In this blog post, we present the kernel design of Generalized Dot-Product Attention (GDPA), a variant of standard dot-product attention (SDPA) in which the softmax operation is replaced by different activation functions to support diverse interaction use cases, as used in the attention blocks of InterFormer [2], Kunlun [1] which are deployed on Meta’s Generative Ads Model (GEM) [3], Meta’s largest Recsys training foundation model. Starting from the real-world attention workloads observed in these models, we build upon Tri Dao’s Flash Attention 4 kernel (FA4) and introduce a series of workload-driven optimizations tailored to large-batch training, variable sequence lengths, and non-softmax activations.
Evaluated NVIDIA B200 GPUs deployed in Meta’s clusters with a 750 W power cap, our optimized GDPA kernel achieves up to 2× speedup in the forward pass, reaching 1,145 BF16 Tensor Core TFLOPs, approximately 97% tensor core utilization, and up to 1.6× speedup in the backward pass, reaching 702 BF16 TFLOPs, compared to the original Triton-based implementation. Beyond attention, the same design principles generalize to other kernels operating on real-world, irregular shapes. When applied across the full model, these customized kernels deliver over 30% training throughput improvement, demonstrating the effectiveness of production-driven kernel design. Overall, under certain real-world production traffic settings, our approach achieves up to 3.5× speedup in the forward pass and 1.6× speedup in the backward pass compared to FA4 (a SOTA attention kernel).
Code Repository: https://github.com/facebookresearch/ads_model_kernel_library/blob/main/gdpa/README.md
† Work done while at Meta
‡ Work done while at Princeton University
1. GDPA in Recsys Training Workloads
Generalized Dot-Product Attention (GDPA) is a widely used interaction pattern, particularly in RecSys models, that generalizes standard dot-product attention beyond the softmax formulation. Rather than being restricted to probability-based normalization, GDPA allows attention scores to be transformed by custom element-wise activation functions, a design that has been adopted in several production Recsys architectures. For example, Kunlun [1] applies GELU activations in its PFFN blocks, while HSTU[4], another one of Meta’s large recommendation models, leverages SiLU activations to better preserve score magnitudes in sequential modeling.
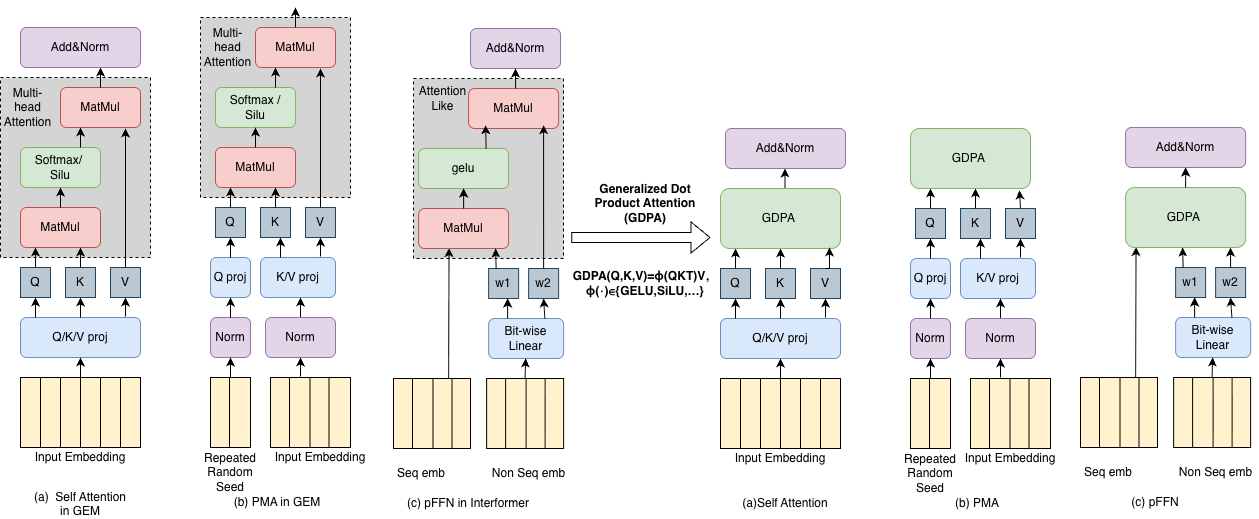
Fig. 1. (a) Self attention in GEM. (b) PMA in GEM. (c) PFFN in InterFormer. With the GDPA kernel, we unify all attention kernels into one similar implementation.
GDPA captures a broad class of attention-like modules used in production RecSys—such as self-attention, PMA, and PFFN—which share a common pattern of two matrix multiplications with an optional activation in between as shown in Fig. 1. By unifying these modules under the GDPA formulation, we can design a single high-performance kernel for efficient optimization across real-world training workloads. In this post, we use GELU as a running example to illustrate the optimization process.
2. Challenges in Real-World Training Workloads
At the starting point, we observed that our original GDPA training kernel, adapted from latest Triton templates, performs poorly under real production workloads. As shown in Fig. 2, we compare real-world kernel performance against the CUTLASS FMHA benchmark, which is the fastest FlashAttention kernel we tested for our production shapes. The real-world kernel is evaluated using actual production data, while the benchmark is measured on synthetic data with the same maximum sequence length. The key difference lies in the data distribution: real-world data is driven by user behavior and does not follow a fixed distribution, while the synthetic data is generated using a normal distribution. On NVIDIA B200, real-world runs exhibit a 2.6× performance gap in the forward pass and a 1.6× gap in the backward pass relative to the benchmark, with worst-case gaps reaching up to 4×.
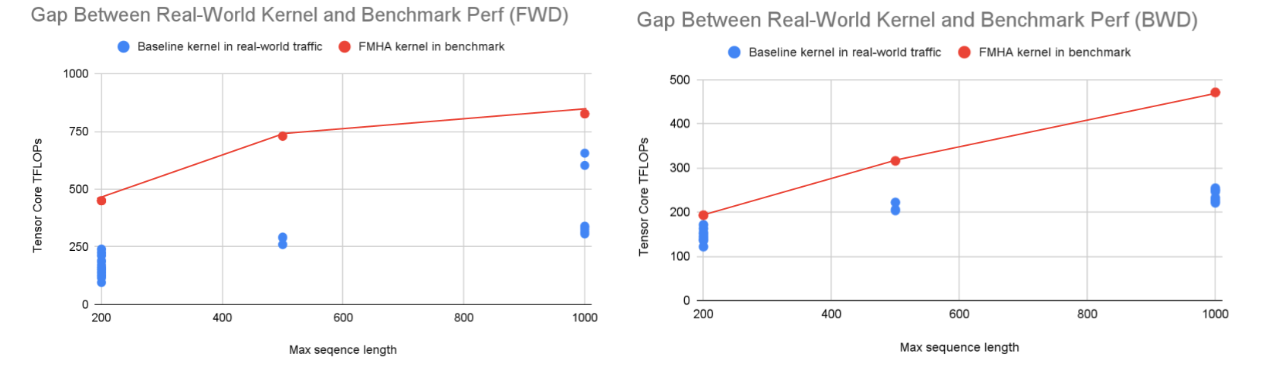
Fig. 2. Real-world vs. benchmark kernel performance. Forward (left) is 2.6× lower and backward (right) is 1.6× lower than benchmark results, with up to 4× gap in the worst case.
Our analysis suggests that this gap arises from a fundamental mismatch between LLM-oriented kernel designs and production RecSys workloads. Real-world traffic is dominated by short and asymmetric sequences, large batch sizes, jagged inputs, which significantly reduce pipeline occupancy and limit compute–memory overlap. These observations motivate a kernel redesign that explicitly accounts for highly dynamic, short-sequence real-world inputs, as discussed in the following section.
3. Design and Optimization of GDPA Kernels for Training
Our goal is to optimize kernels for real production traffic and push performance toward the hardware roofline. Starting from the FA4 kernel —the fastest option on our GPUs under LLM-style shapes in our evaluation—we redesign the kernel for GDPA training workloads by rethinking its pipelining, scheduling, and core computation.
3.1 Redesigning the Pipeline for GDPA Training
In FlashAttention kernels [5], warp specialization is largely driven by softmax computation, with separate warp groups handling softmax evaluation, correction, and epilogue stages. In GDPA, the softmax computation is replaced with element-wise activations, and the softmax correction stage is eliminated. As illustrated in Fig. 3, we simplify the warp-specialized pipeline by eliminating the correction stage entirely and folding the TMEM-to-SMEM epilogue load into the activation stage, rather than assigning it to a dedicated warp group. This design reduces the total warp count by 4 and frees register resources for the remaining warps; in particular, activation warps gain 16 additional registers per warp as shown in Fig.3.
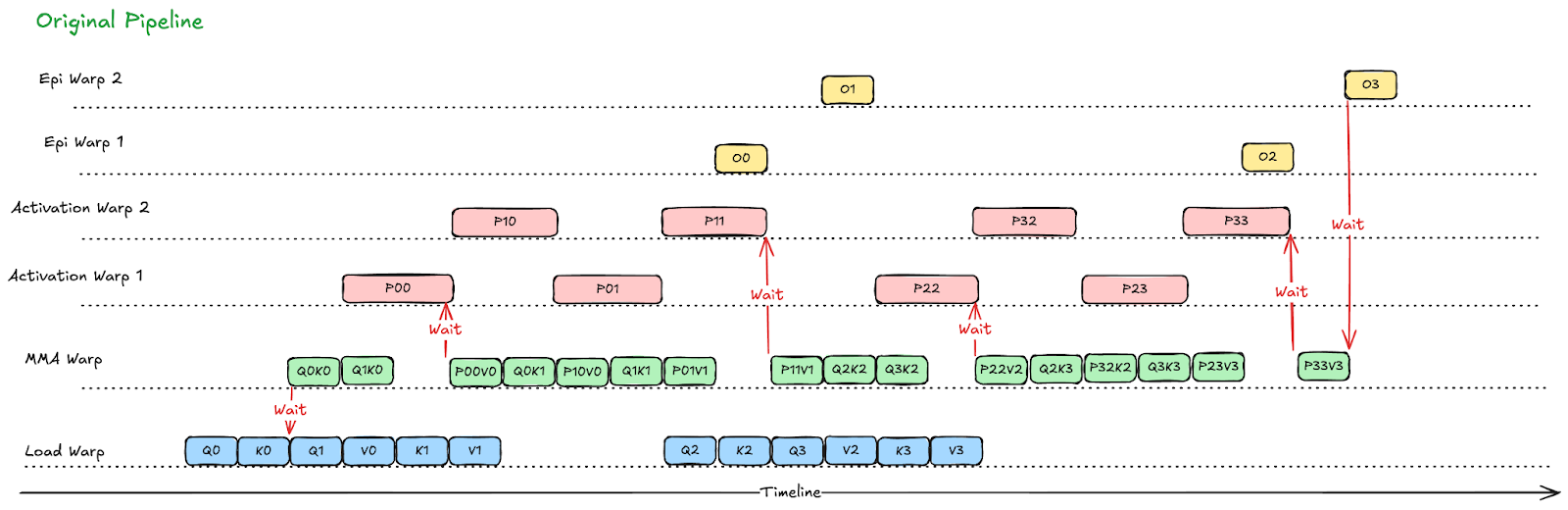
Fig. 3. Redesigning the FlashAttention pipeline for GDPA fwd kernel. The correction stage is removed, and activation warps take over its role in the epilogue, including writing results from TMEM to SMEM. By eliminating 4 warps, we gain 16 registers per activation warp.
Another major bottleneck comes from very short K/V sequences, which are common in production workloads. In a persistent kernel, attention kernels are naturally expressed as a double-nested loop, where the inner loop iterates over the K/V dimension. The original inner-loop design assumes enough iterations to amortize pipeline setup costs as shown in Alg.1 below, but this assumption breaks down when the inner loop runs only a few iterations (e.g., when the kv sequence length is 128 or 256, the inner loop only runs once or twice with block size 128). In these cases, software pipelining on the inner loop becomes much less effective.

Alg. 1–2. Algorithm 1 uses inner-loop SWP in a traditional MMA warp pipeline, while Algorithm 2 applies outer-loop SWP to better handle short K/V sequences.
To address this, we flatten the inner loop into the outer loop and apply software pipelining (SWP) at the outer-loop level as shown in Alg. 2. The idea is straightforward. In the prologue, we compute the qk for the previous iteration while performing the first-stage p·v of the current iteration. In the epilogue, we complete the remaining p·v stages, write the results from tensor memory to shared memory, and release intermediate storage as soon as it is no longer needed. This enables overlap across iterations and effectively pipelines multiple iterations as shown in Fig. 4. In practice, this optimization shows ~10% gain when kv length is short.
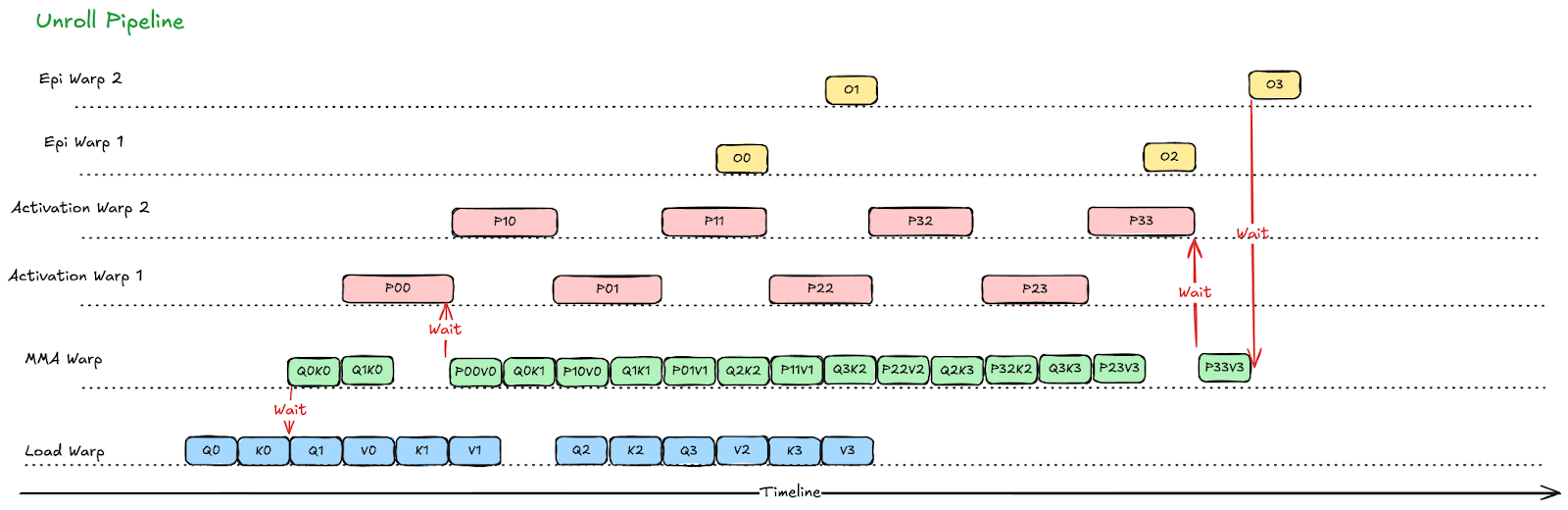
Fig. 4. After loop flattening, MMA and activation warps are better overlapped, reducing pipeline bubbles present in the original inner loop compared to Fig.3.
3.2 A novel software load balancing algorithms for Jagged Tensors
Jagged sequences are common in production workloads and significantly limit GPU utilization, which is a key reason why existing Flash Attention kernels struggle to perform well in production models. Most FlashAttention-style persistent schedulers are built for dense inputs: they enumerate tiles across batch, head, and M dimensions and implicitly assume that each tile carries a similar amount of work.
In practice, sequence lengths are dynamic and often unknown at kernel launch time, so jagged workloads are dispatched by assuming the maximum length and checking tile validity at runtime. This results in many scheduled empty tiles, while valid tiles may still have highly variable workloads due to differing K/V lengths, leading to persistent SM imbalance. Simple heuristics such as reordering sequences by length are insufficient, as the scheduler remains unaware of tile validity and workload heterogeneity.
To address these issues, we move load balancing to the software level by precomputing valid tiles on the CPU using existing sequence-length metadata. In GPU-kernel-bound training workloads, this preprocessing on CPU incurs negligible overhead, as it is performed once per iteration and amortized across layers. The persistent kernel then schedules work only over real tiles, eliminating empty-tile execution and reducing imbalance.
To better understand the design of our tile scheduler, we illustrate the process in the figure and decompose it into two steps. We first focus on balancing the workload along the Q dimension. Specifically, we eliminate all empty Q tiles caused by jagged sequences and assign the remaining valid Q tiles to SMs in a round-robin manner, rather than following a fixed batch–head–M ordering. As shown in Fig. 5, this removes no-op execution and partially balances the workload across SMs in first step.
However, for cross-attention workloads, Q-length balancing alone is insufficient because the amount of work per Q tile still varies with dynamic K/V lengths, as illustrated in Fig.5 step 2. We therefore further sort tiles by their K/V block counts and apply a lightweight zigzag assignment pattern across SMs, where tiles are scheduled in alternating waves from longest-to-shortest and shortest-to-longest, which smooths residual imbalance. This combined strategy reduces workload skew from a wide range (e.g., 12 vs. 2 blocks per max vs min SM) to a much tighter distribution (e.g., 5 vs. 4 blocks).
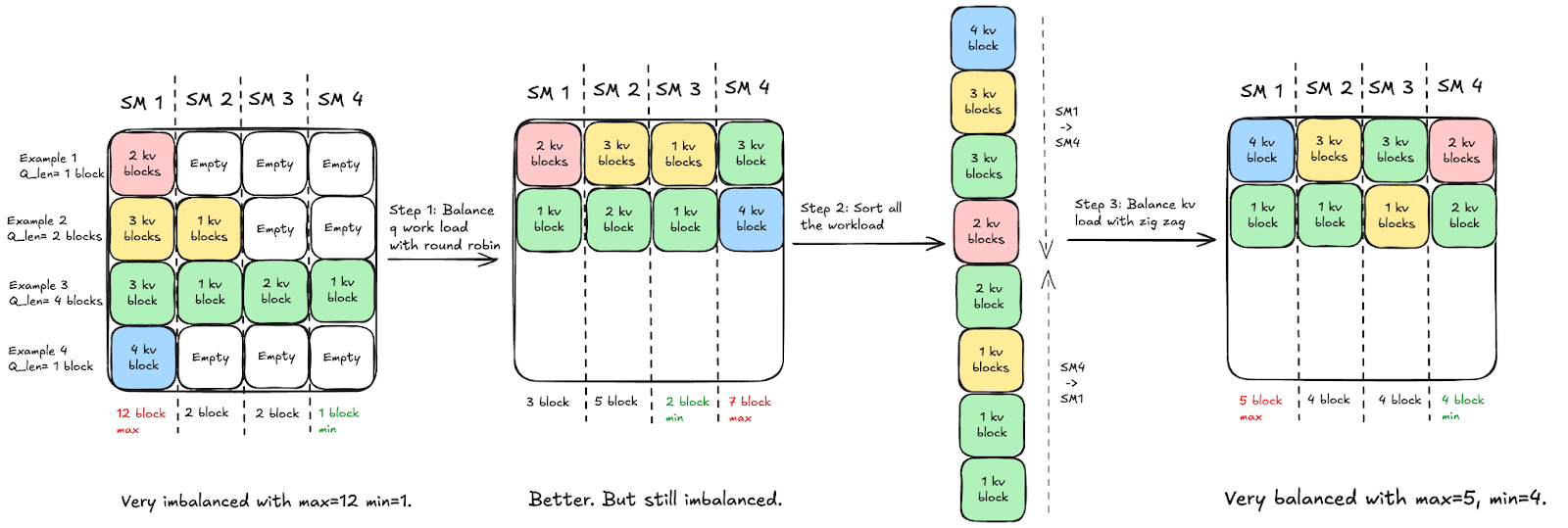
Fig. 5. Initial SM workloads are imbalanced due to variable-length inputs. We first balance the Q workload by removing empty tiles and assigning valid tiles in a round-robin manner, then further balance the K/V workload using a zigzag scheduling strategy.
Together, these two steps form our zigzag tile scheduling algorithm, summarized in Alg. 3. Since both steps are vectorizable, the scheduling overhead on the CPU is minimal; otherwise, a sequential scheduling strategy would be more suitable. The algorithm nevertheless delivers stable improvements in SM utilization.

Alg. 3. Software-level tile scheduling for jagged tensor using precomputed valid tiles and zigzag assignment to balance persistent kernels
We also apply similar software-level tile scheduling to the backward pass, with the key difference being that Q and K/V roles are swapped to match the backward loop structure since the Q sequence length is iterated over in the inner loop.
3.3 Math optimization
Modern attention and FFN kernels are increasingly compute-dense, but GPU compute resources do not scale uniformly. In particular, special function units (SFUs), which execute transcendental operations (e.g., exp, tanh), are significantly more scarce than CUDA Cores. Kernels that rely heavily on SFU can easily become SFU-bound, even when Tensor Cores are underutilized. In practice, this limits further scaling. For example, our baseline GELU implementation relies on tanh.approx.ftz and remains SFU-limited despite further optimizations.
Inspired by FA4 kernel , which alleviates SFU bottlenecks by redistributing transcendental computation between SFUs and CUDA Cores using software approximations of exp, we apply a similar idea to GELU. Instead of approximating only the tanh component, we approximate the entire GELU function using an ALU-only Taylor expansion as shown in Eq. 1 . We found this approach to perform better than simulating a single SFU operator, as it can absorb the polynomial transformations applied to both the input and output of tanh.

Eq.1 Comparison of GELU approximations. The top equation shows the standard tanh-based GELU approximation, which uses 1 SFU instruction and 8 ALU instructions. The bottom equation shows an ALU-only Taylor expansion of GELU with 9 ALU instructions.
This approximation does introduce accuracy limitations when input magnitudes grow large, as illustrated in Fig. 6. However, in our production models, each attention block is preceded by QK-norm. The model also employs additional normalization layers and global clipping for other purposes, jointly constraining the input distribution to ensure the Taylor approximation remains accurate. As a result, this method works well in practice and effectively alleviates the SFU bottleneck in our production workloads. Furthermore, this approach can be applied to both forward and backward kernels and also other activations that use SFU.
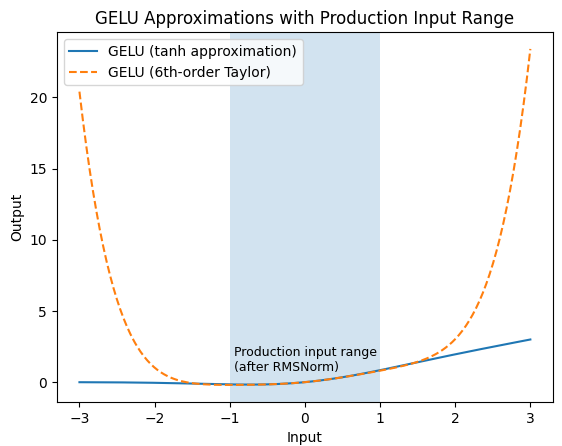
Fig. 6. Comparison between the standard tanh-based GELU approximation and a 6th-order Taylor approximation. Taylor expansion is accurate only within a bounded input range; in our production models, RMSNorm constrains activations to this range.
3.4 Persistent Scheduling for the Backward Pass
The persistent scheduling technique is effective in hiding latency. In our case, it gives 5% FLOPS improvement in backward. To implement the persistent scheduling in backward, a key change is to add additional synchronization to orchestrate the memory queue between asynchronous producer and consumer warps.
The memory queue design reuses the same tensor memory and shared memory for multiple computations (due to limited space in tensor memory and shared memory). In Fig. 7, we show the details of memory reuse. The one related to our additional synchronization is that in stage 4, sQ’s shared memory space is reused for sdK, with producer being Q_reduce warp and consumer being TMA, similar for sdO’s memory. So there are two producers for sQ and sdO’s shared memory space. Because of that, an additional sync need to be added for the load warp (i.e. the warp loading Q, K, V, dO from global memory to shared memory) to wait for the warp to finish storing dK and dV because dK, dV use the same shared memory as dQ, dO which if not waited properly can be overridden by the Load warp.
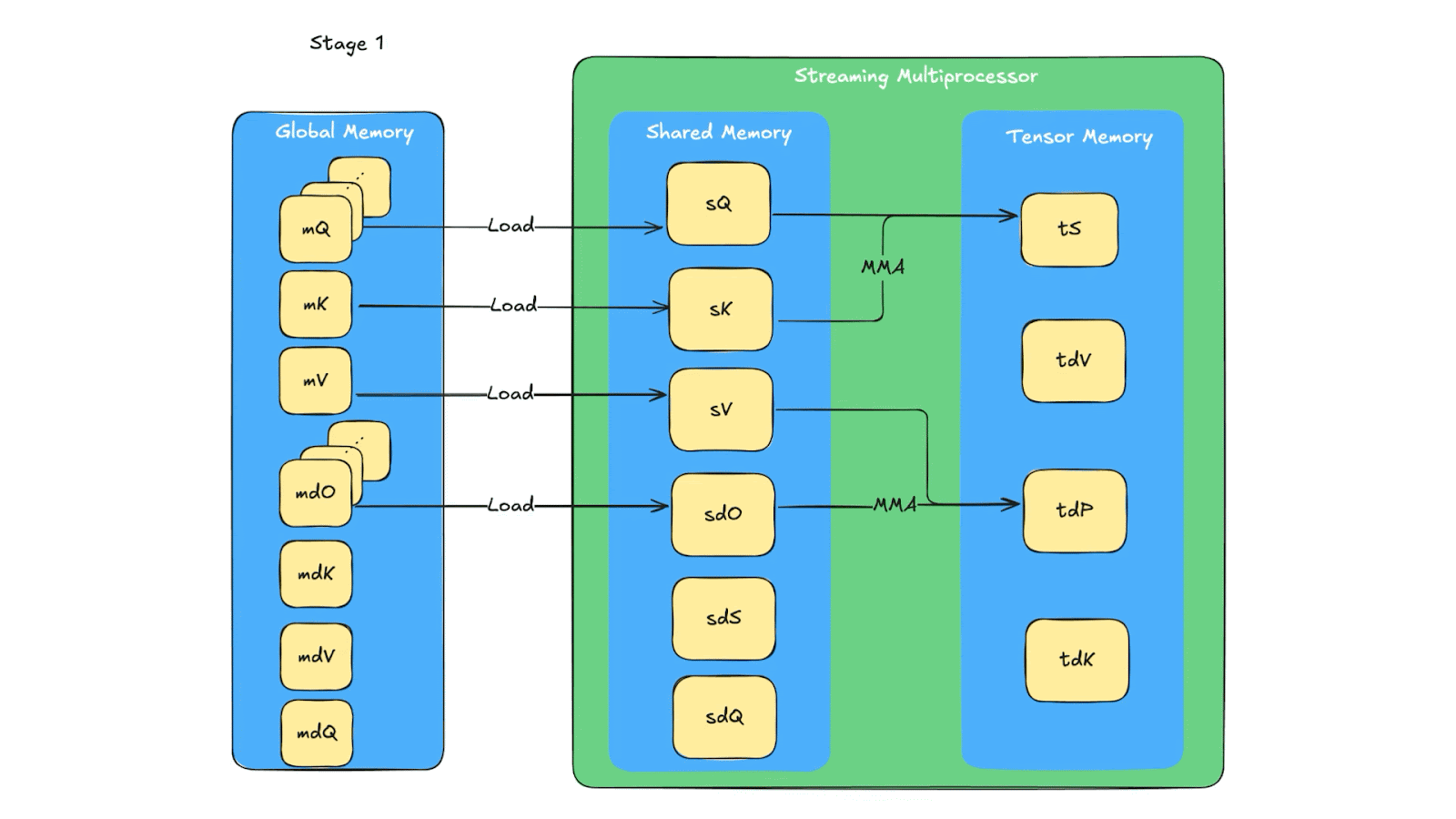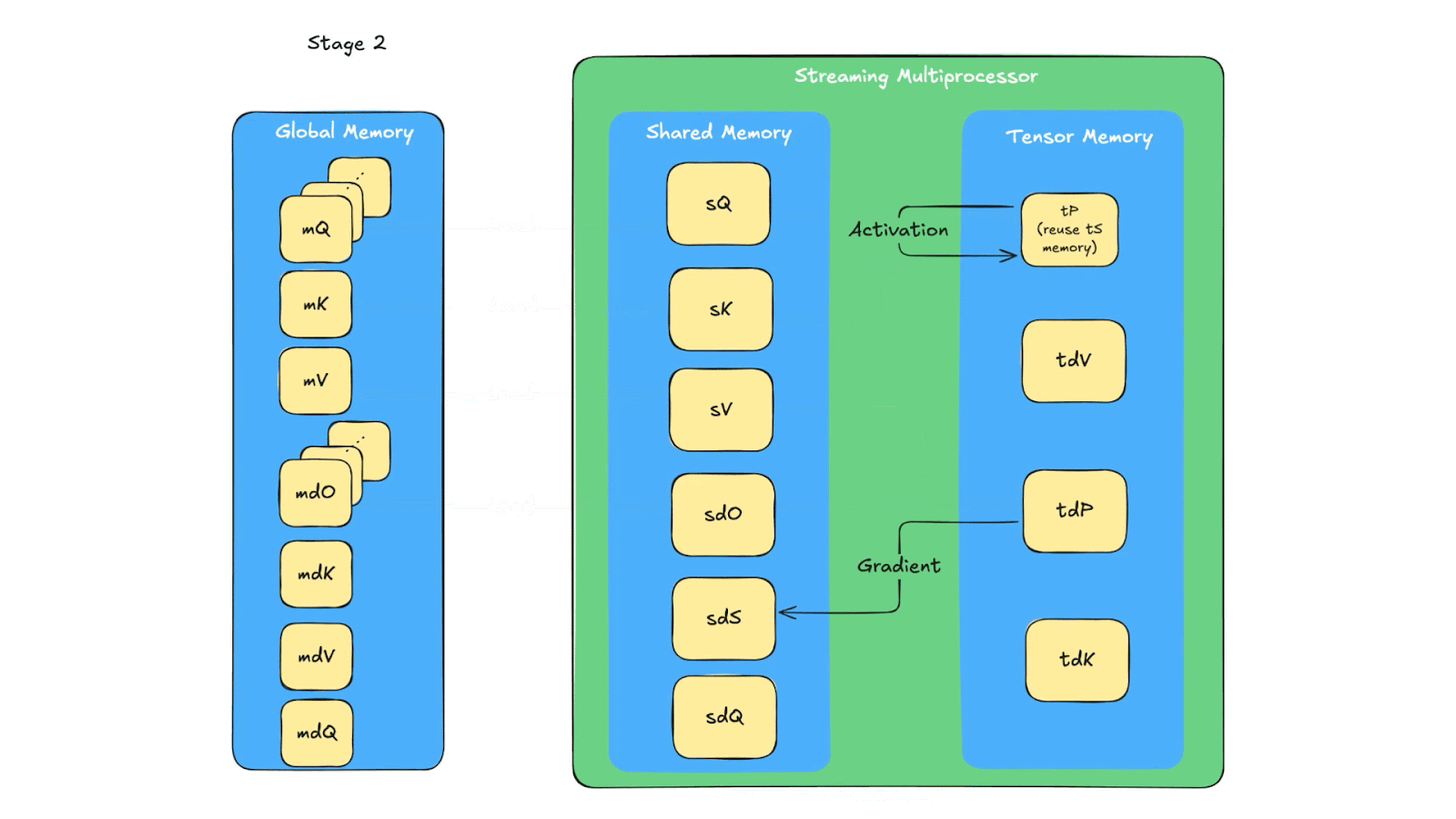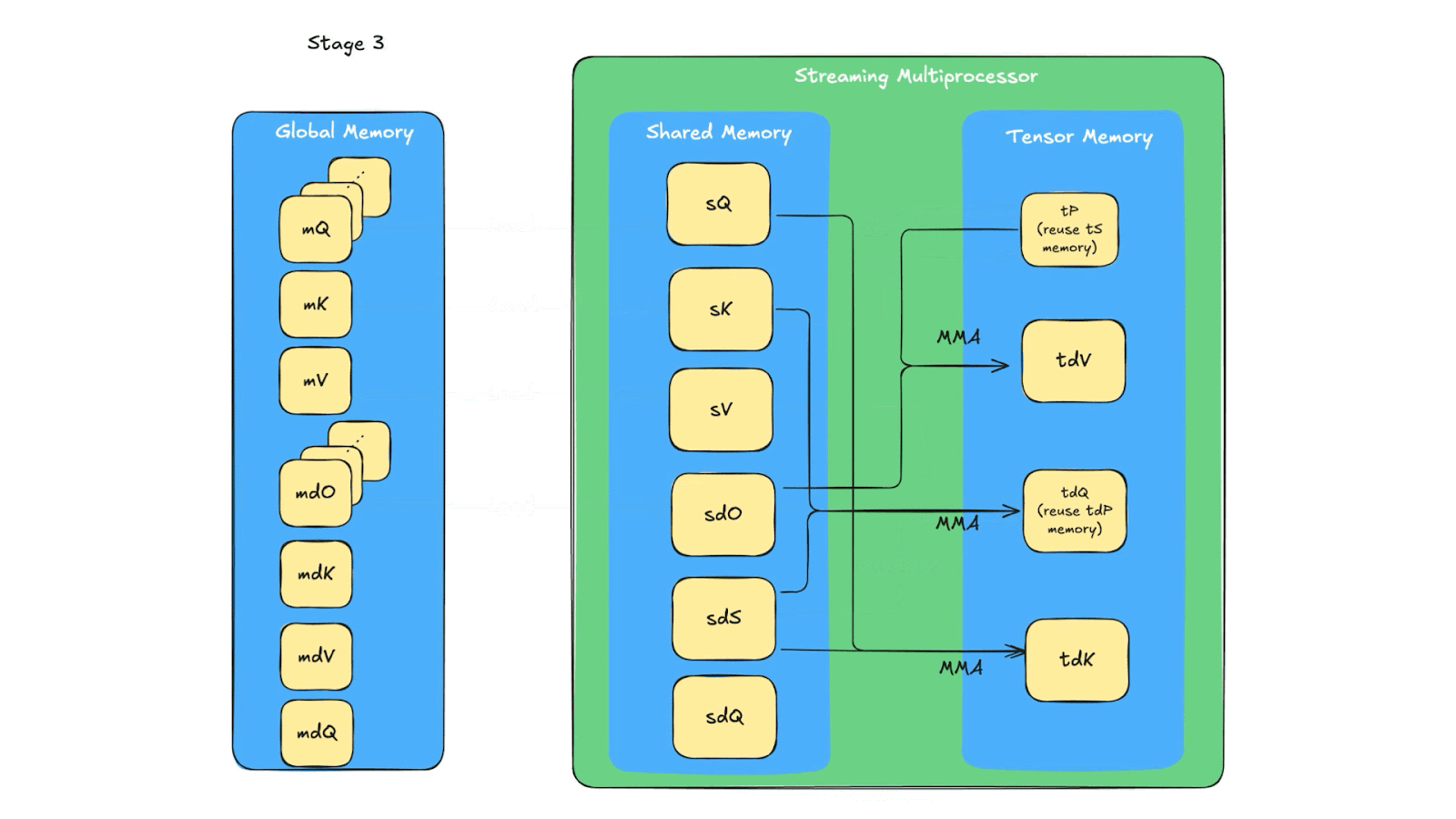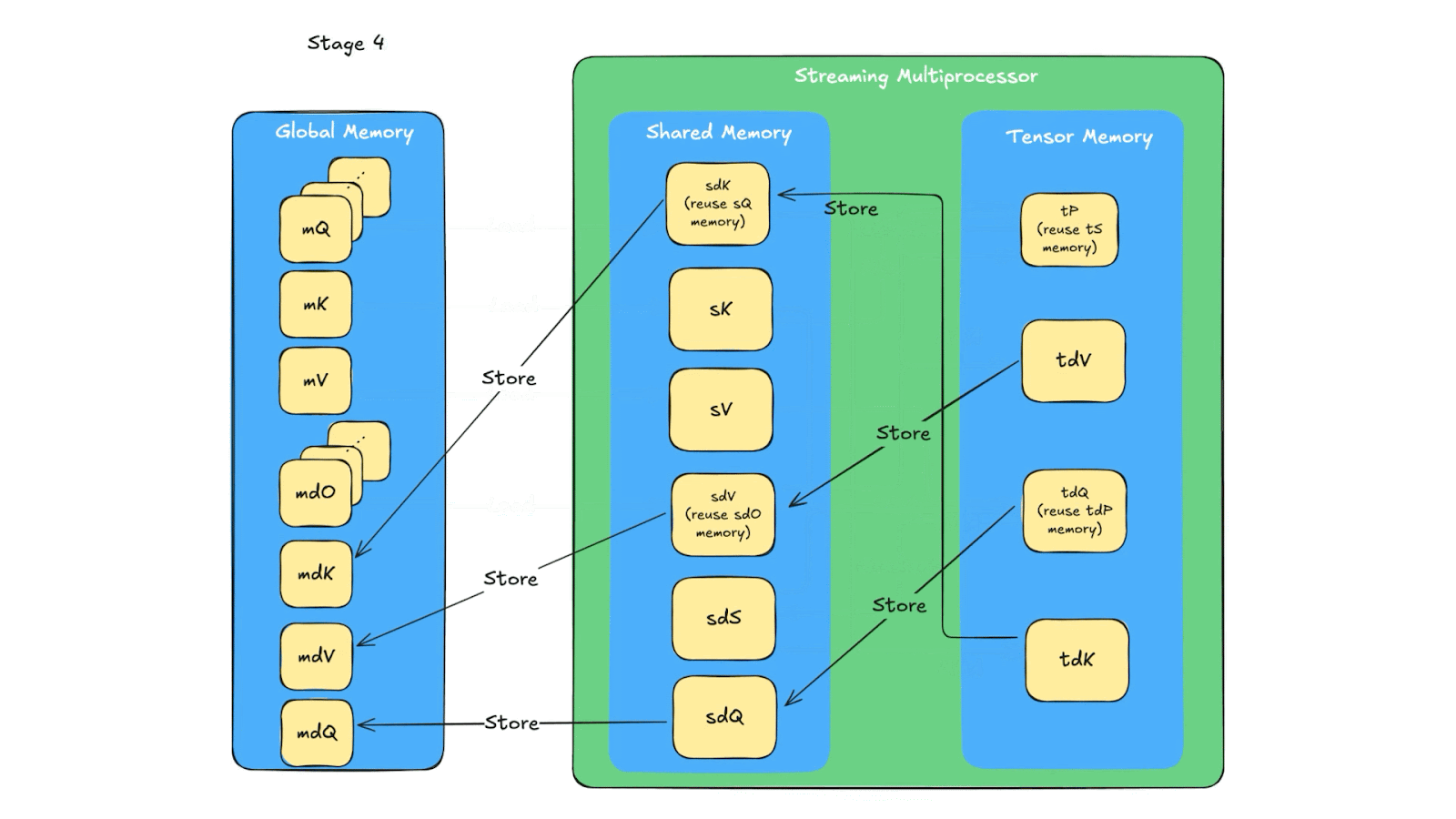
Fig. 7. The data flow of the backward pass across global memory, shared memory and tensor memory.
4. Benchmarks
4.1 Benchmark set up
All benchmarks in this blog are run on NVIDIA B200 GPUs (≈180 GB HBM, CUDA 13.0) on Meta internal clusters, with a power cap of 750 W per GPU and default GPU clocks.
We report kernel-level performance using Tensor Core throughput (TFLOPs) and relative speedup over baseline implementations. We evaluate several GDPA kernel variants, including:
- Triton GDPA (Baseline). A Triton-based implementation derived from Triton templates [6], serving as our primary baseline.
- CUTLASS FMHA. The FMHA kernel from CUTLASS that currently runs on Blackwell GPUs.
- FA4 kernel. The FlashAttention-4 kernel, whose design we build upon and adapt for GDPA in this blog.
- CuteDSL GDPA (ours). The optimized GDPA kernel developed in this work, based on the CuteDSL attention kernel and tailored for real-world GDPA training workloads.
4.2 Key results
We evaluate GDPA kernel performance on both self-attention and cross-attention workloads. In self-attention, the query, key, and value tensors are generated from the same embedding, whereas in cross-attention, queries attend to keys and values from a different source. Since self-attention is the dominant pattern in our target training workloads, we first present detailed self-attention results, followed by cross-attention results.
To characterize input irregularity, we vary the input sparsity, which we define as the ratio between the average sequence length and the maximum sequence length within a batch. A sparsity of 1.0 corresponds to fully dense inputs, where all sequences have identical lengths, while lower sparsity values represent jagged inputs with dynamic sequence lengths. For example, sparsity = 0.5 indicates that the average sequence length is half of the maximum, reflecting realistic training traffic with significant length variation.
As illustrated in Fig. 8, under dense inputs, Blackwell FMHA clearly outperforms the Triton GDPA baseline, achieving up to ~30% higher throughput. However, this advantage collapses under jagged inputs. When sparsity drops to 0.5, both FMHA and the baseline suffer severe performance regression, and FMHA degrades to nearly the same level as the baseline across all sequence lengths.
In contrast, our optimized GDPA kernel remains robust under jagged inputs. While all kernels slow down when moving from dense to jagged shapes, our kernel consistently preserves a significantly larger fraction of its dense-input performance, maintaining ~1.7× average speedup over the baseline even at sparsity = 0.5. This demonstrates that dense-oriented attention kernels do not generalize to dynamic training shapes, whereas GDPA designs optimized for real traffic sustain high utilization under irregular workloads.
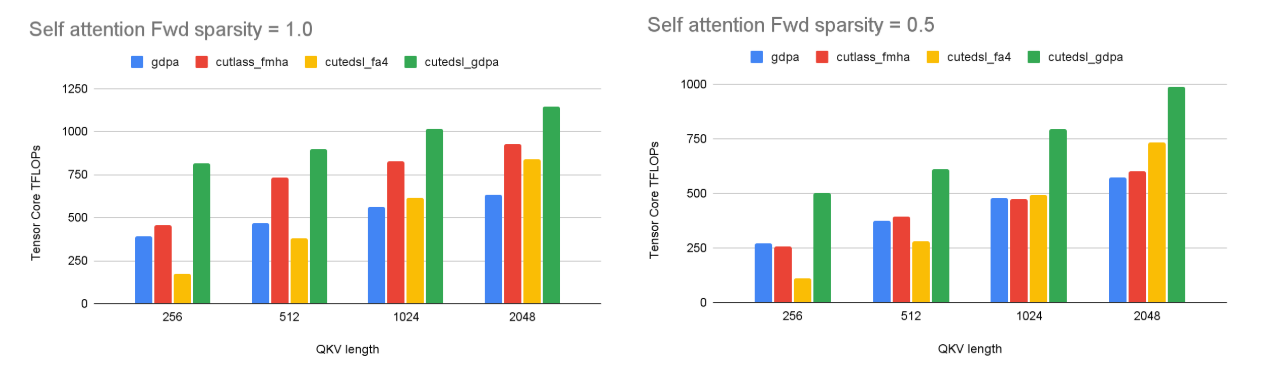
Fig. 8. Self-attention forward performance under dense (left, sparsity = 1.0) and jagged (right, sparsity = 0.5) inputs. Our optimized GDPA kernel consistently maintains higher throughput across both cases.
We also evaluate self-attention backward performance, which is more challenging than the forward pass due to higher memory traffic and gradient accumulation. Under dense inputs, the optimized GDPA kernel achieves up to 1.6× speedup, reaching ~702 BF16 TFLOPs, while the gap to Blackwell FMHA narrows as backward computation becomes more bandwidth- and synchronization-bound as illustrated in Fig.9 . Under jagged inputs, although the relative differences are smaller, our optimized kernel still maintains an average ~1.3× speedup over the baseline. We attribute this behavior to the higher complexity of the backward pass, which requires more delicate pipeline tuning. In addition, since backward kernels are often shared-memory bandwidth bound, the transition from SDPA to GDPA provides less opportunity for performance improvement than in the forward pass, leaving further optimization potential for future work.
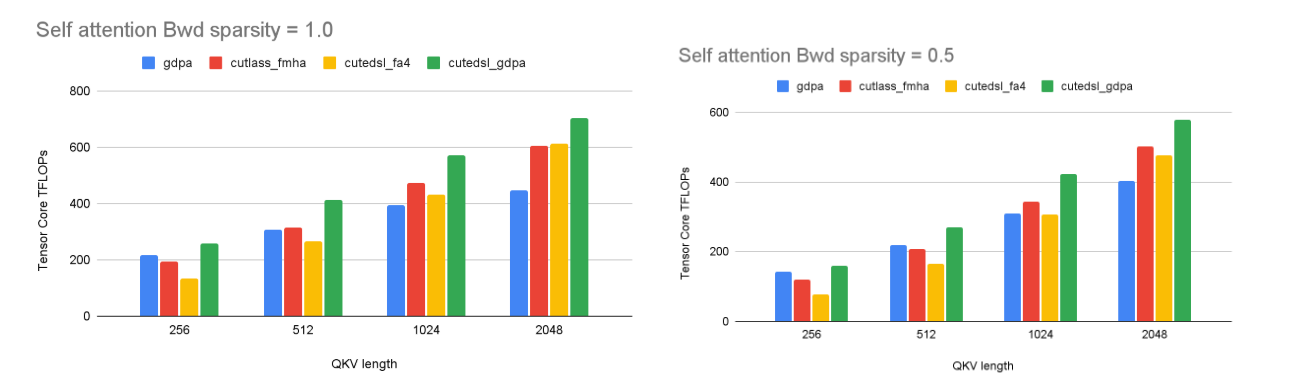
Fig. 9. Self-attention backward performance under dense (sparsity = 1.0) and jagged (sparsity = 0.5) inputs. The optimized GDPA kernel consistently outperforms the Triton baseline, while gains are more modest than in the forward pass due to the bandwidth- and synchronization-bound nature of backward computation.
We further evaluate cross-attention workloads with short K/V sequences (K = V = 256) under production settings. Across a wide range of Q lengths, the optimized GDPA kernel achieves nearly 2× forward and up to 1.6× backward speedup over the Triton baseline, while Blackwell FMHA quickly plateaus, as shown in Fig. 10. Increasing Q length yields limited gains, since the kernel is primarily inner-loop bound with sufficient outer-loop parallelism. Notably, under short-K/V settings, our optimized GDPA kernel significantly outperforms the baseline attention kernels, achieving up to 3.5× speedup in the forward pass and 1.6× in the backward pass compared to FA4. This effectively addresses the performance degradation observed in FA4 under real-world traffic patterns with short K/V sequences.
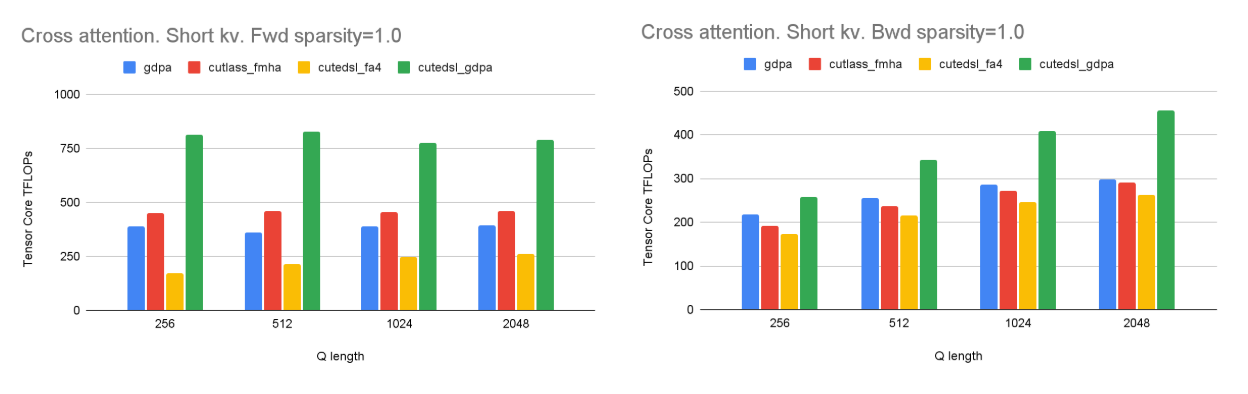
Fig. 10. Cross-attention performance with short K/V (256). Our optimized GDPA scales with Q length for both fwd and bwd, while FA4 plateaus in the short-K/V regime, with avg 3.5× forward and 1.6× backward speedup over FA4 under real-world production traffic settings.
Finally, we evaluate our optimized kernel on a production model under real production traffic. As shown in Fig. 11, compared to the baseline, both the forward and backward kernels achieve up to 2× speedup, and the performance moves significantly closer to the theoretical peak observed in benchmark settings. While a gap remains, we attribute this primarily to the high degree of data randomness in real workloads, where certain corner cases prevent perfectly balanced execution. As future work, we plan to further tune the kernel for real-world traffic patterns to better close this gap.
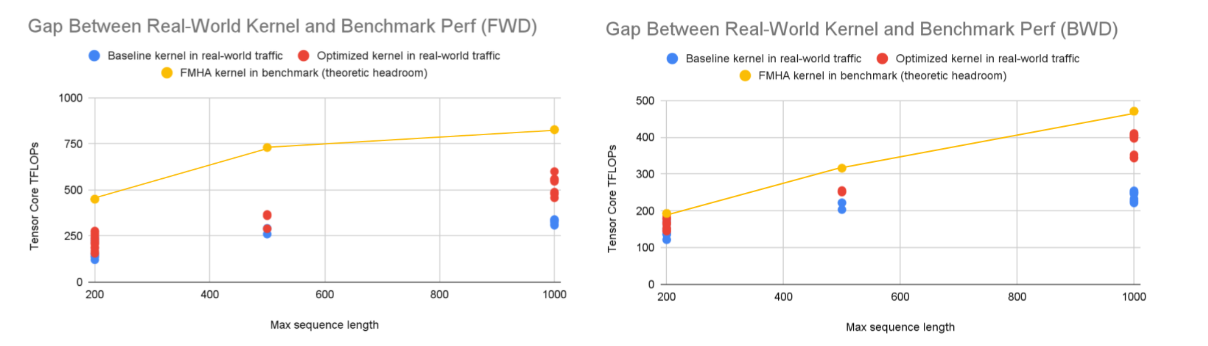
Fig. 11. Real-world vs. benchmark kernel performance. Our optimized GDPA kernel consistently outperforms the baseline in both forward and backward passes, achieving up to 2× speedup.
5. Conclusions
We present a production-driven design of GDPA kernels optimized for RecSys training workloads. This work demonstrates how kernel-level gains developed in academic settings can be translated into practical, production-ready improvements. Targeting workloads characterized by jagged inputs, short and asymmetric K/V dimensions, and non-softmax activations, we redesign the kernel pipeline, introduce software-level tile scheduling, and rebalance computation away from SFUs. As a result, our optimized GDPA kernel achieves up to 2× forward and 1.6× backward speedup over the Triton baseline on NVIDIA B200 GPUs, and significantly outperforms SOTA attention kernels under irregular, real-world input shapes. When applied across multiple modules in the full model, these customized kernels deliver over 30% end-to-end throughput improvement, highlighting the impact of production-driven kernel design on modern GPUs.
Acknowledgements
We would like to thank Tri Dao, Markus Hoehnerbach, Jay Shah, Ted Zadouri and Vijay. Thanks for their open-source work, which provided the foundation for our GDPA kernel design and many of the ideas explored in this post.
References
[1] Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design: https://arxiv.org/abs/2602.10016
[2] InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction https://arxiv.org/abs/2411.09852
[3] Meta’s Generative Ads Model (GEM): The Central Brain Accelerating Ads Recommendation AI Innovation https://engineering.fb.com/2025/11/10/ml-applications/metas-generative-ads-model-gem-the-central-brain-accelerating-ads-recommendation-ai-innovation/
[4] Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations https://arxiv.org/pdf/2402.17152
[5] FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision https://arxiv.org/pdf/2407.08608
[6] Triton tutorials: 06-fused-attention https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html