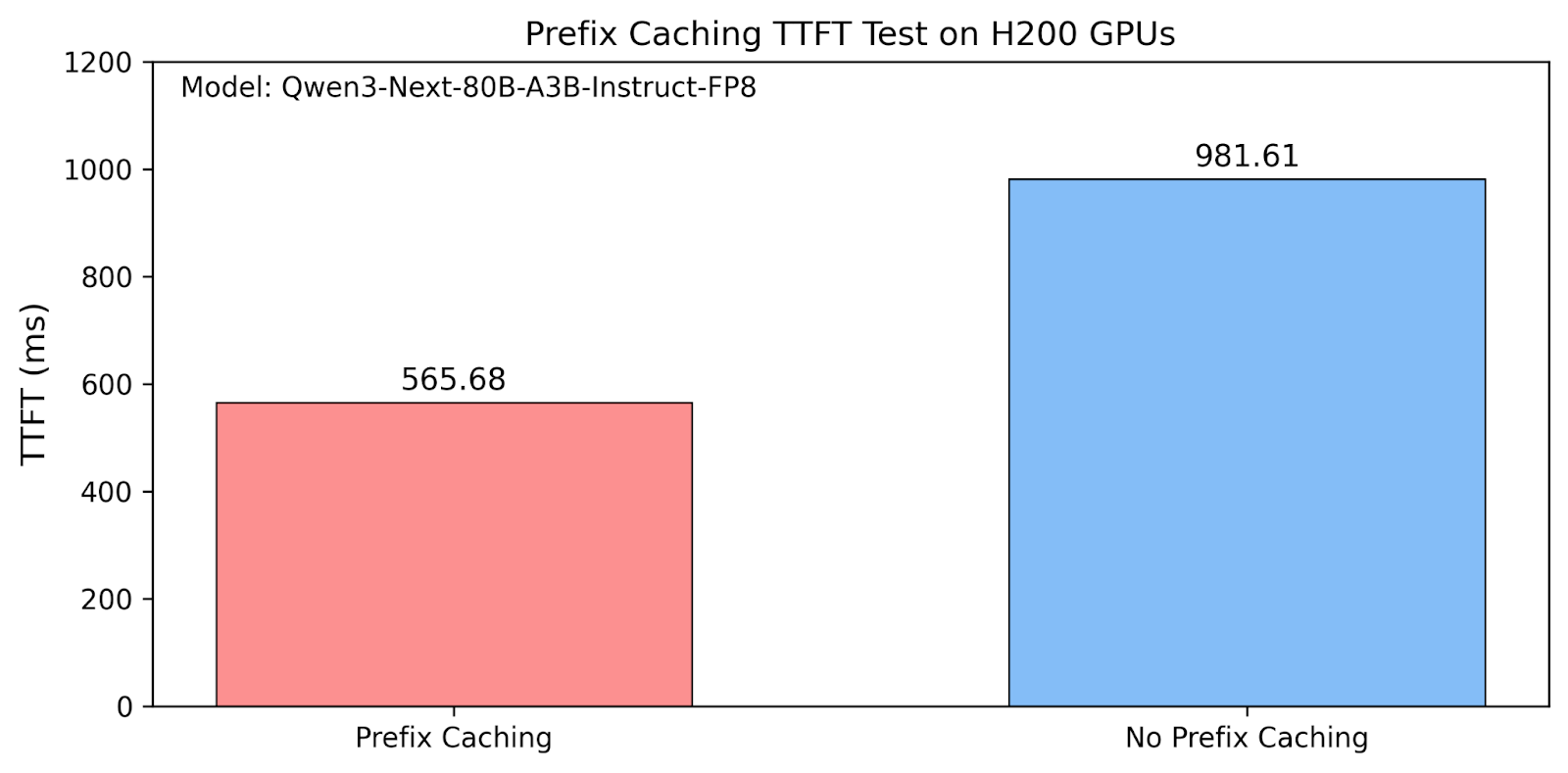
Prefix Caching
python3 -m sglang.launch_server --model Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 –tp 2 python3 -m sglang.bench_serving --backend sglang \ --dataset-name generated-shared-prefix \ --gsp-num-groups 50 \ --gsp-prompts-per-group 10 \ --gsp-system-prompt-len 10240 \ --gsp-question-len 256 \ --gsp-output-len 128 \ --max-concurrency 5 --port 30000
Speculative Decoding
python3 -m sglang.launch_server –model Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 –tp 2 –disable-radix-cache –speculative-num-steps 2 –speculative-eagle-topk 1 –speculative-num-draft-tokens 3 –speculative-algo EAGLE
python3 -m sglang.test.send_one
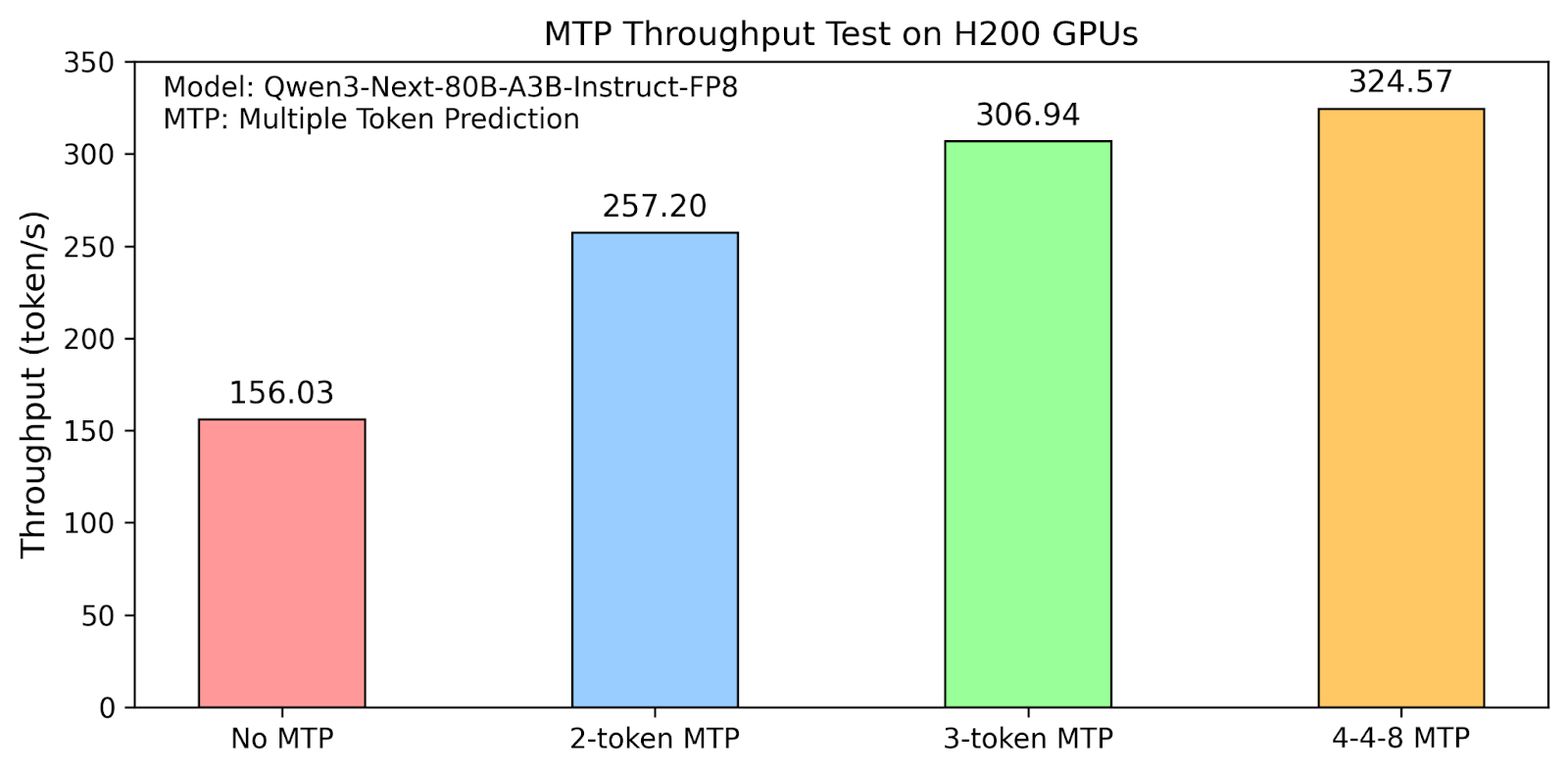
We tested Qwen3-Next-80B-A3B-Instruct-FP8 performance with batch size = 1.With a 2-token MTP window and topk=1, the system achieves a throughput of 257.20 tokens/sec, with an average acceptance length of 2.709 tokens.
With a 3-token MTP window and topk=1, throughput increases to 306.94 tokens/sec, with an average acceptance length of 3.413 tokens.
With a 4-token MTP window and topk=4 and draft tokens=8, throughput increases to 324.57 tokens/sec, with an average acceptance length of 4.231 tokens.
Future Work
Feature work can be tracked here. More specifically, we plan to:
- More general prefix caching: including support page size > 1, speculative decoding and other features.
- Integrate into Hicache: fast hierarchical KV caching is an important feature for SGLang. We need to develop new query, storage and schedule mechanisms for KV cache in linear attention layers.
- Deterministic inference adaption: we hope to make adaptations for hybrid linear models to support bitwise training-inference consistency.
Acknowledgement
SGLang Team: Yi Zhang, Biao He, Binyao Jiang, Ke Bao, Qingquan Song, Hanming Lu, Shangming Cai, Zhangheng Huang, Sicheng Pan, Baizhou Zhang