


Note
Click here to download the full example code
Forced alignment for multilingual data
Authors: Xiaohui Zhang, Moto Hira.
This tutorial shows how to align transcript to speech for non-English languages.
The process of aligning non-English (normalized) transcript is identical to aligning
English (normalized) transcript, and the process for English is covered in detail in
CTC forced alignment tutorial.
In this tutorial, we use TorchAudio’s high-level API,
torchaudio.pipelines.Wav2Vec2FABundle, which packages the pre-trained
model, tokenizer and aligner, to perform the forced alignment with less code.
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.6.0
2.6.0
cuda
from typing import List
import IPython
import matplotlib.pyplot as plt
Creating the pipeline
First, we instantiate the model and pre/post-processing pipelines.
The following diagram illustrates the process of alignment.

The waveform is passed to an acoustic model, which produces the sequence of probability distribution of tokens. The transcript is passed to tokenizer, which converts the transcript to sequence of tokens. Aligner takes the results from the acoustic model and the tokenizer and generate timestamps for each token.
Note
This process expects that the input transcript is already normalized. The process of normalization, which involves romanization of non-English languages, is language-dependent, so it is not covered in this tutorial, but we will breifly look into it.
The acoustic model and the tokenizer must use the same set of tokens.
To facilitate the creation of matching processors,
Wav2Vec2FABundle associates a
pre-trained accoustic model and a tokenizer.
torchaudio.pipelines.MMS_FA is one of such instance.
The following code instantiates a pre-trained acoustic model, a tokenizer which uses the same set of tokens as the model, and an aligner.
Note
The model instantiated by MMS_FA’s
get_model()
method by default includes the feature dimension for <star> token.
You can disable this by passing with_star=False.
The acoustic model of MMS_FA was
created and open-sourced as part of the research project,
Scaling Speech Technology to 1,000+ Languages.
It was trained with 23,000 hours of audio from 1100+ languages.
The tokenizer simply maps the normalized characters to integers. You can check the mapping as follow;
print(bundle.get_dict())
{'-': 0, 'a': 1, 'i': 2, 'e': 3, 'n': 4, 'o': 5, 'u': 6, 't': 7, 's': 8, 'r': 9, 'm': 10, 'k': 11, 'l': 12, 'd': 13, 'g': 14, 'h': 15, 'y': 16, 'b': 17, 'p': 18, 'w': 19, 'c': 20, 'v': 21, 'j': 22, 'z': 23, 'f': 24, "'": 25, 'q': 26, 'x': 27, '*': 28}
The aligner internally uses torchaudio.functional.forced_align()
and torchaudio.functional.merge_tokens() to infer the time
stamps of the input tokens.
The detail of the underlying mechanism is covered in CTC forced alignment API tutorial, so please refer to it.
We define a utility function that performs the forced alignment with the above model, the tokenizer and the aligner.
def compute_alignments(waveform: torch.Tensor, transcript: List[str]):
with torch.inference_mode():
emission, _ = model(waveform.to(device))
token_spans = aligner(emission[0], tokenizer(transcript))
return emission, token_spans
We also define utility functions for plotting the result and previewing the audio segments.
# Compute average score weighted by the span length
def _score(spans):
return sum(s.score * len(s) for s in spans) / sum(len(s) for s in spans)
def plot_alignments(waveform, token_spans, emission, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / emission.size(1) / sample_rate
fig, axes = plt.subplots(2, 1)
axes[0].imshow(emission[0].detach().cpu().T, aspect="auto")
axes[0].set_title("Emission")
axes[0].set_xticks([])
axes[1].specgram(waveform[0], Fs=sample_rate)
for t_spans, chars in zip(token_spans, transcript):
t0, t1 = t_spans[0].start, t_spans[-1].end
axes[0].axvspan(t0 - 0.5, t1 - 0.5, facecolor="None", hatch="/", edgecolor="white")
axes[1].axvspan(ratio * t0, ratio * t1, facecolor="None", hatch="/", edgecolor="white")
axes[1].annotate(f"{_score(t_spans):.2f}", (ratio * t0, sample_rate * 0.51), annotation_clip=False)
for span, char in zip(t_spans, chars):
t0 = span.start * ratio
axes[1].annotate(char, (t0, sample_rate * 0.55), annotation_clip=False)
axes[1].set_xlabel("time [second]")
fig.tight_layout()
def preview_word(waveform, spans, num_frames, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / num_frames
x0 = int(ratio * spans[0].start)
x1 = int(ratio * spans[-1].end)
print(f"{transcript} ({_score(spans):.2f}): {x0 / sample_rate:.3f} - {x1 / sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=sample_rate)
Normalizing the transcript
The transcripts passed to the pipeline must be normalized beforehand. The exact process of normalization depends on language.
Languages that do not have explicit word boundaries (such as Chinese, Japanese and Korean) require segmentation first. There are dedicated tools for this, but let’s say we have segmented transcript.
The first step of normalization is romanization. uroman is a tool that supports many languages.
Here is a BASH commands to romanize the input text file and write
the output to another text file using uroman.
$ echo "des événements d'actualité qui se sont produits durant l'année 1882" > text.txt
$ uroman/bin/uroman.pl < text.txt > text_romanized.txt
$ cat text_romanized.txt
Cette page concerne des evenements d'actualite qui se sont produits durant l'annee 1882
The next step is to remove non-alphabets and punctuations. The following snippet normalizes the romanized transcript.
import re
def normalize_uroman(text):
text = text.lower()
text = text.replace("’", "'")
text = re.sub("([^a-z' ])", " ", text)
text = re.sub(' +', ' ', text)
return text.strip()
with open("text_romanized.txt", "r") as f:
for line in f:
text_normalized = normalize_uroman(line)
print(text_normalized)
Running the script on the above exanple produces the following.
cette page concerne des evenements d'actualite qui se sont produits durant l'annee
Note that, in this example, since “1882” was not romanized by uroman,
it was removed in the normalization step.
To avoid this, one needs to romanize numbers, but this is known to be a non-trivial task.
Aligning transcripts to speech
Now we perform the forced alignment for multiple languages.
German
text_raw = "aber seit ich bei ihnen das brot hole"
text_normalized = "aber seit ich bei ihnen das brot hole"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/10349_8674_000087.flac"
waveform, sample_rate = torchaudio.load(
url, frame_offset=int(0.5 * bundle.sample_rate), num_frames=int(2.5 * bundle.sample_rate)
)
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
tokens = tokenizer(transcript)
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
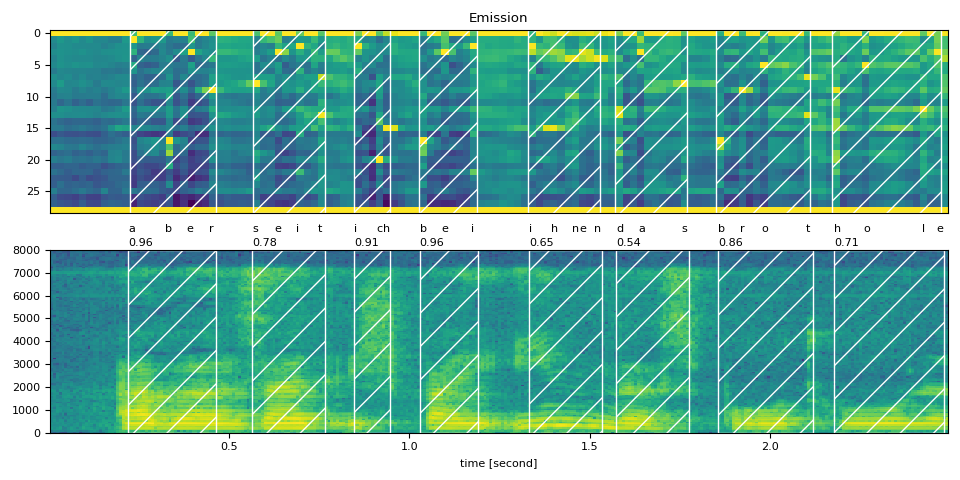
Raw Transcript: aber seit ich bei ihnen das brot hole
Normalized Transcript: aber seit ich bei ihnen das brot hole
preview_word(waveform, token_spans[0], num_frames, transcript[0])
aber (0.96): 0.222 - 0.464 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
seit (0.78): 0.565 - 0.766 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
ich (0.91): 0.847 - 0.948 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
bei (0.96): 1.028 - 1.190 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
ihnen (0.65): 1.331 - 1.532 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
das (0.54): 1.573 - 1.774 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
brot (0.86): 1.855 - 2.117 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
hole (0.71): 2.177 - 2.480 sec
Chinese
Chinese is a character-based language, and there is not explicit word-level tokenization (separated by spaces) in its raw written form. In order to obtain word level alignments, you need to first tokenize the transcripts at the word level using a word tokenizer like “Stanford Tokenizer”. However this is not needed if you only want character-level alignments.
text_raw = "关 服务 高端 产品 仍 处于 供不应求 的 局面"
text_normalized = "guan fuwu gaoduan chanpin reng chuyu gongbuyingqiu de jumian"
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
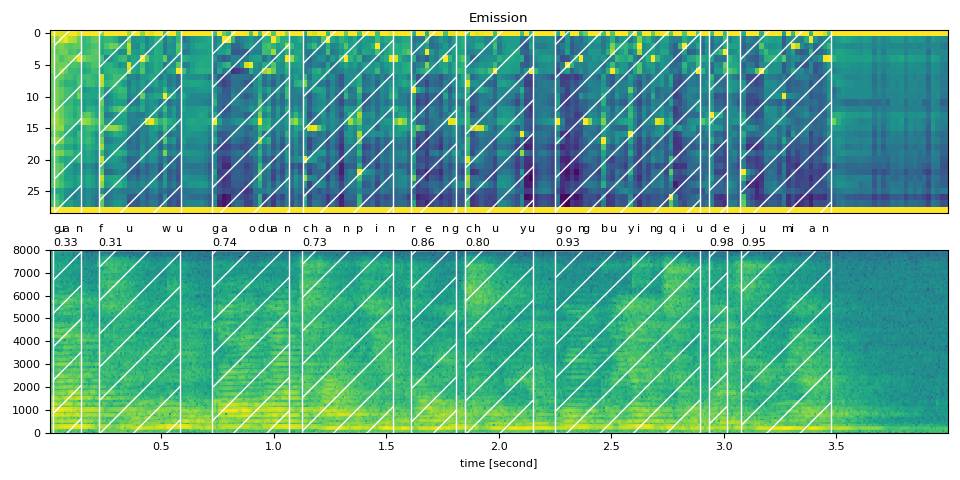
Raw Transcript: 关 服务 高端 产品 仍 处于 供不应求 的 局面
Normalized Transcript: guan fuwu gaoduan chanpin reng chuyu gongbuyingqiu de jumian
preview_word(waveform, token_spans[0], num_frames, transcript[0])
guan (0.33): 0.020 - 0.141 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
fuwu (0.31): 0.221 - 0.583 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
gaoduan (0.74): 0.724 - 1.065 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
chanpin (0.73): 1.126 - 1.528 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
reng (0.86): 1.608 - 1.809 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
chuyu (0.80): 1.849 - 2.151 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
gongbuyingqiu (0.93): 2.251 - 2.894 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
de (0.98): 2.935 - 3.015 sec
preview_word(waveform, token_spans[8], num_frames, transcript[8])
jumian (0.95): 3.075 - 3.477 sec
Polish
text_raw = "wtedy ujrzałem na jego brzuchu okrągłą czarną ranę"
text_normalized = "wtedy ujrzalem na jego brzuchu okragla czarna rane"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/5090_1447_000088.flac"
waveform, sample_rate = torchaudio.load(url, num_frames=int(4.5 * bundle.sample_rate))
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
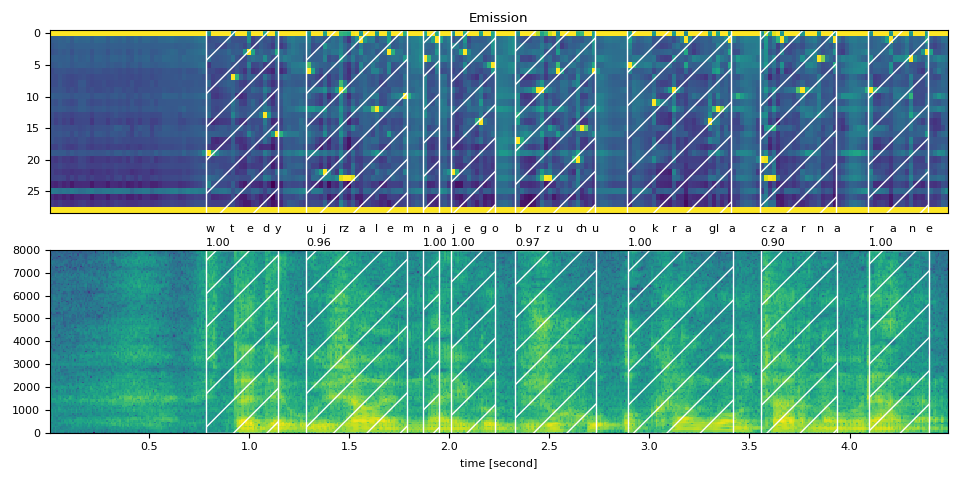
Raw Transcript: wtedy ujrzałem na jego brzuchu okrągłą czarną ranę
Normalized Transcript: wtedy ujrzalem na jego brzuchu okragla czarna rane
preview_word(waveform, token_spans[0], num_frames, transcript[0])
wtedy (1.00): 0.783 - 1.145 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
ujrzalem (0.96): 1.286 - 1.788 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
na (1.00): 1.868 - 1.949 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
jego (1.00): 2.009 - 2.230 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
brzuchu (0.97): 2.330 - 2.732 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
okragla (1.00): 2.893 - 3.415 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
czarna (0.90): 3.556 - 3.938 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
rane (1.00): 4.098 - 4.399 sec
Portuguese
text_raw = "na imensa extensão onde se esconde o inconsciente imortal"
text_normalized = "na imensa extensao onde se esconde o inconsciente imortal"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/6566_5323_000027.flac"
waveform, sample_rate = torchaudio.load(
url, frame_offset=int(bundle.sample_rate), num_frames=int(4.6 * bundle.sample_rate)
)
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
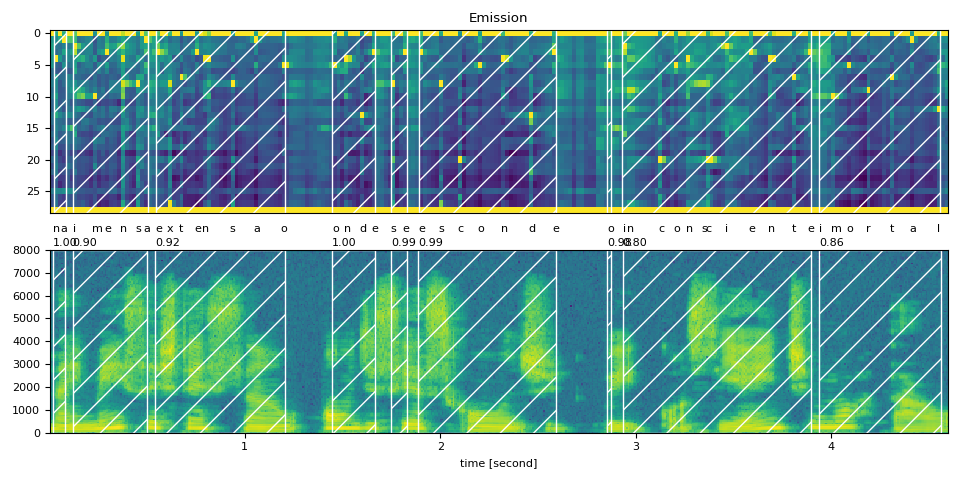
Raw Transcript: na imensa extensão onde se esconde o inconsciente imortal
Normalized Transcript: na imensa extensao onde se esconde o inconsciente imortal
preview_word(waveform, token_spans[0], num_frames, transcript[0])
na (1.00): 0.020 - 0.080 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
imensa (0.90): 0.120 - 0.502 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
extensao (0.92): 0.542 - 1.205 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
onde (1.00): 1.446 - 1.667 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
se (0.99): 1.748 - 1.828 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
esconde (0.99): 1.888 - 2.591 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
o (0.98): 2.852 - 2.872 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
inconsciente (0.80): 2.933 - 3.897 sec
preview_word(waveform, token_spans[8], num_frames, transcript[8])
imortal (0.86): 3.937 - 4.560 sec
Italian
text_raw = "elle giacean per terra tutte quante"
text_normalized = "elle giacean per terra tutte quante"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/642_529_000025.flac"
waveform, sample_rate = torchaudio.load(url, num_frames=int(4 * bundle.sample_rate))
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
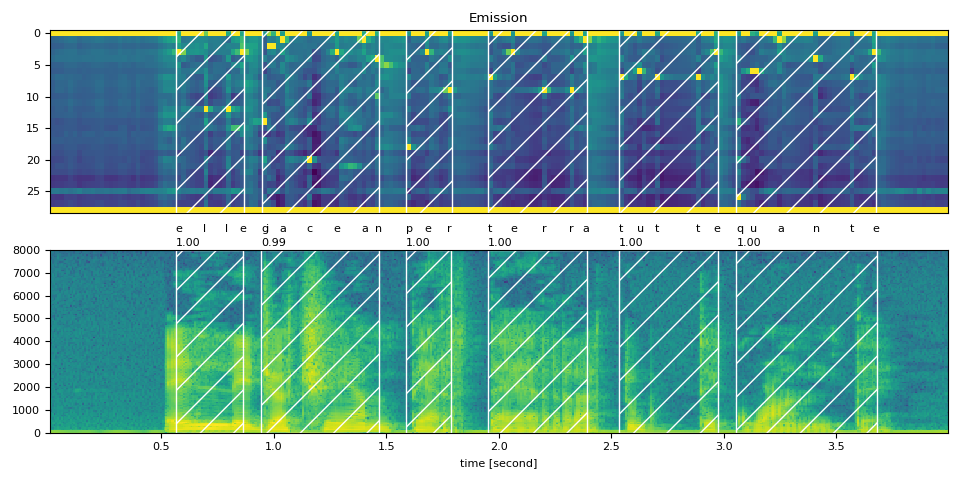
Raw Transcript: elle giacean per terra tutte quante
Normalized Transcript: elle giacean per terra tutte quante
preview_word(waveform, token_spans[0], num_frames, transcript[0])
elle (1.00): 0.563 - 0.864 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
giacean (0.99): 0.945 - 1.467 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
per (1.00): 1.588 - 1.789 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
terra (1.00): 1.950 - 2.392 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
tutte (1.00): 2.533 - 2.975 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
quante (1.00): 3.055 - 3.678 sec
Conclusion
In this tutorial, we looked at how to use torchaudio’s forced alignment API and a Wav2Vec2 pre-trained mulilingual acoustic model to align speech data to transcripts in five languages.
Acknowledgement
Thanks to Vineel Pratap and Zhaoheng Ni for developing and open-sourcing the forced aligner API.
Total running time of the script: ( 0 minutes 4.835 seconds)
