If you want powerful on-device AI that doesn’t blow your memory budget or turn your phone into a hand-warmer, you need tools more refined than post-training quantization, where the model cannot recover any consequent reduction in accuracy.
We have produced a collection of practical Jupyter notebook tutorials to introduce developers and ML researchers to a variety of advanced hardware-software co-design topics. We show how mixed-precision quantization, quantization-aware techniques, and a mixture of expert models can produce models that are both small and capable, and ready to run efficiently on Arm-based devices with edge inference runtimes like ExecuTorch.
Quantization and Hardware-Software Co-Design
The goal is to tune precision to minimize accuracy loss while maximizing model compression. Traditional quantization (FP32 to INT8) is a powerful but blunt instrument, as not all layers in a neural network are equally sensitive to precision loss.
The level of precision needed depends on data’s distribution. The figure below shows how, at 4-bit quantization, different feedforward and attention components within a transformer incur very different levels of quantization error. This illustrates how minimizing accuracy loss requires allocating bits adaptively so each section is represented with the appropriate precision. We show how mixed levels of precision can be achieved simply in PyTorch through the QConfig API.
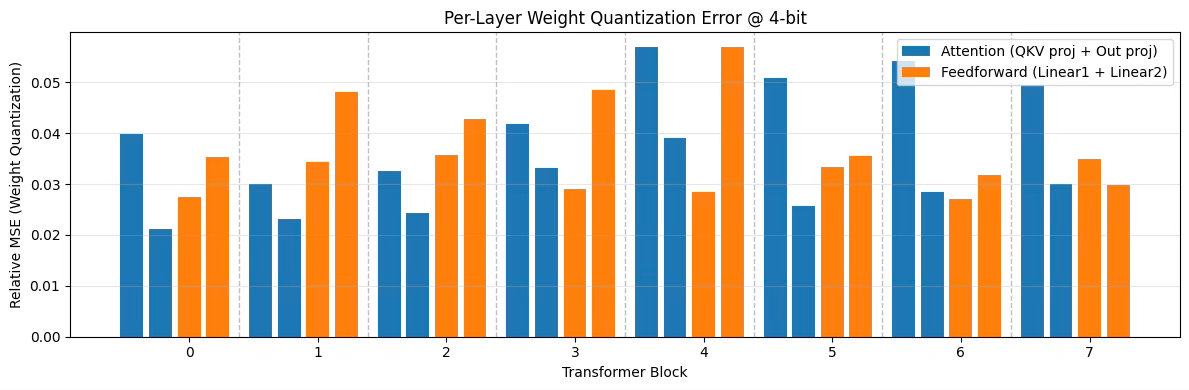
Further, to maintain strong performance in mixed precision models, Arm’s KleidiAI delivers highly optimised compute kernels currently down to 4-bit, ensuring that low-bit tensor types are efficiently mapped to Arm hardware instructions. For developers looking to deploy to Arm-based devices such as smartphones and laptops, all this happens transparently when using PyTorch and the Edge inference runtime, ExecuTorch, through the KleidiAI and Arm VGF backends.
In our notebooks, we also explore hardware-software co-design, going beyond training a model not only to minimize loss but also to minimize model size by letting the model learn how to quantize each layer. This teaches developers to balance accuracy against model compactness and train models that reliably fit within specified memory footprints.
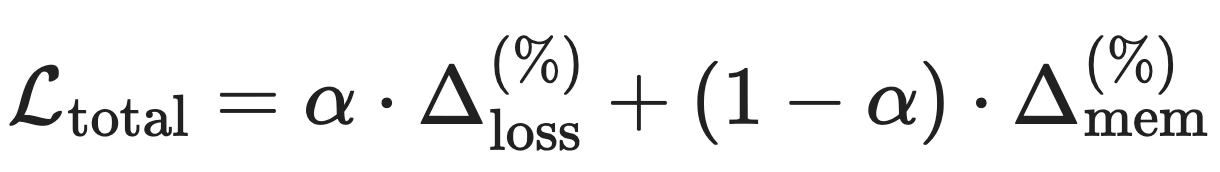
The formula above suggests how we can form a loss function that includes terms for software cost in model accuracy, and hardware cost through static model size. We implement this example loss function directly in PyTorch and explore it in much more detail in our Hardware–Software Co-Design tutorials, where we use it to train a transformer-based network on the Tiny Shakespeare dataset.
Extreme Quantization
Building on this co-design view, our tutorials then explore training algorithms that make aggressive low-bit deployment practical. Quantization-aware training (QAT) exposes the model to simulated low-precision arithmetic during training, so it can adapt its weights and activations to be robust to rounding noise.
Rather than treating quantization as a final deployment step, QAT lets the optimiser “see” the quantizer throughout training, which is especially valuable when pushing below 8 bits or targeting tight memory budgets. Extreme quantization pushes this even further, asking how close we can get to binary-like representations while still retaining useful accuracy. Recent work on ultra-low-bit large language models, such as The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (Ma et al., 2024), suggests just how far careful algorithm–hardware co-design can compress modern architectures while keeping them functional at scale.
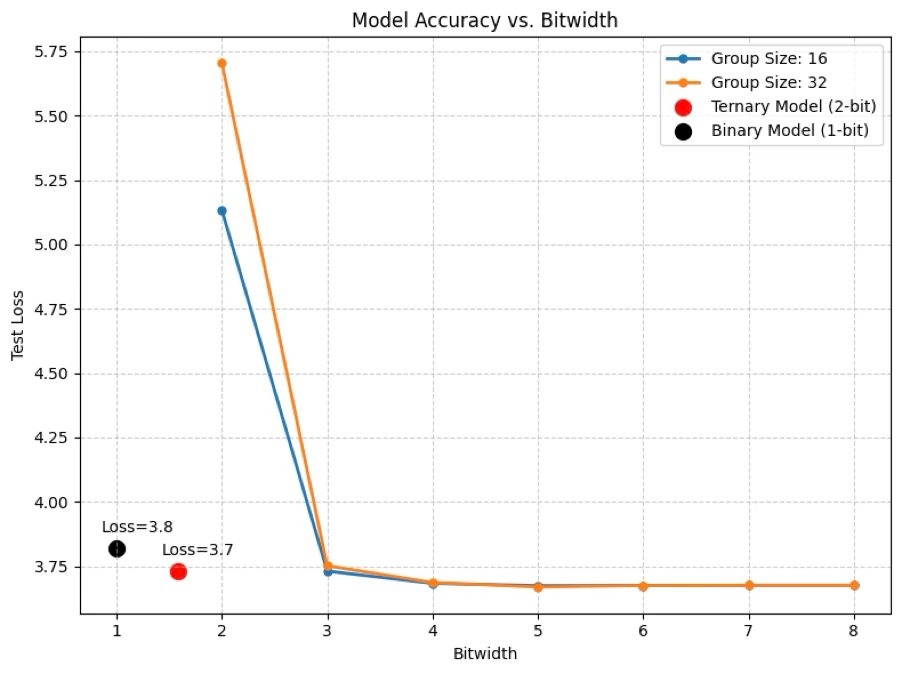
In our PyTorch notebooks, you can experiment with these ideas end to end: start from a baseline model, enable QAT, explore more aggressive quantization schedules, and observe how accuracy, model size, and performance trade off in practice. The graph below, discussed in detail in our tutorials, shows that with QAT, 1–2-bit binary/ternary models nearly match the 8-bit baseline while dramatically outperforming naive low-bit post-training quantization.
Efficient Model Inference Using Mixture of Experts Architectures
Beyond quantization, our curriculum also covers introductory content on implementing Mixture of Experts (MoE) models. Unlike dense models, where every parameter is used for every input, MoE architectures activate only a specific section of the network, known as ‘experts’, for any given token.
To get familiar with these topics, we have released a comprehensive collection of Jupyter Notebook series that serves as a practical step-by-step guide. With around 10 hours of practical content, our labs are designed so you can run and modify the code on your own hardware, making the theory immediately actionable. Take a look here.
This collection has been produced through a collaborative effort between Kieran Hejmadi at Arm and leading academics, including Oliver Grainge, AI Researcher at the University of Southampton, and Professor Constantine Caramanis, IEEE Fellow and Professor at the Department of Electrical and Computer Engineering at the University of Texas at Austin.
Additional thanks go to the academic reviewers at IIT Delhi and IIT Hyderabad, who ensured the material is both cutting-edge and rigorously validated.
If you’re looking for more introductory content, try our course on Optimizing GenAI on Arm Processors, from Edge to Cloud.
References
Ma, S., et al. (2024). The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits. arXiv