The Challenge of PyTorch 2.0 Compilation
Since the release of PyTorch 2.0 (PT2) and its powerful new compilation infrastructure, researchers and engineers have benefited from dramatic improvements in model execution speed and runtime efficiency. However, these gains come at a cost: initial compilation can become a significant bottleneck, especially for large and complex models like the ones used internally at Meta for recommendation.
Understanding Compilation Bottlenecks
PT2 introduces a compilation step that transforms Python model code into high-performance machine code before execution.
While the result is faster training and inference, compiling very large models can take up to an hour—or more—especially on cold starts, for some of our internal recommendation models with complex model architectures beyond Transformers.
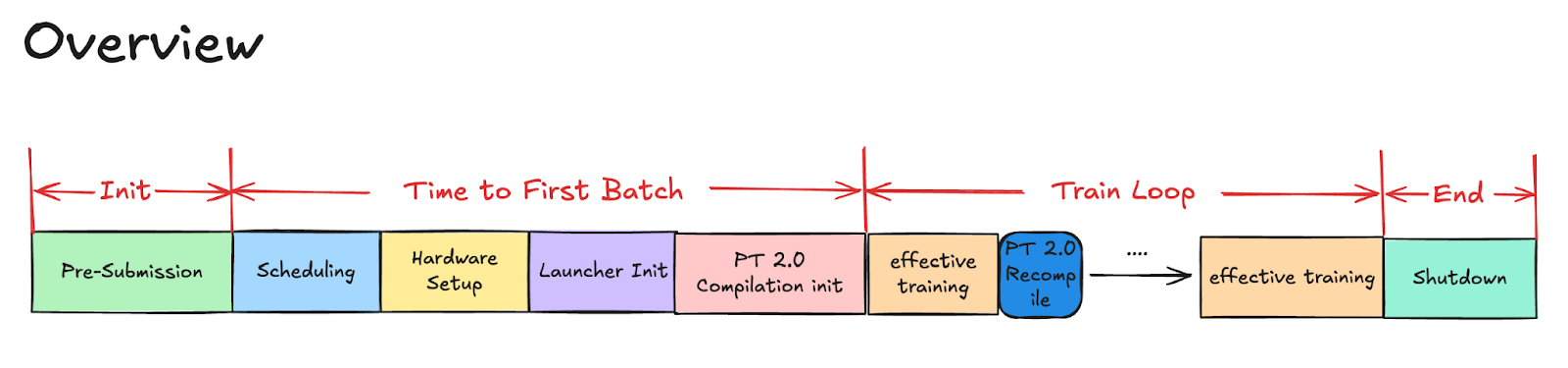
Figure 1. Training Overview
In late 2024, we undertook a focused initiative to break down and reduce PT2 compilation time for one of our largest foundation models. We begin by running a comprehensive, long-duration compilation job to perform a detailed analysis of the PT2 compilation process.
Tlparse
Tlparse parses structured torch trace logs and outputs HTML files analyzing data. This allows us to identify bottlenecks in various stages of compilation.
Run PyTorch with the TORCH_TRACE environment variable set:
TORCH_TRACE=/tmp/my_traced_log_dir example.py
|
Feed input into tlparse:
tlparse /tmp/my_traced_log_dir -o tl_out/ |
The result organizes the log into several easy-to-consume sections, highlighting each time the analysis restarted, any graph breaks, and more. It also provides trace files to help you analyze execution and performance in detail.
You can refer to those steps if you need more information to run the Tlpase.
Example result:
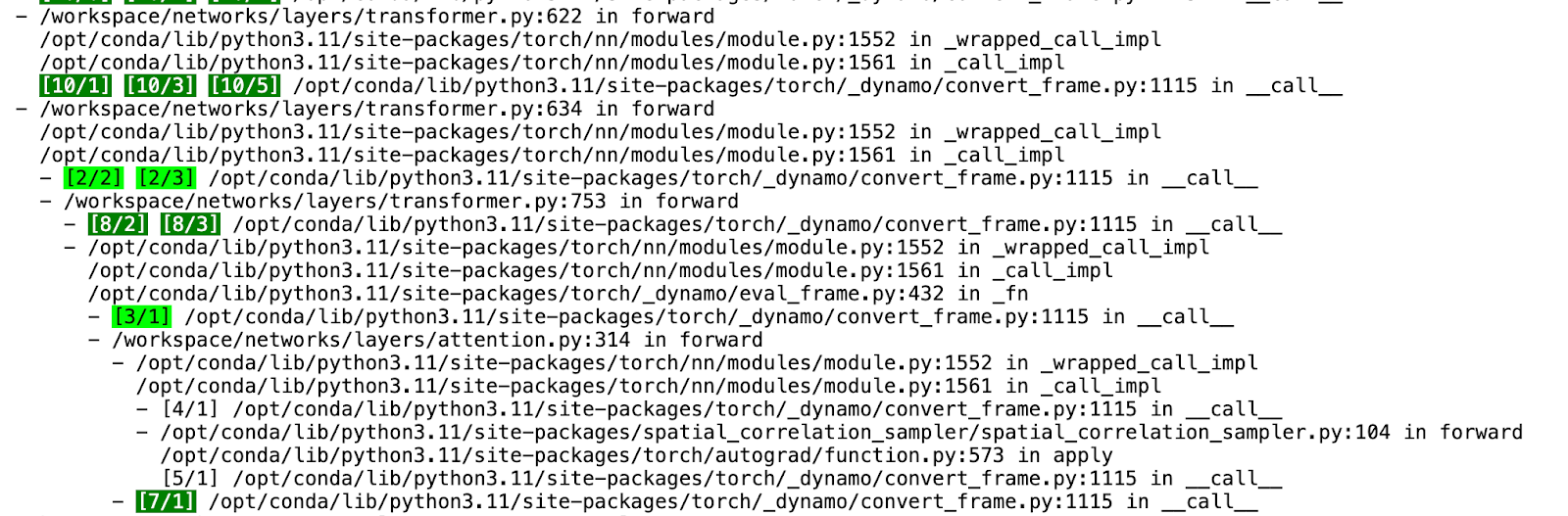
Figure 2. PT2 Compilation HTML
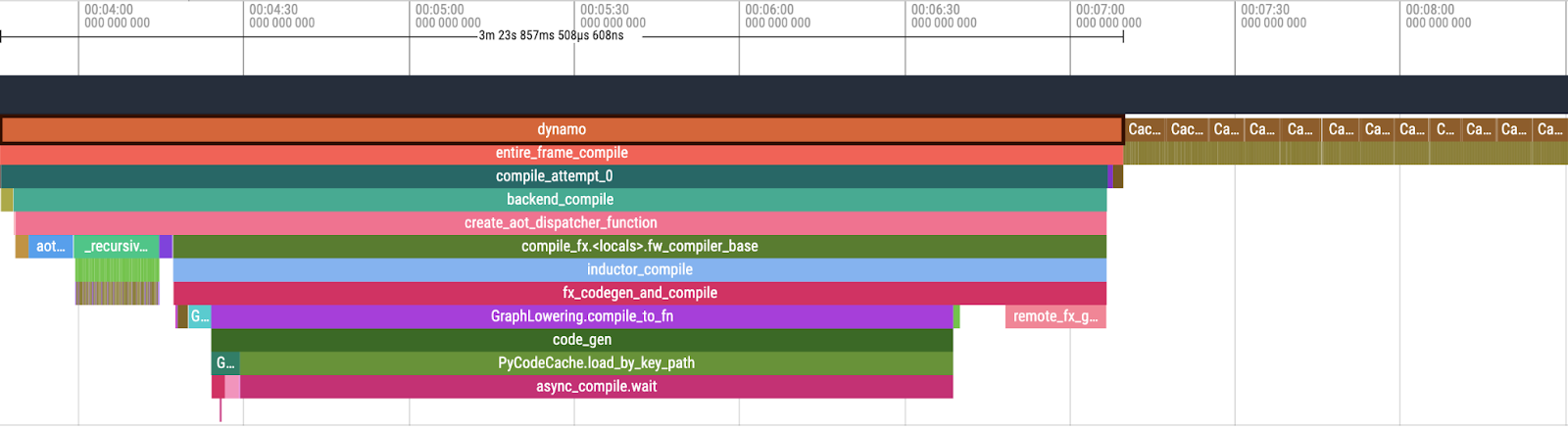
Figure 3. PT2 Compilation Overview in Perfetto UI
When examining the output of Tlparse, we focus on the following key components of the PT2 compilation stack:
- Dynamo: initial stage responsible for dynamic graph transformations and optimizations.
- AOTInductor (AOTDispatch): overloads PyTorch’s autograd engine as a tracing autodiff for generating ahead-of-time backward traces.
- TorchInductor: a deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA and AMD GPUs, it uses OpenAI Triton as a key building block.
Following this analysis, we systematically address each bottleneck area with targeted improvements to reduce overall compilation time.
| Phase | Time (exclusive, seconds) |
| Total | 1825.58 |
| Dynamo | 100.64 (5.5%) |
| AOTDispatch | 248.03 (13.5%) |
| TorchInductor | 1238.50 (67.8%)
Most of it is async_compile.wait (843.95) |
| CachingAutotuner.benchmark_all_configs | 238.00 (13.0%) |
| Remainder (inductor) | 0.41 (0%) |
Key Focus Areas for Reducing PT2 Compilation Time
Based on the analysis of baseline compilation jobs, we have identified several critical areas to target for reducing overall compilation time, especially for cold starts:
- Identify and optimize the most time-consuming regions to minimize the number of compilation times.
- Enhance the async_compile.wait process to accelerate Triton compilation.
- Effectively prune Triton autotuning configurations, particularly for user-defined kernel configs, to reduce both compilation and benchmarking times.
- Improve overall PT2 cache performance and increase cache hit rates for downstream jobs.
Technique Deep-Dives
Over the past year, we have collaborated with multiple teams across Meta to develop and implement several new technologies aiming at reducing PT2 compilation time. Below is an overview of the key technologies applied to our foundation model.
1. Maximize Parallelism With Triton Compilation
This optimization includes two key improvements: avoiding Triton compilation in the parent process and starting Triton compilation earlier by calling Triton in worker processes with the future cache to increase the parallelism of compilation processes.
Specifically, our parallel compile workers now compile Triton kernels and pass the compiled results directly to the parent process, eliminating the need for redundant compilation in the parent. This enhances parallelism and reduces overall compile time.
2. Dynamic Shape Marking
- mark_dynamic
The use of the mark_dynamic API from PyTorch aids in identifying dynamic shapes before compilation. Since many recompilations occur due to changes in tensor shapes during compilation, marking these shapes as dynamic can significantly reduce the number of recompilations. This, in turn, improves the overall PT2 compilation time.
This process involves marking tensors as dynamic and handling specializations individually. Initially, it was challenging to determine the specializations and the best way to mark them as dynamic, requiring numerous experiments and proving to be quite complex.
Throughout this process, we developed tools and technologies to simplify the use of mark_dynamic, including enhanced logging for dynamic info in tlparse.
Example:
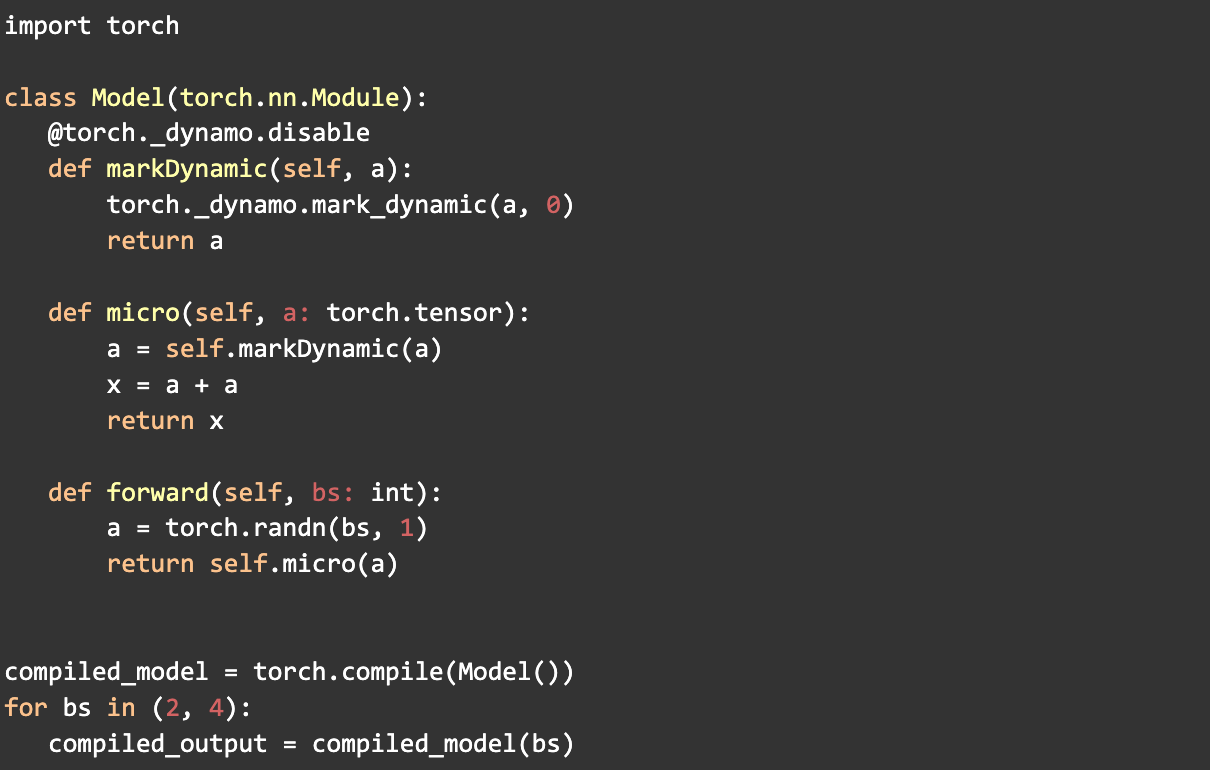
- TORCH_COMPILE_DYNAMIC_SOURCES
The introduction of the dynamic sources whitelist (TORCH_COMPILE_DYNAMIC_SOURCES) has improved the handling of dynamic shapes for parameters by providing an easy and user-friendly way to mark parameters as dynamic without modifying the underlying code. This feature also supports marking integers as dynamic and allows the use of regular expressions to include a broader range of parameters, enhancing flexibility and reducing compilation time.
Example:

3. Autotuning Configuration Pruning
We found that the number of user kernels and user-defined configurations applied to the foundation model significantly impacts PT2 compilation
Because PT2 autotuning automatically benchmarks many possible runtime configurations for each kernel to find the most efficient one, which can be very time-consuming when there are many kernels and configurations.
To address this, we developed a process to identify the most time-consuming kernels and determine optimal runtime configurations for implementation in the codebase. This approach has led to a substantial reduction in compilation time.
4. Improve Caching Hit Rates
Profile-guided optimization(PGO) can disrupt caching, leading to non-deterministic cache keys, which cause cache misses and result in long compilation time.
w/o PGO

w PGO

To resolve this, the team implemented the hash function to generate consistent symbolic IDs for stable assignment and use linear probing to avoid symbol collisions (details).
This change dramatically improved cache hit rates for both warm runs within a job and across different jobs using the remote cache.
5. Optimize Kernel Launching
Regular Triton kernels have a high launch cost due to needing to codegen C++ at compile time, and have low cache hit rates on ads models. The StaticCudaLauncher is a new PyTorch launcher for Triton-generated CUDA kernels, which we used as the default launcher for all Triton kernels. This led to faster compile times on both cold and warm start.
6. Mega-Caching
MegaCache brings together several types of PT2 compilation caches—including components like inductor (the core PT2 compiler), triton bundler (for GPU code), AOT Autograd (for efficient gradient computation), Dynamo PGO (profile-guided optimizations), and autotune settings—into a single archive that can be easily downloaded and shared.
By consolidating these elements, MegaCache offers those improvements:
- Minimizes repeated requests to remote servers
- Cuts down on time spent setting up models
- Makes startup and retried jobs more dependable, even in distributed or cloud environments
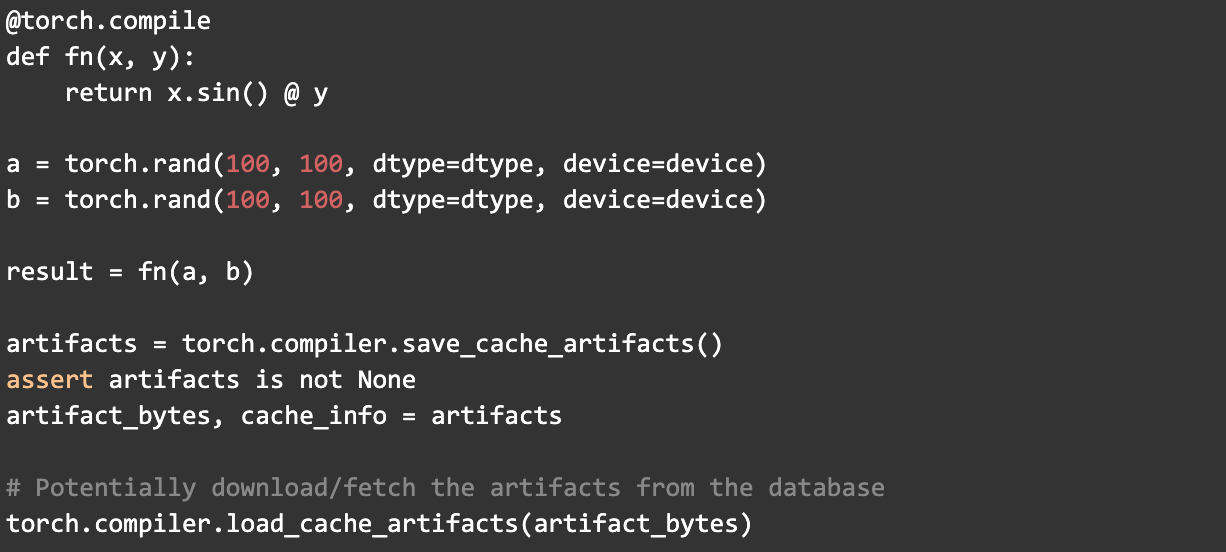
Mega-Cache provides two compiler APIs:
- torch.compiler.save_cache_artifacts()
- torch.compiler.load_cache_artifacts()
Take this as an example:
Results and Impact: >80% Faster Compilation
Thanks to our optimization efforts, the compilation time for one of our largest foundation models during offline training has been reduced by more than 80%, decreasing from around 3000 seconds to just under 500 seconds over the past year.
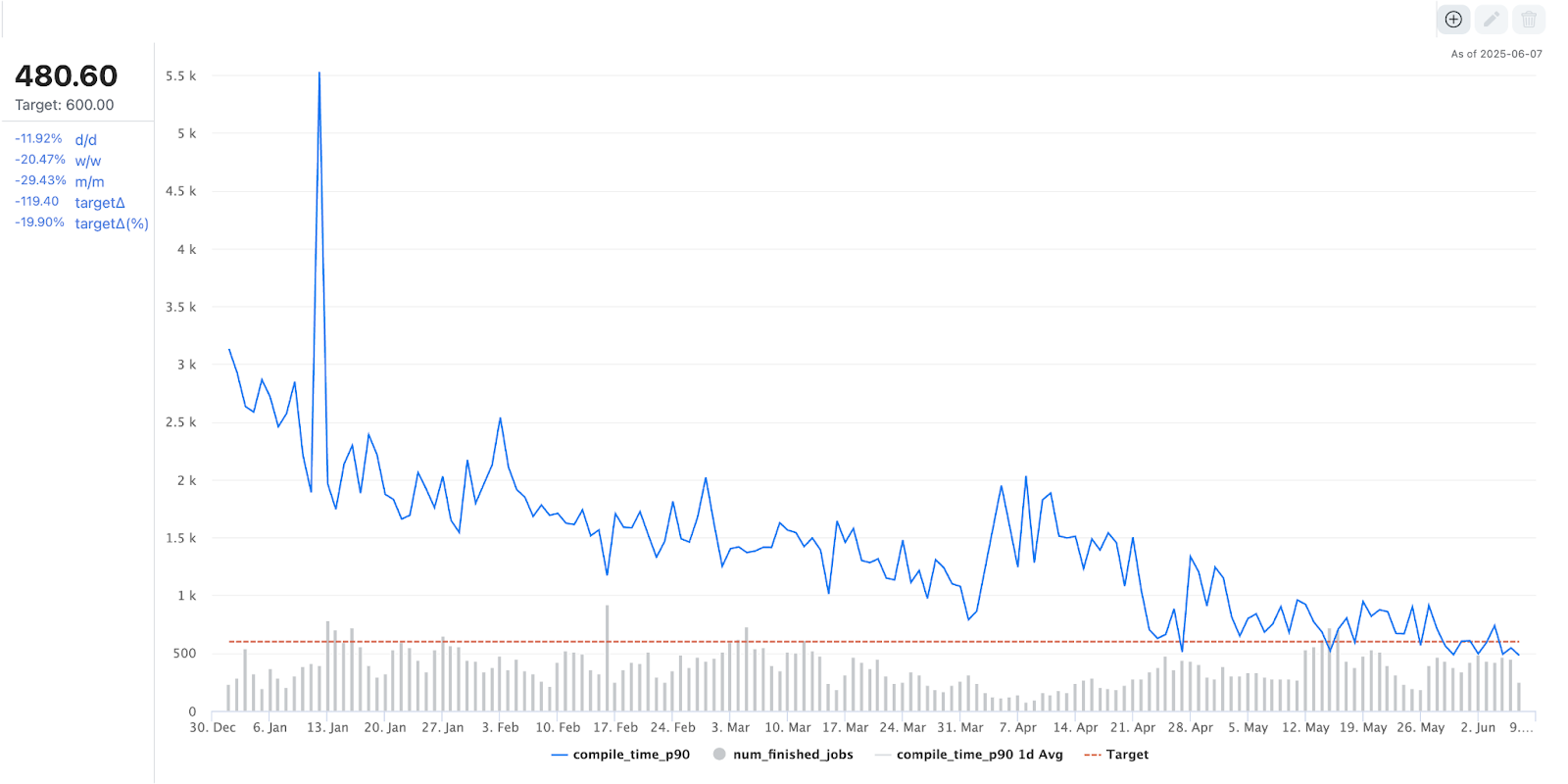
Figure 4. PT2 Compilation Time Trend
In the End
We have integrated these optimizations into the PT2 compiler stack, making them the default for all users compiling models with PT2. Our generalized transformation approach is designed to benefit a wide range of models beyond Meta’s ecosystem, and we welcome ongoing discussions and improvements inspired by this work.
Acknowledgements
Many thanks to Max Leung, Musharaf Sultan, John Bocharov, and Gregory Chanan for their insightful support and reviews.