TL;DR
- Open source voice models are proliferating, but there’s no unified native inference platform for voice agent workloads (transcription, real-time streaming, diarization, voice activity detection, live translation) across devices and hardware.
- ExecuTorch fills this gap. As a general-purpose PyTorch-native inference platform, it enables developers to export voice models directly from PyTorch and run them across CPU, GPU, and NPU on Linux, macOS, Windows, Android, and iOS.
- We provide reference implementations for five voice models spanning four distinct tasks, with working C++ application layers and mobile apps ready to build on. LM Studio is already shipping voice transcriptions powered by ExecuTorch in production.
Voice on the Edge Today
AI agents are increasingly expected to hear and speak. Whether it’s a personal assistant on smart glasses, a real-time translator on a phone, or a voice-driven coding companion on a laptop, voice is becoming a key modality for how agents interact with users. A voice-capable agent needs more than just offline transcription: it needs streaming speech recognition, speaker diarization, voice activity detection, noise suppression, speech-to-text, live translation, and full-duplex support, all running locally with low latency.
This demand is fueling a wave of open source voice models. In just the past few months we’ve seen Qwen3-ASR, Parakeet ASR, Voxtral Realtime, Kyutai Hibiki-Zero, Kokoro TTS, SAM-3-Audio, Liquid LFM2.5-Audio, Sortformer Diarization, and many more. What’s missing is a uniform way to deploy them natively on edge devices, as compiled C/C++ libraries that run directly on device hardware without a Python runtime or cloud dependency.
Most of these models can run in Python, but production level edge deployments require native C++ libraries. Existing native solutions tend to be either model-specific C++ rewrites that need to be rebuilt for each new architecture, or platform-specific frameworks tied to a single hardware ecosystem. As voice models diversify in architecture and complexity, neither approach scales.
We built ExecuTorch as a general-purpose native inference platform that works across models, backends, and devices. Last year we reached general availability with production-ready support including LLMs, vision, and multimodal models. Now we’re extending the same platform to voice. We see voice as a key frontier for on-device AI, and we wanted to prove that ExecuTorch’s architecture could handle the diversity of voice workloads across diverse hardwares. In this post, we provide reference implementations for five voice models spanning four distinct tasks, along with sample applications and mobile apps ready to build on. LM Studio is already shipping voice transcription powered by ExecuTorch in their desktop application.
Design Principles
Three principles underpin this approach:
Minimal model changes, not full rewrites. The model author’s PyTorch code is the starting point. Instead of rewriting models in other languages or converting them to other formats, we use torch.export() directly on the original PyTorch model’s core components (audio encoder, text decoder, token embedding, mel spectrogram) with minimal edits. For example, when Mistral released Voxtral Realtime and NVIDIA published Parakeet TDT and Sortformer, we exported their PyTorch source directly with targeted edits to satisfy torch.export() constraints. No format conversion, no reimplementation in C++.
Export the model, orchestrate in C++. The model and the application logic live in different layers. Model components are exported into a compiled artifact. A thin C++ application layer ties everything together, handling the complex orchestration: streaming-window bookkeeping, audio overlap handling, spectrogram alignment, stateful decoding loops. ExecuTorch handles the hard part: efficient inference across hardware backends.
Write once, run on any backend. One export serves every target platform. The same exported model runs on XNNPACK (CPU), Metal Performance Shaders (Apple GPU), CUDA (NVIDIA GPU), or Qualcomm (NPU) with minimal backend-specific logic in the model or export script. Quantization (int4, int8) is applied in PyTorch before export, shrinking models significantly without manual kernel work.
Voice Models in Practice
We’ve validated this approach across five voice models with very different architectures:
Voxtral Realtime (streaming transcription, ~4B params). Mistral’s streaming transcription model delivers real-time transcription with offline-level accuracy, and is a good example of the “export the model, orchestrate in C++” approach. The C++ application layer handles audio signal processing: overlapping audio windows with past context and lookahead, spectrogram frame alignment, and encoder position tracking. The exported model handles the heavy compute: transformers with ring-buffer KV caches that enable unlimited-duration streaming within fixed memory. All streaming constants are derived at export time and baked into the exported model as self-describing metadata. Int4 quantization shrinks the model from 20GB to 5–6GB.
Parakeet TDT (offline transcription, 0.6B params). NVIDIA’s high-accuracy speech recognition model uses a Token-and-Duration Transducer architecture, where the model predicts both what token to emit and how far to advance in the audio at each step. This non-standard decoding loop is a good example of ExecuTorch’s multi-method export: the encoder, decoder, and joint network are exported as three separate methods in a single artifact, while the C++ application layer implements the TDT-specific greedy decode with LSTM state management. The application layer also includes timestamp extraction in C++ (word boundaries, sentence segmentation), making this a fully standalone on-device transcription pipeline.
Sortformer (speaker diarization, 117M params). NVIDIA’s diarization model answers “who spoke when” for up to four speakers in an audio stream. The model itself is stateless: it takes audio embeddings in and outputs per-frame speaker probabilities. All streaming complexity lives in the C++ application layer: a speaker cache that retains the most discriminative frames, a sliding FIFO window for short-term context, and cache compression that drops the least informative frames when memory fills up. This is one of the clearest demonstrations of ExecuTorch’s separation between model and orchestration.
Whisper (offline transcription, 39M–1.5B params). OpenAI’s widely adopted speech recognition model, with the widest backend coverage in ExecuTorch (CPU, Apple GPU, NVIDIA GPU, and Qualcomm NPU).
Silero VAD (voice activity detection, 2MB). A lightweight model that detects whether someone is speaking. A building block for any voice agent, and a good starting point for contributors.
| Model | Task | Backends | Platforms |
| Parakeet TDT | Transcription | XNNPACK, CUDA, Metal Performance Shaders, Vulkan | Linux, macOS, Windows, Android |
| Voxtral Realtime | Streaming Transcription | XNNPACK, Metal Performance Shaders, CUDA | Linux, macOS, Windows |
| Whisper | Transcription | XNNPACK, Metal Performance Shaders, CUDA, Qualcomm | Linux, macOS, Windows, Android |
| Sortformer | Speaker Diarization | XNNPACK, CUDA | Linux, macOS, Windows |
| Silero VAD | Voice Activity Detection | XNNPACK | Linux, macOS |
Sample Applications
Beyond model enablement, we’ve built a few end-to-end applications to demonstrate what’s possible. These are starting points, and we encourage application developers to build on them for their own use cases:
Real-time transcription on desktop. The demo reads live audio from the microphone and outputs transcribed text as you speak, running entirely on-device. This is the foundation for voice input in any desktop application: coding assistants, note-taking tools, accessibility features. Download the dmg file and try the app today:
Standalone realtime voice transcription macOS application powered by ExecuTorch and Voxtral Realtime. Video
Speech recognition on Android. The Parakeet and Whisper Android apps let users record audio and transcribe it on-device. These are fully functional apps with model download, microphone recording, and transcription, available in the executorch-examples repository.
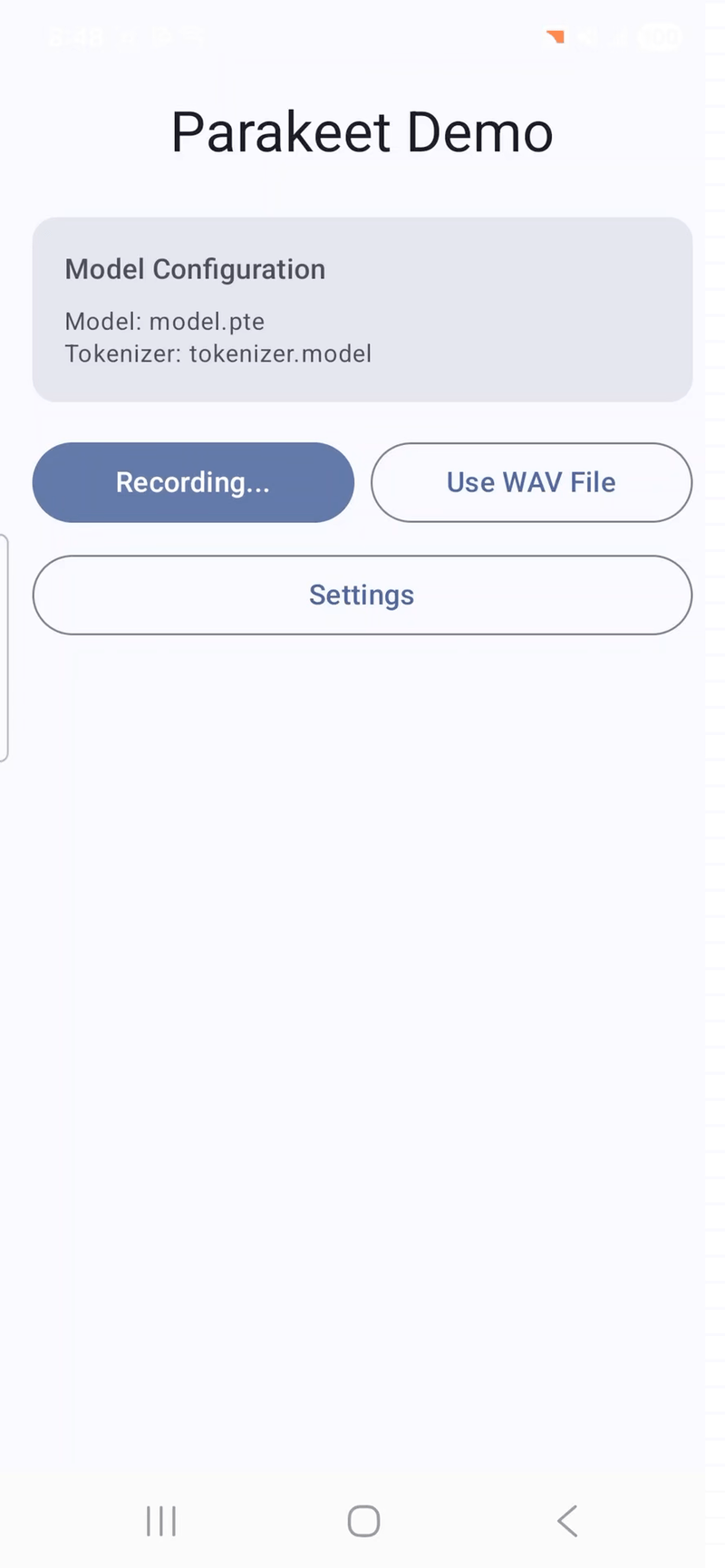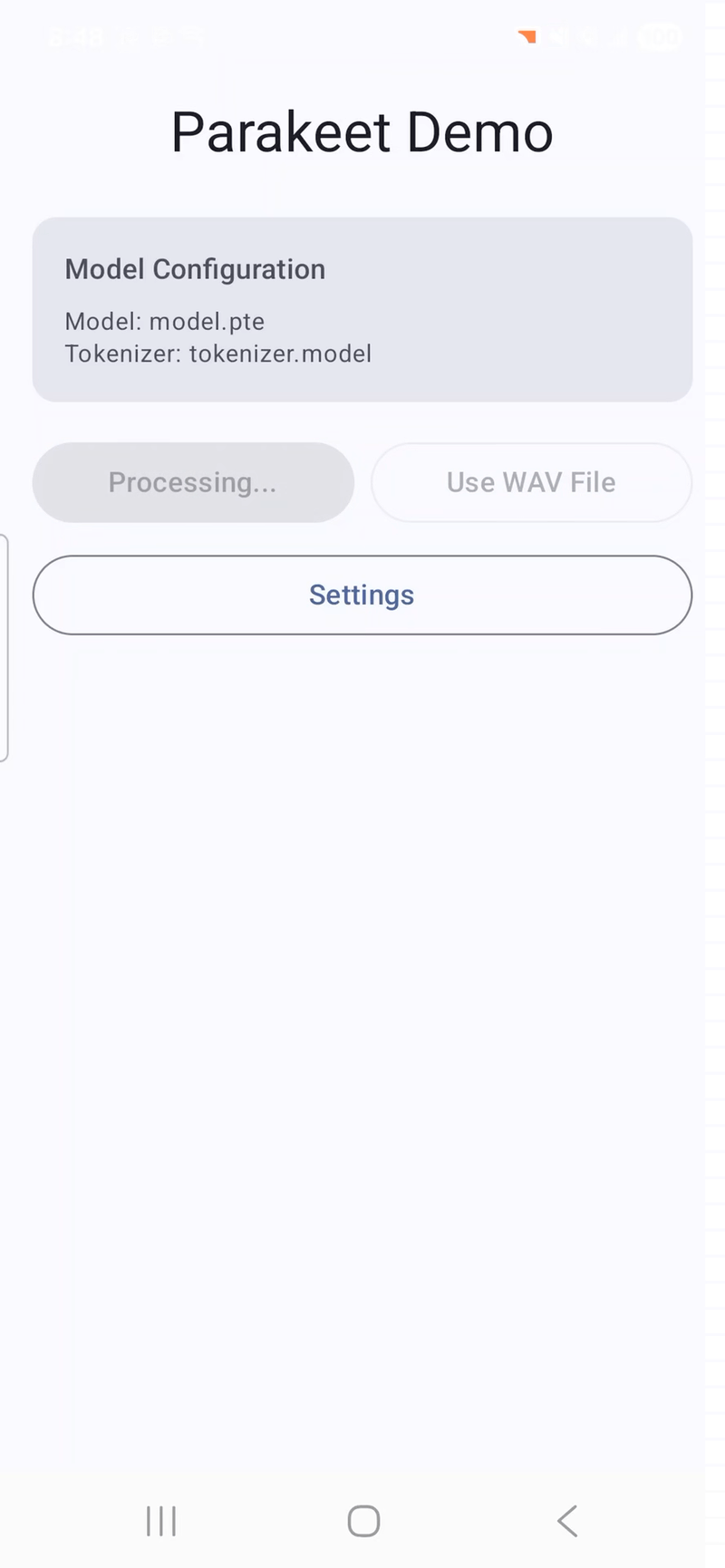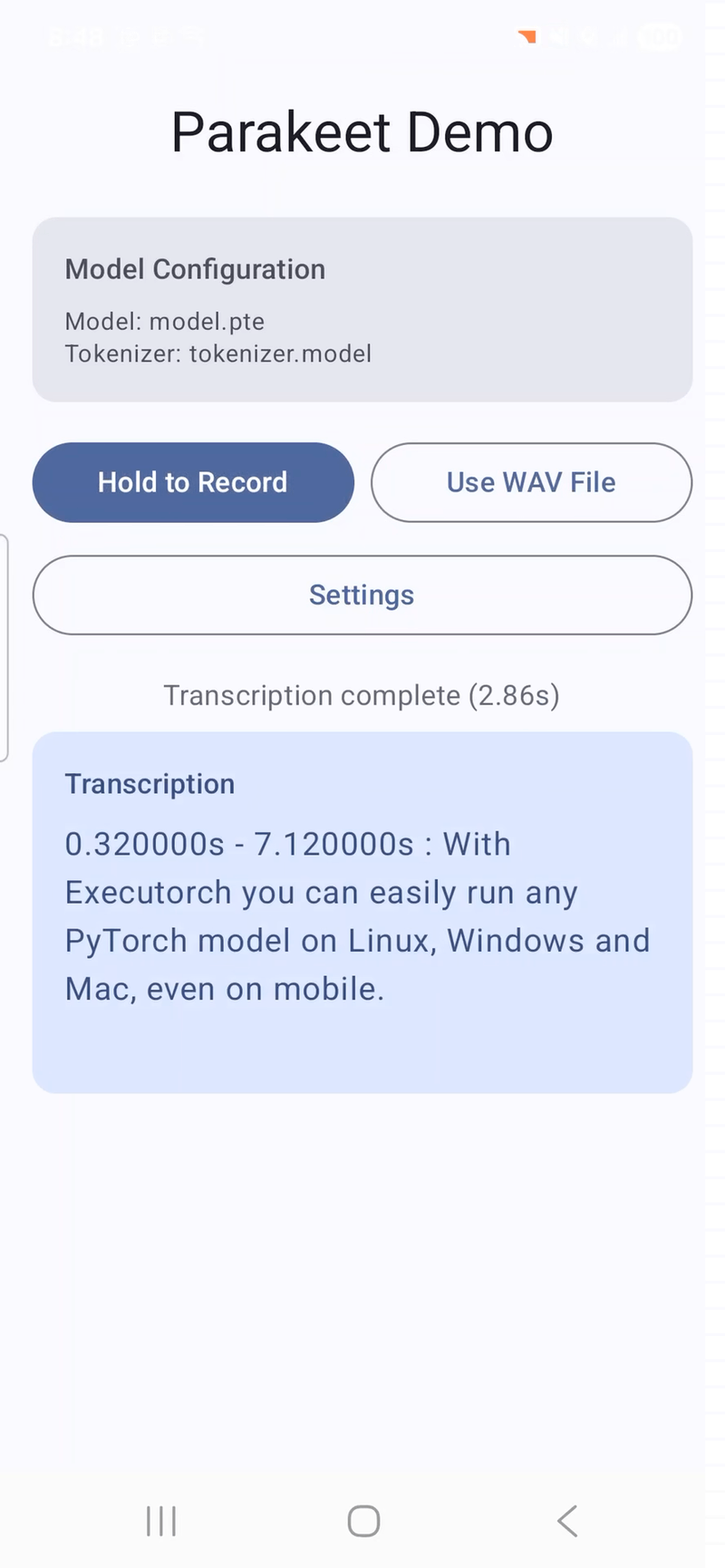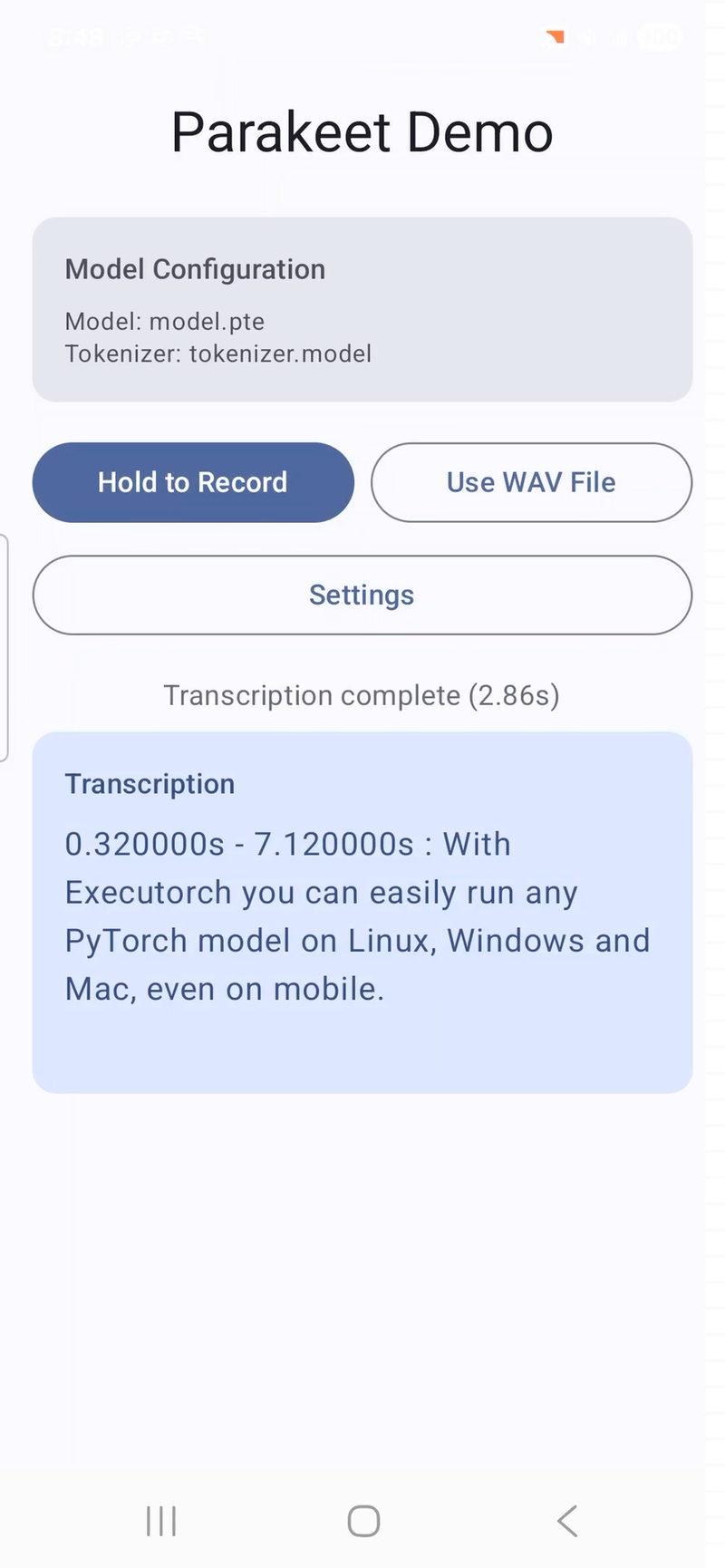
Voice transcription with timestamp on Android (Samsung Galaxy S24) powered by ExecuTorch and Parakeet. Video
Adoption Case Study in production: LM Studio
LM Studio is a popular desktop application for running LLMs locally. They recently added voice transcription to their product, powered by ExecuTorch running the Parakeet TDT model. LM Studio exposes transcription in the app UI, with an API endpoint coming soon. With this, LM Studio will be enabling developers to integrate local speech recognition into their workflows. They chose ExecuTorch for its cross-platform support and competitive performance, shipping on macOS (Metal Performance Shaders) and Windows (CUDA) from the same model and application layer.

LM Studio adopts ExecuTorch for cross-platform, on-device transcription
Get Involved
These reference implementations are starting points, and the landscape of voice models we want to support is much larger. Models like Qwen3-ASR, Kyutai Hibiki-Zero, Kokoro TTS, SAM-3-Audio, and Liquid LFM2.5-Audio are all PyTorch-native and natural candidates for ExecuTorch enablement. We want the community’s help to get there:
- Adopt ExecuTorch for voice inference in your frameworks and applications.
- Contribute new models — pick a voice model, export it, write an application layer, and open a PR. Live translation, speech enhancement, wake word detection, noise reduction, text-to-speech. The architecture is ready for all of them.
- Contribute backends and platforms — help us close the remaining gaps and improve performance across hardware.
ExecuTorch isn’t just for voice. It’s the same platform powering on-device LLMs, vision models, and multimodal AI.
Start building: ExecuTorch Documentation | ExecuTorch repo | ExecuTorch Examples | ExecuTorch Discord
Acknowledgement
This work wouldn’t have been possible without support and core contributions from PyTorch team members, including Bilgin Cagatay, Tanvir Islam, Hamid Shojanazeri, Siddartha Pothapragada, Jack Khuu, Kaiming Cheng, Nikita Shulga, Angela Yi, Bin Bao, Shangdi Yu, Sherlock Huang, Yanan Cao, Digant Desai, Anthony Shoumikhin, Mark Saroufim, Chris Gottbrath, Joe Spisak, Jerry Zhang, Supriya Rao
Thank you to Patrick von Platen from Mistral AI for building the Voxtral Realtime model, open sourcing it, and reviewing and testing our integration code.