torchaudio.functional.resample
- torchaudio.functional.resample(waveform: Tensor, orig_freq: int, new_freq: int, lowpass_filter_width: int = 6, rolloff: float = 0.99, resampling_method: str = 'sinc_interp_hann', beta: Optional[float] = None) Tensor[source]
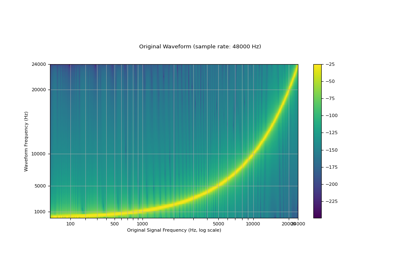
Resamples the waveform at the new frequency using bandlimited interpolation. [Smith, 2020].


Note
transforms.Resampleprecomputes and reuses the resampling kernel, so using it will result in more efficient computation if resampling multiple waveforms with the same resampling parameters.- Parameters:
waveform (Tensor) – The input signal of dimension (…, time)
orig_freq (int) – The original frequency of the signal
new_freq (int) – The desired frequency
lowpass_filter_width (int, optional) – Controls the sharpness of the filter, more == sharper but less efficient. (Default:
6)rolloff (float, optional) – The roll-off frequency of the filter, as a fraction of the Nyquist. Lower values reduce anti-aliasing, but also reduce some of the highest frequencies. (Default:
0.99)resampling_method (str, optional) – The resampling method to use. Options: [
"sinc_interp_hann","sinc_interp_kaiser"] (Default:"sinc_interp_hann")beta (float or None, optional) – The shape parameter used for kaiser window.
- Returns:
The waveform at the new frequency of dimension (…, time).
- Return type:
Tensor
- Tutorials using
resample: 
Torchaudio-Squim: Non-intrusive Speech Assessment in TorchAudio
Torchaudio-Squim: Non-intrusive Speech Assessment in TorchAudio