TL;DR. We show how to use Accelerated PyTorch 2.0 Transformers and the newly introduced torch.compile() method to accelerate Large Language Models on the example of nanoGPT, a compact open-source implementation of the GPT model from Andrej Karpathy. Using the new scaled dot product attention operator introduced with Accelerated PT2 Transformers, we select the flash_attention custom kernel and achieve faster training time per batch (measured with Nvidia A100 GPUs), going from a ~143ms/batch baseline to ~113 ms/batch. In addition, the enhanced implementation using the SDPA operator offers better numerical stability. Finally, further optimizations are achieved using padded inputs, which when combined with flash attention lead to ~87ms/batch.
Recent times have seen exponential adoption of large language models (LLMs) and Generative AI in everyday life. Tightly coupled with these ever-growing models is the ever-growing training cost – in terms of both time and hardware utilization. The PyTorch team has tackled these challenges head on with Accelerated PyTorch 2 Transformers (previously known as “Better Transformer”) and JIT Compilation in PyTorch 2.0.
In this blog post, we explore training optimizations gained by utilizing custom kernel implementations of SDPA – also known as scaled dot product attention – a critical layer in transformer models. The custom kernel for SDPA replaces several discrete sequential operations with one globally optimized kernel which avoids allocating a large amount of intermediate CUDA memory. This approach offers a number of advantages, including but not limited to: higher performance computation of SDPA by reducing memory bandwidth bottleneck, reduced memory footprint to support larger batch sizes, and finally added numerical stability by prescaling input tensors. These optimizations are demonstrated on nanoGPT, an open-source implementation of GPT from Andrej Karpathy.
Background
Scaled dot product attention is the fundamental building block of multihead attention, as introduced in “Attention is All You Need”, and has a wide range of applications in LLM and Generative AI models.
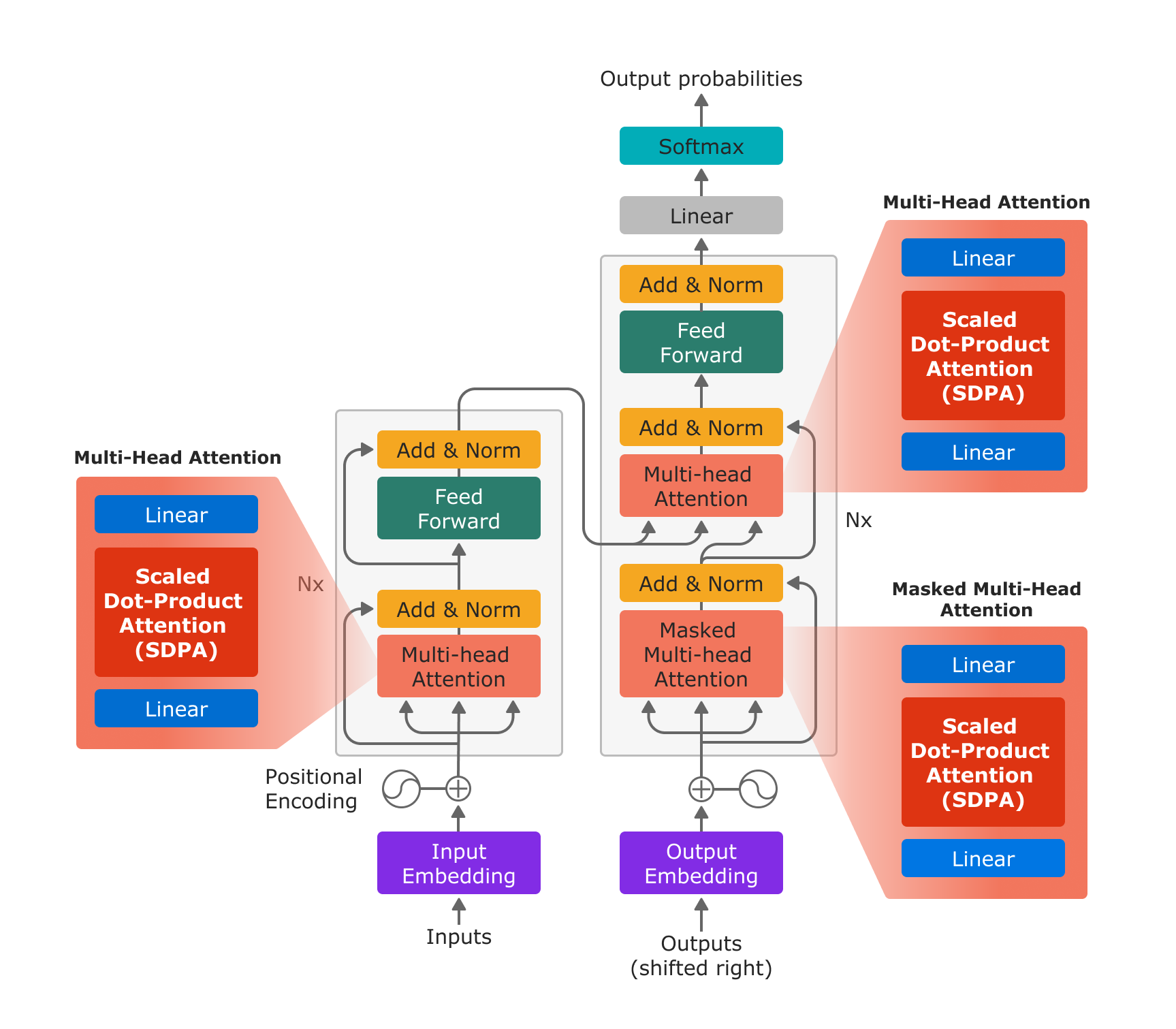
Figure 1: The Transformer model architecture based on “Attention is All You Need”. With the new PyTorch SDPA operator, Multi-Head Attention is efficiently implemented by a linear layer for the in-projection, the SDPA operator, and a linear layer for the out-projection.
With the new scaled_dot_product_attention operator, multihead attention can be implemented in just 3 steps: in projection with a linear layer, SDPA, and out projection with a linear layer.
# In Projection
# variable descriptions:
# q,k,v = Query, Key, Value tensors
# bsz = batch size
# num_heads = Numner of heads for Multihead Attention
# tgt_len = Target length
# src_len = Source Length
# head_dim: Head Dimension
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
q = q.view(bsz, num_heads, tgt_len, head_dim)
k = k.view(bsz, num_heads, src_len, head_dim)
v = v.view(bsz, num_heads, src_len, head_dim)
# Scaled Dot Product Attention
attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
# Out Projection
attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
PyTorch 2. supports multiple different kernels optimized for specific use cases, with specific requirements. A kernel picker picks the best kernel for a particular combination of input parameters. If no optimized “custom kernel” for a particular combination of input parameters can be identified, the kernel picker selects a general kernel that can handle all input combinations.
While future releases may extend this set of operators, PyTorch 2.0 launches with 3 implementations for the SDPA operator:
- A generic kernel which implements the mathematical equation of SDPA in the function
sdpa_math() - An optimized kernel based on the paper “Flash Attention”, which supports evaluation of SDPA with 16 bit floating point data types on compute architecture SM80 (A100).
- An optimized kernel based on the paper “Self-Attention Does Not Need O(n^2) Memory” and implemented in xFormer, which supports both 32 and 16 bit floating data types on a wider range of architectures (SM40 and later). This blog post refers to this kernel as the
mem_efficientkernel.
Note that both optimized kernels (two and three listed above), support a key padding mask and limit the supported attention mask to causal attention. Accelerated PyTorch 2.0 Transformers today only support the causal mask when it is specified using the is_causal boolean. When a mask is specified, the general-purpose kernel will be selected because it is too expensive to analyze the contents of a provided mask to determine if it is the causal mask. Additional explanations on the constraints for each kernel can be found in the Accelerated PT2 Transformer blog.
Enabling Accelerated Transformers with nanoGPT
The SDPA operator being a critical component of the GPT model, we identified the open source nanoGPT model as an excellent candidate for both demonstrating the ease of implementation and benefits of PyTorch 2.0’s Accelerated Transformers. The following demonstrates the exact process by which Accelerated Transformers was enabled on nanoGPT.
This process largely revolves around replacing the existing SDPA implementation with the newly added F.scaled_dot_product_attention operator from functional.py. This process can be easily adapted to enable the operator in many other LLMs. Alternatively, users can instead choose to call F.multi_head_attention_forward() or utilize the nn.MultiHeadAttention module directly where applicable. The following code snippets are adapted from Karpathy’s nanoGPT repository.
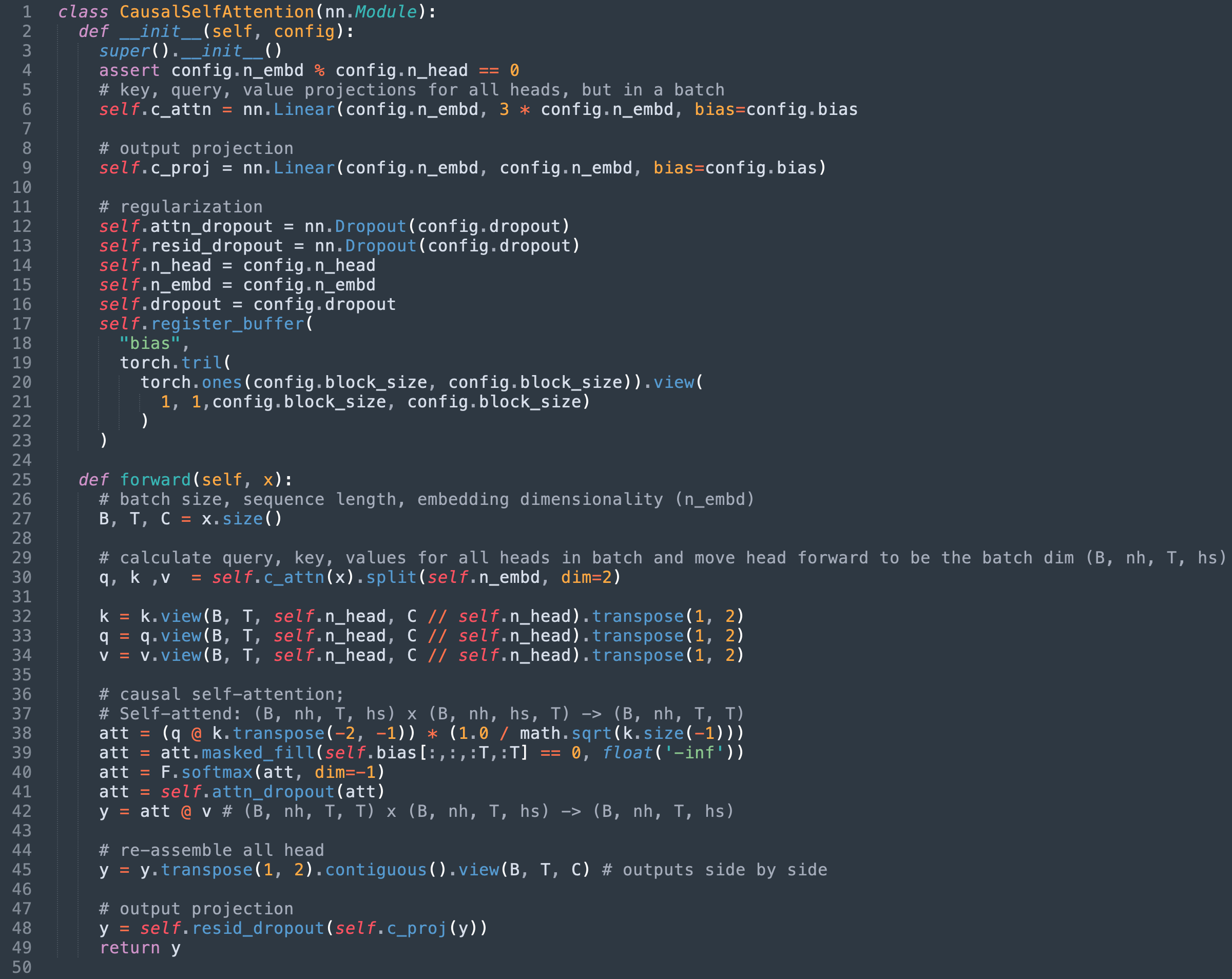
Step 1: Identify the existing SDPA implementation
In the case of nanoGPT, SDPA is implemented in the model’s CausalSelfAttention class. The original implementation at time of writing is adapted below for this post.
Step 2: Replace with Torch’s scaled_dot_product_attention
At this point we can note the following:
- Lines 36 – 42 define the mathematical implementation of SDPA which we are replacing
- The mask applied on line 39 is no longer relevant since we are using scaled_dot_product_attention’s
is_causalflag. - The dropout layer used in line 41 is also now unnecessary.
Swapping out the SDPA implementation for torch’s scaled_dot_product_attention and removing the now redundant code yields the following implementation.
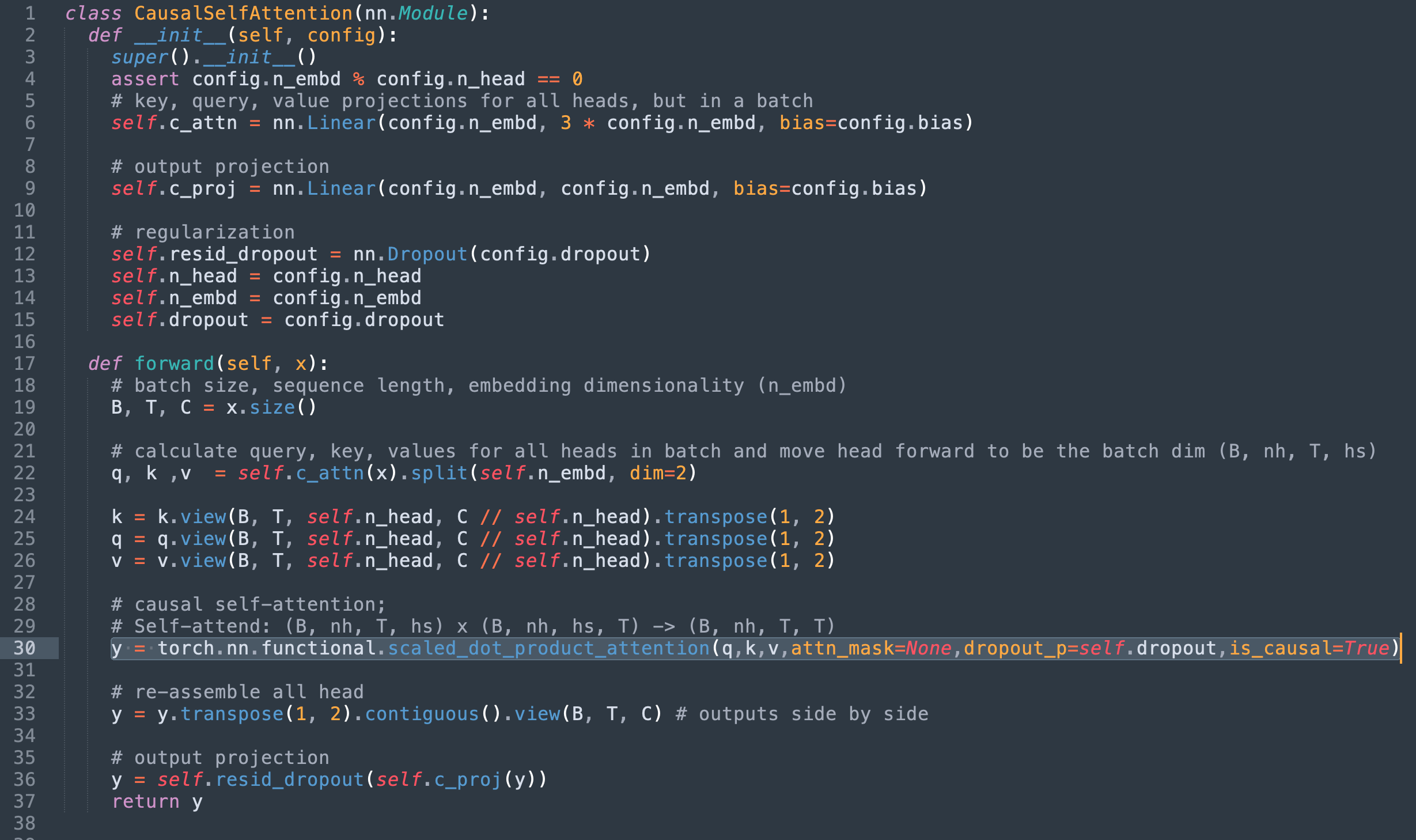
Alternatively, the original mask can be passed into the attn_mask field however due to the mentioned kernel constraints that would limit the implementation to only support the generic sdpa_math kernel.
Step 3 (Bonus): Faster matmuls with padding
On top of the performance improvements from SDPA, our analysis yielded a nice ancillary win. In Andrej’s words “The most dramatic optimization to nanoGPT so far (~25% speedup) is to simply increase the vocab size from 50257 to 50304 (nearest multiple of 64).”

The vocab size determines the dimensions of matmuls in the output layer of GPT, and these are so large that they were taking a majority of the time for the entire training loop! We discovered that they were achieving performance significantly below the peak throughput achievable on the A100 GPU, and guessed from NVIDIA’s matmul documentation that 64-element alignment would yield better results. Indeed, padding these matmuls achieves nearly a 3x speedup! The underlying cause is that unaligned memory accesses significantly reduce efficiency. A deeper analysis can be found in this Twitter thread.
With this optimization we were able to further reduce training time from ~113 ms (using flash attention) to ~87 ms per batch.
Results
The figure below demonstrates the performance gained using Pytorch custom kernels. Here are the exact figures:
- baseline (nanoGPT implementation): ~143ms
- sdpa_math (generic): ~134ms (6.71% faster)
mem_efficientkernel: ~119ms (20.16% faster)flash_attentionkernel: ~113ms (26.54% faster)- flash_attention + padded vocab: ~87ms (64.37% faster)
All code was run on an 8 x NVIDIA Corporation A100 server with 80 GB HBM [A100 SXM4 80GB], and for the purpose of this experiment dropout was set to 0.
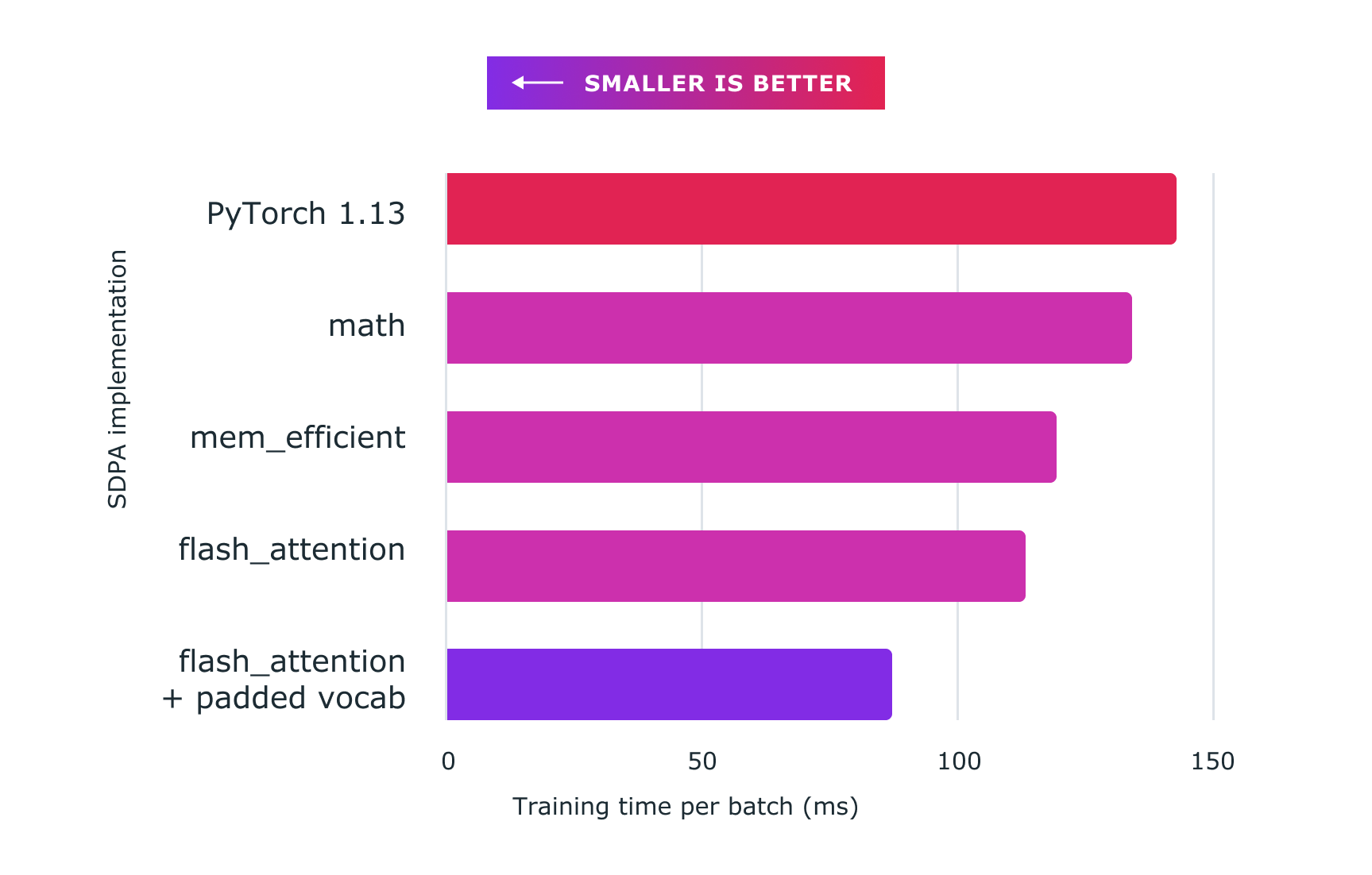
Figure 2: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for nanoGPT shown here.
Enhancing Numerical Model Stability
In addition to being faster, PyTorch’s implementation offers increased numerical stability by avoiding loss of precision in many execution scenarios. There is a great explanation here, but essentially the PyTorch implementation scales the Query and Key matrices before multiplication, which is said to be more stable and avoid loss of precision. Because of the merged custom kernel architecture of SDPA, this scaling does not introduce additional overhead in the computation of the attention result. In comparison, an implementation from the individual computational components would require separate pre-scaling at additional cost. For an additional explanation, see Appendix A.
Improved Memory Consumption
Yet another large advantage of using the torch SDPA kernels is the reduced memory footprint, which allows for the utilization of larger batch sizes. The following chart compares the best validation loss after one hour of training for both flash attention and the baseline implementations of causal attention. As can be seen, the maximum batch size achieved with the baseline causal attention implementation (on 8 x NVIDIA Corporation A100 server with 80 GB HBM) was 24, significantly less then the maximum achieved with flash attention, which was 39.
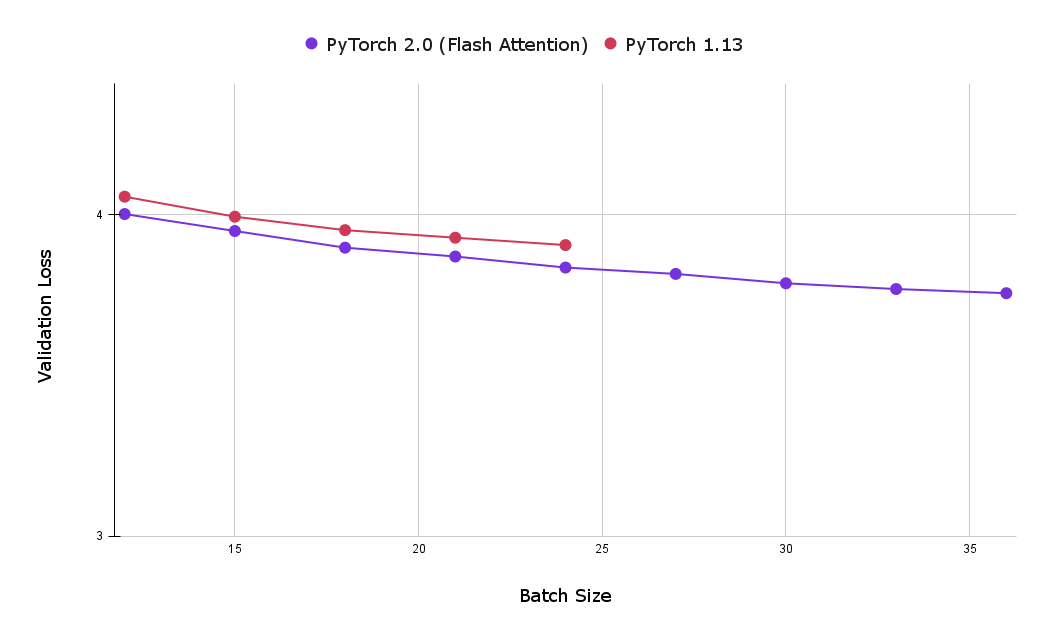
Figure 3: Using Flash Attention enables the usage of larger batch sizes, allowing users to achieve lower validation loss after one hour of training (smaller is better).
Conclusion
Accelerated PyTorch 2 Transformers were designed to make the training and production deployment of state-of-the-art transformer models affordable and integrated with PyTorch 2.0 model JIT compilation. The newly introduced PyTorch SDPA operator provides improved performance for training Transformer models and is particularly valuable for the expensive Large Language Model training. In this post we demonstrate a number of optimizations on the exemplary nanoGPT model including:
- Over 26% training speedup, when compared against the baseline with constant batch size
- An additional speedup achieved with padded vocabulary, bringing the total optimization to approximately 64% compared to the baseline
- Additional numerical stability
Appendix A: Analyzing Attention Numeric Stability
In this section we provide a more in depth explanation of the previously mentioned enhanced numerical stability which is gained by prescaling SDPA’s input vectors. The following is a simplified version of nanoGPT’s mathematical implementation of SDPA. The important thing to note here is that the query undergoes matrix multiplication without being scaled.
# nanoGPT implementation of SDPA
# notice q (our query vector) is not scaled !
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
# Dropout is set to 0, so we can safely ignore this line in the implementation# att = self.attn_dropout(att)
y_nanogpt = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
The following is the equivalent mathematical implementation in torch’s scaled_dot_product_attention.
# PyTorch implementation of SDPA
embed_size = q.size(-1)
scaling_factor = math.sqrt(math.sqrt(embed_size))
q = q / scaling_factor # notice q _is_ scaled here !
# same as above, but with scaling factor
att = q @ (k.transpose(-2, -1) / scaling_factor)
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att0, dim=-1)
# Dropout is set to 0, so we can safely ignore this line in the implementation# att = self.attn_dropout(att)
y_scale_before = att @ v
Mathematically both approaches should be equivalent, however our experimentation shows that in practice we receive different results from each approach.
Using the approach above, we verified y_scale_before matches the expected output from using the scaled_dot_product_attention method while y_nanogpt does not.
The torch.allclose method was used to test equivalence. Specifically, we showed that:
y_sdpa = torch.nn.functional._scaled_dot_product_attention(
q,
k,
v,
attn_mask=self.bias[:,:,:T,:T] != 0,
dropout_p=0.0,
need_attn_weights=False,
is_causal=False,
)
torch.allclose(y_sdpa, y_nanogpt) # False, indicating fp issues
torch.allclose(y_sdpa, y_scale_before) # True, as expected
Appendix B: Reproducing Experiment Results
Researchers seeking to reproduce these results should start with the following commit from Andrej’s nanoGPT repository – b3c17c6c6a363357623f223aaa4a8b1e89d0a465. This commit was used as the baseline when measuring the per batch speed improvements. For results which include padded vocabulary optimizations (which yielded the most significant improvements to batch speed), use the following commit – 77e7e04c2657846ddf30c1ca2dd9f7cbb93ddeab. From either checkout, selecting kernels for experimentation is made trivial with the use of the torch.backends API.
The desired kernel can be selected via a context manager:
with torch.backends.cuda.sdp_kernel (
enable_math = False,
enable_flash = False,
enable_mem_efficient = True
):
train(model)