Training massive Mixture-of-Experts (MoE) models like DeepSeek-V3 and Llama 4-Scout efficiently is one of the challenges in modern AI. These models push GPUs, networks, and compilers to their limits. To tackle this, AMD and Meta’s PyTorch team joined forces to tune TorchTitan and Primus-Turbo, AMD’s open-source kernel library, for the new Instinct MI325X GPUs. Together, they reached near-ideal scaling across 1,024 GPUs, showing that efficiency and scale don’t have to be a trade-off.
At a Glance
By leveraging TorchTitan, Primus-Turbo kernels, and MI325X hardware capabilities, we achieved:
- 2.77× speed-up on DeepSeek-V3-671B through kernel-level optimization
- 96% scaling efficiency of DeepSeek-V3-671B from 128 → 1,024 GPUs
- Perfect linear scaling for Llama 4-Scout (32 → 512 GPUs)
- Fully open-source stack built on TorchTitan + Primus-Turbo
What is TorchTitan?
TorchTitan is Meta’s PyTorch-native blueprint for large-scale training across multi-GPU and multi-node clusters. It packages proven recipes for modern LLMs and MoE models into a single, configurable training stack, so you can reuse the same code path from early experiments to full-scale runs.
Config-first scaling
Set pipeline, tensor, data, or expert parallelism degrees in a single TOML file, and TorchTitan automatically builds the job, wires NCCL/RCCL groups, and runs the same script on one GPU or a thousand.
Broad architecture coverage
Train dense (Llama 3), hybrid (Qwen 3), and sparse MoE models (DeepSeek-V3, Llama 4) — all through a unified TorchTitan configuration.
Modular by design
Optimised kernels like AMD’s FP8 Primus-Turbo drop in without code changes, and the same hooks accept future post-training workflows.
In short, TorchTitan offers one unified, composable path for scaling any model—dense or sparse—from laptop prototype to cluster production.
Understanding Mixture-of-Experts Models
Mixture-of-Experts is a sparsely-activated alternative to dense Transformers. In a standard model every token flows through the same feed-forward block, so doubling parameters doubles the compute. An MoE layer replaces that single MLP with a pool of specialized experts. A learned router examines each token and sends it to just a few (e.g. k) of them.
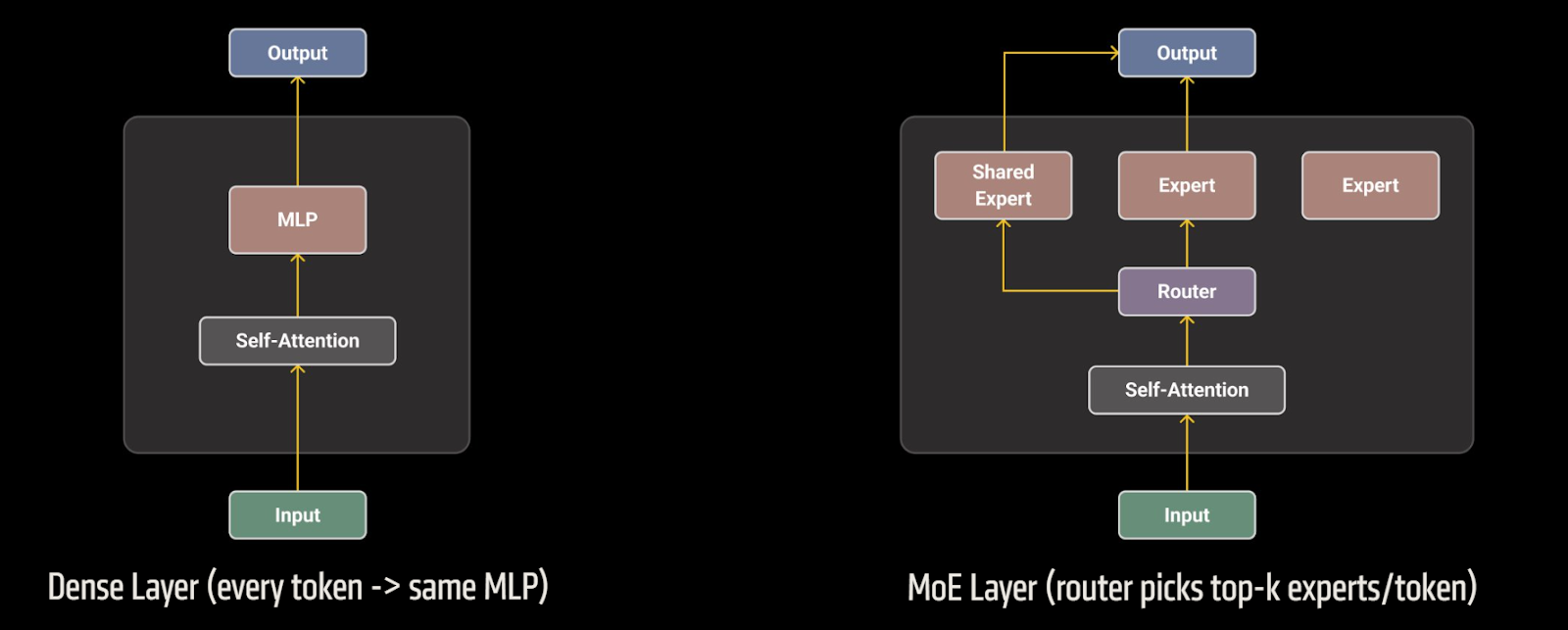
Figure 1: Dense Layer vs MoE Layer architecture
Because only a handful of experts run per token, the compute budget per token now scales with that small k instead of the total number of experts. Memory follows the same pattern: if expert parallelism is applied each GPU stores parameters only for the experts it owns, leaving room to push hidden dimensions, sequence length, or vocabulary size without overrunning device limits. The experts themselves are ordinary MLP blocks, so adding capacity is as simple as replicating more copies rather than widening every layer.
These economics let MoE models climb into the hundreds-of-billions-parameter range while training at dense-model speeds. DeepSeek-v3 and Llama 4 illustrate the payoff, blending MoE and dense layers to balance capacity, accuracy, and efficiency on today’s hardware.
Challenges of MoE Pre-Training
While MoE models offer compelling advantages, training them at scale introduces unique challenges that must be addressed for efficient distributed training.
Kernel Efficiency
Tiny matrix multiplications (GEMMs) → GPUs under-utilized: After routing, each expert processes only a handful of tokens, so the resulting matrix-multiplication (GEMM) operations become extremely small. These micro-GEMMs fail to keep the GPU’s compute units fully occupied and introduce significant launch and data-movement overhead.
Communication
Heavy All-to-All communication → networking bottlenecks: Expert Parallelism scatters token embeddings to the GPUs that own the selected experts. Every forward pass therefore triggers heavy All-to-All collectives, and as the cluster grows, communication time can overtake computation, becoming the primary bottleneck.
Parallelism
Complex parallelism → idle bubbles from out-of-sync pipelines: Modern training often stacks Fully-Sharded Data Parallelism for memory savings, Pipeline Parallelism for depth, and Expert Parallelism for width. If their micro-batches or schedules drift out of sync, “bubbles” appear—periods when some GPUs sit idle while others work—leading to poor utilization.
Routing and Stability
Unstable routing → uneven expert loads: The learned router must distribute tokens evenly across experts while respecting capacity limits. Skewed token counts, overloaded experts, or dropped tokens can slow convergence or degrade final model quality.
We address these pre-training hurdles on three fronts: AMD Instinct MI325X GPUs provide 256GB of HBM3E and >6TB/s of bandwidth plus FP8 tensor cores for keeping MoE experts local and compute-bound; a TorchTitan parallel strategy (FSDP + PP/VPP + EP) balances compute and communication; and Primus-Turbo’s FP8 attention and grouped-GEMM kernels turn MoE’s tiny GEMMs into high-occupancy, high-throughput operations.
AMD Instinct™ MI325X: Hardware and Software Stacks

Figure 2: AMD Instinct MI325X specifications
The Instinct MI325X couples 256 GB of HBM3E with more than 6 TB/s of on-package bandwidth and petaflop-class FP8/BF16 matrix cores. That much fast memory lets a MoE run most of its experts on the local device instead of scattering them across the cluster, which brings three payoffs at once:
- More experts per GPU — capacity grows without fragmenting the model into ever-smaller shards.
- Higher capacity factors, fewer token drops — the router can assign extra tokens to busy experts without running out of memory, stabilizing training.
- Less All-to-All traffic — smaller Expert-Parallel degrees shrink the collective footprint, so communication no longer dominates wall-time.
In practice, the MI325X’s memory headroom and bandwidth turn what is usually a networking bottleneck into an in-socket workload, keeping MoE training compute-bound even at large scale.
Parallel strategy design
We support multi-dimensional parallel strategy on AMD GPUs
- Expert Parallelism (EP) partitions the expert pool across GPUs within a node and—when the model no longer fits on a single node—across nodes. This lets us grow the number of experts while keeping per-GPU expert state bounded and avoiding excessively small expert shards.
- Fully-Sharded Data Parallelism (FSDP) slices parameters, gradients, and optimizer states across the data-parallel group, reducing the per-GPU model footprint by roughly the data-parallel degree so large checkpoints fit comfortably within the MI325X’s 256 GB of HBM.
- Pipeline + Virtual Pipeline Parallelism (PP + VPP) splits layers into stages and interleaves forward and backward steps; VPP further subdivides each stage into virtual chunks so micro-batches are staggered and pipeline idle time is reduced.
With EP absorbing width, FSDP handling memory, and PP + VPP overlapping forward and backward passes to reduce pipeline bubbles, the stack aligns GPU arithmetic, HBM bandwidth, and 400 Gb RoCE traffic—so no single dimension becomes a bottleneck.
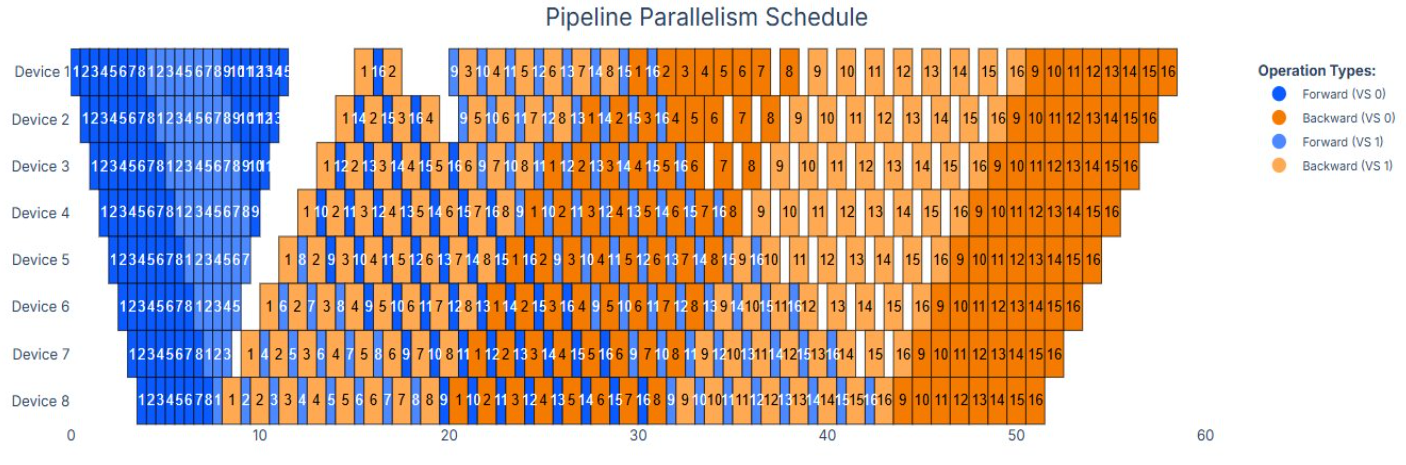
Figure 3: PP Schedule—the blue/orange heat-map showing how VPP overlaps forward/backward passes
Primus-Turbo: AMD’s Acceleration Library
Primus-Turbo is a high-performance acceleration library dedicated to large-scale model training on AMD GPUs. Within this stack, Primus-Turbo is the ROCm-optimized kernel library used in this work. It provides high-performance operators (GEMM, attention, grouped GEMM), communication primitives (including All-to-All/DeepEP), optimizer utilities, and low-precision kernels such as FP8 for efficient training on AMD Instinct™ GPUs.
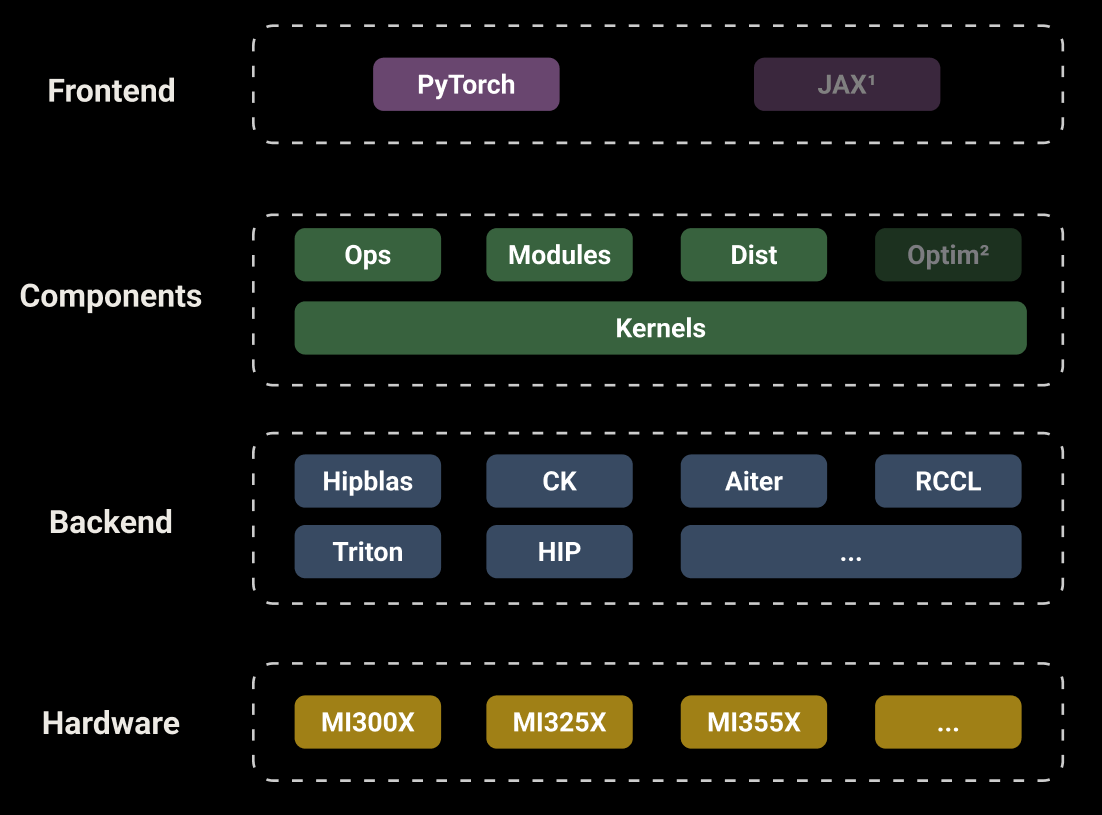
Figure 4: Primus-Turbo architecture
Key Components
| Components | Features |
| GEMM | – Support BF16/FP16
– Support for FP8 (E4M3/E5M2) with tensor-wise, row-wise, and block-wise quantization |
| Grouped GEMM | – Support BF16/FP16
– Support low precision like FP8 (E4M3/E5M2) with tensor-wise, row-wise, and block-wise quantization |
| Attention | – Support BF16/FP16
– Support low precision like FP8 (E4M3/E5M2) with block-wise quantization |
| DeepEP | – Intra-node and Inter-node support
– Support Mellanox; Broadcom NIC and AMD AINIC (both under development) |
| All2All | – Support low precision like FP8 (E4M3/E5M2) with tensor-wise, and row-wise quantization |
| Elementwise Ops | – Support for normalization, activation functions, RoPE, and more |
Integration example:
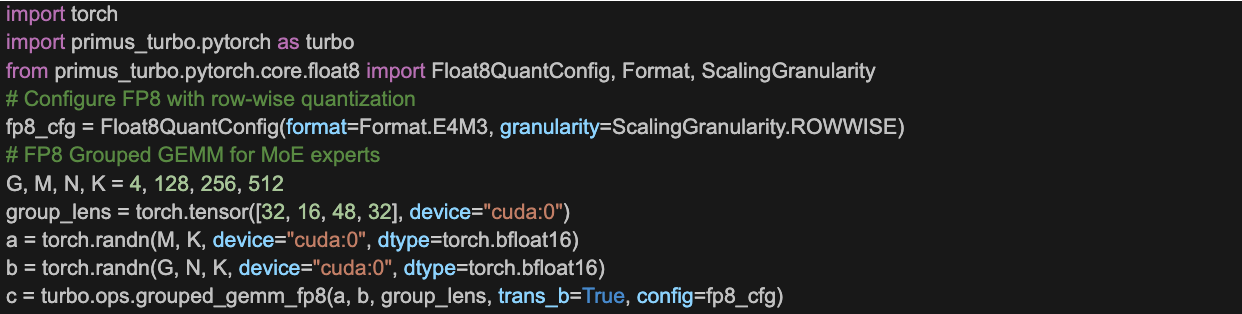
Large-scale pre-training on MI325X cluster
All experiments ran on a TensorWave cluster equipped with 1024 AMD Instinct MI325X GPUs. Each GPU is attached to a 400Gb RoCE v2 Broadcom Thor 2 NIC, and the nodes are wired in a three-tier fat-tree topology. This design provides full-bisection bandwidth, so Expert-Parallel All-to-All traffic never hits a network bottleneck. TorchTitan and Primus-Turbo supplied the software stack.
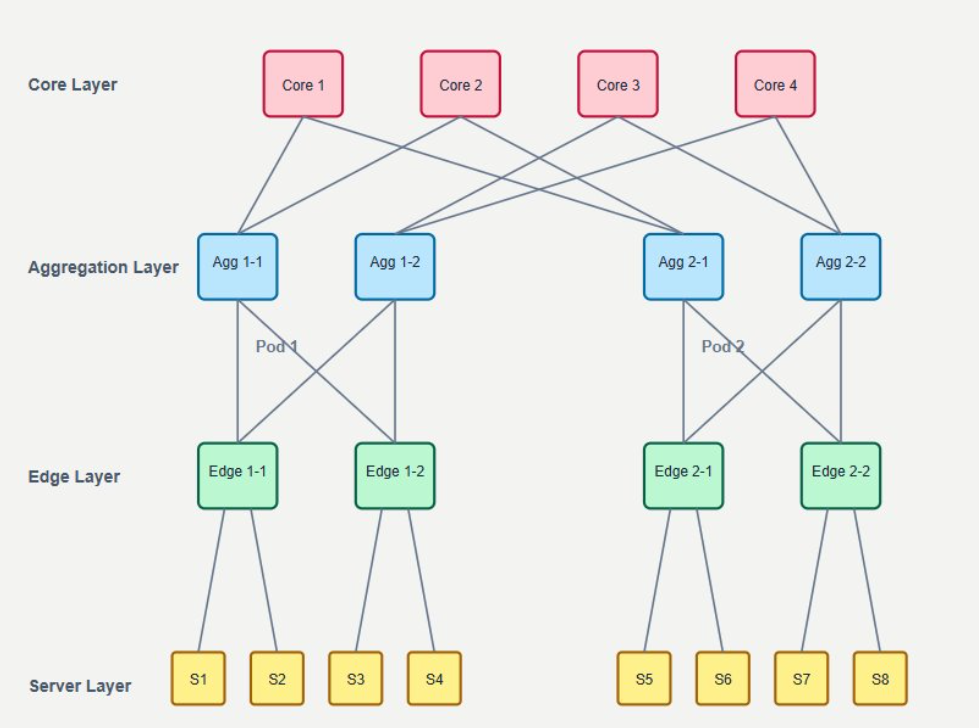
Figure 5: MI325X cluster with 3-layer Fat-Tree network topology
DeepSeekV3-671B Performance Optimization through Primus-Turbo
Firstly, we profile a full-run of DeepSeek-V3-671B on 64 MI325X nodes to identify kernel hotspots, like attention kernel and the grouped GEMMs in Fig.6.
Experiment configurations:
| # layers | Seq len | EP | PP | VPP | Batch size |
|---|---|---|---|---|---|
| 64 | 4096 | 8 | 8 | 4 | 16 |

Figure 6: Kernel profiling showing attention kernel and FP8 grouped GEMM kernel optimization targets
Using Primus-Turbo we tackled them and measured throughput after each step as shown in the bar chart in Fig.7.
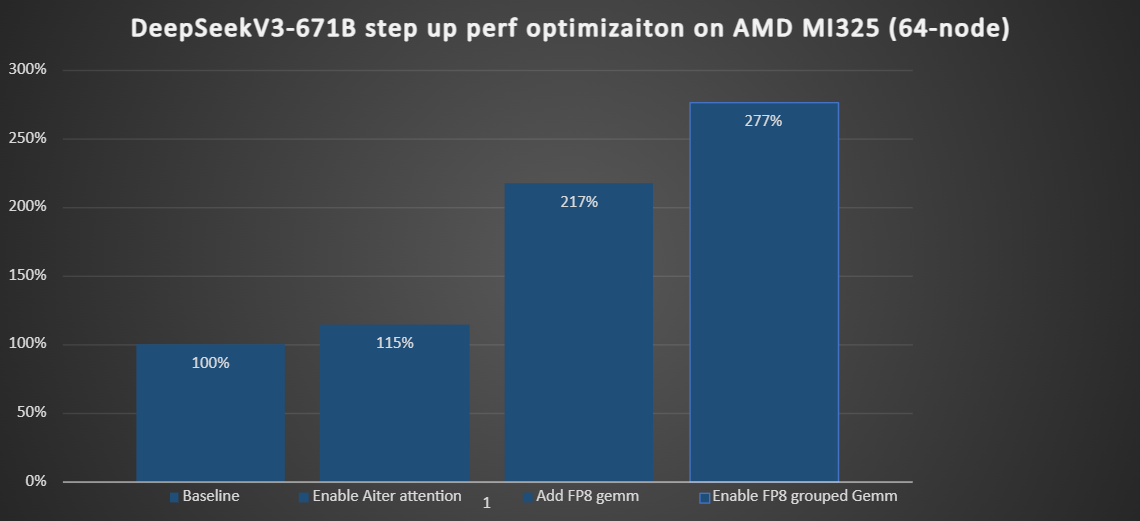
Figure 7: Step-by-step performance optimization on 64 nodes (512 GPUs)
- Enable AITER attention. lifted throughput by ≈15%. (To learn more about AITER: AITER blog)
- FP8 GEMM for dense layers. Switching the linear layers to tensorwise FP8 cut memory traffic and doubled effective flops, adding another ≈102% over the previous run.
- FP8 grouped GEMM for experts. Finally, a fused kernel that combines permutation and compute removed the micro-GEMM bottleneck and delivered a further ≈60% gain.
Stacked together, these optimizations raised end-to-end training speed by 2.77× compared with the baseline, turning the MI325X cluster into a compute-bound, rather than bandwidth-bound, MoE training machine.
DeepSeekV3-671B Pre-training Scaling
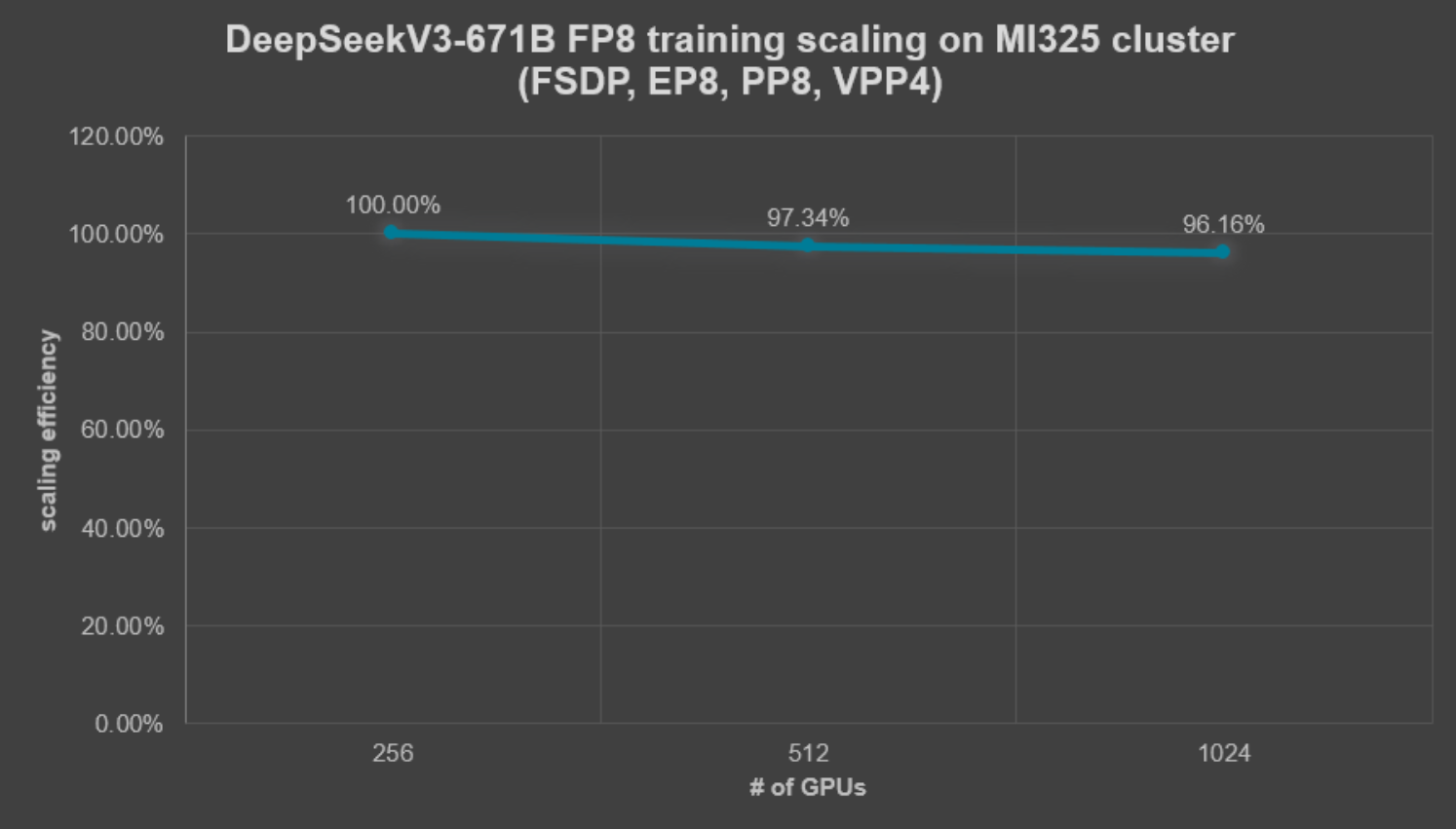
Figure 8: DeepSeekV3-671B scaling efficiency on MI325 cluster
Starting at 256 GPUs, throughput stayed within striking distance of ideal: 97% at 512 GPUs and 96% at the full 1024-GPU scale, proving that the combined hardware–software stack can coordinate eight-way pipeline stages, expert routing, and FP8 kernels without wasting cycles.
DeepSeekV3 Pre-Training Convergence
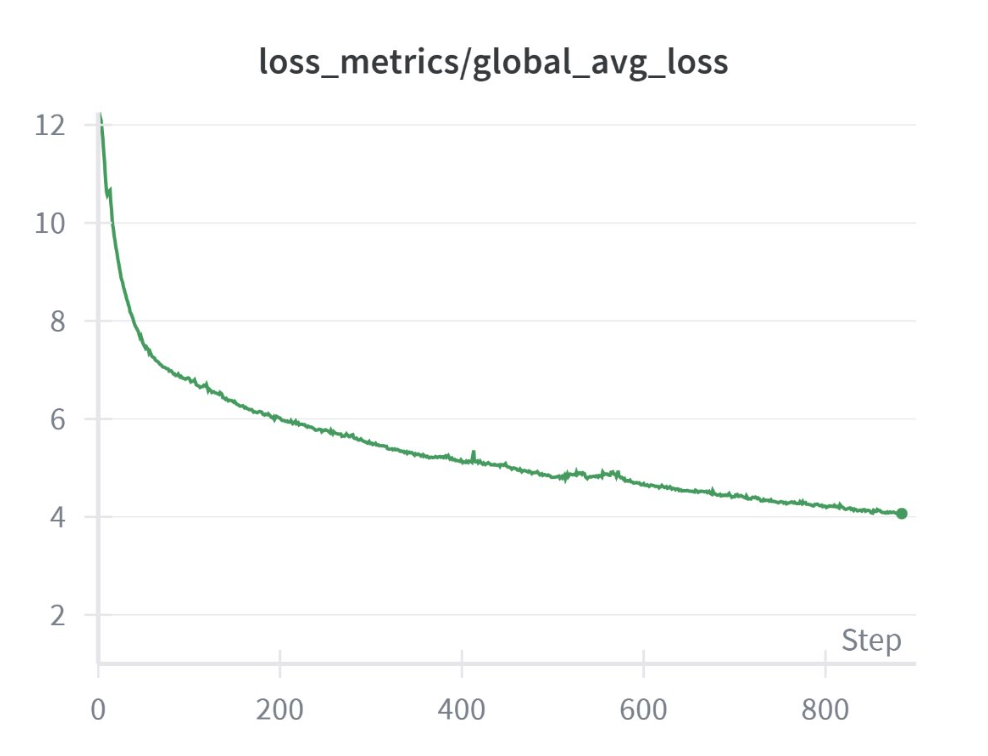
Figure 9: DeepSeek-V3 loss on MI325X cluster
To verify that speed does not compromise quality, we tracked the training loss of DeepSeek-V3 FP8 on 32 MI325X nodes (256 GPUs) using the allenai/c4 dataset. The curve shows smooth, monotonic descent over 900 iterations, matching reference behavior on other platforms and confirming that FP8 kernels, expert routing, and parallel schedules converge as expected.
Llama4-Scout Pre-training Scaling
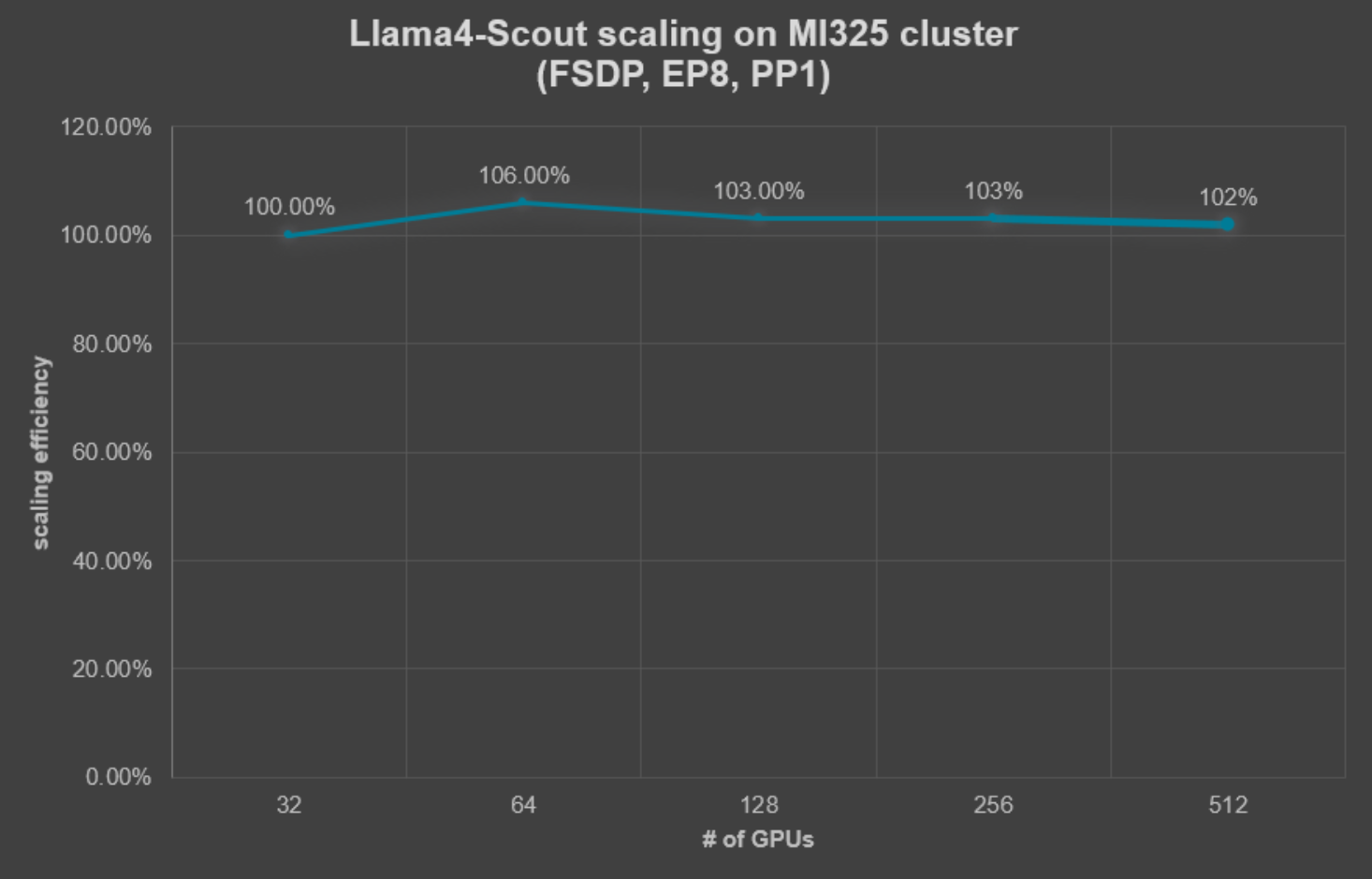
Figure 10: Llama4-Scout scaling efficiency on MI325X cluster
With FSDP combined with EP = 8, Llama-4 Scout sustained 100–102% scaling efficiency as we increased the cluster size from 32 to 512 GPUs, demonstrating that the same optimizations transfer cleanly to other MoE architectures.
DeepEP — keeping expert traffic under control
In the above experiments, we applied EP=8 because increasing the degree of expert parallelism make the All-to-All communication step prohibitively expensive. To mitigate this effect when scaling up the EP degree, Primus-Turbo also provides DeepEP to accelerate All-to-All performance. The charts below compare a standard All-to-All implementation (red) with DeepEP (blue) on a 16-node MI325X cluster training DeepSeek-V3 671B (24 layers, PP 4 + VPP 3, local batch 16). As the expert-parallel degree (EP) rises from 8 to 32, plain All-to-All throughput sinks from roughly 2000 TPS to about 750 TPS and its share of total runtime balloons from 10% to nearly 50%. DeepEP holds throughput steady around 2000–2100 TPS and total runtime for communication caps at ~18% even at EP 32, turning the scalability curve flat.
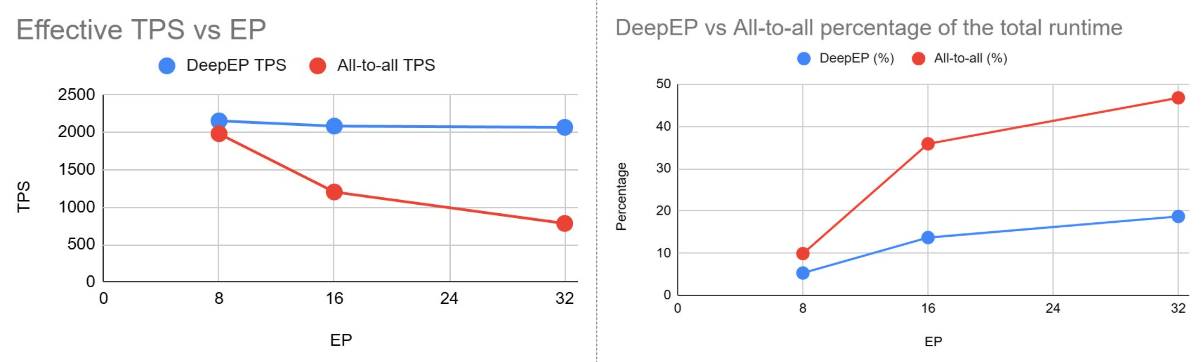
Figure 11: DeepEP performance analysis across different EP degrees (DeepSeek-V3 671B, EP=8/16/32, LBS=16, PP=4, VPP=3, 24 layers, 16 nodes)
Prims-turbo is built on top of ROCm DeepEP (https://github.com/ROCm/DeepEP) with additional performance improvement like no cpu/gpu sync on training workloads (available at https://github.com/AMD-AGI/Primus-Turbo).
Conclusion and Next Steps
Our joint work with Meta shows that AMD Instinct MI325X hardware, combined with TorchTitan and the open-source Primus-Turbo library, delivers production-ready throughput for modern pre-training MoE models. DeepSeek-V3 reached more than 96 percent scaling efficiency up to 1024 GPUs; Llama-4 Scout displayed even higher linear scaling efficiency. Kernel-level tuning—FP8 GEMM, grouped GEMM, and Aiter attention—raised end-to-end performance by 2.77×, and all our implementation is open-sourced.
What comes next
- Pipeline evolution. DualPIPE and other advanced schedules will further shrink idle bubbles in deep pipelines.
- Broader kernel coverage. Ongoing FP6/FP4 support and new ops target the next wave of MoE and sparse-tensor architecture.
- Next-generation hardware. Preparations are under way for MI450 GPUs and the Helios AI rack to extend today’s results to even larger clusters.
- Open-source expansion. Continuous support for TorchTitan and contributions to Monarch, TorchForge, etc.
Together, these efforts aim to keep AMD platforms at the forefront of large-scale, cost-efficient MoE training.
Learn More
Open-Source Repositories
- Primus-Turbo: https://github.com/AMD-AGI/Primus
- TorchTitan: https://github.com/pytorch/torchtitan
- AMD-optimized torchtitan fork: github.com/AMD-AGI/torchtitan-amd
Documentation
- An Introduction to Primus-Turbo: https://rocm.blogs.amd.com/software-tools-optimization/primus-large-models/README.html
- Pipeline Parallelism Visualization: https://github.com/AMD-AGI/Primus/tree/main/tools/visualization/pp_vis
- ROCm Documentation: https://rocm.docs.amd.com/en/latest/ https://rocm.docs.amd.com/
- AMD Instinct MI325X: https://www.amd.com/en/products/accelerators/instinct/mi300/mi325x.html
Disclaimers
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.