TL;DR
In a joint effort between PyTorch and Nebius, we enabled training DeepSeek-V3 Mixture-of-Experts models (16B and 671B) on a 256-GPU NVIDIA B200 cluster using TorchTitan. We evaluated two orthogonal optimizations on top of a BF16 baseline: MXFP8 training (via TorchAO) and DeepEP communication acceleration (via DeepEP). The highlights:
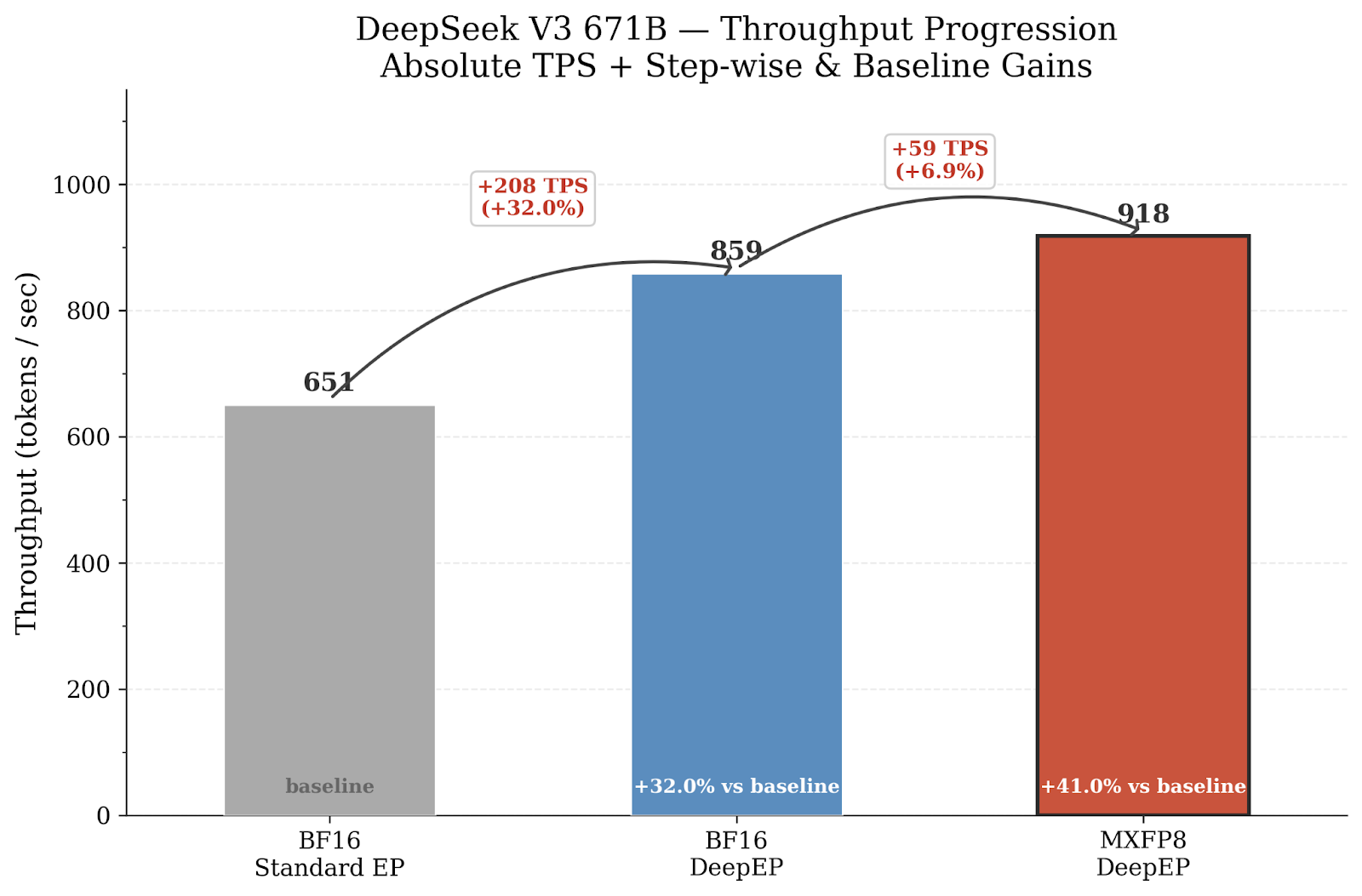
- DeepSeek-V3 671B: DeepEP alone yields 859 token/sec (+32%) over the BF16 baseline (651 token/sec). Adding MXFP8 on grouped GEMMs and combining that with DeepEP pushes the performance to 918 token/sec, a +41% total throughput gain.
- DeepSeek-V3 16B MoE: Loss convergence experiments over 1,500 steps confirm that MXFP8 training is equivalent to BF16 (No degradation in convergence behavior).
All experiments ran on Nebius Cloud using open-source PyTorch-native tooling and are fully reproducible. Please refer to the last section (Reproducibility), to get access to all recipes.
Why This Experiment
Training frontier-scale MoE models demands both software maturity and system-level efficiency. With the arrival of NVIDIA Blackwell (B200) GPUs and their native MXFP8 tensor core support, there is an opportunity to push beyond “faster training” toward significantly better cost-performance, especially for MoE architectures where both compute and inter-GPU communication are bottlenecks.
Using TorchTitan as the pre-training framework, we set out to answer these questions:
- How much can MXFP8 accelerate computation? Blackwell’s 5th-generation tensor cores natively support MXFP8, enabling up to 2x higher peak TFLOPS over BF16 for eligible GEMMs. We wanted to measure the real end-to-end speedup when applying MXFP8 (via TorchAO) to DeepSeek-V3’s routed experts (grouped GEMMs) and linear layers within TorchTitan.
- How much can DeepEP accelerate communication? MoE models require two all-to-all exchanges per layer to dispatch tokens to experts and combine their outputs. Because transfer sizes and destinations are determined dynamically by the router at each step, standard collective communication proves to be inefficient since it is typically designed for fixed transfer sizes known ahead of time. As EP grows, the problem worsens and all-to-all becomes a large bottleneck. DeepEP replaces the standard all-to-all backend with purpose built NVLink and RDMA kernels that reduce CPU involvement by allowing GPUs to directly send weights, reducing latency. This is better suited for this variable workload. We wanted to quantify the throughput gain from reducing this communication bottleneck in TorchTitan’s expert-parallel pipeline.
- Do these computation and communication gains compose? MXFP8 targets compute (GEMMs) while DeepEP targets communication (all-to-all). We wanted to verify that applying both within TorchTitan yields a cumulative speedup greater than either alone, and demonstrate stable end-to-end pre-training at scale with this combined configuration.
Background
Before diving into the experiments, this section provides a brief overview of the two key technologies we evaluate: MXFP8 mixed-precision training (including the different recipes we tested) and DeepEP’s optimized expert-parallel communication.
MXFP8: Microscaling FP8 via TorchAO
MXFP8 (Microscaling FP8) is a low-precision numerical format defined by the OCP Microscaling Specification. Unlike standard float8 which uses a single scale factor per tensor or per row, MXFP8 assigns a shared exponent (E8M0 scale) to every block of 32 elements. This finer-grained scaling preserves numerical fidelity while still enabling the hardware’s FP8 tensor cores.
NVIDIA Blackwell GPUs provide native hardware support for MXFP8 through their tcgen05.mma tensor core instructions, meaning that MXFP8 GEMMs run at the full FP8 throughput without emulation overhead. This makes B200 the natural hardware target for MXFP8 training.
In practice, MXFP8 is applied through TorchAO which provides:
- MXFP8 for linear layers: Converts nn.Linear layers to dynamically quantize inputs to MXFP8 for all three GEMMs (forward output, input gradient, weight gradient) in each linear layer, with accumulation back to BF16.
- MXFP8 for grouped GEMMs: Converts torch._grouped_mm ops to use TorchAO’s _to_mxfp8_then_scaled_grouped_mm autograd function, which dynamically quantizes inputs to MXFP8 for all three grouped GEMMs (forward output, input gradient, weight gradient), providing a net speedup on the grouped matrix multiplications that dominate MoE expert layers.
In our experiments we use two MXFP8 configurations:
| Configuration | Description |
| MXFP8 for all grouped GEMMs | MXFP8 applied to grouped GEMMs |
The MXFP8 GMM recipe dynamically quantizes inputs immediately before each grouped GEMM. This works well when the GEMMs are large; the compute cost grows as O(GMNK), while the quantization overhead grows only as O(MK) for inputs or O(GNK) for weights, so for large dimensions the overhead becomes negligible and the net speedup is significant. However, when GEMM dimensions are small (as in smaller MoE models), the quantization overhead can match or exceed the MXFP8 speedup, resulting in neutral or even negative performance.
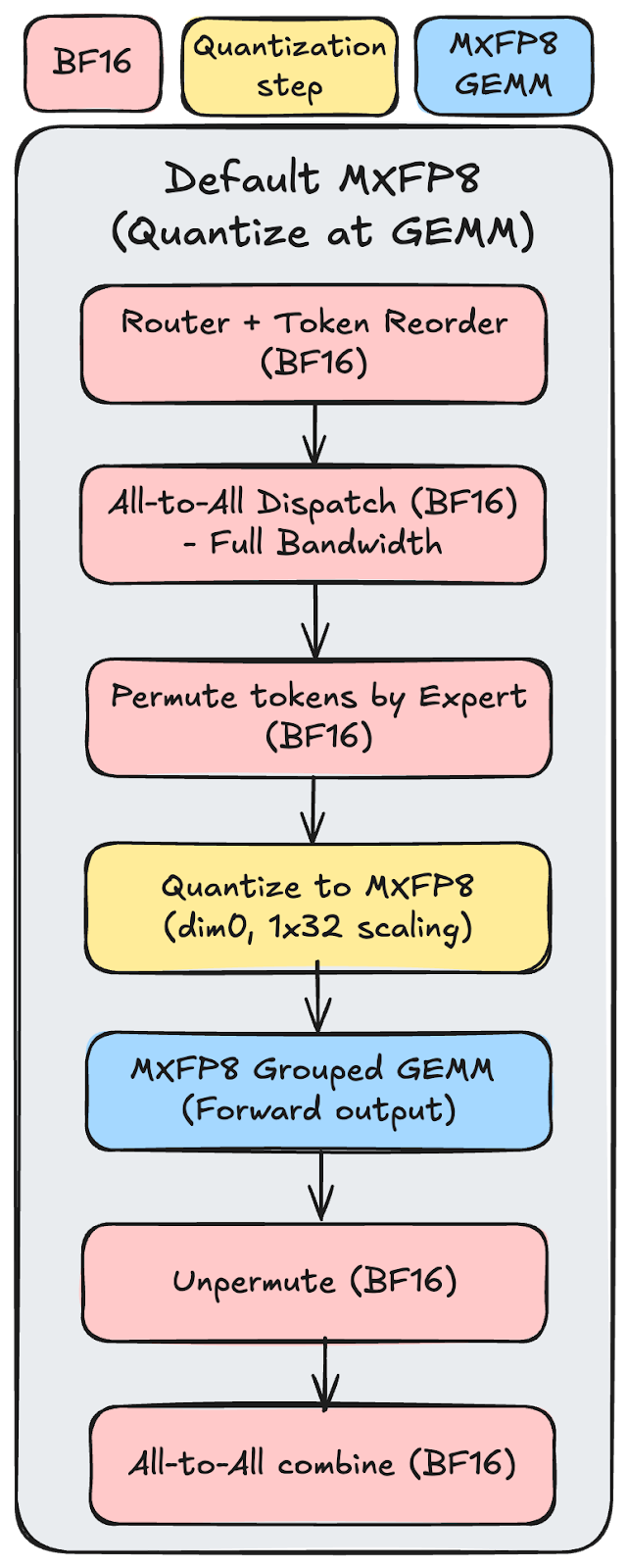
Figure 1: MXFP8 default process from Router input to all-to-all combined output
DeepEP: Optimized Expert-Parallel Communication
DeepEP is a GPU communication library developed by DeepSeek, purpose-built for the all-to-all token dispatch and combine operations in MoE expert parallelism. In standard expert parallelism, every GPU may need to send tokens to (and receive tokens from) every other GPU based on the router’s decisions. Standard collective libraries (e.g., NCCL, RCCL) provide generic all-to-all primitives that do not exploit the structure of MoE workloads.
DeepEP addresses this with:
- Pipelined inter-node and intra-node comms: Data first moves via high-bandwidth NVLink within a node, then crosses nodes via RDMA over InfiniBand. This exploits the bandwidth asymmetry between intra-node (~900 GB/s NVLink) and inter-node interconnects.
- GPU-initiated RDMA built on NVSHMEM: DeepEP is built on top of NVSHMEM, which exposes a Partitioned Global Address Space (PGAS) where each GPU maps a symmetric memory region addressable by all peers. Combined with InfiniBand GPUDirect Async (IBGDA), GPUs can drive NIC operations directly from CUDA kernels without any CPU involvement, eliminating a key latency source for small, dynamic transfers.
- Fused metadata transfer: Token embeddings, expert indices, and routing weights are bundled into a single communication operation, reducing kernel launch and synchronization overhead.
- Configurable SM usage: Communication kernels can be tuned to use a specific number of streaming multiprocessors, freeing the rest for overlapping computation.
In our setup with 32 nodes (EP=32), DeepEP replaces the standard PyTorch all-to-all backend for the MoE dispatch/combine operations.
Hardware and Cluster Environment
The Nebius B200 Cluster
All experiments ran on a Nebius Cloud cluster with the following specifications:
| Component | Specification |
| Node count | 32 |
| GPUs per node | 8 x NVIDIA B200 |
| Total GPUs | 256 |
| Intra-node interconnect | NVLink / NVSwitch |
| Inter-node interconnect | InfiniBand |
| Scheduling | Soperator (Slurm + Kubernetes) |
Software Stack
| Component | Details |
| Training framework | TorchTitan |
| Mixed-precision | TorchAO (MXFP8) |
| Expert communication | DeepEP |
| Compilation | torch.compile (model + loss) |
| Dataset | C4 |
For infrastructure, we ran on Nebius Soperator, which brings Slurm-style scheduling and multi-node semantics to Kubernetes without exposing Kubernetes operational complexity to ML engineers. The environment was production-ready out of the box: a pre-configured, performance-optimized cluster with minimal setup required for this run. Two capabilities mattered most:
- First, Soperator continuously validates GPU and interconnect health using active checks (including NCCL all-reduce benchmarks) and passive signals (such as GPU XID errors), then automatically drains and replaces nodes that fall below performance thresholds. That same telemetry feeds into observability dashboards and alerting, which made troubleshooting faster and reduced time to root cause.
- Second, scaling is straightforward: resizing the cluster is a single command, and new nodes inherit the full runtime environment automatically. This let us focus on optimizing the training recipe rather than cluster bring-up, straggler mitigation, or rerunning failed jobs.
Experiment 1: DeepSeek-V3 671B
Training Configuration
| Parameter | Value |
| Model | DeepSeek-V3 671B |
| Nodes / GPUs | 32 / 256 |
| Sequence length | 8192 |
| Local batch size | 64 |
| Tensor Parallel (TP) | 2 |
| Pipeline Parallel (PP) | 2 |
| Data Parallel (DP) | 1 |
| FSDP | -1 (auto) |
| Context Parallel (CP) | 1 |
| Expert Parallel (EP) | 32 |
| Expert Tensor Parallel (ETP) | 1 |
| Activation checkpointing | Full |
| Compile | model, loss |
| Learning rate | 1e-4 |
| LR warmup steps | 2000 |
| Dataset | C4 |
Full Slurm scripts and TorchTitan training configs for all 671B configurations are available at the Nebius ML-CookBook repository.
Configurations Tested
We evaluated three configurations, varying the precision mode and the expert-parallel communication backend:
| Configuration | Precision | Expert Communication |
| BF16 + Standard EP | BF16 | Standard all-to-all |
| BF16 + DeepEP | BF16 | DeepEP |
| MXFP8 GMM + DeepEP | MXFP8 on all grouped GEMMs | DeepEP |
Throughput Results
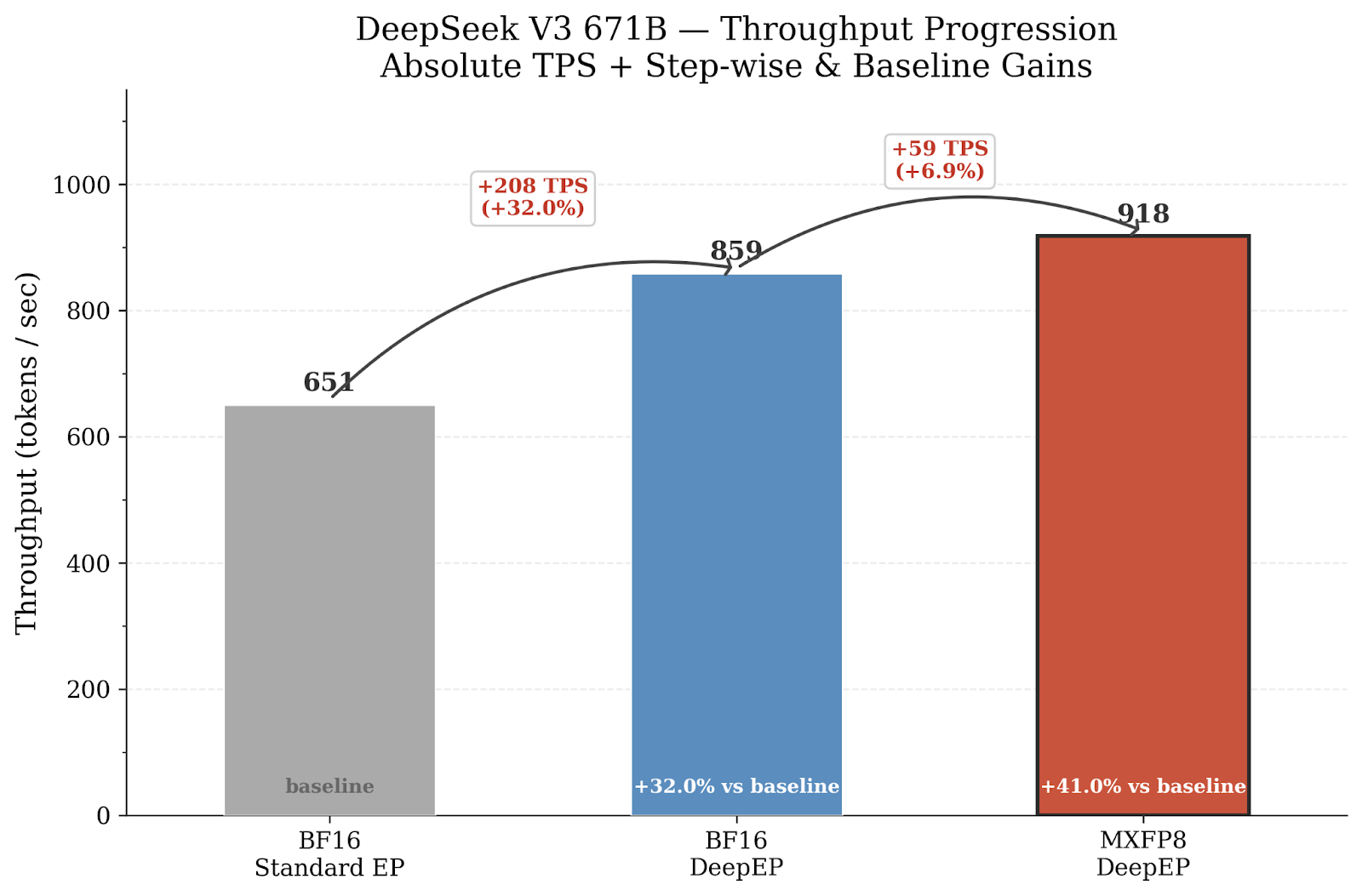
Figure2: Throughput (tokens/sec) for each configuration. Two different EP backend x two different precision. The chart showing how each optimization contributes to the total throughput gain. Starting from BF16 baseline (651 TPS), DeepEP adds another +32% on top of the BF16. Combination of DeepEP and MXFP adds +41% reaching 918 TPS total.
Key observations:
- DeepEP alone provides +32.0%. The single largest individual gain. For this 671B model with EP=32 across 32 nodes, inter-node all-to-all communication is a major bottleneck, and DeepEP’s optimized RDMA+NVLink forwarding dramatically reduces it.
- MXFP8 GMM + DeepEP compose well, reaching +41.0% combined. The gains are additive because they target different bottlenecks: MXFP8 accelerates compute (GEMMs) while DeepEP accelerates communication (all-to-all).
Experiment 2: DeepSeek-V3 16B MoE Loss Convergence Validation
Training Configuration
| Parameter | Value |
| Model | DeepSeek-V3 16B MoE |
| Nodes / GPUs | 32 / 256 |
| Sequence length | 8192 |
| Local batch size | 16 |
| Tensor Parallel (TP) | 1 |
| Pipeline Parallel (PP) | 1 |
| Data Parallel (DP) | 1 |
| FSDP | -1 (auto) |
| Context Parallel (CP) | 1 |
| Expert Parallel (EP) | 32 |
| Expert Tensor Parallel (ETP) | 1 |
| Activation checkpointing | Full |
| Compile | model, loss |
| Learning rate | 1e-4 |
| LR warmup steps | 2000 |
| Dataset | C4 |
Full Slurm scripts and TorchTitan training configs for all 16B configurations are available on Nebius ML-CookBook repository.
Configurations Tested
All 16B experiments used Standard EP (no DeepEP):
| Configuration | Description |
| BF16 | Baseline |
| MXFP8 (MXFP8 a2a EP Backend) | MXFP8 on grouped GEMMs only (expert parallel + GMM) |
Loss Convergence
We ran each 16B configuration for 1,500 training steps to verify that MXFP8 does not degrade convergence.
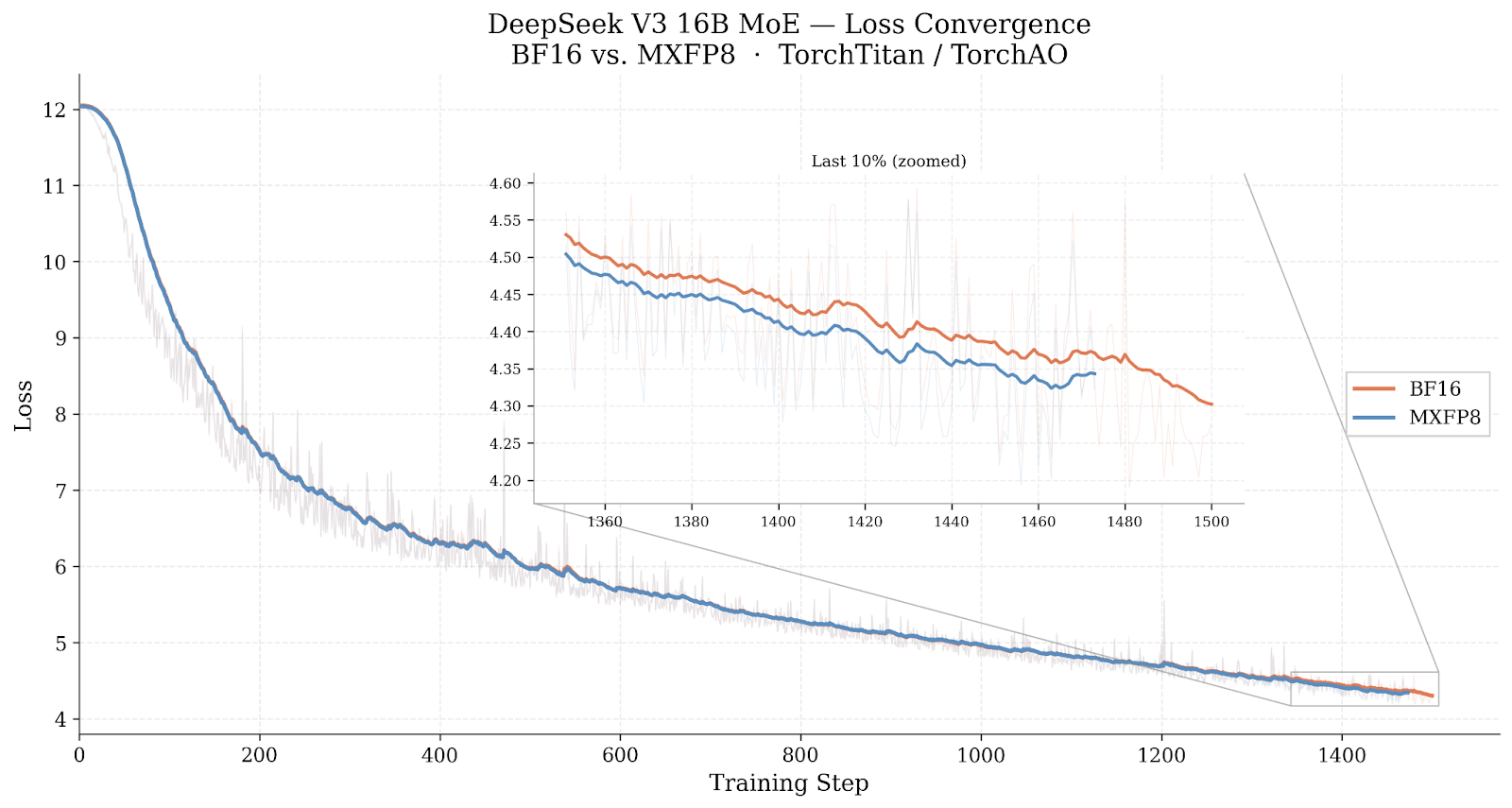
Figure 3: Training loss over 1,500 steps for BF16 and MXFP8. Both curves are virtually identical. Inset shows the last 10% of training zoomed in.
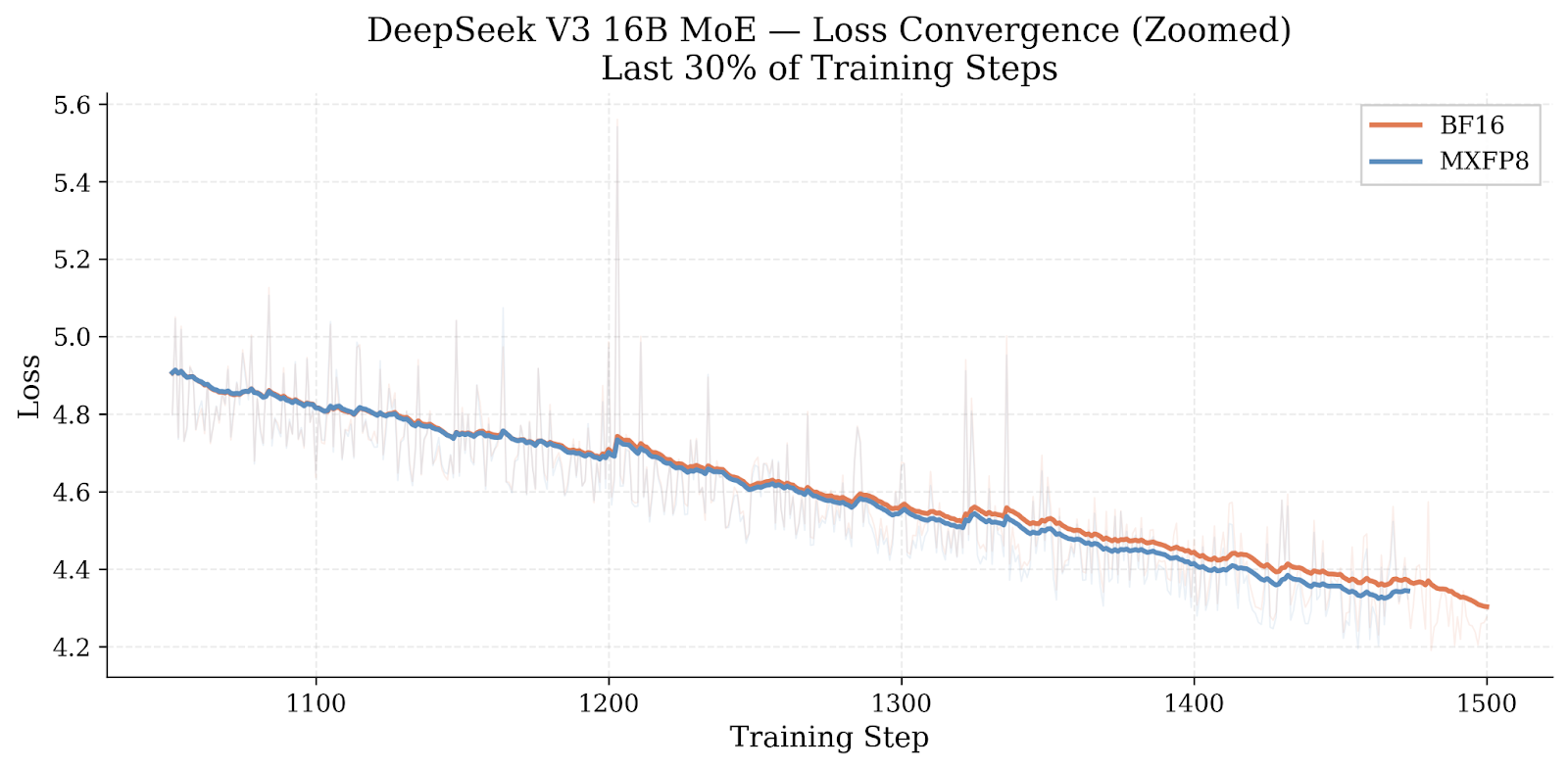
Figure 4: Zoomed view of the last 30% of training steps. The two configurations track each other closely, confirming equivalent convergence behavior.
The loss curves confirm that MXFP8 training converges equivalently to the BF16 baseline over this training window. The MXFP8 shows no meaningful divergence from BF16.
Summary of Results
| Model | Configuration | TPS | Speedup |
| 671B | BF16 + Standard EP | 651 | baseline |
| 671B | BF16 + DeepEP | 859 | +32.0% |
| 671B | MXFP8 GMM + DeepEP | 918 | +41.0% |
Lessons Learned
- DeepEP is the single largest lever for 671B. At EP=32 across 32 nodes, inter-node all-to-all communication dominates step time. DeepEP’s hierarchical NVLink+RDMA forwarding cuts this bottleneck substantially.
- The two optimizations are complementary. MXFP8 targets compute (GEMMs), DeepEP targets communication (all-to-all). Because they address independent bottlenecks, their gains stack. The combined +41% is close to the sum of individual improvements.
MXFP8 converges equivalently to BF16. Over 1,500 steps on the 16B model, loss curves for MXFP8 and BF16 are indistinguishable, consistent with findings from other MXFP8 training experiments on MoE architectures.
Future works
The results presented here do not yet represent the full potential of MXFP8 on the 671B model. Our current 671B experiments apply MXFP8 only on grouped GEMMs (routed experts), because torch.compile does not yet support MXFP8 linear layers when combined with tensor parallelism (TP). Since the 671B configuration requires TP=2, we could not enable MXFP8 on attention and shared-expert linear layers.
Once TP + torch.compile + MXFP8 linear layer support lands in TorchTitan, we expect the 671B throughput to improve further.
Reproducibility
All experiments use open-source tooling and can be reproduced on a Nebius Cloud B200 cluster. Please refer to the README file on Nebius repository for more information.
| Component | Reference |
| TorchTitan | https://github.com/pytorch/torchtitan |
| TorchAO | https://github.com/pytorch/ao |
| DeepEP | https://github.com/deepseek-ai/DeepEP |
| 671B training configs | train_671b.sh |
| 16B training configs | train_16b.sh |
| Environment setup | setup.sh, requirement.txt, README |