Introduction
As introduced in a previous blog post, Helion is a high-level DSL that empowers developers to write high-performance ML kernels using a familiar PyTorch-like syntax, delegating the complex task of optimization to its autotuning engine. This autotuner explores a vast, high-dimensional space of implementation choices—block sizes, loop orders, memory access patterns—to discover configurations that maximize performance on the target hardware. As a result, Helion can achieve significant speedups over torch.compile and even highly-optimized, hand-written kernels in Triton or CuTe DSL.
However, the performance gains from auto-tuning comes with a cost: long wall-clock times. A typical autotuning session can take 10+ minutes, evaluating thousands of candidate configurations, and can even take on the order of hours for complex kernels. Since its launch, long autotuning times have consistently surfaced as a user complaint and one of the biggest pain points in the kernel development cycle. While Helion provides developers options to shorten the auto-tuning process, e.g. by reducing the number of search steps, this typically leads to a loss in kernel performance, forcing an undesirable trade-off.
In this blog post, we discuss our ongoing efforts to improve the autotuning experience. In particular, we discuss a new search algorithm LFBO Pattern Search we developed to address these issues, which employs techniques from machine learning (ML) to improve efficiency of the autotuning engine. The search algorithm trains an ML model to intelligently filter candidate configurations, substantially reducing the number of candidates evaluated. Importantly, the model only uses data collected during the search process, and doesn’t need the user to provide any additional data.
Using ML, we can reduce autotuning time substantially without sacrificing performance:
- On our set of benchmark NVIDIA B200 kernels, we reduce autotuning time by 36.5% while improving kernel latency by 2.6% on average.
- On AMD MI350 kernels, we reduce autotuning time by 25.9% while improving kernel latency by 1.7%.
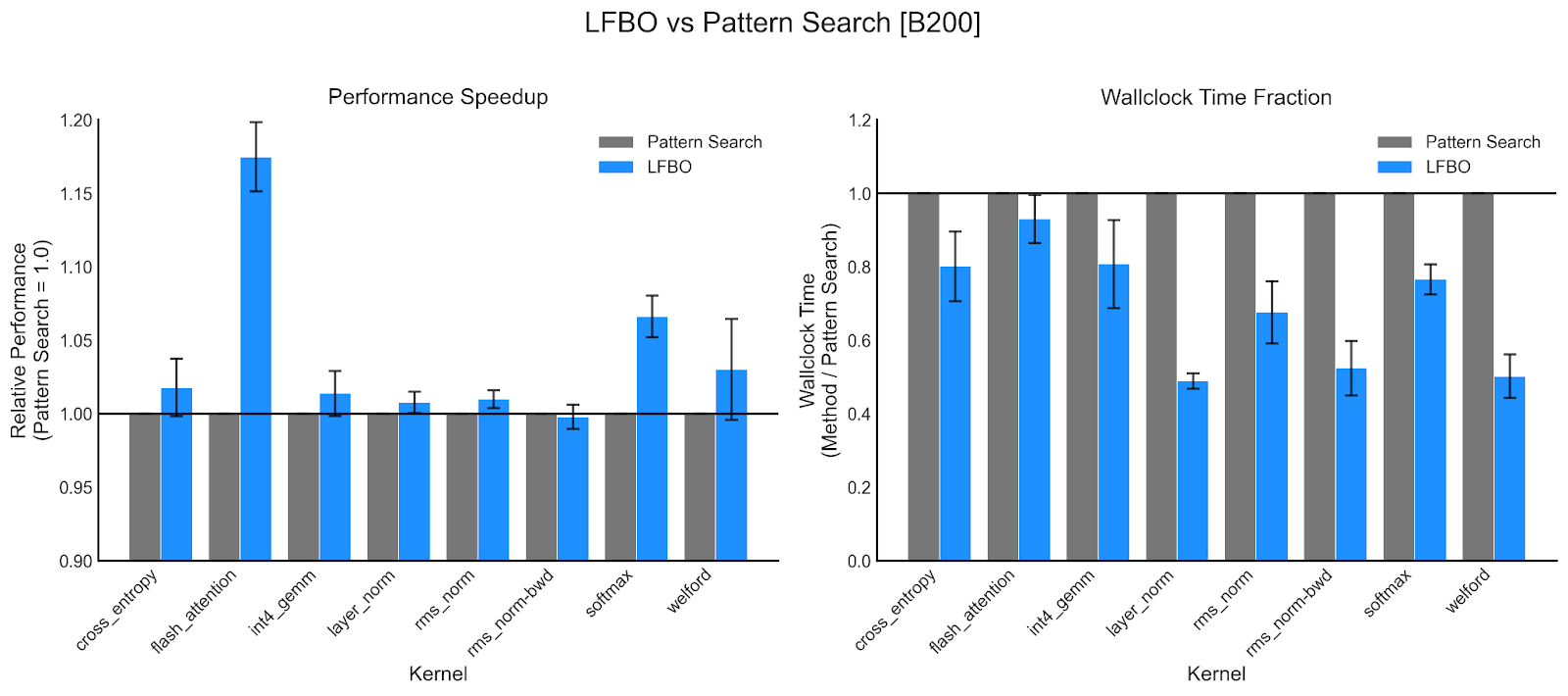
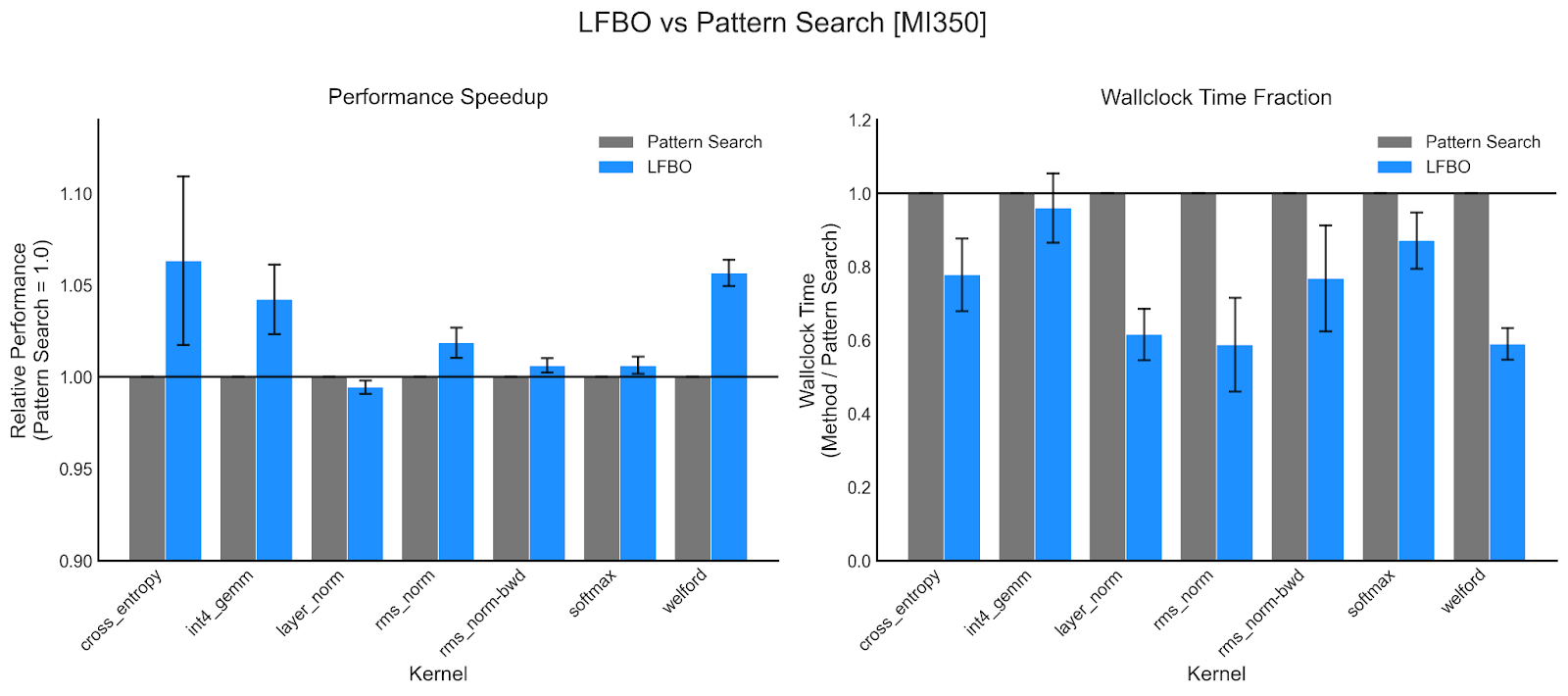
For some kernels the improvements are especially significant: we see up to a 50% reduction in wall-clock time for B200 layer-norm kernels, and even a >15% improvement in kernel latency for B200 Helion FlashAttention kernels. Due to its enhanced performance, it is the default search algorithm at the time of writing.
The Challenges of Kernel Autotuning
The autotuning engine searches through kernel configurations, benchmarking their latency and using the outcomes to determine the next set of configs to benchmark. While compiling and measuring the latency of a single configuration takes on the order of seconds, the autotuning engine typically searches through thousands of configurations to achieve the best possible performance. Finding the optimal kernel configuration is a challenging optimization problem due to several factors inherent to the design space:
- High-Dimensional, Combinatorial Space: The space of all possible combinations of block sizes, unroll factors, etc. is high-dimensional and vast. Even a simple kernel like LayerNorm has more than 8 quadrillion (10^16) possible configurations. However, while the search space is large, only a small fraction of configs have good performance.
- Long Compile Times: Certain kernel configurations can take a significant amount of time to compile, unnecessarily extending the autotuning process’s wall-clock time.
- Config Errors and Timeouts: The search space can also include configs that have compilation errors, produce inaccurate results, or take too long to compile.
The previous default search strategy (Pattern Search) starts from multiple promising configurations (‘search copies’) and explores neighboring configs by exhaustively evaluating all single-parameter perturbations. While thorough, this approach is inefficient: the vast majority of neighbors offer no performance improvement, yet each is compiled and benchmarked. Furthermore, restricting moves to single-parameter changes limits the algorithm’s ability to traverse the high-dimensional search space quickly.
Likelihood-Free Bayesian Optimization Pattern Search
To address these inefficiencies, we take inspiration from Bayesian Optimization, a sub-domain of machine learning which utilizes a probabilistic surrogate model (e.g. a Gaussian Process) to intelligently select which points to evaluate next (available in libraries such as botorch and Ax). To minimize additional wall-clock time, we adapt Likelihood-Free Bayesian Optimization (LFBO), which uses a lighter-weight classification model as a surrogate. We combine the local search heuristic of Pattern Search with the LFBO classifier model to filter only the most promising candidates to benchmark, instead of exhaustive search.
The LFBOPatternSearch algorithm is as follows:
- Similar to PatternSearch, we first benchmark a set of randomly generated configs, and identify a small set of the most promising configurations (‘search copies’).
- We generate candidates from the search copies, by making random perturbations across multiple parameters, exploring more widely than PatternSearch.
- We train a classification model (RandomForest) on latency data collected so far. Instead of predicting latency directly, we predict a binary label indicating whether the config is in the top 10% in terms of latency.
- We rank the candidates based on ML model predictions. Unlike typical LFBO, we also add a penalty for similarity to previously ranked candidates to encourage exploration.
- We select the top 10% of them to compile and benchmark. We update the search copies based on the best performing configs and add the latencies to the dataset.

We discuss some key design decisions, which are critical for achieving the improvements in wall-clock time and latency we observed:
Classification vs Regression: Regression-based methods, i.e. training the model to predict latency directly, is the de-facto approach for cost modeling in systems / compiler research. However, we find that a classification-based approach better focuses model capacity on the most performant configs instead of trying to learn the latency of all configs, good or bad. Second, the classification loss enables the model to learn to avoid configs that error out or suffer compile timeouts (as these are assigned negative labels). However, these points do not have any valid latency data for a regression-based approach to learn from.
Encouraging Diversity: Typically configs are compiled in batch, to take advantage of parallelized pre-compilation. The Random Forest classifier may repeatedly select similar configurations that cluster, which can waste the batch budget on redundant samples that provide little new information. To mitigate this, we compute a similarity score based on leaf node co-occurrence from the Random Forest model, and penalize similarity to previously ranked configs.
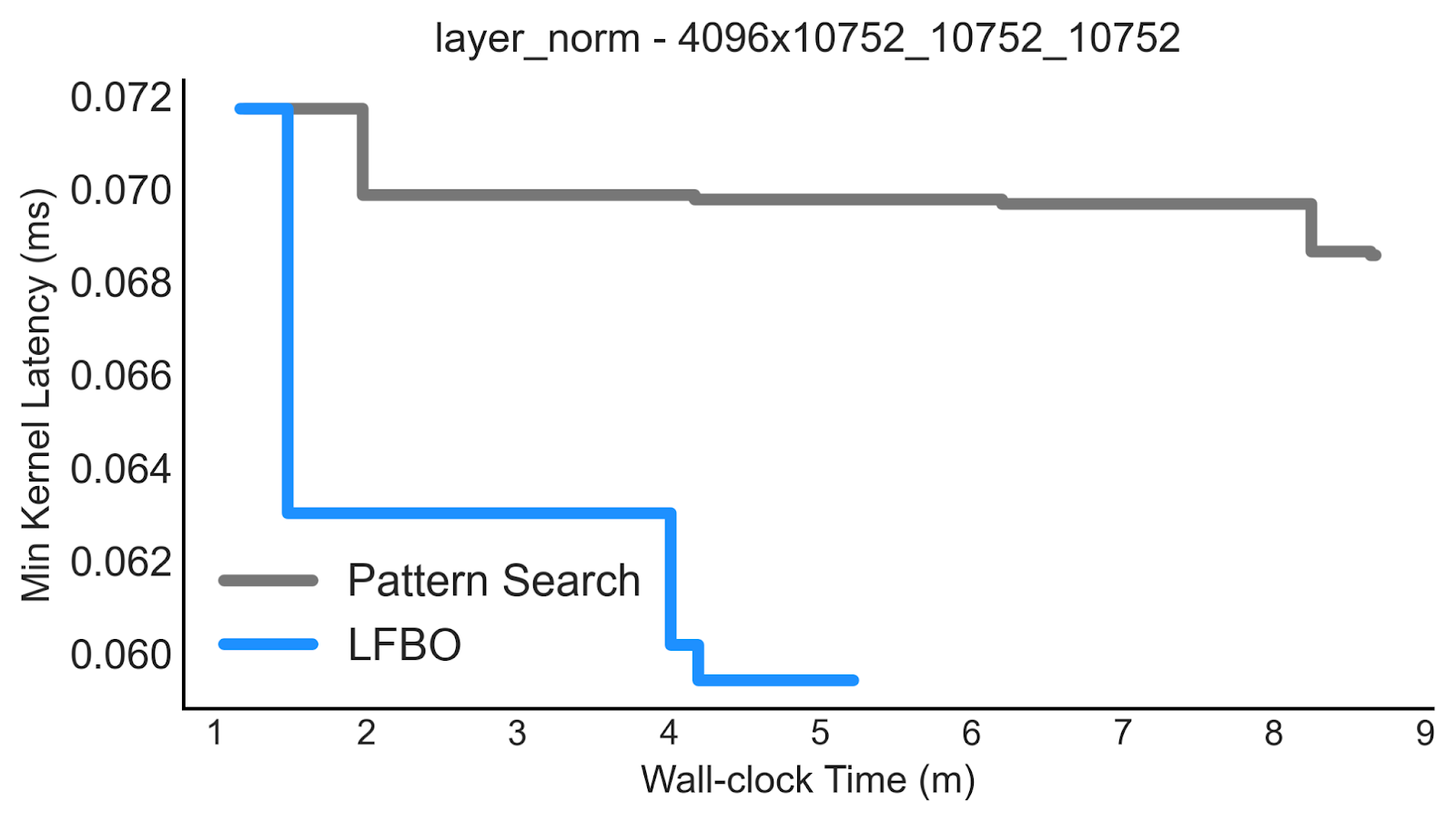
When we investigate the behavior of LFBO Pattern Search, we see indeed that improvements in performance across kernels, hardware types, and shapes are due its ability to find configurations with better runtime using fewer evaluations. Below is a plot of example auto-tuning traces for a B200 layer-norm kernel, displaying the latency of the best configuration obtained by the autotuner over time. We see not only that LFBO completes auto-tuning earlier (~5 min instead of ~9 min), it finds better configurations faster with much larger jumps in performance compared to Pattern Search.
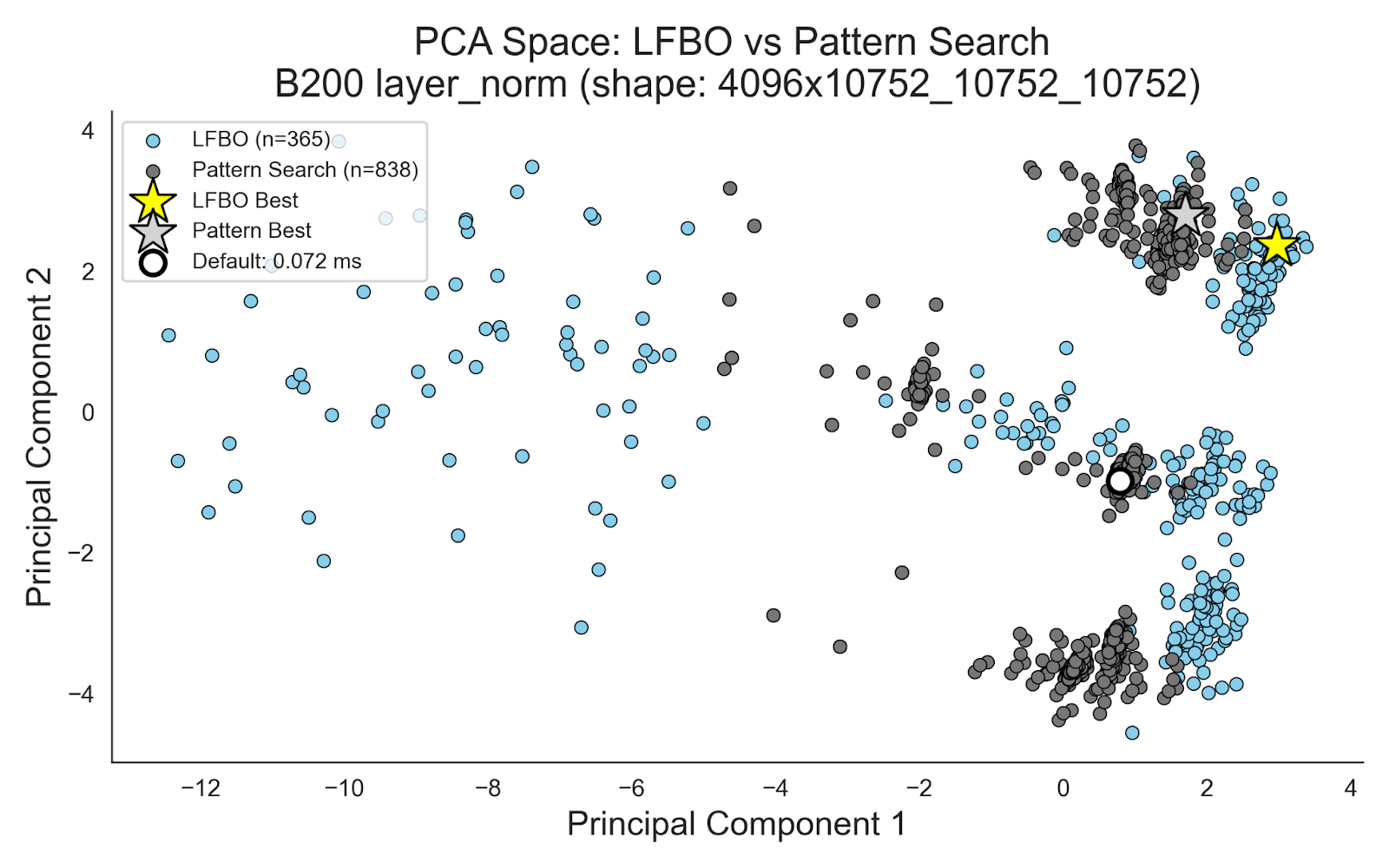
 We see that LFBO accomplishes this by exploring more widely than Pattern Search. Below is a plot of configs sampled by LFBO Pattern Search and Pattern Search for the same B200 layer-norm kernel, where we apply Principal Component Analysis (PCA) for visualization (as configs are high-dimensional). We see that while LFBO Pattern Search evaluates less than half of the number of configs , its sampled configs are more spread out than Pattern Search’s which are highly clumped together due to Pattern Search making only single parameter perturbations. Guided by the classifier, the LFBO Pattern Search is able to make larger, but more targeted jumps.
We see that LFBO accomplishes this by exploring more widely than Pattern Search. Below is a plot of configs sampled by LFBO Pattern Search and Pattern Search for the same B200 layer-norm kernel, where we apply Principal Component Analysis (PCA) for visualization (as configs are high-dimensional). We see that while LFBO Pattern Search evaluates less than half of the number of configs , its sampled configs are more spread out than Pattern Search’s which are highly clumped together due to Pattern Search making only single parameter perturbations. Guided by the classifier, the LFBO Pattern Search is able to make larger, but more targeted jumps.
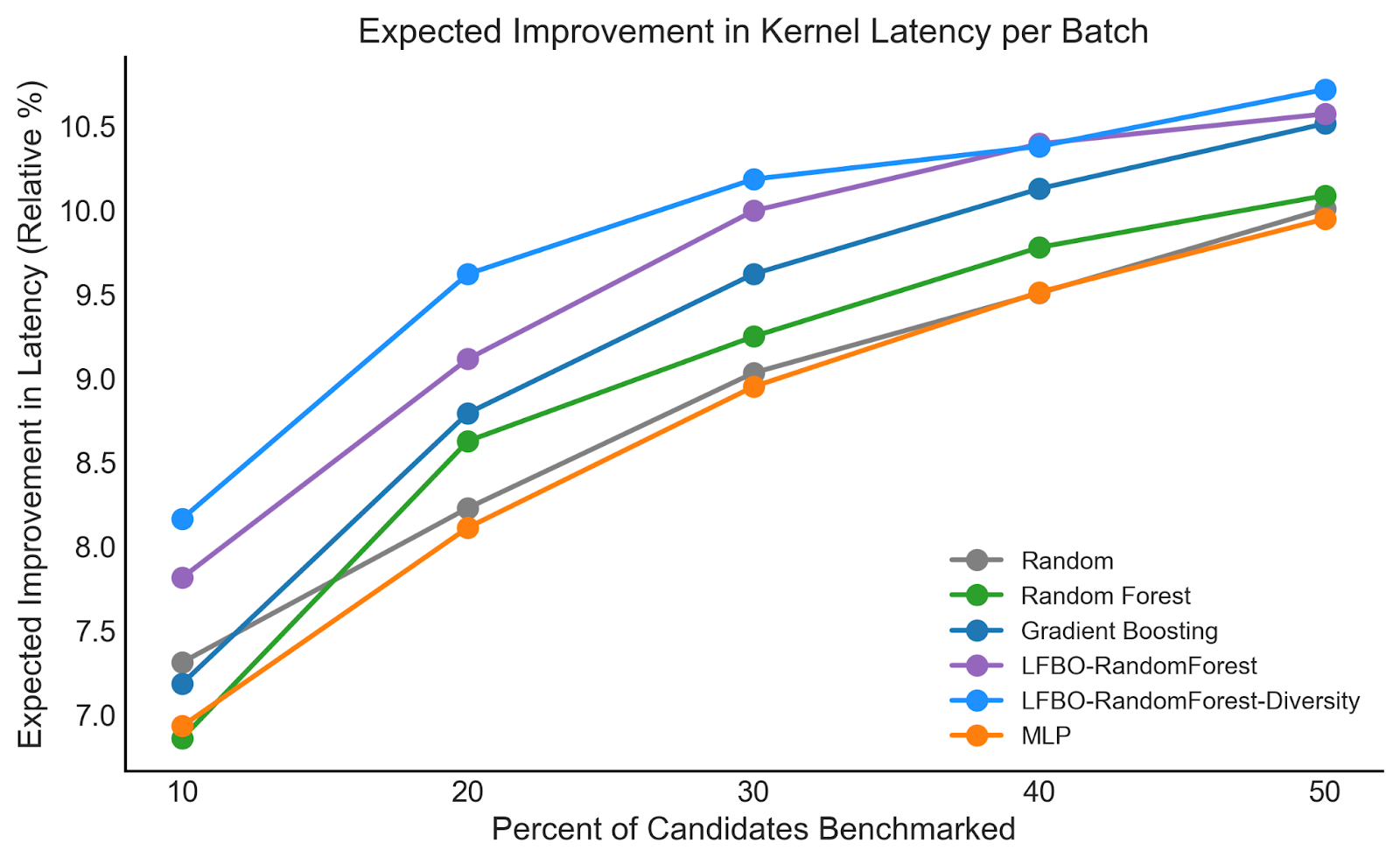
Finally, we perform an ablation with other surrogate models, in particular regression-based approaches involving a Random Forest, Gradient-Boosting Tree, and Multi-Layer Perceptron (MLP), using a dataset of autotuner logs (collected from PatternSearch). We compute a metric that is most directly correlated with autotuner performance: the expected improvement in kernel latency when using the surrogate to filter the next batch of candidates. Below we plot the expected improvement (in terms of relative % improvements in latency) compared to the percent of candidates the surrogate is allowed to select. We find that the LFBO-based methods deliver the largest expected improvement, with meaningful improvements from diverse selection. Notably, when we only can select 10% of candidates, the regression-based methods perform equivalent or even worse than simple random selection, as regression is not always aligned with ranking performance.
Conclusion
In this blog post, we illustrate how machine learning (ML) can accelerate the autotuning engine and improve the kernel authoring experience in Helion. By using the latency data collected during the search process, we can focus the autotuner on more promising configurations, saving time and discovering faster kernel configs. We are actively interested in applying additional ML techniques to enhance the auto-tuner, including methods from reinforcement learning (RL) and large language models (LLMs), and welcome any contributions.