Training large deep learning models requires large datasets. Amazon Simple Storage Service (Amazon S3) is a scalable cloud object store service used for storing large training datasets. Machine learning (ML) practitioners need an efficient data pipe that can download data from Amazon S3, transform the data, and feed the data to GPUs for training models with high throughput and low latency.
In this post, we introduce the new S3 IO DataPipes for PyTorch, S3FileLister and S3FileLoader. For memory efficiency and fast runs, the new DataPipes use the C++ extension to access Amazon S3. Benchmarking shows that S3FileLoader is 59.8% faster than FSSpecFileOpener for downloading a natural language processing (NLP) dataset from Amazon S3. You can build IterDataPipe training pipelines with the new DataPipes. We also demonstrate that the new DataPipe can reduce overall Bert and ResNet50 training time by 7%. The new DataPipes have been upstreamed to the open-source TorchData 0.4.0 with PyTorch 1.12.0.
Overview
Amazon S3 is a scalable cloud storage service with no limit on data volume. Loading data from Amazon S3 and feeding the data to high-performance GPUs such as NVIDIA A100 can be challenging. It requires an efficient data pipeline that can meet the data processing speed of GPUs. To help with this, we released a new high performance tool for PyTorch: S3 IO DataPipes. DataPipes are subclassed from torchdata.datapipes.iter.IterDataPipe, so they can interact with the IterableDataPipe interface. Developers can quickly build their DataPipe DAGs to access, transform, and manipulate data with shuffle, sharding, and batch features.
The new DataPipes are designed to be file format agnostic and Amazon S3 data is downloaded as binary large objects (BLOBs). It can be used as a composable building block to assemble a DataPipe graph that can load tabular, NLP, and computer vision (CV) data into your training pipelines.
Under the hood, the new S3 IO DataPipes employ a C++ S3 handler with the AWS C++ SDK. In general, a C++ implementation is more memory efficient and has better CPU core usage (no Global Interpreter Lock) in threading compared to Python. The new C++ S3 IO DataPipes are recommended for high throughput, low latency data loading in training large deep learning models.
The new S3 IO DataPipes provide two first-class citizen APIs:
- S3FileLister – Iterable that lists S3 file URLs within the given S3 prefixes. The functional name for this API is
list_files_by_s3. - S3FileLoader – Iterable that loads S3 files from the given S3 prefixes. The functional name for this API is
load_files_by_s3.
Usage
In this section, we provide instructions for using the new S3 IO DataPipes. We also provide a code snippet for load_files_by_s3().
Build from source
The new S3 IO DataPipes use the C++ extension. It is built into the torchdata package by default. However, if the new DataPipes are not available within the environment, for example Windows on Conda, you need to build from the source. For more information, refer to Iterable Datapipes.
Configuration
Amazon S3 supports global buckets. However, a bucket is created within a Region. You can pass a Region to the DataPipes by using __init__(). Alternatively, you can either export AWS_REGION=us-west-2 into your shell or set an environment variable with os.environ['AWS_REGION'] = 'us-east-1' in your code.
To read objects in a bucket that aren’t publicly accessible, you must provide AWS credentials through one of the following methods:
- Install and configure the AWS Command Line Interface (AWS CLI) with
AWS configure - Set credentials in the AWS credentials profile file on the local system, located at
~/.aws/credentialson Linux, macOS, or Unix - Set the
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYenvironment variables - If you’re using this library on an Amazon Elastic Compute Cloud (Amazon EC2) instance, specify an AWS Identity and Access Management (IAM) role and then give the EC2 instance access to that role
Example code
The following code snippet provides a typical usage of load_files_by_s3():
from torch.utils.data import DataLoader
from torchdata.datapipes.iter import IterableWrapper
s3_shard_urls = IterableWrapper(["s3://bucket/prefix/",])
.list_files_by_s3()
s3_shards = s3_shard_urls.load_files_by_s3()
# text data
training_data = s3_shards.readlines(return_path=False)
data_loader = DataLoader(
training_data,
batch_size=batch_size,
num_workers=num_workers,
)
# training loop
for epoch in range(epochs):
# training step
for bach_data in data_loader:
# forward pass, backward pass, model update
Benchmark
In this section, we demonstrate how the new DataPipe can reduce overall Bert and ResNet50 training time.
Isolated DataLoader performance evaluation against FSSpec
FSSpecFileOpener is another PyTorch S3 DataPipe. It uses botocore and aiohttp/asyncio to access S3 data. The following is the performance test setup and result (quoted from Performance Comparison between native AWSSDK and FSSpec (boto3) based DataPipes).
The S3 data in the test is a sharded text dataset. Each shard has about 100,000 lines and each line is around 1.6 KB, making each shard about 156 MB. The measurements in this benchmark are averaged over 1,000 batches. No shuffling, sampling, or transforms were performed.
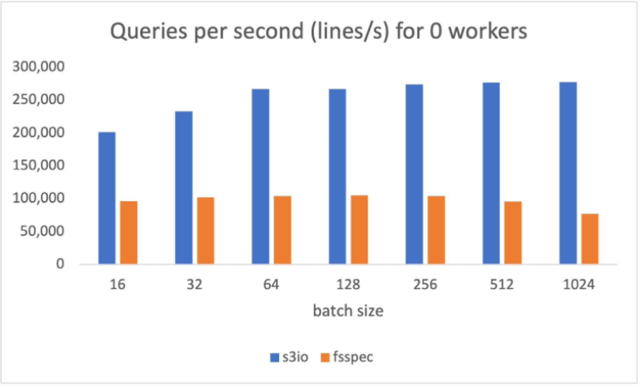
The following chart reports the throughput comparison for various batch sizes for num_workers=0, the data loader runs in the main process. S3FileLoader has higher queries per second (QPS). It is 90% higher than fsspec at batch size 512.
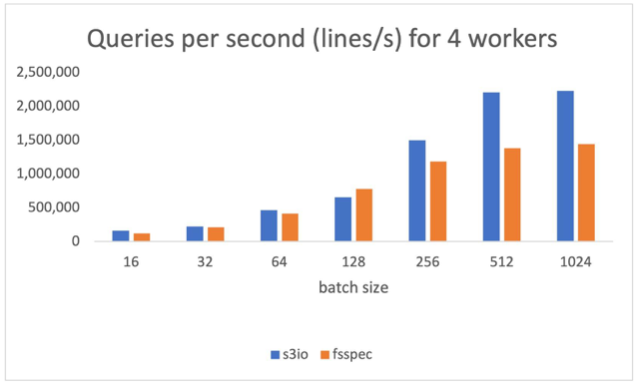
The following chart reports the results for num_workers=4, the data loaders runs in the main process. S3FileLoader is 59.8% higher than fsspec at batch size 512.
Training ResNet50 Model against Boto3
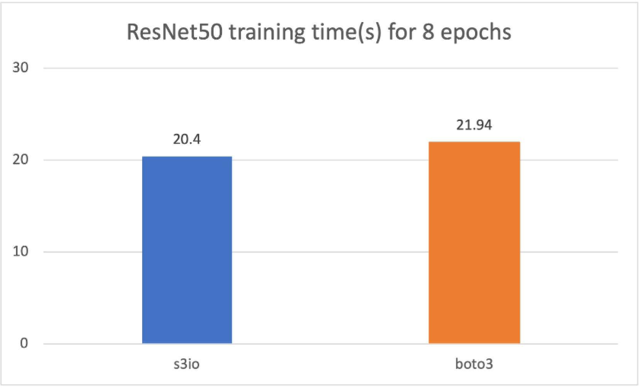
For the following chart, we trained a ResNet50 model on a cluster of 4 p3.16xlarge instances with a total 32 GPUs. The training dataset is ImageNet with 1.2 million images organized into 1,000-image shards. The training batch size is 64. The training time is measured in seconds. For eight epochs, S3FileLoader is 7.5% faster than Boto3.
Training a Bert model against Boto3
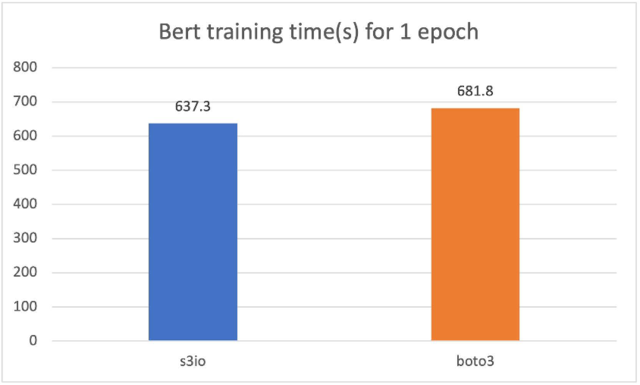
For the following cart, we trained a Bert model on a cluster of 4 p3.16xlarge instances with a total 32 GPUs. The training corpus has 1474 files. Each file has around 150,000 samples. To run a shorter epoch, we use 0.05% (approximately 75 samples) per file. The batch size is 2,048. The training time is measured in seconds. For one epoch, S3FileLoader is 7% faster than Boto3.
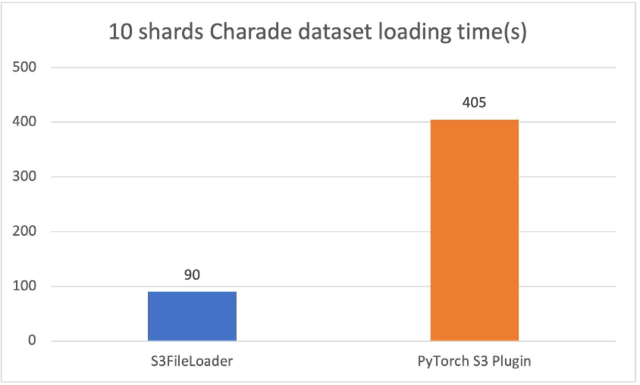
Comparison against the original PyTorch S3 plugin
The new PyTorch S3 DataPipes perform substantially better than the original PyTorch S3 plugin. We have tuned the internal buffer size for S3FileLoader. The loading time is measured in seconds.
For the 10 sharded charades files (approximately 1.5 GiB each), S3FileLoader was 3.5 times faster in our experiments.
Best practices
Training large deep learning models may require a massive compute cluster with tens or even hundreds of nodes. Each node in the cluster may generate a large number of data loading requests that hit a specific S3 shard. To avoid throttle, we recommend sharding training data across S3 buckets and S3 folders.
To achieve good performance, it helps to have file sizes that are big enough to parallelize across a given file, but not so big that we hit the limits of throughput on that object on Amazon S3 depending on the training job. The optimal size can be between 50–200 MB.
Conclusion and next steps
In this post, we introduced you to the new PyTorch IO DataPipes. The new DataPipes use aws-sdk-cpp and show better performance against Boto3-based data loaders.
For next steps, we plan to improve on usability, performance, and functionality by focusing on the following features:
- S3 authorization with IAM roles – Currently, the S3 DataPipes support explicit access credentials, instance profiles, and S3 bucket policies. However, there are use cases where IAM roles are preferred.
- Double buffering – We plan to offer double buffering to support multi-worker downloading.
- Local caching – We plan on making model training able to traverse the training dataset for multiple passes. Local caching after the first epoch can cut out time of flight delays from Amazon S3, which can substantially accelerate data retrieval time for subsequent epochs.
- Customizable configuration – We plan to expose more parameters such as internal buffer size, multi-part chunk size, and executor count and allow users to further tune data loading efficiency.
- Amazon S3 upload – We plan to expand the S3 DataPipes to support upload for checkpointing.
- Merge with fsspec –
fsspecis used in other systems such astorch.save(). We can integrate the new S3 DataPipes withfsspecso they can have more use cases.
Acknowledgement
We would like to thank Vijay Rajakumar and Kiuk Chung from Amazon for providing their guidance for S3 Common RunTime and PyTorch DataLoader. We also want to thank Erjia Guan, Kevin Tse, Vitaly Fedyunin , Mark Saroufim, Hamid Shojanazeri, Matthias Reso, and Geeta Chauhan from Meta AI/ML, and Joe Evans from AWS for reviewing the blog and the GitHub PRs.