As developers, we all know the story: Large Language Models (LLMs) are revolutionary, but their cost is staggering. Running frontier models requires specialized GPU farms with massive energy consumption. For years, our community has relied on low-precision quantization with bespoke mixed precision kernels to make these models practical. But for those of us focused on edge computing and on-device inference, even this isn’t enough. We need the next frontier of optimization. That frontier is sparsity. We believe the path forward is a unified framework for sparse inference, and we’re building it in PyTorch.
Unlocking Sparsity in LLMs
Early models like Meta’s OPT, which used ReLU activations, were a goldmine. Research showed that for an average input, over 95% to 99% of the weights in its MLP blocks weren’t even activated
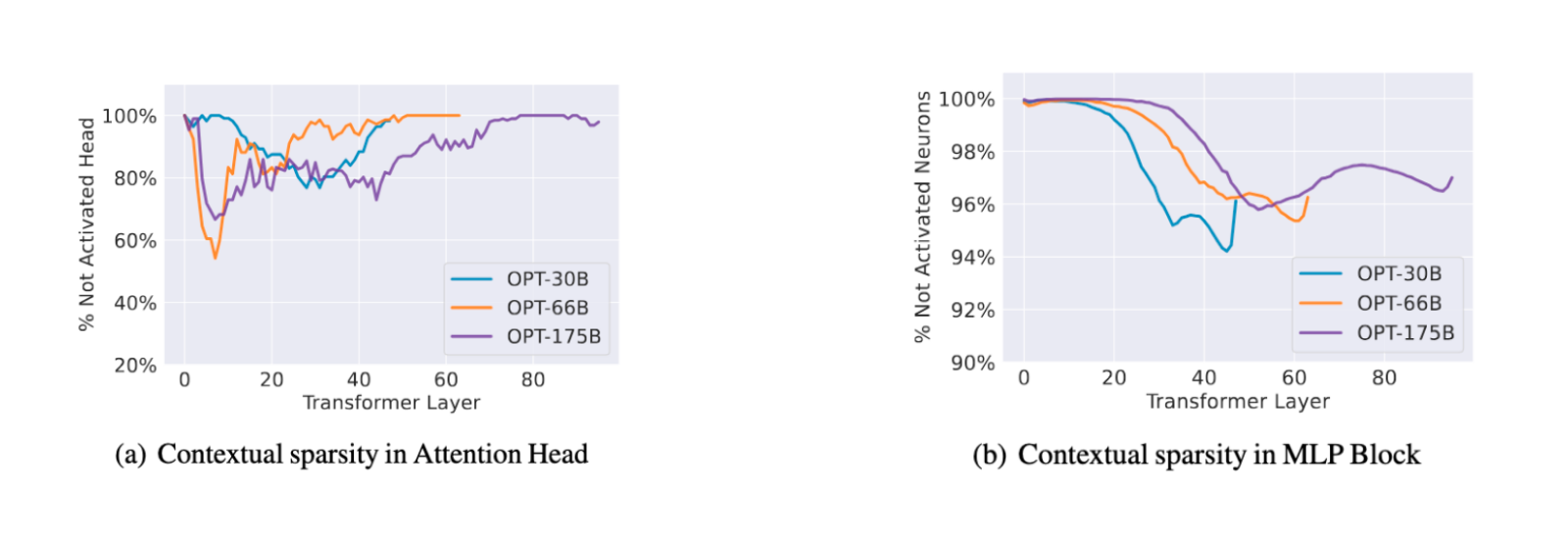
Figure 1: Observed sparsity in attention and MLP blocks of OPT models
(figure taken from Liu et al. [2023])
So we could just update the FFN calculation in the MLP blocks, avoiding these unactivated neurons, saving both memory and compute.
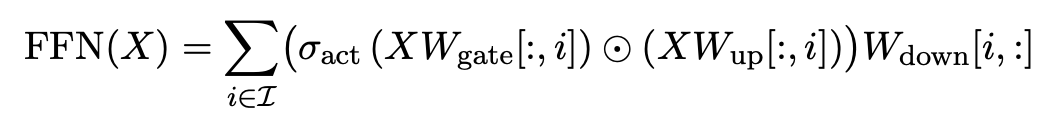
In order to find the sparse indices ahead of time, we can use low-rank predictors to calculate an approximate decomposition of the gate matrix. Using projections down to 4-10% of the hidden size allows the gate approximation to be computed lightning-fast, while still retaining accuracy. This can be accelerated even further by observing that the residual structure of transformers leads to very similar embeddings across layers – which means that we can compute the predictors for layer i asynchronously using the inputs from layer i-1, in order to fully minimize latency.
When combined with various hardware optimizations and asynchronous look-ahead execution of the sparse predictor layers, this approach (known as “Deja Vu”) led to 2-6x speedups in inference speed with little to no drop in accuracy [figure 1]. The approach was quickly adopted by other researchers, and iterated on by papers such as LLM in a Flash [Alizadeh et al.,2024], PowerInfer [Song et al., 2023] and PowerInfer2 [Xue et al., 2024].
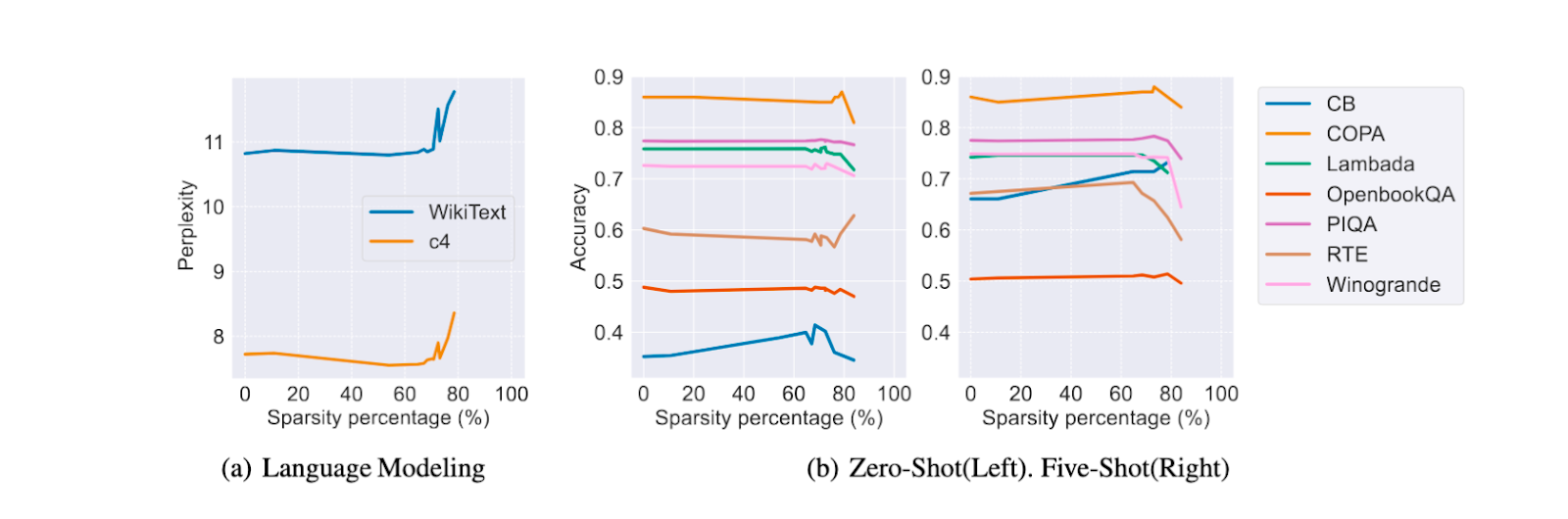
Figure 2: Downstream accuracy of sparsified OPT using Deja Vu sparse predictors. Little to no degradation in performance is observed, even at very high sparsity levels.
(figure taken from Liu et al. [2023])
The long‑tail challenge of modern LLMs
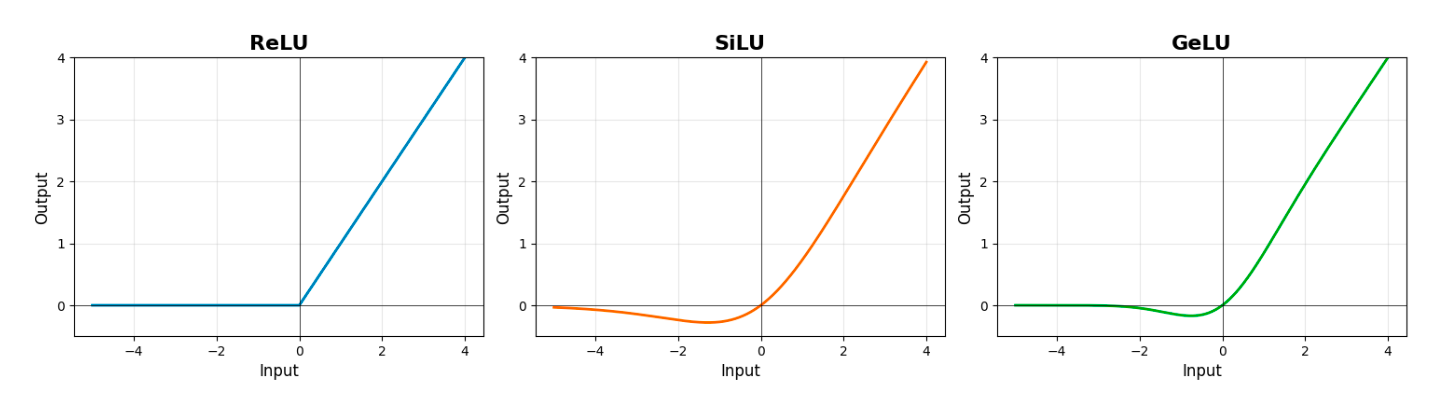
Figure 3: Plots of activation curves for ReLU, SiLU and GeLU.
Since OPT, newer state‑of‑the‑art models—including Llama, Mistral, and Gemma—have replaced ReLU with smoother activations like SiLU and GeLU. These functions do not hard‑zero negative inputs; instead they have “long tails” that smoothly extend past zero. As Figure 2 illustrates, this change dramatically reduces activation sparsity. Naively thresholding activations yields severe accuracy penalties, and sparsity levels fall far below the >95% seen in OPT.
Finding Sparsity in Modern LLMs
So is activation sparsity dead in the modern era? Not at all. Two major schools of thought have emerged as possible solutions to this challenge.
1. Relufication: Fine‑tuning back to ReLU
The simplest idea is to replace SiLU/GeLU activations with ReLU and then fine-tune the model to restore performance. Mirzadeh et al. [2023] showed that fine‑tuning a 7B‑parameter Llama on 15 billion tokens regained ≈60 % sparsity while sacrificing only about 1% accuracy across nine zero‑shot tasks. Subsequent work pushed sparsity even further: Song et al. proposed auxiliary losses and multi‑phase training schedules, achieving 80–90 % sparsity on Llama‑2 (7B and 13B) with negligible accuracy loss.
Relufication remains powerful, and pre‑trained “ReluLlama”, “ProSparse”, and “TurboSparse” checkpoints are already available. However, building relufied versions of every new model is expensive and requires large fine‑tuning runs, limiting its practicality.
2. Training‑free “Error Budget” thresholding: CATS and CETT
When retraining isn’t possible, we can approximate sparsity by thresholding activations. A straightforward approach called Contextually Aware Thresholding Sparsity (CATS) precomputes activation norms on a calibration set and drops neurons whose norms fall below the p‑th percentile; this achieved around 50% sparsity on Llama‑2 7B and Mistral 7B without fine‑tuning. However, CATS considered only the gate activations; small values multiplied by large weights could still contribute significantly to the output.
To address this, Zhang et al. proposed Cumulative Errors of Tail Truncation (CETT). For each neuron i, CETT computes the full contribution ni from that neuron — gate, up‑projection and down‑projection—and then chooses a threshold τ such that the L2‑norm of the neglected contributions remains below a target error budget. Fixing an “error budget” (e.g. allowing 20 % of the output norm to be dropped) yields a data‑dependent τ via binary search.
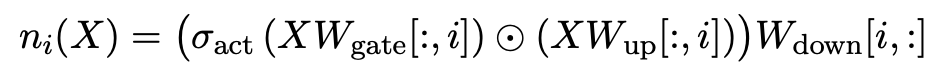
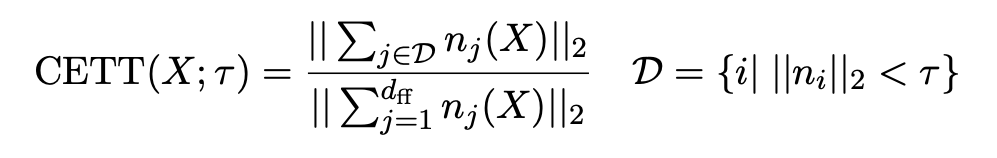
In our experiments, using a standard CETT budget of 0.2 recovered >60% sparsity across several modern models.
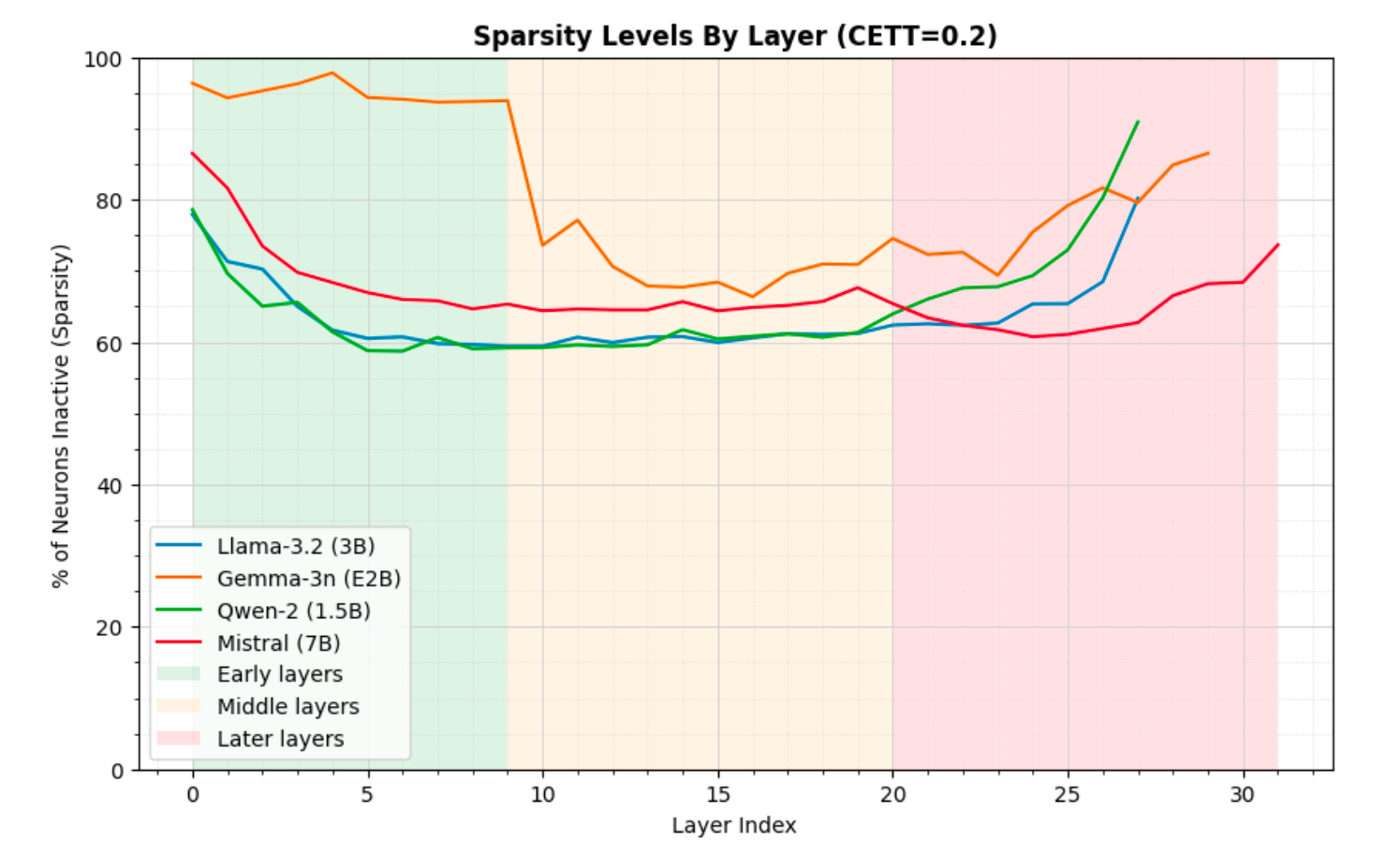
Figure 4: Sparsity Levels by Layer using CETT threshold of 0.2
Paging LLM Weights in Pytorch
Finding a sparse mask with CETT is only half of the challenge: we also need to execute sparse operations efficiently. A naive sparse implementation performs a full index_select(gather) on every forward pass to load active weights; this operation is memory‑bound bottlenecked. We observed that neuron concentration, the tendency for a small set of neurons to remain “hot” across successive tokens, means that many weights are reused across steps. Why reload them each time?
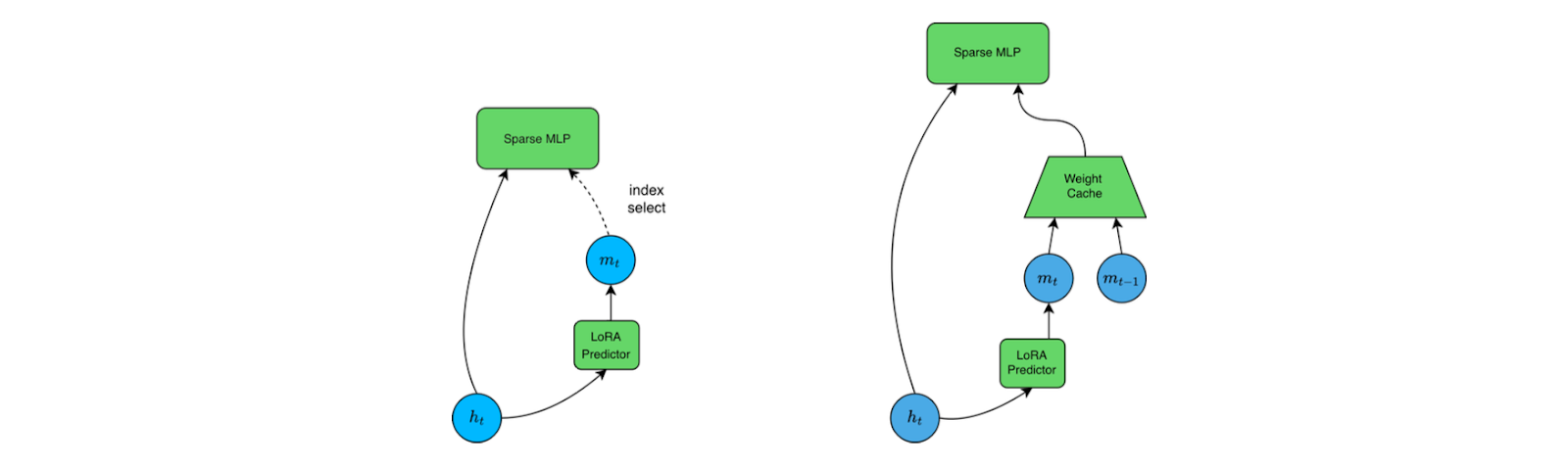
Figure 5: Left diagram shows a naive sparse mlp implementation, with full index select operation
at each step. Right shows our modified version with weight caching.
We built a custom weight caching operator in PyTorch that keeps previously active weights in a cache and loads only the difference between consecutive masks as isolated index swaps. The operator stores up‑projection weights in row‑major format and down‑projection weights in column‑major format for efficient memory copying. Preliminary experiments are promising: the cached implementation accelerates isolated index_select operations by 6.7× (29.89 ms → 4.46 ms) and yields up to 5× faster MLP inference on CPUs (30.1 ms → 6.02 ms) when combined with fused sparse kernels and OpenMP parallelisation.
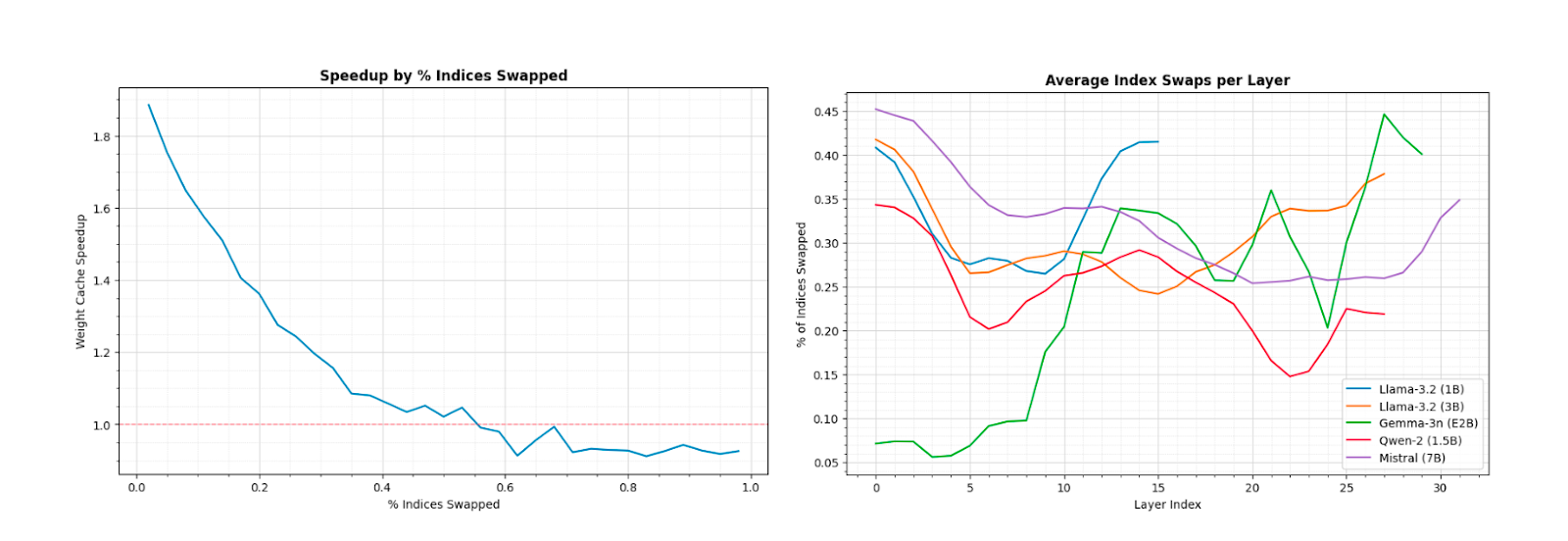
Figure 6: Overall speedup in MLP block operations as a function of index swaps per cache update. Right plot shows average index swaps for common models using sparsities derived from Fig 3.
Enforcing sparsity in LLM training
Sparsity is quickly moving from an optimization trick to a core architectural feature. DeepSeek v3.2 and Google’s Gemma 3-n are already enforcing it while training.
DeepSeek’s Lightning Indexer
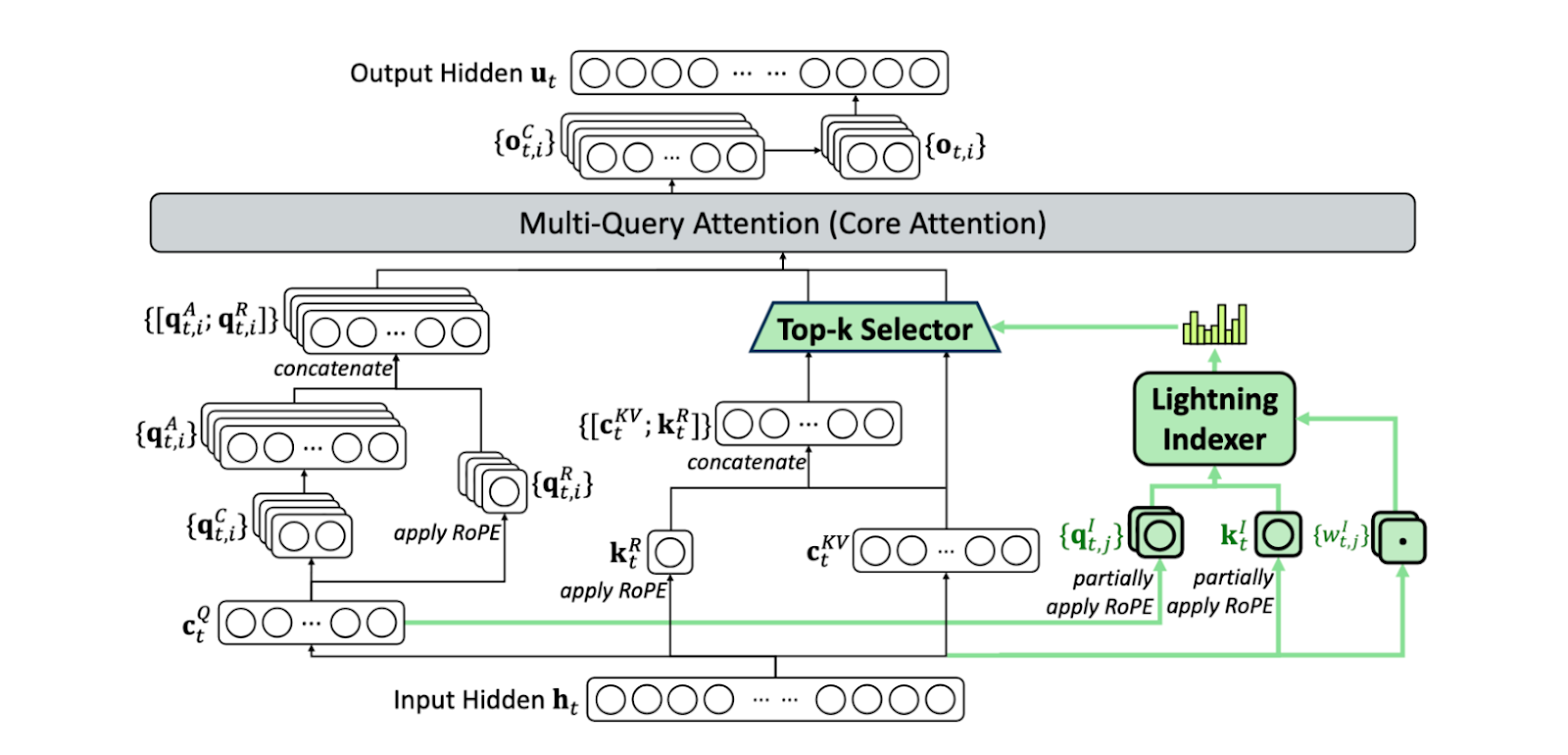
Figure 7: Architecture of Deepseek Sparse Attention (figure taken from DeepSeek-AI [2025])
DeepSeek’s v3.2 model introduces DeepSeek Sparse Attention (DSA), which uses a lightweight predictor called the lightning indexer. The indexer is essentially a small, ReLU‑activated network that operates on low‑precision vectors to estimate attention energies. By selecting the top‑k entries from these approximate energies, DSA narrows a 100k‑token context window down to a fixed 2048‑token slice for the full attention computation. The result is dramatically faster inference in long‑context settings. Although DeepSeek trained this mechanism on a huge corpus, the idea of a small predictor that prunes the attention window is broadly applicable.
Google’s Spark Transformer
Spark Transformer proposes a different sparse predictor for both attention and feed‑forward layers. It partitions the input vectors into two segments: a small prefix used only to compute a top‑k mask, and the remainder used for the full computation. Their approach involves defining sparse operators “SparkAttention” and “SparkFFN”, which function somewhat similarly to the lightweight sparse predictors we have discussed previously.
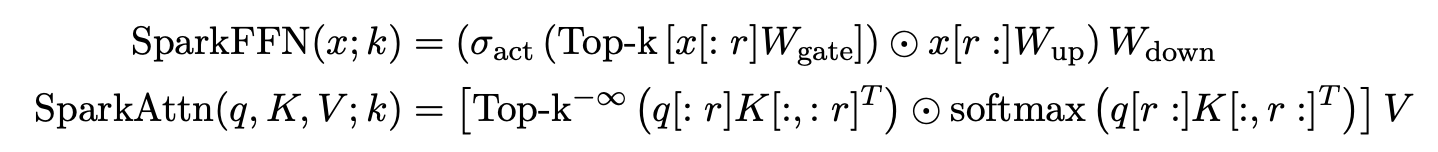
While the full SparkTransformer requires massive pretraining, its second contribution, statistical top‑k, is immediately useful. Instead of sorting activations to find the threshold, statistical top‑k models activations as approximately normally distributed and computes a threshold using means and standard deviations.
θ(x,k)=μ(x)+n(k)·σ(x)
This eliminates the need for expensive sorting, making top‑k selection much faster on GPUs. Versions of this technique have already appeared in Google’s Gemma 3‑n model.
Towards a Unified Sparse Inference Framework
Sparsity is transitioning from a research curiosity to a production necessity. The 2–6× speed‑ups demonstrated by contextual sparsity and weight caching are not incremental tweaks; they determine whether on‑device LLM deployment is feasible. Yet most existing implementations explore individual tricks in isolation. The real challenge is systematic integration.
At NimbleEdge, we are working to combine the best ideas – predictive masking, weight caching, statistical top‑k and hardware‑aware kernels – into a unified framework for sparse inference. Our repository is open, and we are releasing components and benchmarks as they mature. You can find it here:
https://github.com/NimbleEdge/sparse_transformers
Our current research priorities include:
Weight caching validation |
Confirming neuron‑concentration patterns across models and translating our 6.7× index‑select speed‑ups into end‑to‑end gains. |
CETT integration |
Combining relufied models and CETT‑based thresholding to recover sparsity on long‑tailed activations. |
Fused sparse kernels |
Developing kernels that simultaneously perform sparse prediction and cached weight access. |
Lightweight attention indexers |
Exploring long‑context attention indexers similar to DeepSeek’s lightning indexer for edge deployment. |
LLMs will continue to grow larger, and energy‑efficient inference will remain a central challenge. Sparsity provides a path forward. By revisiting activation functions (Relufication), adopting smarter thresholding methods (CETT), exploiting neuron concentration (weight caching) and borrowing innovations from frontier models (lightning indexers and statistical top‑k), we can achieve the multi‑fold speed‑ups necessary for edge deployment. But building a production‑grade sparse inference stack requires open collaboration. We invite researchers and practitioners to contribute to this effort: the future of edge AI depends on making sparse inference not the exception, but the standard.
For an in-depth understanding of sparsity and the latest developments, consult the white paper from the NimbleEdge team: Accelerating LLM Inference Using Sparsity.