Beam search decoding with industry-leading speed from Flashlight Text (part of the Flashlight ML framework) is now available with official support in TorchAudio, bringing high-performance beam search and text utilities for speech and text applications built on top of PyTorch. The current integration supports CTC-style decoding, but it can be used for any modeling setting that outputs token-level probability distributions over time steps.
A brief beam search refresher
In speech and language settings, beam search is an efficient, greedy algorithm that can convert sequences of continuous values (i.e. probabilities or scores) into graphs or sequences (i.e. tokens, word-pieces, words) using optional constraints on valid sequences (i.e. a lexicon), optional external scoring (i.e. an LM which scores valid sequences), and other score adjustments for particular sequences.
In the example that follows, we’ll consider — a token set of {ϵ, a, b}, where ϵ is a special token that we can imagine denotes a space between words or a pause in speech. Graphics here and below are taken from Awni Hannun’s excellent distill.pub writeup on CTC and beam search.
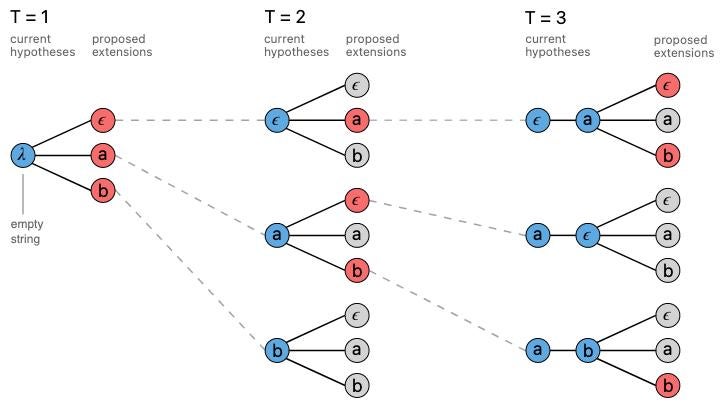
With a greedy-like approach, beam search considers the next viable token given an existing sequence of tokens — in the example above, a, b, b is a valid sequence, but a, b, a is not. We rank each possible next token at each step of the beam search according to a scoring function. Scoring functions (s) typically looks something like:
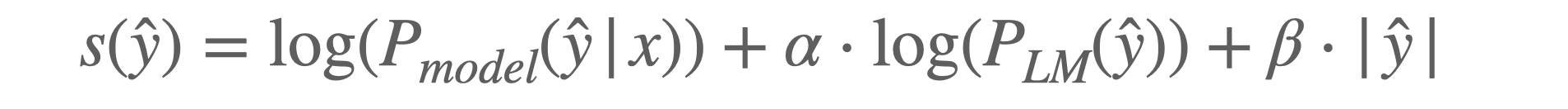
Where ŷ is a potential path/sequence of tokens, x is the input (P(ŷ|x) represents the model’s predictions over time), and 𝛼 is a weight on the language model probability (P(y) the probability of the sequence under the language model). Some scoring functions add 𝜷 which adjusts a score based on the length of the predicted sequence |ŷ|. This particular scoring function is used in FAIR’s prior work on end-to-end ASR, and there are many variations on scoring functions which can vary across application areas.
Given a particular sequence, to assess the next viable token in that sequence (perhaps constrained by a set of allowed words or sequences, such as a lexicon of words), the beam search algorithm scores the sequence with each candidate token added, and sorts token candidates based on those scores. For efficiency and since the number of paths is exponential in the token set size, the top-k highest-scoring candidates are kept — k represents the beam size.
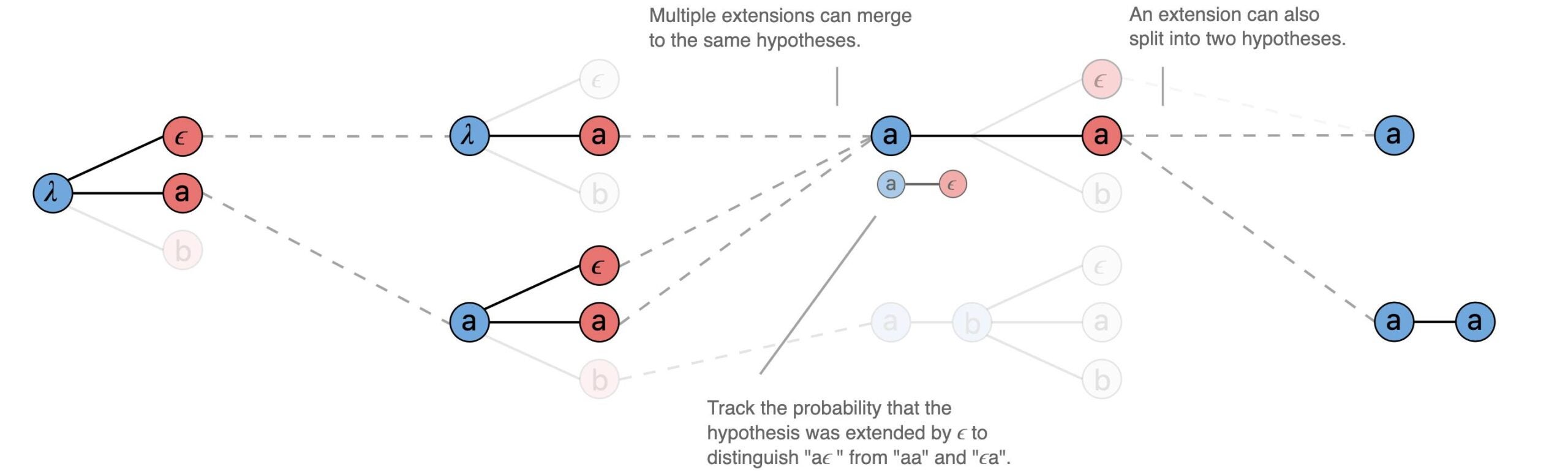
There are many other nuances with how beam search can progress: similar hypothesis sequences can be “merged”, for instance.
The scoring function can be further augmented to up/down-weight token insertion or long or short words. Scoring with stronger external language models, while incurring computational cost, can also significantly improve performance; this is frequently referred to as LM fusion. There are many other knobs to tune for decoding — these are documented in TorchAudio’s documentation and explored further in TorchAudio’s ASR Inference tutorial. Since decoding is quite efficient, parameters can be easily swept and tuned.
Beam search has been used in ASR extensively over the years in far too many works to cite, and in strong, recent results and systems including wav2vec 2.0 and NVIDIA’s NeMo.
Why beam search?
Beam search remains a fast competitor to heavier-weight decoding approaches such as RNN-Transducer that Google has invested in putting on-device and has shown strong results with on common benchmarks. Autoregressive text models at scale can benefit from beam search as well. Among other things, beam search gives:
- A flexible performance/latency tradeoff — by adjusting beam size and the external LM, users can sacrifice latency for accuracy or pay for more accurate results with a small latency cost. Decoding with no external LM can improve results at very little performance cost.
- Portability without retraining — existing neural models can benefit from multiple decoding setups and plug-and-play with external LMs without training or fine-tuning.
- A compelling complexity/accuracy tradeoff — adding beam search to an existing modeling pipeline incurs little additional complexity and can improve performance.
Performance Benchmarks
Today’s most commonly-used beam search decoding libraries today that support external language model integration include Kensho’s pyctcdecode, NVIDIA’s NeMo toolkit. We benchmark the TorchAudio + Flashlight decoder against them with a wav2vec 2.0 base model trained on 100 hours of audio evaluated on LibriSpeech dev-other with the official KenLM 3-gram LM. Benchmarks were run on Intel E5-2698 CPUs on a single thread. All computation was in-memory — KenLM memory mapping was disabled as it wasn’t widely supported.
When benchmarking, we measure the time-to-WER (word error rate) — because of subtle differences in the implementation of decoding algorithms and the complex relationships between parameters and decoding speed, some hyperparameters differed across runs. To fairly assess performance, we first sweep for parameters that achieve a baseline WER, minimizing beam size if possible.
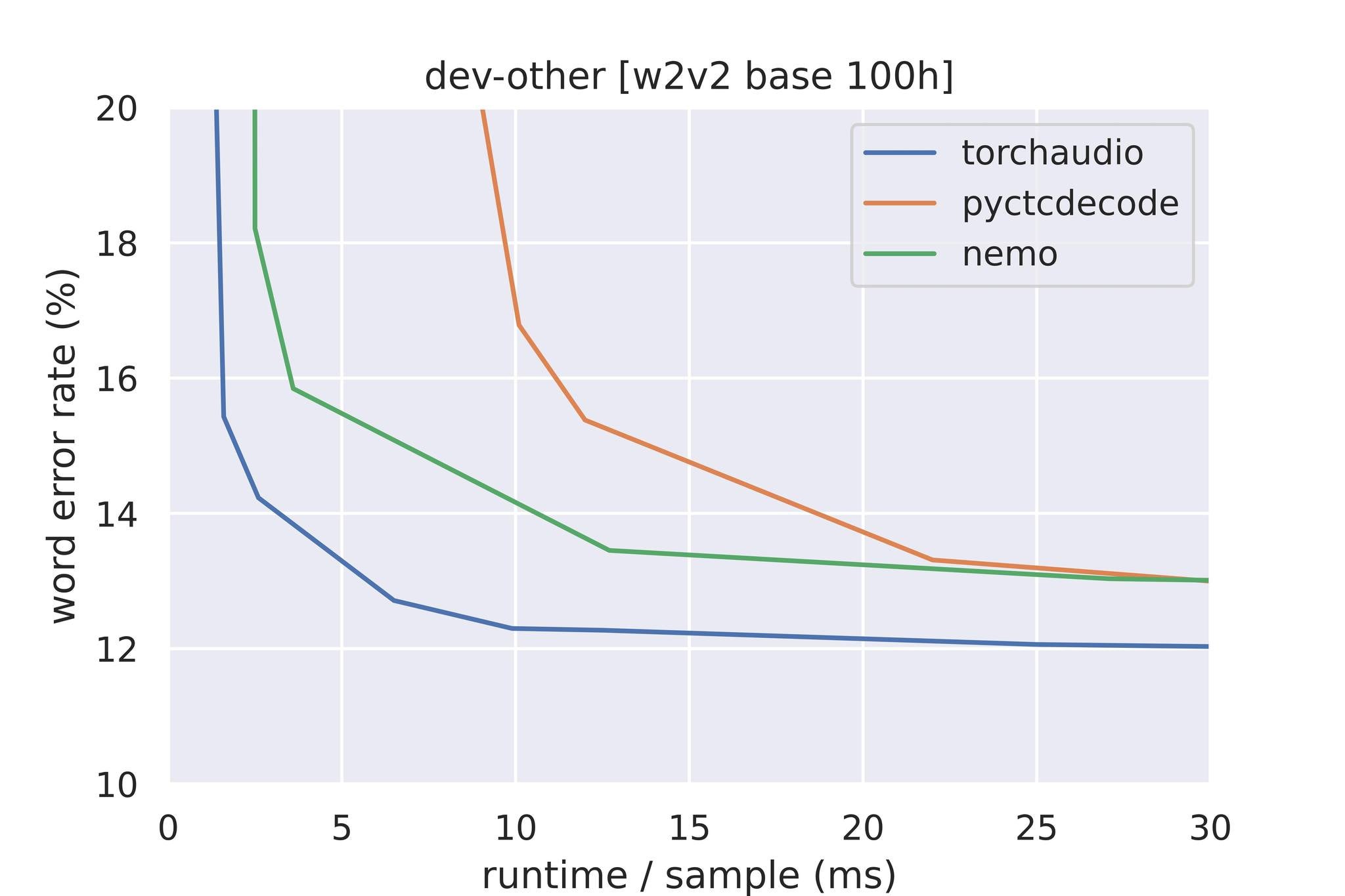
Decoding performance on Librispeech dev-other of a pretrained wav2vec 2.0 model. TorchAudio + Flashlight decoding outperforms by an order of magnitude at low WERs.
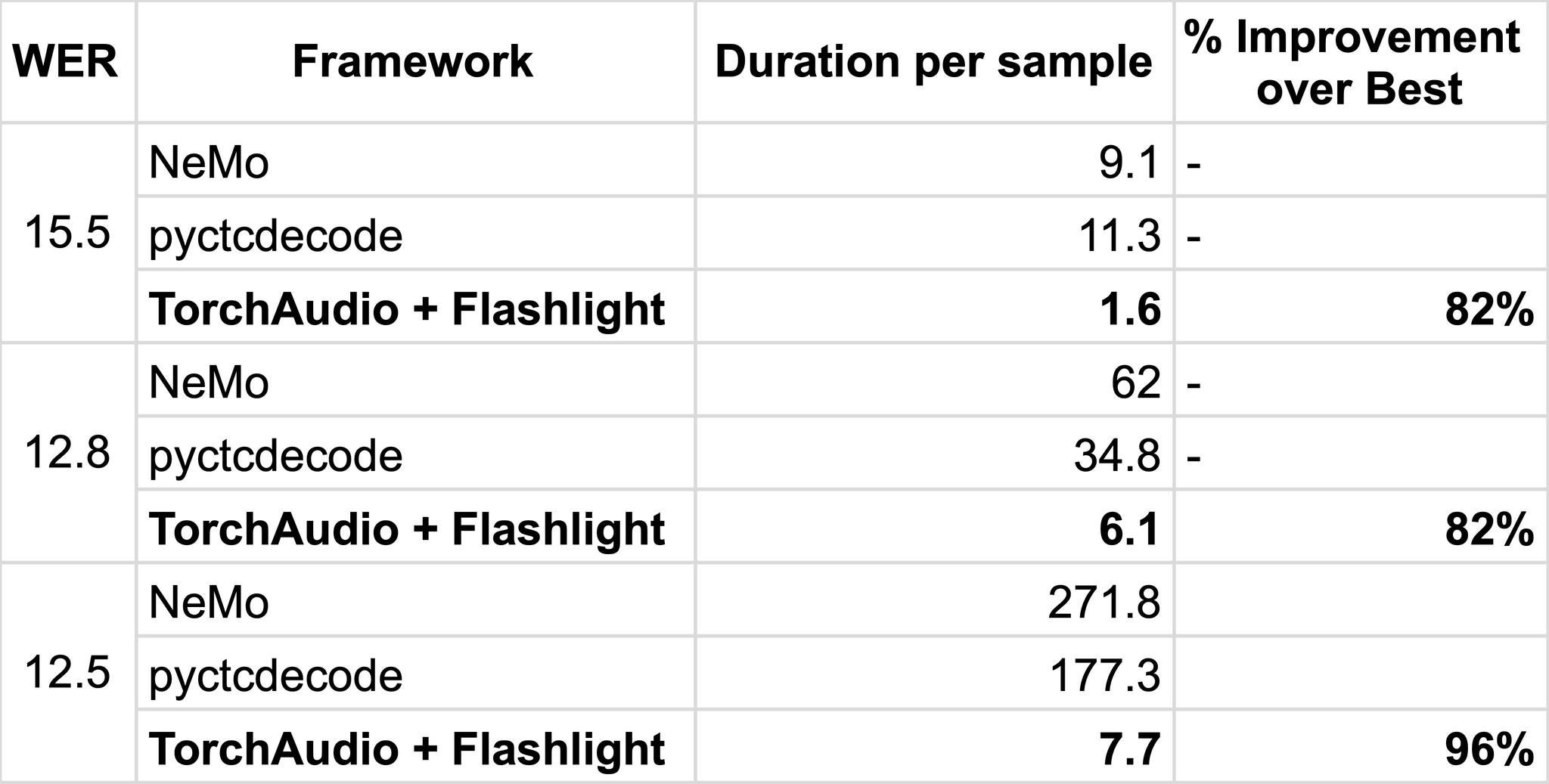
Time-to-WER results, deferring to smaller beam size, across decoders. The TorchAudio + Flashlight decoder scales far better with larger beam sizes and at lower WERs.
TorchAudio API and Usage
TorchAudio provides a Python API for CTC beam search decoding, with support for the following:
- lexicon and lexicon-free decoding
- KenLM n-gram language model integration
- character and word-piece decoding
- sample pretrained LibriSpeech KenLM models and corresponding lexicon and token files
- various customizable beam search parameters (beam size, pruning threshold, LM weight…)
To set up the decoder, use the factory function torchaudio.models.decoder.ctc_decoder
from torchaudio.models.decoder import ctc_decoder, download_pretrained_files
files = download_pretrained_files("librispeech-4-gram")
decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
nbest=1,
... additional optional customizable args ...
)
Given emissions of shape (batch, time, num_tokens), the decoder will compute and return a List of batch Lists, each consisting of the nbest hypotheses corresponding to the emissions. Each hypothesis can be further broken down into tokens, words (if a lexicon is provided), score, and timesteps components.
emissions = acoustic_model(waveforms) # (B, T, N)
batch_hypotheses = decoder(emissions) # List[List[CTCHypothesis]]
# transcript for a lexicon decoder
transcripts = [" ".join(hypo[0].words) for hypo in batch_hypotheses]
# transcript for a lexicon free decoder, splitting by sil token
batch_tokens = [decoder.idxs_to_tokens(hypo[0].tokens) for hypo in batch_hypotheses]
transcripts = ["".join(tokens) for tokens in batch_tokens]
Please refer to the documentation for more API details, and the tutorial (ASR Inference Decoding) or sample inference script for more usage examples.
Upcoming Improvements
Full NNLM support — decoding with large neural language models (e.g. transformers) remains somewhat unexplored at scale. Already supported in Flashlight, we plan to add support in TorchAudio, allowing users to use custom decoder-compatible LMs. Custom word level language models are already available in the nightly TorchAudio build, and is slated to be released in TorchAudio 0.13.
Autoregressive/seq2seq decoding — Flashlight Text also supports sequence-to-sequence (seq2seq) decoding for autoregressive models, which we hope to add bindings for and add to TorchAudio and TorchText with efficient GPU implementations as well.
Better build support — to benefit from improvements in Flashlight Text, TorchAudio will directly submodule Flashlight Text to make upstreaming modifications and improvements easier. This is already in effect in the nightly TorchAudio build, and is slated to be released in TorchAudio 0.13.
Citation
To cite the decoder, please use the following:
@inproceedings{kahn2022flashlight,
title={Flashlight: Enabling innovation in tools for machine learning},
author={Kahn, Jacob D and Pratap, Vineel and Likhomanenko, Tatiana and Xu, Qiantong and Hannun, Awni and Cai, Jeff and Tomasello, Paden and Lee, Ann and Grave, Edouard and Avidov, Gilad and others},
booktitle={International Conference on Machine Learning},
pages={10557--10574},
year={2022},
organization={PMLR}
}
@inproceedings{yang2022torchaudio,
title={Torchaudio: Building blocks for audio and speech processing},
author={Yang, Yao-Yuan and Hira, Moto and Ni, Zhaoheng and Astafurov, Artyom and Chen, Caroline and Puhrsch, Christian and Pollack, David and Genzel, Dmitriy and Greenberg, Donny and Yang, Edward Z and others},
booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={6982--6986},
year={2022},
organization={IEEE}
}