What is cluster launch control (CLC)?
Blackwell brings in cluster launch control (CLC) to enable dynamic scheduling. This capability allows the kernel to launch a grid with as many threadblocks as needed — mirroring the approach used in non-persistent kernels while keeping the benefits of both fewer thread block launches (provided by persistent kernels) and load balance (powered by hardware).
We start with a simple GEMM kernel with 32×32 output tiles and 144 SMs available.
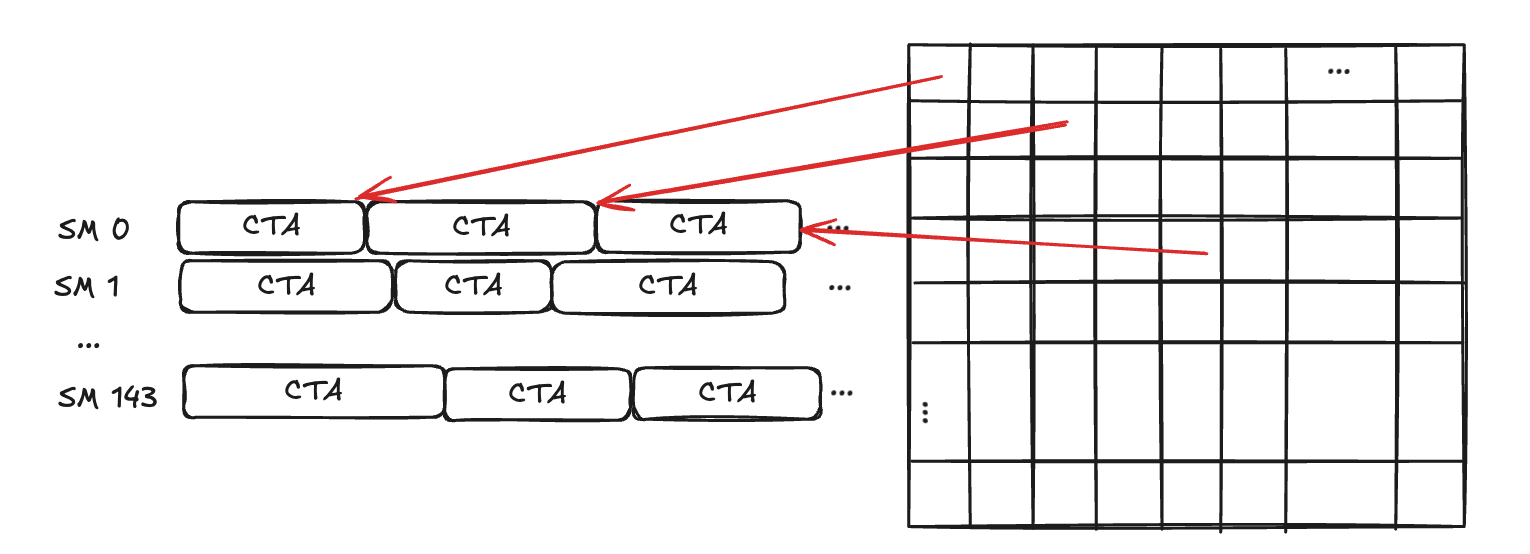
Fig-1. Non-persistent scheduling
With CLC enabled, launching a 32×32 grid from the host assigns CTAs 0–143 to SMs 0–143 initially.
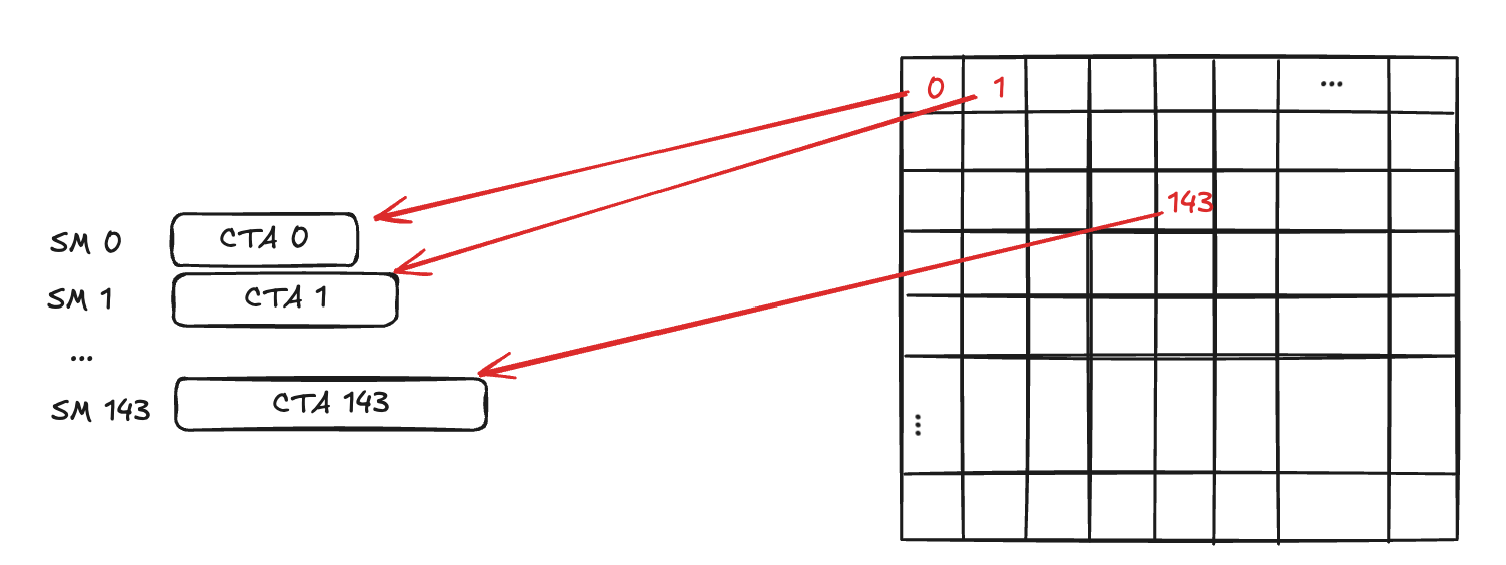
Fig-2. CLC assigns the initial CTAs to SMs
While, for example, CTA 0 is still running on SM 0, CLC allows SM 0 to asynchronously and atomically “steal” the next available work (such as CTA #200) such that SM-0 can immediately start processing block #200 without a new thread block launch.
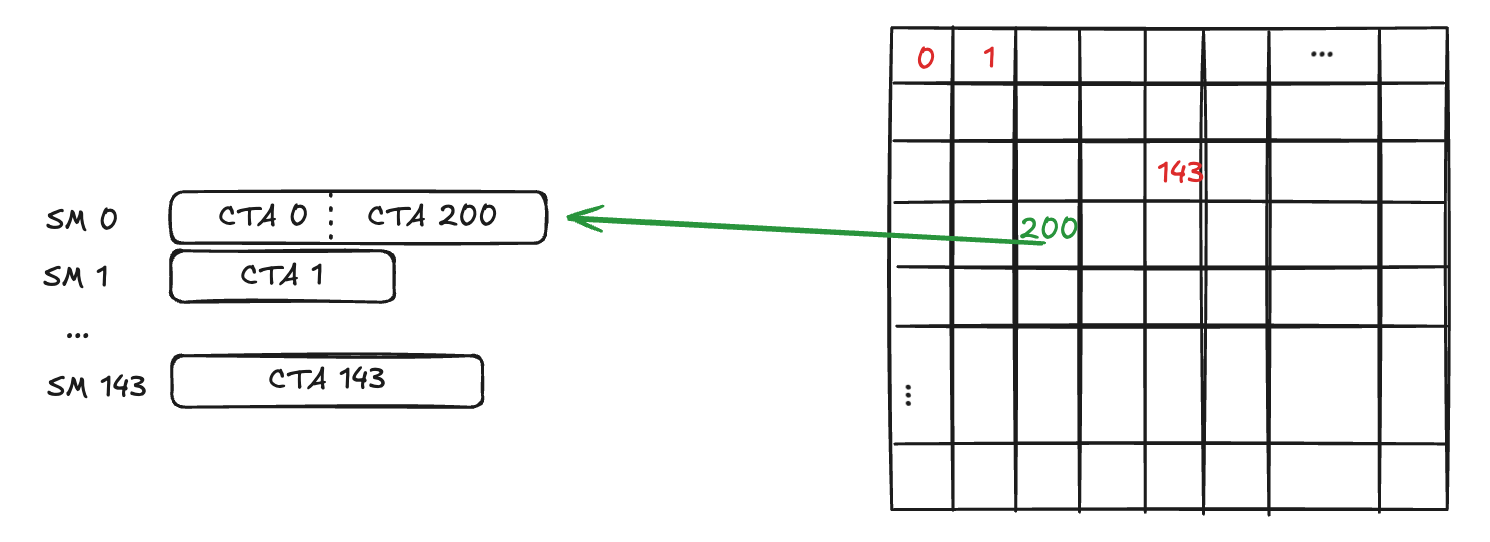
Fig-3. CLC steals work
Dynamic scheduling allows the system to adjust to changing workloads and resource availability during execution. For instance, if 5 additional SMs become available at runtime, they can also steal and process available work.
What is TLX?
TLX is a low-level extension of the Triton DSL, designed for expert users who need fine-grained control over GPU operations. TLX provides:
- Hardware-specific intrinsics (such as wgmma, async_copy, and barrier)
- Shared and local memory management
- Instruction-level scheduling and control
- Cross-warpgroup synchronization
These features enable advanced kernel development by exposing low-level GPU primitives and explicit constructs for memory, computation, and asynchronous control flow. While TLX currently focuses on NVIDIA GPUs, it allows users to implement architecture-specific optimizations, reducing reliance on compiler heuristics. This approach gives users more responsibility and flexibility, but may also lead to greater divergence between hardware platforms.
https://github.com/facebookexperimental/triton/tree/main
CLC in TLX
TLX provides three CLC APIs
- Initialization
tlx.clc_create_context(num_stages,num_consumersAllocates shared memory for the CLC.-
num_stagesenables pipelined workload stealing -
num_consumerssupports multi-consumers.
-
- Producer
tlx.clc_producer(context, k, p_producer)attempts to steal a workload stage-
contextis the handle returned by clc_create_context -
kis the stage index (0 to num_stages-1) -
p_produceris the mbarrier parity phase.
-
- Consumer
tlx.clc_consumer(context, k, p_consumer)for CTA ID decoding (if succeeded)kis again the stage indexp_consumeris the consumer’s mbarrier parity phase.
The initialization API tlx.clc_create_contextenables both multi-stage pipelining and multi-consumer workflows. A CLC producer–consumer setup requires, in shared memory, one pair of mbarriers (mbar_empty and mbar_full) per stage and a single CLC response object per stage.
Producer API will acquire by waiting formbar_empty and commit by try_cancel with mbar_full. Consumer API will wait on mbar_full, decode tile ID from CLC response and release mbar_empty.
# init clc_context = tlx.clc_create_context(NUM_CLC_STAGES, 1) # only 1 CLC consumer # init mbar parity phases clc_phase_producer = 1 clc_phase_consumer = 0 # cicular-buffer pipeline counter clc_buf = 0 tile_id = start_pid while tile_id != -1: clc_buf = clc_buf % NUM_CLC_STAGES # producer: steal workload tlx.clc_producer(clc_context, clc_buf, clc_phase_producer) clc_phase_producer = clc_phase_producer ^ (clc_buf == (NUM_CLC_STAGES - 1)) ... # main # consumer: decode CTA ID tile_id = tlx.clc_consumer(clc_context, clc_buf, clc_phase_consumer) clc_phase_consumer = clc_phase_consumer ^ (clc_buf == (NUM_CLC_STAGES - 1)) clc_buf += 1
Case study
Compare WS GEMM vs CLC+WS GEMM both with 3 WS regions (diffchecker)
- Default WG (epilogue consumer): invoke both
tlx.clc_producerandtlx.clc_consumer

Fig-4. Initialize context outside tlx.async_tasks and call producer API in ws-region
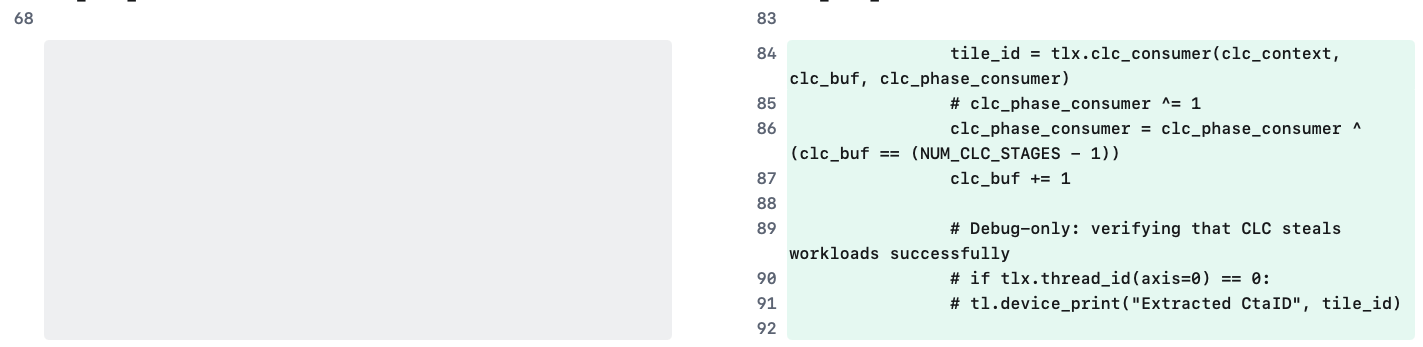
Fig-5. Call consumer API in the epilogue ws-region
- non-default WG (MMA consumer): invoke
tlx.clc_consumeronly


Fig-6. Call consumer API in the MMA ws-region
- non-default WG (producer, TMA load): invoke
tlx.clc_consumer only


Fig-7. Call consumer API in the TMA load ws-region

Fig-8. Mirror the grid size used in non-persistent kernels
Visualizing the differences between pipelined GEMM vs CLC GEMM:
- Y-axis: Represents the 144 SMs, each identified by its SM ID (from 0 to 143).
- X-axis: Represents time, measured in clock cycles, spanning the duration of the workload.
- Most of the heatmap is yellow, meaning that SMs are occupied by thread blocks for most clock cycles.
- CLC achieves better performance by eliminating the idleness gaps (purple) in pipelined GEMM.
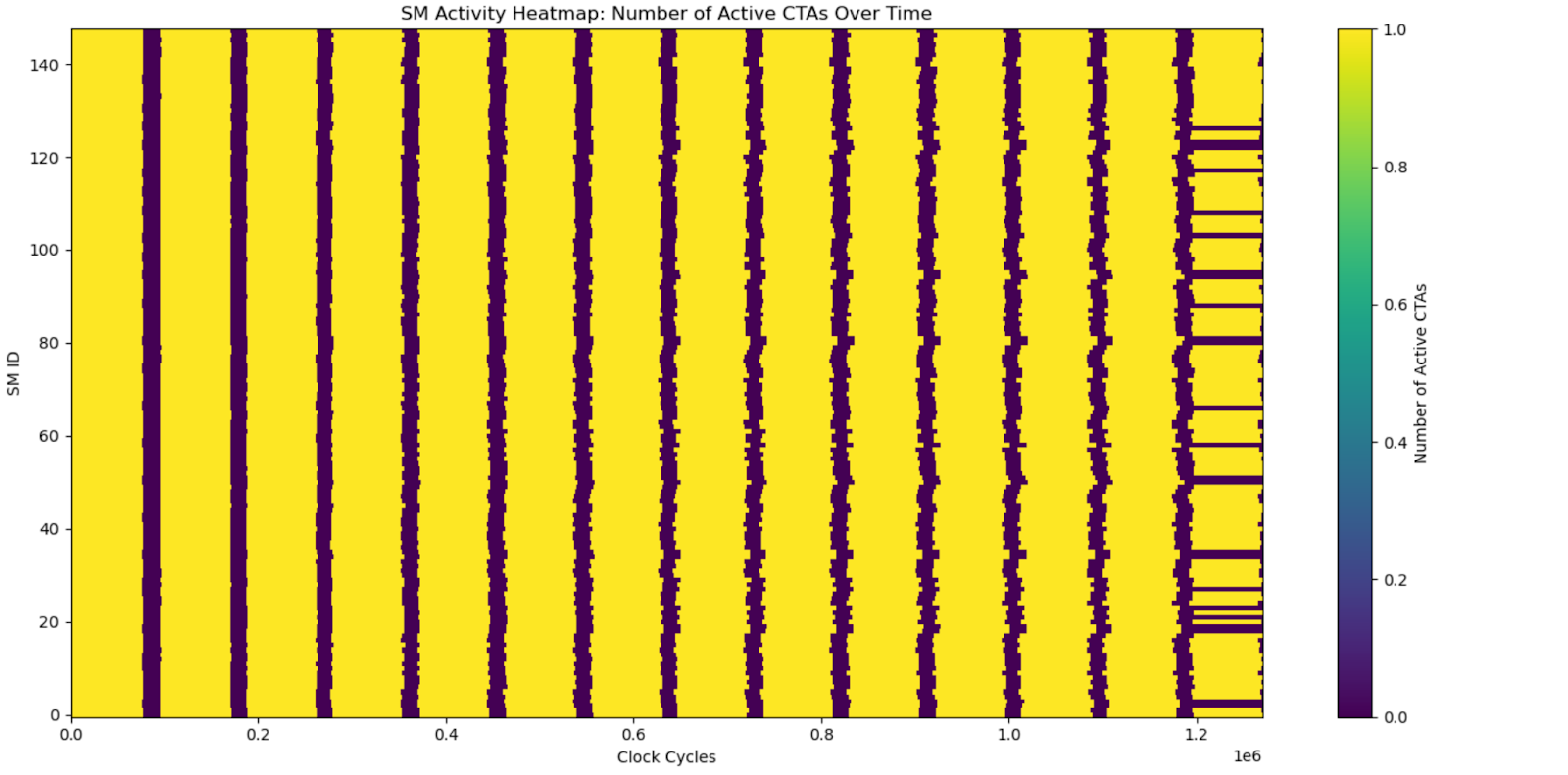
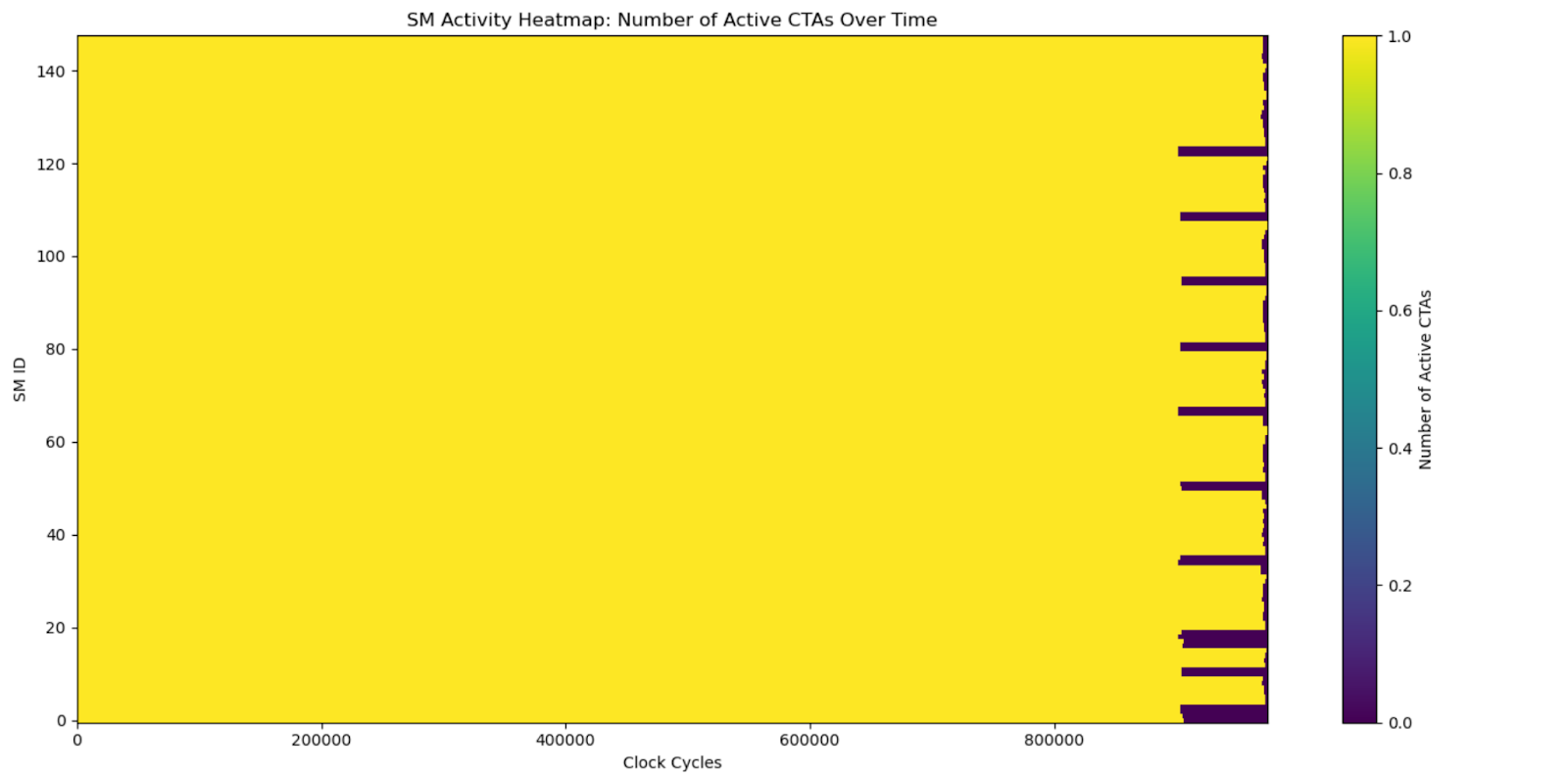
Fig-9. SM-occupancy heatmaps between pipelined GEMM and CLC GEMM
- Since all thread blocks are processing the same sized workloads in the above GEMM example, CLC doesn’t improve load balance. But for kernels with uneven workloads across thread blocks, CLC will greatly enhance load balancing like this.

Fig-10. SM-occupancy heatmap of an internal kernel with CLC enabled
Acknowledgements
Really appreciate the inspiring discussion with Bingyi Zhang (Nvidia) on CLC and tooling support from Srivatsan Ramesh (Meta) and Yuanwei (Kevin) Fang (Meta) on generating SM-occupancy heatmaps.