Last year, Meta announced that PyTorch joined the Linux Foundation as a neutral home for growing the machine learning project and community with AMD representation as a part of the founding membership and governing board.
PyTorch Foundation’s mission is to drive AI adoption by democratizing its software ecosystem through open source principles aligning with the AMD core principle of an Open software ecosystem. AMD strives to foster innovation through the support for latest generations of hardware, tools, libraries, and other components to simplify and accelerate adoption of AI across a broad range of scientific discoveries.
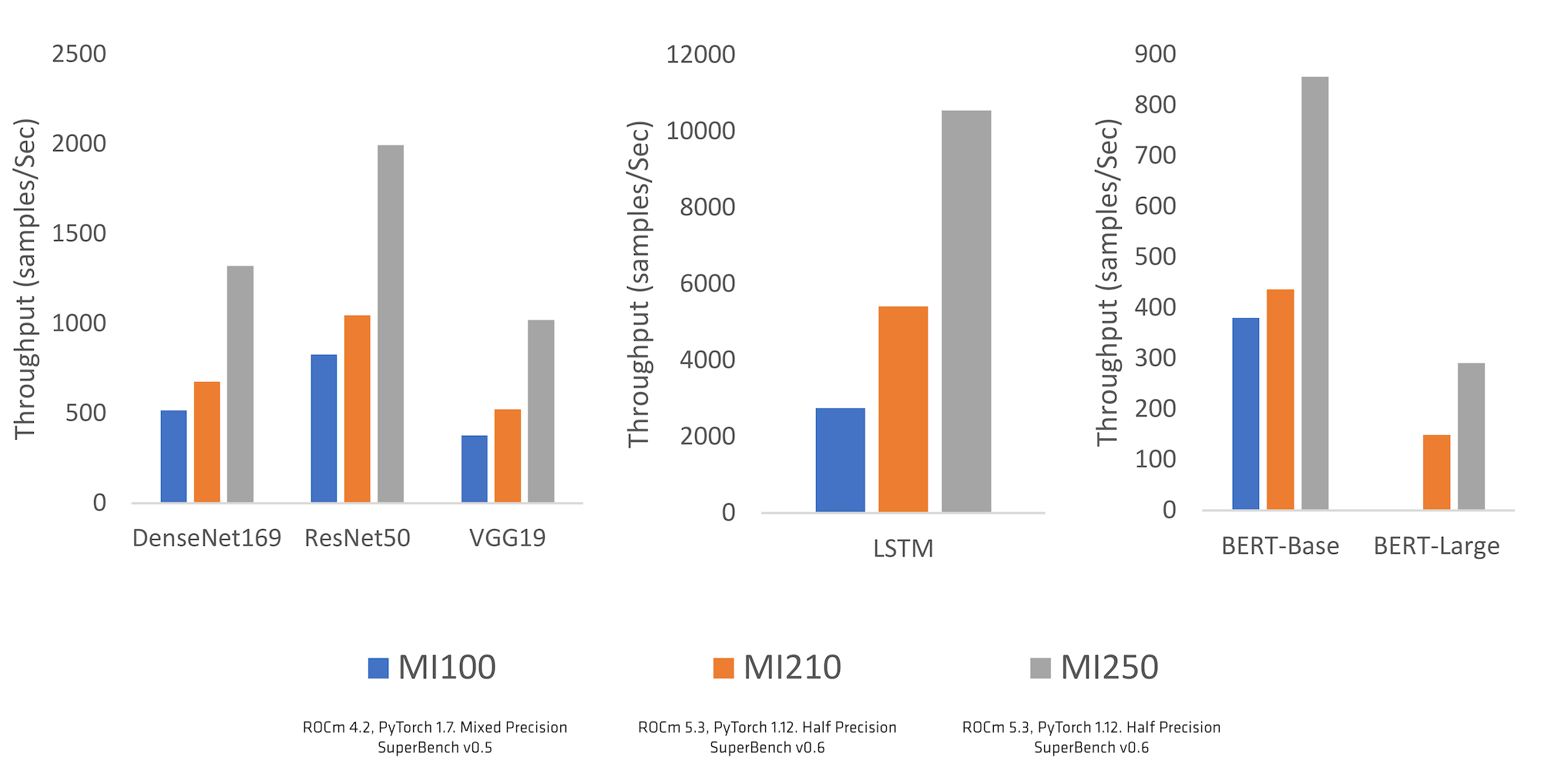
AMD, along with key PyTorch codebase developers (including those at Meta AI), delivered a set of updates to the ROCm™ open software ecosystem that brings stable support for AMD Instinct™ accelerators as well as many Radeon™ GPUs. This now gives PyTorch developers the ability to build their next great AI solutions leveraging AMD GPU accelerators & ROCm. The support from PyTorch community in identifying gaps, prioritizing key updates, providing feedback for performance optimizing and supporting our journey from “Beta” to “Stable” was immensely helpful and we deeply appreciate the strong collaboration between the two teams at AMD and PyTorch. The move for ROCm support from “Beta” to “Stable” came in the PyTorch 1.12 release (June 2022) brings the added support to easily run PyTorch on native environment without having to configure custom dockers. This is a sign of confidence about the quality of support and performance of PyTorch using AMD Instinct and ROCm. The results of these collaborative efforts are evident in the performance measured on key industry benchmarks like Microsoft’s SuperBench shown below in Graph 1.
“We are excited to see the significant impact of developers at AMD to contribute to and extend features within PyTorch to make AI models run in a more performant, efficient, and scalable way. A great example of this is the thought-leadership around unified memory approaches between the framework and future hardware systems, and we look forward to seeing that feature progress.”
– Soumith Chintala, PyTorch lead-maintainer and Director of Engineering, Meta AI