Introduction to Helion
In modern machine learning, the demand for high-performance computation has led to a proliferation of custom kernels. While these kernels can deliver impressive performance, they are often written in low-level, hardware-specific languages. This creates a long-term maintenance burden: A kernel meticulously optimized for one hardware architecture quickly becomes technical debt, difficult and costly to port to another. This challenge hinders development and innovation and forces developers to choose between productivity and performance.
Helion resolves this conflict by compiling a high-level Python-embedded domain-specific language (DSL) into automatically tuned Triton code. It establishes a new layer of abstraction that bridges the user-friendly simplicity of PyTorch with the performance of a lower level language. By automating tedious and error-prone tasks like tensor indexing, memory management, and hardware-specific tuning, Helion empowers developers to focus on algorithmic logic rather than hardware-specific implementation details. Helion achieves this balance by pairing a familiar, PyTorch-centric syntax with a powerful autotuning engine that automates the complex search for optimal kernel configurations. This results in a system that delivers performance portability across hardware architectures while drastically reducing development effort.
Motivation for a New DSL
Choosing the right abstraction level for kernel development is a strategic decision that directly impacts performance, maintainability, and the developer velocity. The current programming languages and abstractions force developers into a false dichotomy between low-level control and high-level productivity. Both ends of the spectrum come with advantages and drawbacks.
- CUDA/Gluon/TLX: Writing kernels directly in languages like CUDA offers maximum control but can require significant effort to achieve high performance. These kernels are highly specialized to specific hardware and can be difficult to adapt to new architectures.
- Triton: While Triton represents a major step forward, it still requires significant manual effort. Developers are responsible for explicitly managing tensor indexing, defining search spaces for autotuning, managing kernel arguments, and changing the optimization strategy can often require significant code rewrites.
- PyTorch: While frameworks like PyTorch and
torch.compileoffer exceptional ease of use, they provide limited fine-grained control. Users who need to specify exact fusion strategies often find the high-level abstraction too restrictive.
Helion Programming Model: “PyTorch with Tiles”
The goal of Helion’s programming model is to minimize boilerplate and leverage developers’ existing knowledge of PyTorch. This design philosophy accelerates the creation of correct, efficient kernels by providing a familiar and intuitive syntax, which can be described as “PyTorch with Tiles”.
A typical Helion kernel, such as the matrix multiplication example below, is composed of two distinct parts that work in concert:
import torch, helion, helion.language as hl @helion.kernel() def matmul(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor: # --- Host Code (runs on CPU) --- m, k = x.size() k, n = y.size() out = torch.empty([m, n], dtype=x.dtype, device=x.device) # --- Device Code (compiles to a Triton kernel) --- for tile_m, tile_n in hl.tile([m, n]): acc = hl.zeros([tile_m, tile_n], dtype=torch.float32) for tile_k in hl.tile(k): acc = torch.addmm(acc, x[tile_m, tile_k], y[tile_k, tile_n]) out[tile_m, tile_n] = acc return out
- Host Code: The code outside the outermost
hl.tilefor loop is standard PyTorch code. It is primarily used for setup tasks such as allocating output tensors and computing shapes. Helion automatically handles the passing of these values to the device code, eliminating the need for manual argument management. - Device Code: The code inside the outermost
hl.tilefor loop is the core of the kernel. This section is compiled into a single, high-performance Triton kernel that executes in parallel on a GPU.
The core language construct, hl.tile, subdivides the kernel’s iteration space into tiles. The programmer only specifies to tile the iteration space, and the specific implementation details, such as tile sizes, iteration order, and memory layout optimizations, are handled by Helion’s autotuner, which systematically explores the optimal configuration for the target hardware.
Within the kernel body, developers can use standard PyTorch operators like torch.addmm and other pointwise or reduction operations. Helion leverages TorchInductor, a core component of PyTorch 2, to automatically map these PyTorch calls to their corresponding low-level Triton implementations. This delivers a powerful usability benefit: Familiarity with PyTorch means you already know most of Helion.
Helion also includes templating capability that allows lambda functions, that may capture additional arguments in closures, to be passed in as arguments to a kernel. As shown in this example, this is particularly useful for implementing generic kernels with customizable epilogues. For instance, a lambda function can capture a tensor defined in the surrounding scope. Helion’s compiler automatically detects this variable and makes it into an argument in the generated Triton kernel. This eliminates a significant amount of boilerplate code to pass new inputs through multiple layers of function calls, enabling creation of highly reusable and generic kernels.
Helion makes kernel implementations radically simpler: the Attention kernel is just 30 lines in Helion, compared to 120 lines in Triton and thousands of lines in CUDA. This high-level, declarative programming model is made performant by the core mechanism that underpins the entire system: the autotuning engine.
Helion’s Autotuner: Generating Optimal Kernels via Implicit Search Spaces
Helion’s key differentiator is its automated, ahead-of-time (AOT) autotuning engine. In Triton, developers are responsible for manually defining the search space for optimizations. This requires explicitly enumerating every configuration to be tested, a tedious process that limits the scope of exploration.
Helion changes this dynamic with implicit search spaces. The high-level language automatically constructs a vast, multi-dimensional search space over implementation choices. For example, a single hl.tile call implicitly instructs the autotuner to explore different block sizes, loop orderings, and whether to flatten the iteration space into a single dimension. One Helion kernel definition thus maps to thousands of Triton configurations, allowing the autotuner to create a much larger and richer search space to discover a superior configuration.
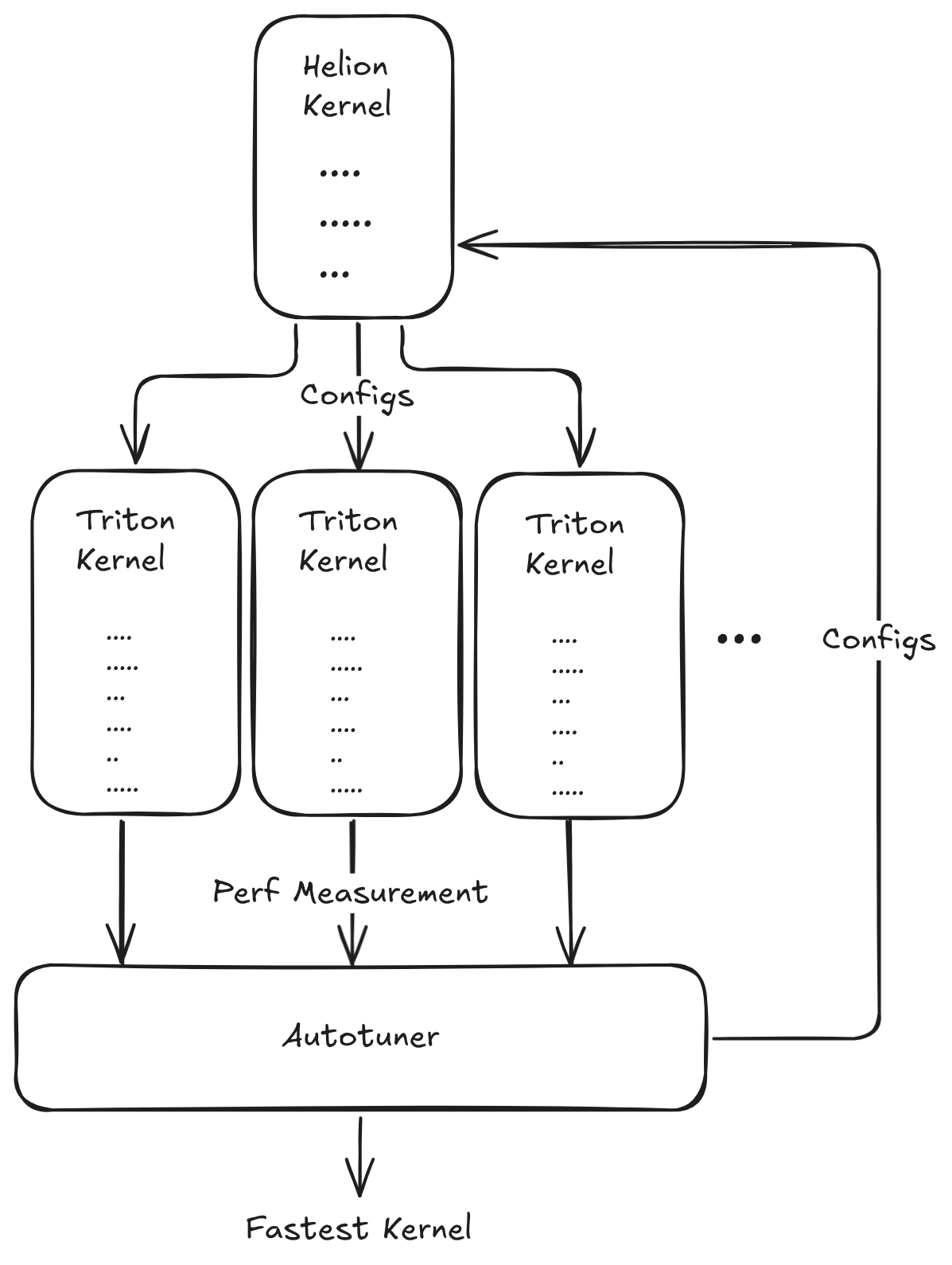
The Autotuning Workflow
When a kernel is run for the first time without a specified configuration, the autotuner initiates an automated search. This process, which typically takes around 10 minutes, evaluates thousands of candidate Triton kernel configurations using search strategies like Differential Evolution or Pattern Search to identify optimized sets of parameters for the given input shapes and hardware. Upon completion, the autotuner prints the single best configuration it discovered:
[586s] Autotuning complete in 586.6s after searching 1520 configs. One can hardcode the best config and skip autotuning with: @helion.kernel(config=helion.Config(block_sizes=[64, 64, 64], loop_orders=[[0, 1]], l2_groupings=[4], range_unroll_factors=[0, 1], range_warp_specializes=[None, False], range_num_stages=[0, 3], range_multi_buffers=[None, False], range_flattens=[None, None], num_warps=8, num_stages=6, indexing='block_ptr', pid_type='flat'))
The developer can copy this config into the @helion.kernel() decorator in their source code. This instructs Helion to bypass the search process entirely during subsequent runs. In a production environment, this results in fast, deterministic compilation that generates the single, pre-optimized Triton kernel, delivering performance equivalent to a meticulously hand-tuned kernel with far less effort.
@helion.kernel(config=helion.Config( block_sizes=[64, 64, 64], loop_orders=[[0, 1]], l2_groupings=[4], range_unroll_factors=[0, 1], range_warp_specializes=[None, False], range_num_stages=[0, 3], range_multi_buffers=[None, False], range_flattens=[None, None], num_warps=8, num_stages=6, indexing='block_ptr', pid_type='flat' )) def matmul(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor: ...
The developer can also specify a list of configs in@helion.kernel(), in which case Helion will explore only those configs to choose the fastest implementation.
The Configuration Space
The configuration space represents the set of implementation choices that Helion automates. This space is the primary source of Helion’s performance portability, as it allows a single kernel definition to be adapted to the unique characteristics of different hardware architectures and input tensor sizes. Exploring this space is what gives Helion its advantage over manually written kernels, which are often tuned for a specific set of conditions.
The autotuner explores a wide range of parameters that control everything from data movement to thread mapping. The table below details the configuration options.
| Parameter | Description | |
|
In Triton, a developer can choose between three distinct methods for memory access: pointer arithmetic, block pointers, and tensor descriptors, which leverage Tensor Memory Accelerators (TMAs) on NVIDIA Hopper/Blackwell GPUs. The optimal choice depends on the hardware architecture and memory access patterns, but switching between these methods requires significant code rewrite.
Helion abstracts this complexity with the |
|
|
The block_sizes parameter is a list of tile sizes for each dimension in an hl.tile loop that determines the amount of data each thread block processes. This affects register usage, shared memory requirements, and parallelism. |
|
|
The flatten_loops option controls flattening a multi-dimensional tiling space of a hl.tile loop into a single dimension, expanding autotuner’s search space without having the developer re-write the kernel code. |
|
|
To optimize data locality, Helion provides two configuration knobs. The loop_orders parameter allows the autotuner to permute the iteration order of nested tiles, which can affect cache hit rates depending on tensor layouts. The l2_grouping configuration enables PID swizzling, a technique that reorders the assignment of thread blocks to improve data reuse in the L2 cache. In Triton, these transformations would require rewriting complex loop structures and index calculations. |
|
|
When performing a reduction (e.g., sum() over a tensor dimension), a persistent reduction processes the entire reduction dimension for a single tile, which is fast for small dimensions. However, if the reduction is large, this approach can create high register pressure, leading to register spilling and low performance. Alternatively, a developer can write a loop to iterate over the reduction dimension in smaller chunks.
While switching between the two strategies typically requires code rewrites, Helion automates this choice with the |
|
|
Helion automates the calculation of grid sizes and the mapping of Program IDs (PIDs) to data tiles. The pid_type configuration allows the autotuner to explore various mapping strategies without any manual code changes:
|
|
|
Helion autotunes over Tritontl.load’s eviction_policy parameter, influencing GPU L1 cache residency. Autotuning can pick the combination of eviction hints that best suits the kernel’s memory access patterns. |
|
Triton configs:
|
Helion automatically explores standard Triton tunable parameters, alleviating the developer effort of manual tuning. | |
Performance Analysis and Benchmarks
We benchmark the performance of Helion to torch.compile(with max-autotune), and hand-written Triton to measure their respective speedups over eager mode execution across a wide variety of kernels and shapes on NVIDIA B200 and AMD MI350X GPUs. Most of the hand-written Triton kernels are from the Liger-Kernel benchmark suite.
Performance on NVIDIA B200
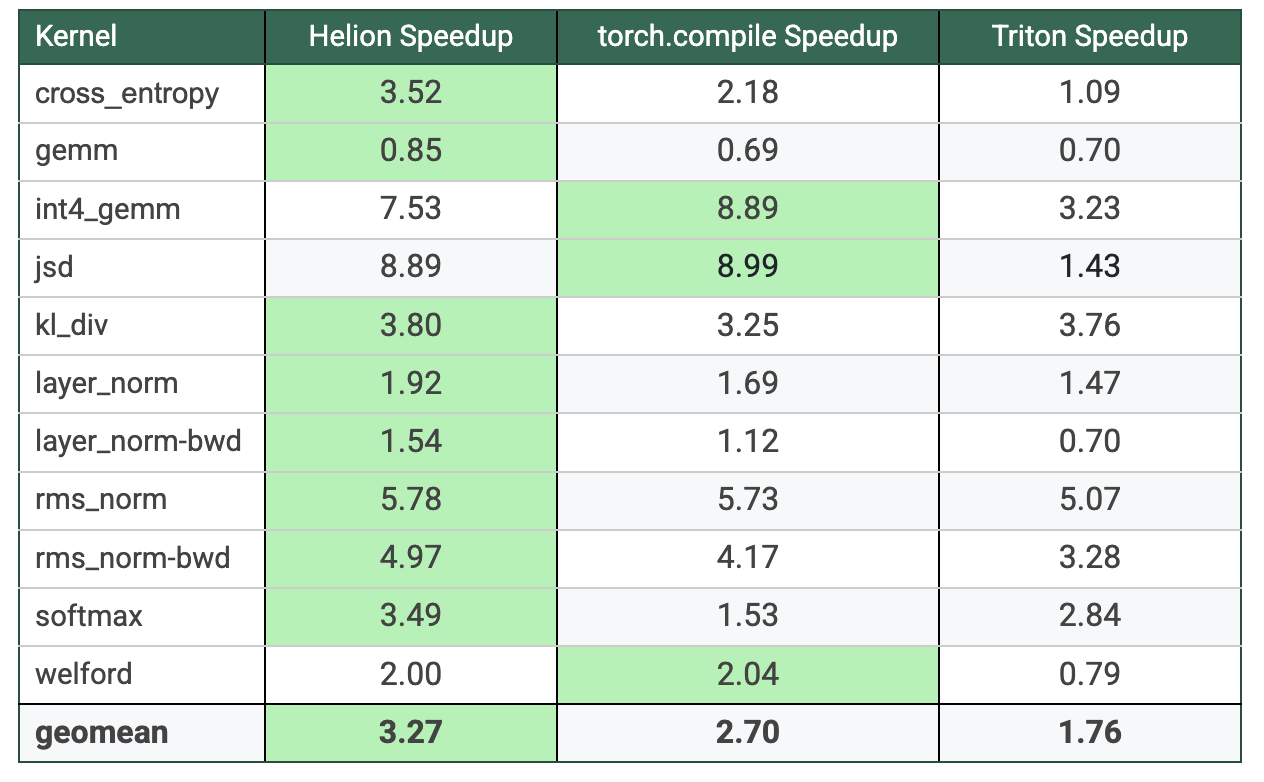
The following table summarizes the performance on NVIDIA B200 GPU, with green highlighted cells indicating the highest speedup over eager mode execution for each kernel. Across all benchmarks, Helion achieves the highest geomean speedup of 3.27x, followed by torch.compile (with max-autotune) at 2.7x, and hand-written Triton kernels at 1.76x. On average, Helion delivers 1.21x speedup over torch.compile and 1.85x speedup over Triton kernels. Performance gains are especially notable for the softmax kernel, with Helion achieving 2.28x speedup over torch.compile, and for the jsd kernel, where Helion outperforms hand-written Triton by 6.22x.
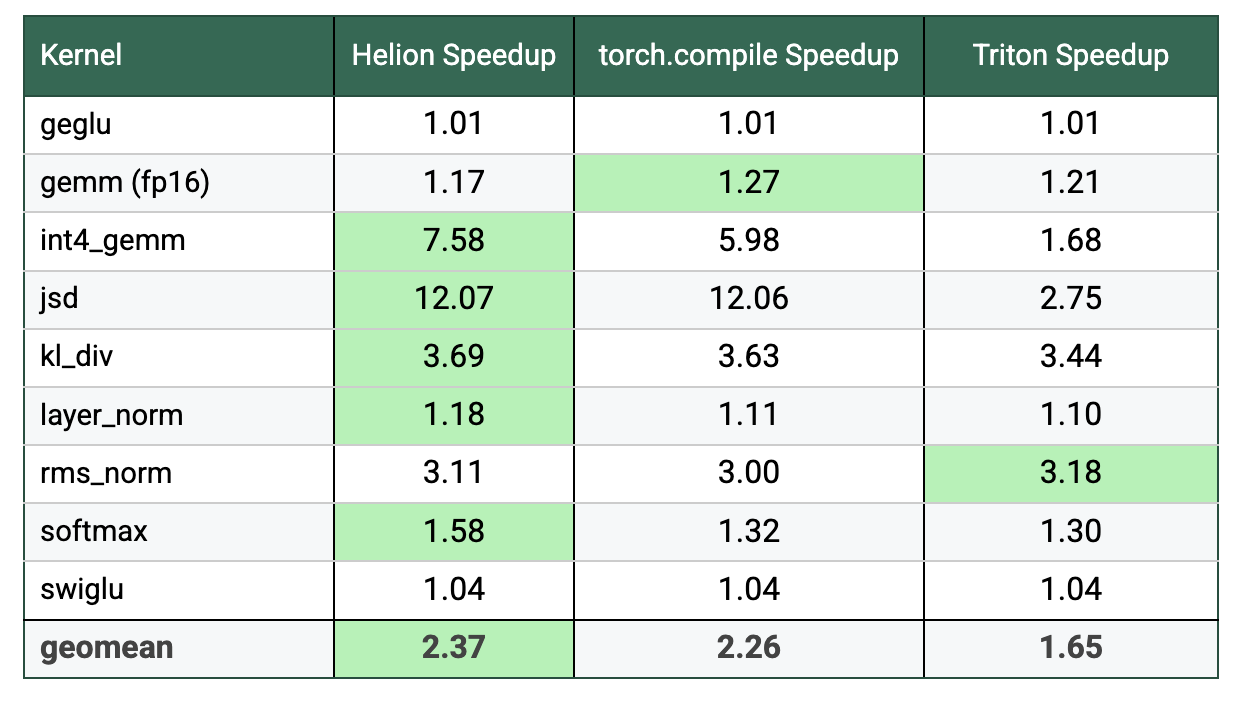
Performance on AMD MI350X
Performance on AMD MI350X shows a similar trend, with Helion achieving the highest geomean speedup of 2.37x over eager mode execution, compared to 2.26x for torch.compile and 1.65x for Triton kernels. On average, Helion delivers 1.05x speedup over torch.compile and 1.44x speedup over Triton kernels. The performance gains are particularly pronounced for the int4_gemm and jsd kernels, with Helion outperforming hand-written Triton kernels by 4.5x and 4.4x, respectively.
Case Study 1: Outperforming Highly Optimized CuTe DSL Kernel
A Helion implementation of the RMSNorm backward kernel, written in less than a day, demonstrates performance on par with or exceeds a highly hand-optimized Quack kernel written in CuTe DSL. Across a range of reduction dimensions on H100 GPU, Helion consistently matches or outperforms the manually-tuned kernel, demonstrating its ability to match expert-level performance with significant productivity boost from developing at a higher level of abstraction. We also compare to torch.compile (with max-autotune) and hand-written Triton, where Helion outperformed in many cases.
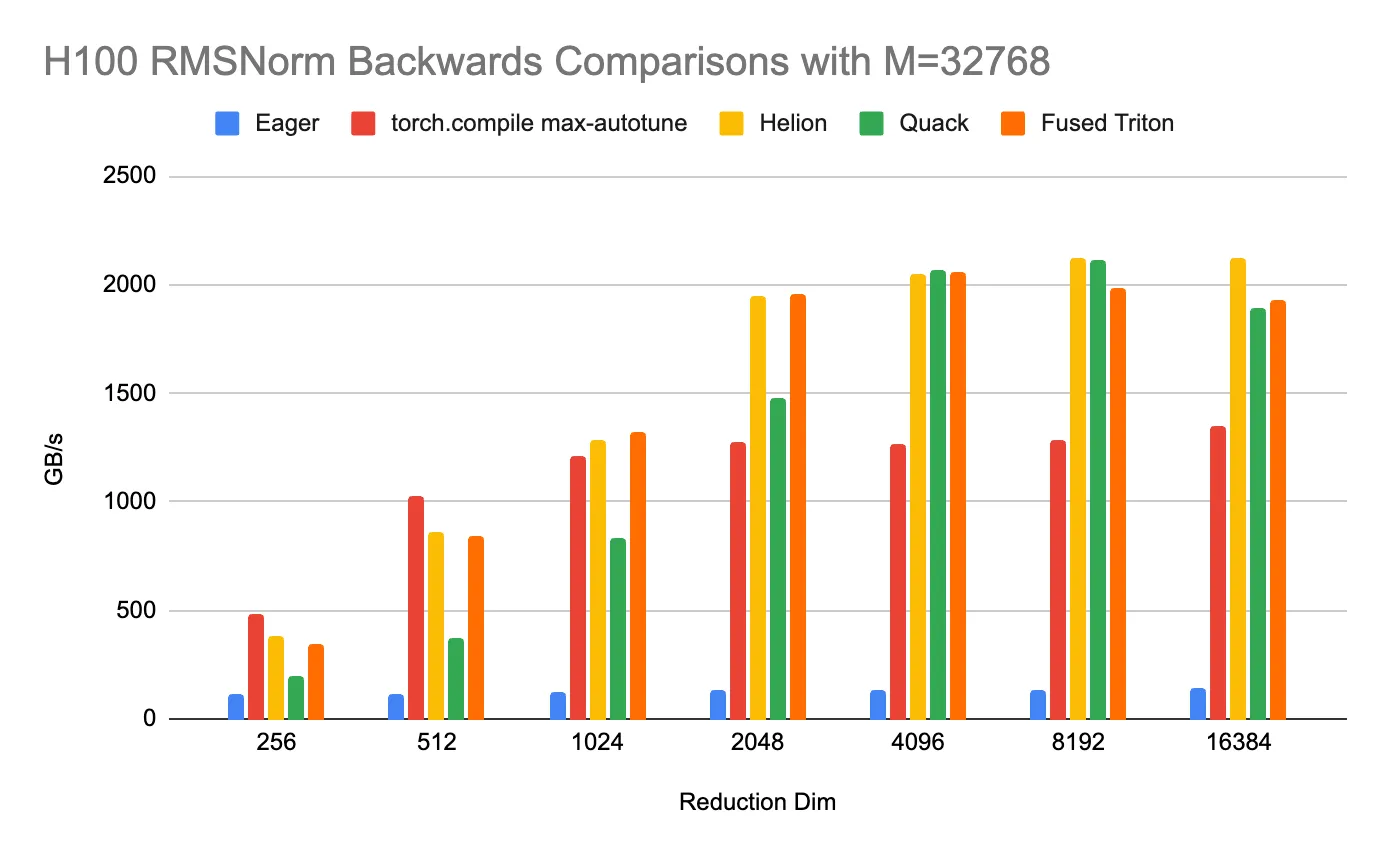
These results are made possible by Helion’s underlying compiler architecture, which is designed to efficiently support large-scale search for autotuning.
Case Study 2: Benchmarking Helion to TileLang
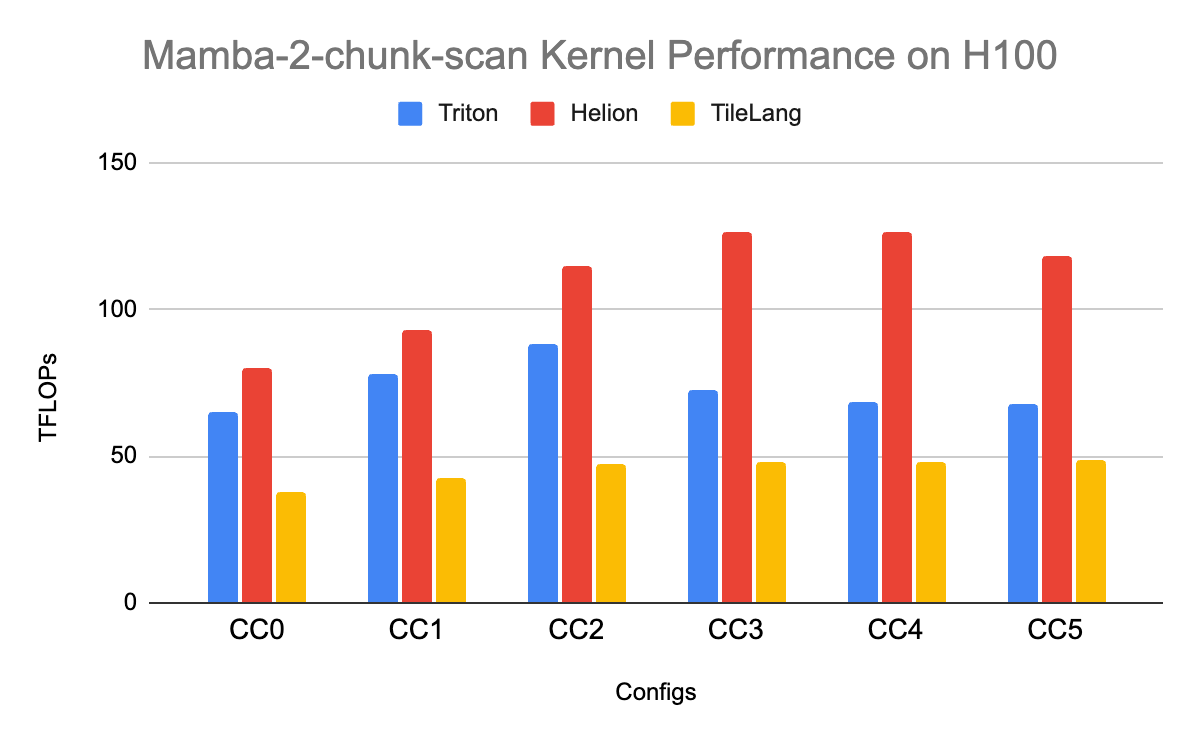
We also compare the performance of Helion to TileLang, an open-source DSL for developing high-performance GPU kernels. We implemented the Mamba-2-chunk-scan kernel — a selective scan operation central to the Mamba-2 architecture — in Helion to compare against its TileLang and Triton counterparts. On H100, Helion delivers the highest performance, achieving 2.12x–2.63x speedups over TileLang and 1.2x–1.85x over Triton across different configurations.
High-Level Compiler Architecture
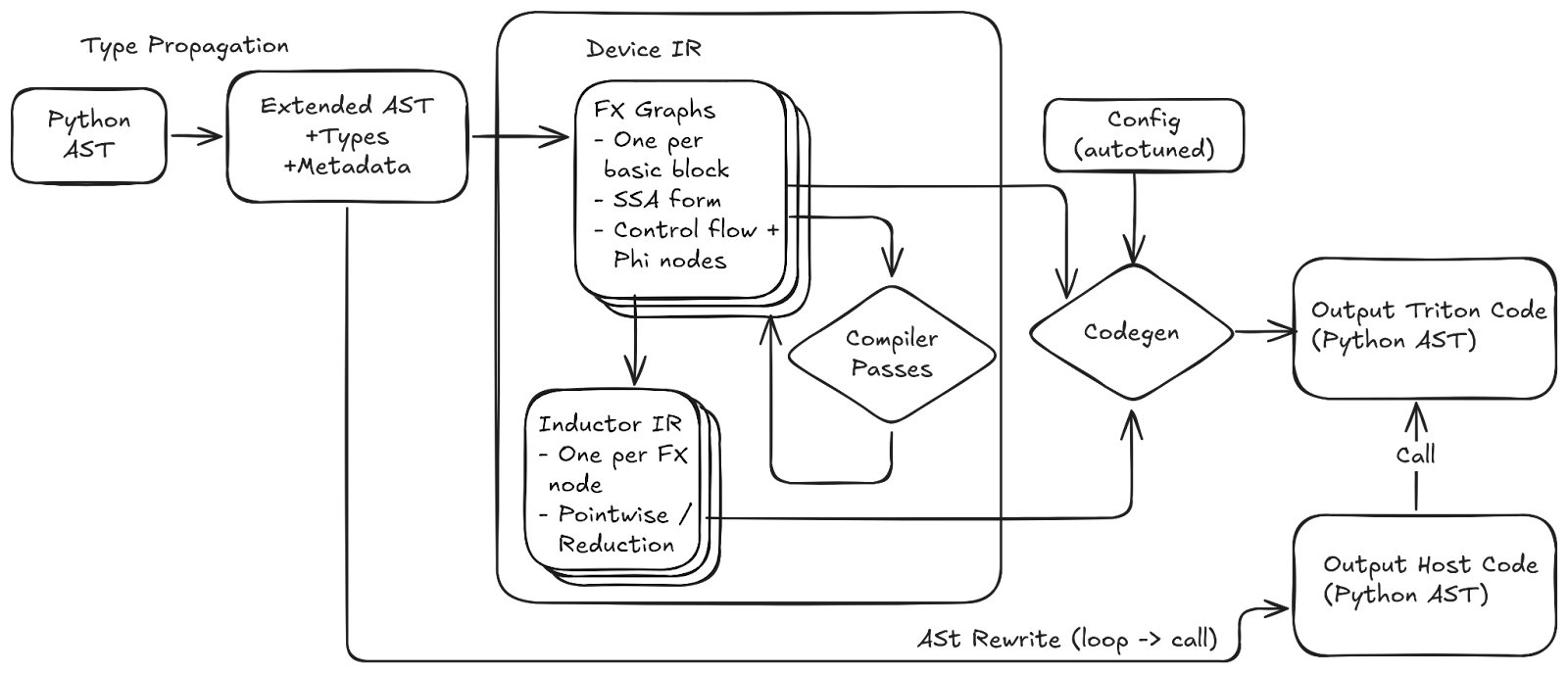
Helion’s compiler architecture is designed to progressively lower a Python function into highly optimized Triton code with TorchInductor.
The compilation pipeline proceeds through the following key stages:
- Python AST Parsing: The process begins by parsing the kernel’s Python source code into an Abstract Syntax Tree (AST).
- Type Propagation & Metadata: A custom pass traverses the AST, annotating each node with type information and other essential metadata to create an extended AST.
- Lowering to Device IR: This annotated tree is lowered into Helion’s primary intermediate representation (IR). The Device IR is a collection of FX Graphs in Static Single-Assignment (SSA) form, with one graph representing each basic block of the program. Every node in this graph contains a pointer to an Inductor IR node, which is used for code generation.
- Compiler Passes: A series of transformation passes are applied to the Device IR. These passes implement key semantic changes, such as the reduction rolling optimization, which converts a persistent reduction into a looped one.
- Codegen with Configuration: In the final stage, the code generator takes two inputs: the transformed Device IR and the autotuned config. It uses these to generate the final output Triton code.
A key architectural decision is that the performance-critical config is applied only at the very end of the pipeline during code generation. This allows the majority of the compilation process, from parsing to IR transformation, to be run just once before the autotuning search, making the exploration of thousands of configurations computationally efficient.
Conclusions
Helion addresses a critical gap in today’s kernel authoring space for machine learning. By combining a familiar and high-level PyTorch-like syntax with a powerful, ahead-of-time autotuning engine, it provides a unique balance of developer productivity, fine-grained control, and performance portability. It empowers developers to write portable, future-proof kernels that achieve state-of-the-art performance without requiring deep hardware expertise, establishing a new and a more productive paradigm for performant machine learning kernels.
Helion is being released in Beta on Oct. 22nd, 2025, and we welcome feedback, bug reports, and contributions from the community. For more information, see:
Acknowledgements
Helion is the work of many hands including: Jason Ansel, Oguz Ulgen, Will Feng, Jongsok Choi, Markus Hoehnerbach, Manman Ren, Jie Liu, Paul Zhang, Driss Guessous, Joy Dong, Xuan Zhang, Karthick Panner Selvam, Peng Wu, Hongtao Yu, Neil Dhar, Nick Riasanovsky, Shane Nay, Alexey Loginov, as well as teams at Meta, NVIDIA, AMD, and Intel
Note: B200 Performance numbers updated 10/23.