We are excited to announce the addition of embedding operators with low-bit weights (1-8 bit) and linear operators with 8-bit dynamically quantized activations and low-bit weights (1-8 bit) for Arm CPUs in TorchAO, PyTorch’s native low-precision library. These operators work seamlessly across all PyTorch surfaces, including eager, torch.compile, AOTI, and ExecuTorch, and are available to use in torchchat.
In developing these linear operators, our focus was on code sharing between PyTorch and ExecuTorch, and establishing a clear boundary between the higher-level operator and the lower-level kernel. This design allows third-party vendors to easily swap in their own kernels. We also set out to create a place and infrastructure to experiment with new CPU quantization ideas and test those across the PyTorch ecosystem.
Universal low-bit kernels
There is no hardware support for low-bit arithmetic. In what we call universal kernels, we explicitly separated the logic that unpacks low-bit values to int8 values, and the int8 GEMV kernel logic in a modular fashion. We started with an 8-bit kernel, for example, this 1×8 8-bit GEMV kernel that uses the Arm neondot instruction. Within the 8-bit kernel, we invoke an inlined unpacking routine to convert low-bit values into int8 values. This unpacking routine is force-inlined and templated on some low-bit value. Our experiments showed no performance difference between using a separate force-inlined unpacking routine and directly embedding the unpacking code inline.
The advantage of this modular design is improved development speed and code maintainability. After writing an 8-bit kernel, we quickly achieved full low-bit coverage by writing simple bitpacking routines. In fact, developers who worked on the bit packing routines did not need to be experts on GEMV/GEMM kernel writing. We also reused the same bitpacking routines from the linear kernels within the embedding kernels. In future we could reuse the same bitpacking routines for universal GEMM kernels or kernels based on fma or i8mm instructions.
Shared code between PyTorch and ExecuTorch
To achieve shared code between PyTorch and ExecuTorch, we wrote kernels using raw pointers instead of PyTorch tensors. Moreover, we implemented the linear operator in a header that is included in separate PyTorch and ExecuTorch operator registration code. By using only features common to both ATen and ExecuTorch tensors, we ensured compatibility between the two frameworks. For multi-threaded compute, we introduced torchao::parallel_1d, which compiles to either at::parallel_for or ExecuTorch’s threadpool based on compile-time flags.
Swappable kernels
Our design for the higher-level multi-threaded linear operator is agnostic to the lower-level single-threaded kernels, allowing third-party vendors to swap in their own implementations. The interface between the operator and kernel is defined by a ukernel config, which specifies kernel function pointers for preparing activation data, preparing weight data, and running the kernel. The operator, responsible for tiling and scheduling, interacts with kernels solely through this config.
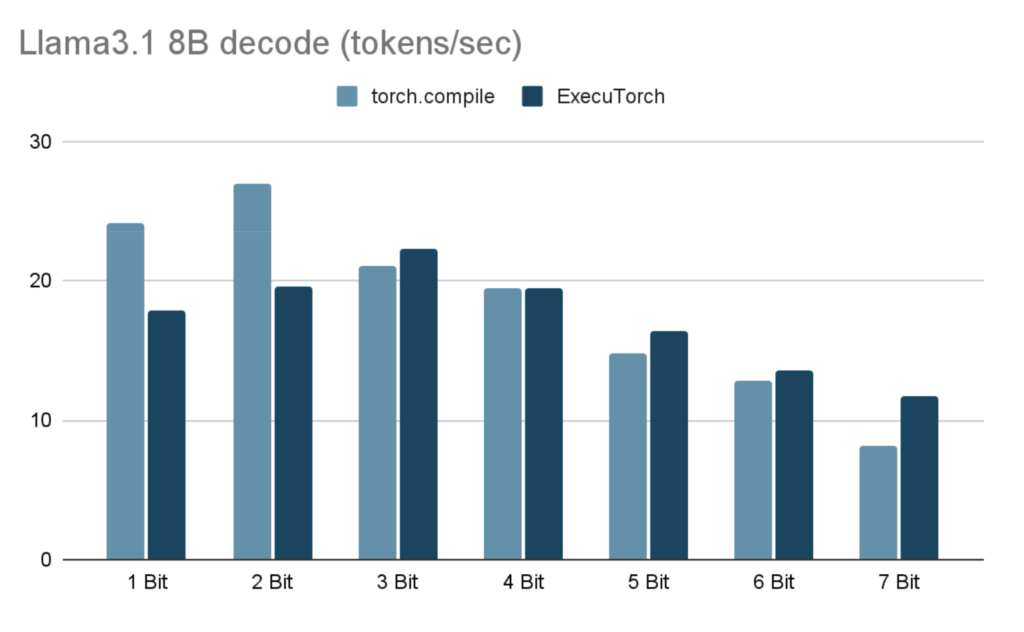
Performance
In the table below, we show Llama3.1 8B token generation performance using 6 CPU threads on an M1 Macbook Pro with 32GB of RAM.
| Bitwidth x | torch.compile (Decode tokens/sec) | ExecuTorch (Decode tokens/sec) | ExecuTorch PTE size (GiB) |
| 1 | 24.18 | 17.86 | 1.46 |
| 2 | 27.02 | 19.65 | 2.46 |
| 3 | 21.01 | 22.25 | 3.46 |
| 4 | 19.51 | 19.47 | 4.47 |
| 5 | 14.78 | 16.34 | 5.47 |
| 6 | 12.80 | 13.61 | 6.47 |
| 7 | 8.16 | 11.73 | 7.48 |
Results were run on an M1 Macbook Pro (with 8 perf cores, and 2 efficiency cores) with 32GB of RAM and 6 threads using torchchat. In each test, the max-seq-length of 128 tokens were generated. For each bit width x, the embedding layer was groupwise quantized to x-bits with group size 32. In the linear layers, activations were dynamically quantized per token to 8 bits and weights were groupwise quantized to x-bits with group size 256. Our focus here is performance and we do not report accuracy or perplexity numbers. Depending on the model, lower bit widths may require quantization-aware training, quantizing a model with a mixture of bit widths, or adjusting the group sizes for acceptable accuracy.
Try them out and contribute!
If you want to see the new low-bit kernels in action, give them a try by setting up torchchat and quantizing and running an LLM locally using the kernels.
If you want to help contribute, consider adding support for one of the following areas:
- Add universal low-bit GEMM kernels for Arm CPU, reusing the same bitpacking routines from the universal GEMV kernels.
- Improve runtime selection of ukernel configs based on ISA, packing format, and activation shape.
- Add low-bit kernels for other CPU ISAs like x86.
- Integrate third-party libraries like KleidiAI with the operator framework.