Featured projects
TL;DR:
- Traditional RecSys inference explicitly replicates shared user embeddings/sequences for every candidate. In-Kernel Broadcast Optimization (IKBO) eliminates this overhead via a kernel-model-system co-design that fuses broadcast logic directly into user-candidate interaction kernels. By decreasing both the memory footprint and IO utilization, IKBO unlocks even higher throughput.
- IKBO delivers up to a 2/3 reduction in compute-intensive net latency, serving as the scalability backbone for the request-centric, inference-efficient framework that powers the Meta Adaptive Ranking Model.
- Deployed end-to-end across Meta’s multi-stage recommendation funnel on both GPU and MTIA (Meta Training and Inference Accelerator).
- The IKBO Linear Compression kernel achieved a cumulative ~4× speedup on H100 SXM5 after four stages of progressive co-design, culminating in warp-specialized fusion via TLX.
- The IKBO co-design shifted the Flash Attention kernel from IO-bound to compute-bound (hitting 621 BF16 TFLOPs on H100 SXM5). Coupled with TLX warp-specialized optimization, this results in a 2.4x/6.4× throughput gain over the non-co-designed CuTeDSL FA4 Hopper baseline (kernel only/kernel + broadcasting).
In this post, we present In-Kernel Broadcast Optimization (IKBO), a kernel-model-system co-design approach that eliminates redundant user-embedding broadcast in recommendation model inference. In production RecSys, user embeddings are identical across all candidates for a given request, yet standard approaches require explicit replication, wasting memory bandwidth and compute that scale with candidate count. IKBO encodes a simple insight: broadcast is a data layout concern, not a computational necessity. Each IKBO kernel accepts user and candidate inputs at their natural, mismatched batch sizes and handles broadcast internally, so no replicated tensors ever materialize. We showcase the methodology through two kernel deep dives: Linear Compression and Flash Attention.
Deployed across Meta’s RecSys inference stack—from early-stage to late-stage ranking models, spanning both GPU and MTIA (Meta Training and Inference Accelerator)—IKBO delivers up to a 2/3 reduction in compute-intensive net latency on co-designed models. It serves as the scalability backbone for the request-centric, inference-efficient framework underlying the Meta Adaptive Ranking Model (serving LLM-scale models in production). On H100 SXM5, our IKBO Linear Compression kernel achieves ~4× speedup through four progressive co-design stages: matmul decomposition, memory alignment, broadcast fusion, and warp-specialized multi-stage fusion via TLX (Triton Low-Level Extensions). For Flash Attention, IKBO delivers a 2.4×/6.4× throughput compared to non-co-designed CuTeDSL FA4-Hopper (kernel only / kernel + broadcasting) with 621 BF16 TFLOPs. Unlike system-level broadcast or net-splitting that work around replication, IKBO eliminates it at the computational primitive layer, achieving dense interaction quality at near-independent cost.
Code Repository: https://github.com/pytorch/FBGEMM/tree/main/fbgemm_gpu/experimental/ikbo
† Work done while at Meta
1. In-Kernel Broadcast Optimization: Eliminating Memory and Compute Redundancy
When a user opens their feed, the recommendation system must score hundreds to thousands of candidate items to decide what to show. The model’s inputs split into two categories: user features (e.g., browsing history, profile, context) that are identical for every candidate in a request, and candidate features (e.g., item ID, category, engagement statistics) that are unique to each item. Both pass through embedding lookups and subsequent processing to produce embedding representations. At various points in the model, interaction layers (e.g., linear projections, feature crosses, target attention) combine user and candidate embeddings. We call embeddings shared across all candidates in a request Request-Only (RO), and per-candidate embeddings Non-Request-Only (NRO).
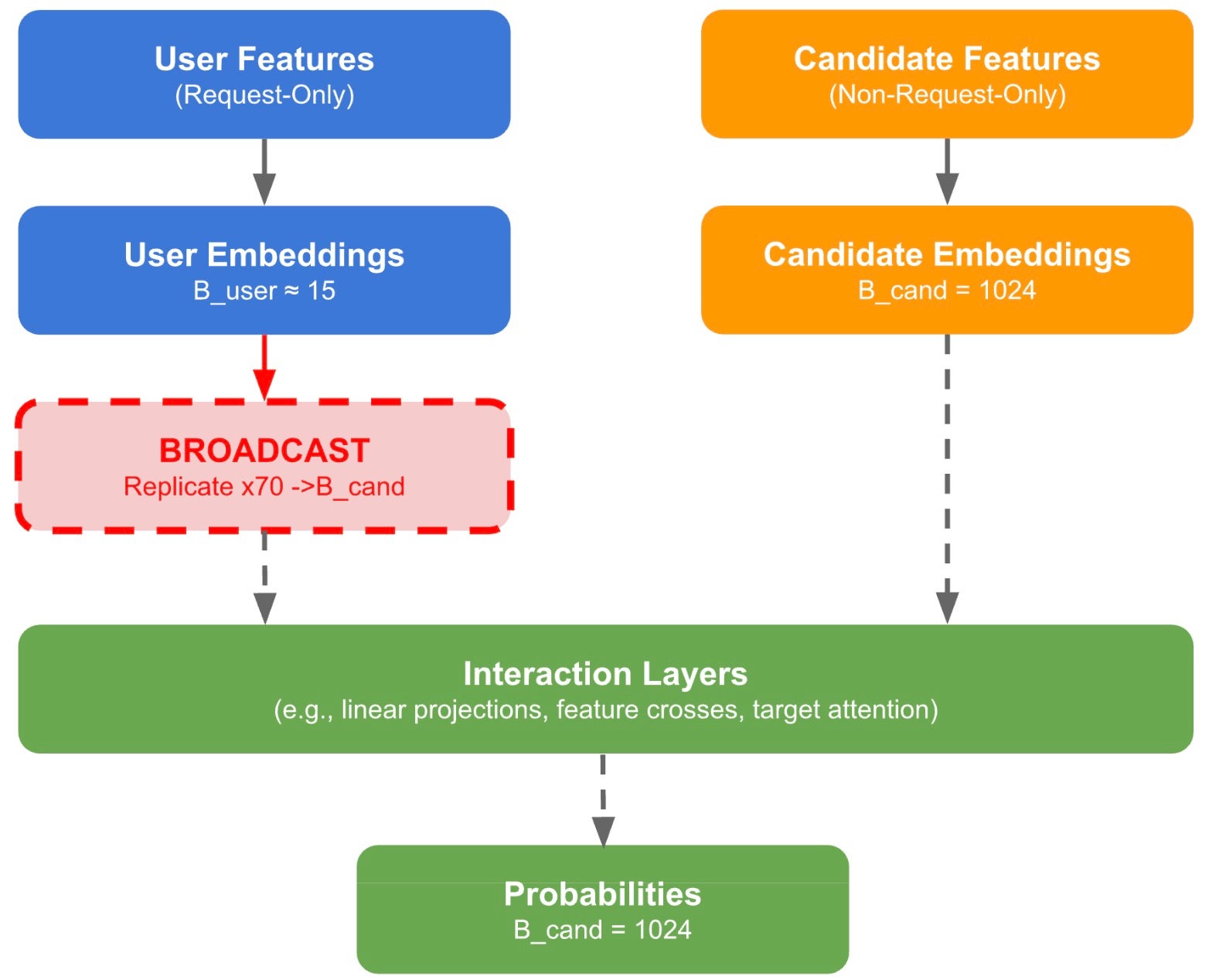
Fig. 1. A very simplified RecSys inference data flow. Request-Only (RO) user embeddings must be broadcast (replicated) to match the Non-Request-Only (NRO) candidate batch dimension before interaction layers. IKBO eliminates this materialization by handling broadcast internally within each kernel.
Interaction layers require tensors with matching batch dimensions. In a batch of 1,024 candidates served by ~15 users, RO embeddings must be broadcast, replicated ~70 times, to match the NRO batch size before any interaction (Fig. 1). As architectures have evolved from DLRM [1] and DCN [2] through sequential models like HSTU [3] and X’s Phoenix [4], they have steadily enriched user-candidate interaction. But richer interaction comes at a cost: user features must be broadcast across all candidates. For batch sizes of 10 – 10,000+ in inference, this replication overhead incurs significant computation and memory cost that scales linearly with candidate count.
Broadcast is a data layout concern, not a computational necessity. Viewing the model and inference system through this lens opens optimization at every layer: the inference runtime eliminates system-level broadcast, user-only model layers run at the smaller user batch size, and kernels that mix both are redesigned to handle broadcast internally—no replicated tensors ever materialize. Deployed across Meta’s RecSys inference stack, from early-stage to late-stage ranking models, spanning both GPU and MTIA, IKBO delivers up to 2/3 reduction in compute-intensive net latency on co-designed models.
This post focuses on the kernel layer through two deep dives: Linear Compression and Flash Attention.
1.1. Kernel Optimization Type
Type I — Decomposable Operations. Mathematical restructuring lets the Request-Only (RO) portion be computed independently at small batch size, combining with the Non-Request-Only (NRO) portion only at the end. This saves both memory bandwidth and compute.
Type II — Memory-Only Optimization. Handling RO-NRO broadcasting within the kernel avoids redundant data movement, pushing the kernel away from IO bound.
1.2. E2E System Design
Deploying IKBO touches three layers of the infra stack:
- Kernels: Custom GPU kernels that accept mismatched RO/NRO batch sizes and handle broadcast internally (Sections 2 and 3).
- Compilation Specification: The ML compiler needs per-operator dynamic shape ranges to select appropriately shaped kernels. With one batch size this is trivial; with two (user and candidate) or even more, reliably resolving which each operator uses—across production models where interactions obscure batch lineage—requires systematic automation.
- Inference: The runtime passes the candidate-to-user mapping into the model instead of materializing the broadcast.
These kernels enter the model through one of two paths:
- Direct adoption: Model authors integrate IKBO kernels directly into their model definitions. When candidate-to-user ratio > 1 during training, the same kernels reduce training cost as well.
- Inference-time transformation: A pass automatically swaps standard ops for IKBO equivalents at inference time — no model code changes required.
The net effect: broadcast disappears from every stage of inference, with no architectural constraints on the model and no infrastructure changes beyond the inference runtime’s mapping interface.
1.3. Comparison with Other Approaches
Existing approaches work around broadcast rather than eliminating it.
- System-level broadcast materializes the replicated tensor before GPU dispatch—simple but wasteful, with cost scaling linearly with candidate count.
- Net-splitting (ROO) [5] partitions the model into RO and NRO sub-networks, reducing redundant work but constraining where user-candidate interactions can occur and still introduce extra cost at small RO batch sizes.
Both preserve broadcast as a materialized tensor. IKBO eliminates it at the computational primitive layer: savings scale with the candidate-to-user ratio, any interaction pattern works without broadcast cost, and the full NRO batch dimension provides GPU occupancy within fused kernels.
IKBO has been deployed on both GPU and MTIA accelerators. In this blog post, we focus on H100 GPU kernel design to illustrate the core optimization principles.
2. Kernel Deep Dive I: IKBO Linear Compression
Linear Compress Embedding (LCE) compresses input embeddings (B, K, N) via a learned projection (M, K) @ (B, K, N) → (B, M, N), and is widely adopted in Meta RecSys models, e.g., Wukong [6]. We go through four progressive optimization stages.
2.1 Matmul Decomposition
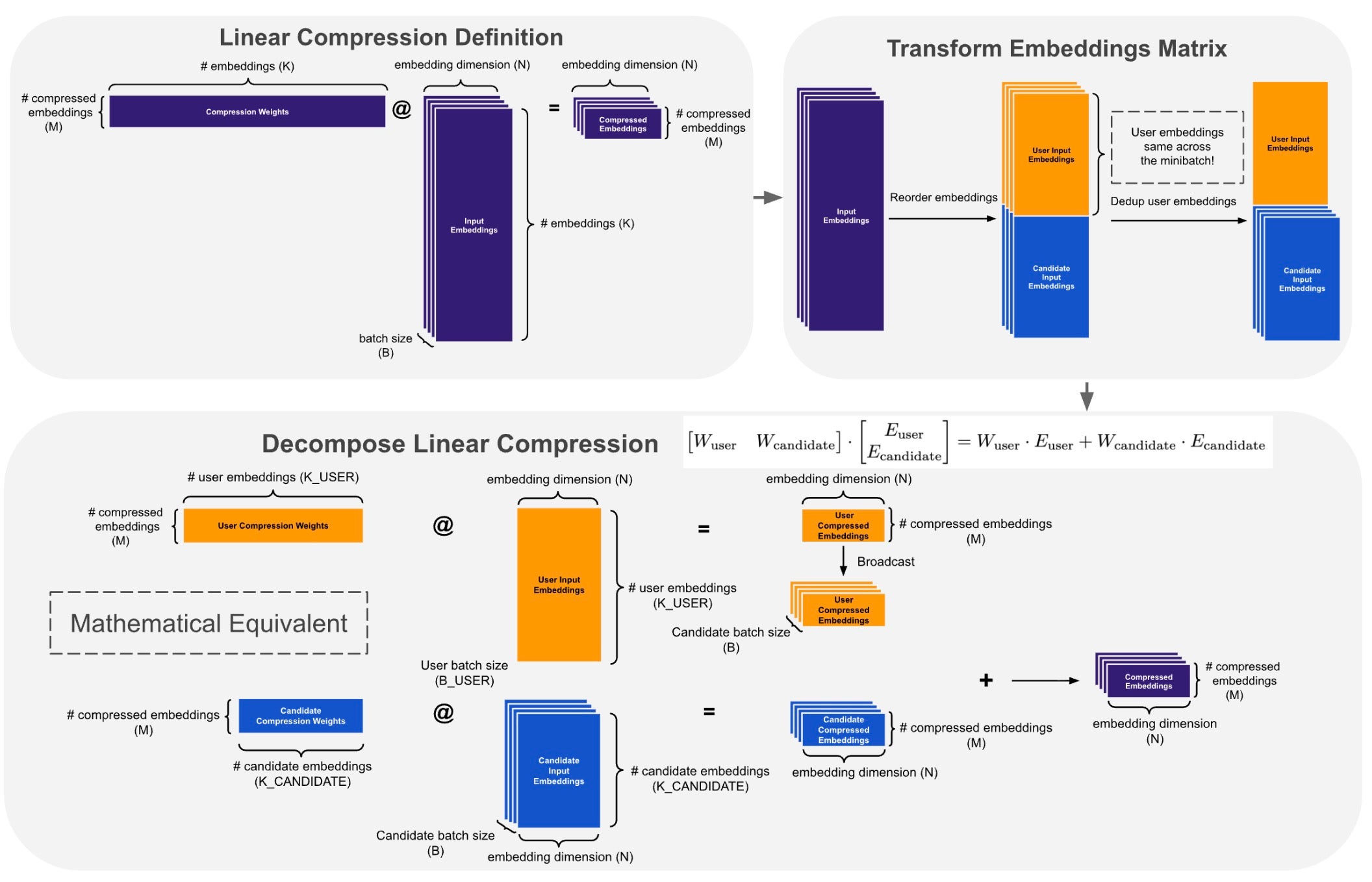
Fig. 2. LCE decomposition: baseline batched matmul (top-left), embedding separation and user deduplication along K (top-right), two independent GEMMs with broadcast-add on compressed output (bottom).
The baseline LCE computes a single batched matmul across all B candidates. The input embeddings concatenate user and candidate parts along K — but user embeddings are identical across all candidates for the same user.
Push broadcast past the matmul. Since W is batch-independent, we decompose by linearity: separate user and candidate embedding blocks along K, deduplicate the repeated user embeddings, and compute two independent GEMMs at their natural batch sizes. Instead of replicating user embeddings before the matmul, we broadcast only the small compressed result. See Fig. 2. With a candidate-to-user ratio of ~70 (a representative setting), the user batch shrinks from B=1024 to B_user ≈ 15 — a 70x reduction in user-side compute. The decomposition is implemented in standard PyTorch.
Result. 1.944 ms → 1.389 ms (28.5% reduction; benchmark setup in Appendix 1). Both the original batched GEMM (arithmetic intensity ~ 356 FLOPs/Byte, below H100’s ~495 FLOPs/Byte machine balance point; see Appendix 2 for derivations) and the two decomposed GEMMs are memory-bound, so the speedup is driven by memory cost reduction. Deduplication cuts memory cost more than half — as the user-side GEMM (B_user ≈ 15 vs. B = 1024) becomes negligible in cost.
Note that the decomposition pushes broadcast past the matmul: instead of replicating full K-dimensional input embeddings before the GEMM, we broadcast only the small compressed result, which is far cheaper. In Section 2.3, we will further eliminate this remaining broadcast entirely via in-kernel broadcast fusion.
The current bottleneck is L1/TEX pipeline utilization (84%) rather than DRAM utilization — a suspicious imbalance we will zoom into in the next section. Detailed profiling breakdown in Appendix 3.
2.2 Memory Layout Optimization
Detailed result analysis of the decomposed GEMM reveals an imbalance: L1/TEX sits at 84% of peak while DRAM reaches only 19%, indicating unnecessarily narrow memory loads. SASS confirms: every cp.async copies only 4 bytes instead of a single 128-bit load.
LDGSTS.E.LTC128B P0, [R203], [R38.64] // 4 bytes
LDGSTS.E.LTC128B P1, [R203+0x4], [R38.64+0x4] // 4 bytes (×4 total, only 16B load in total)
cp.async width is capped by the source pointer’s natural alignment. Matrix A is (M, K) row-major with stride K × 2 bytes, so when K is not a multiple of 8, the stride breaks 128-bit alignment.
Model-kernel co-design insights. Memory alignment is a well-understood GPU optimization — but decomposition turns it into a model-kernel co-design challenge. K is formed by torch.cat of embedding tensors whose sizes depend on many model config factors. Decomposition makes it very hard to manually engineer these factors so that decomposed embeddings remain perfect multiples. A systematic solution is needed.
Solution. Pad each decomposed K to the next multiple of 8 by appending zeros to the concat list. We prove this is mathematically equivalent in both forward and backward passes (see Proof 1 below), and with the ML compiler’s memory planner, reduces to a cheap constant copy.
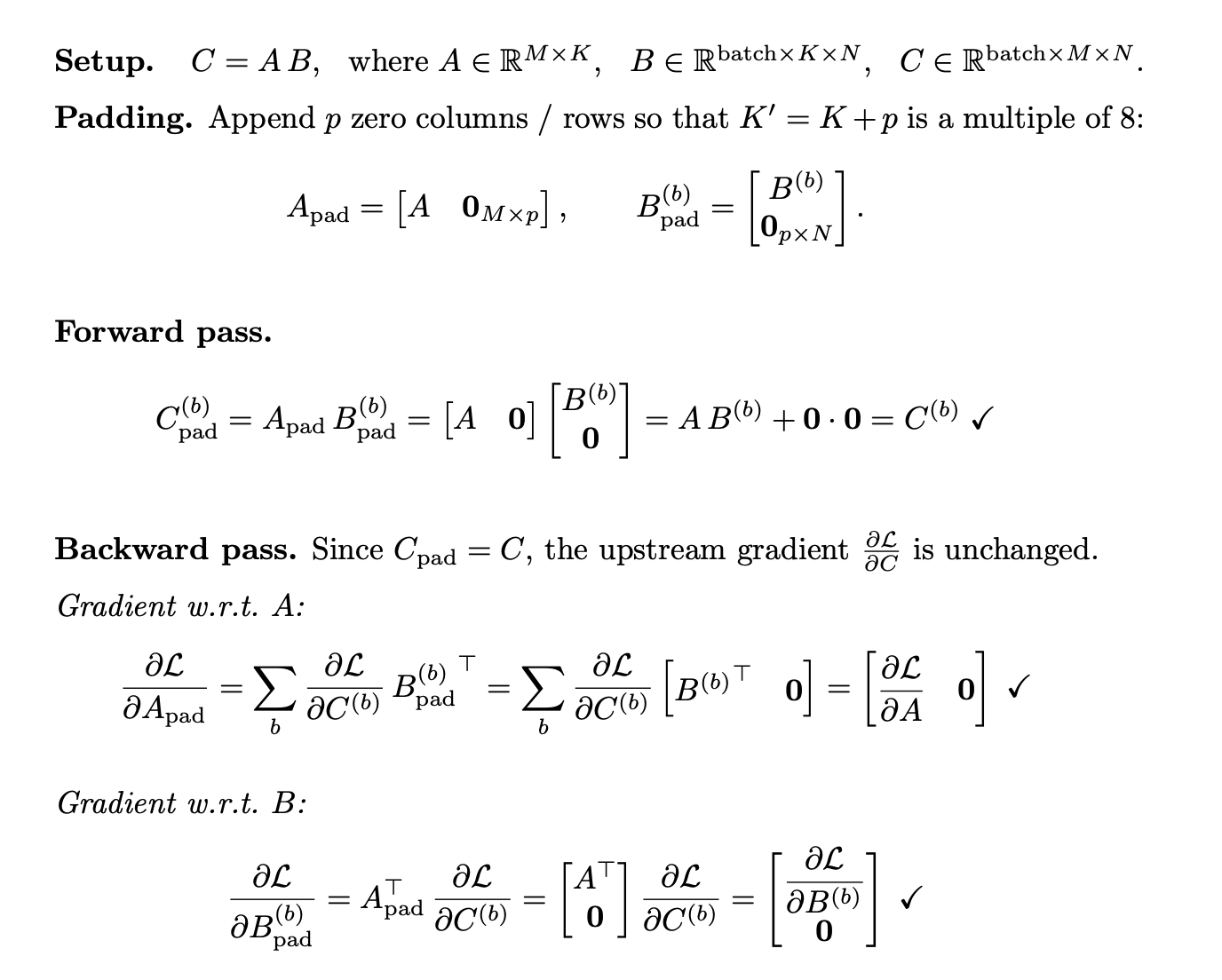 Proof 1. Zero-padding K preserves exact numerical equivalence in both forward and backward passes.
Proof 1. Zero-padding K preserves exact numerical equivalence in both forward and backward passes.
Result. 1.389 ms → 0.798 ms (42.5% reduction). Padding enables CUTLASS to select a TMA-based kernel, bypassing L1/TEX entirely (sectors 351M → 0) and cutting GEMM latency from 0.984 ms to 0.400 ms. With the GEMM resolved, the unfused broadcast and add (0.398 ms) now accounts for half the total latency — to be addressed in the next section. Detailed result analysis in Appendix 5.
2.3 Candidate GEMM In-Kernel Broadcast Fusion
The unfused broadcast and add are memory-bound: write the candidate GEMM result to HBM, read it back alongside the user result, add, and write again. We eliminate this by fusing the broadcast into the candidate GEMM epilogue (Fig. 3). After each tile’s accumulation, the epilogue looks up the user index, loads the pre-computed user result, adds it in registers, and writes the final sum — the intermediate tensor is never materialized. We implement this as a Triton kernel: a standard batched GEMM with a custom post-accumulation epilogue block.
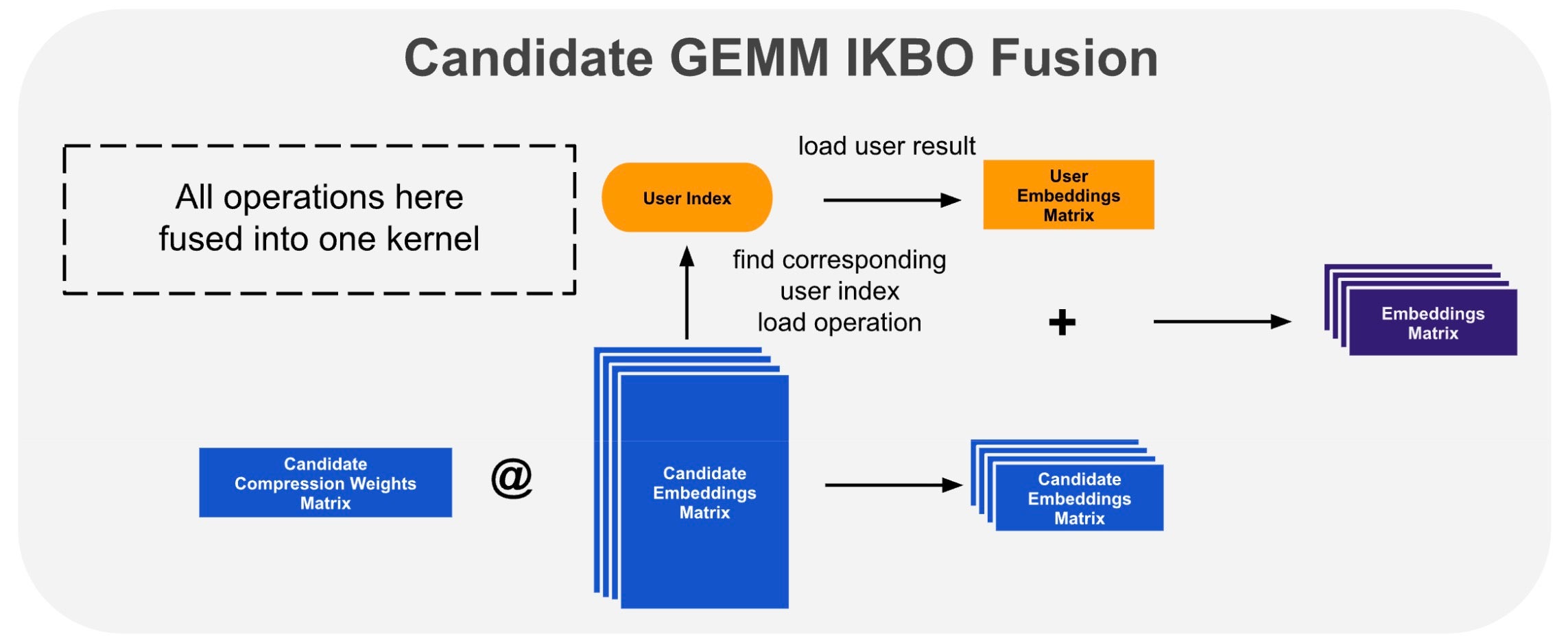
Fig. 3. In-kernel broadcast fusion: the GEMM epilogue loads the pre-computed user result via index lookup and adds it in-register.
Result. 0.798 ms → 0.580 ms (27.4% reduction). Fusion eliminates 0.87 GB of intermediate DRAM traffic, contributing to the latency win. However, occupancy is just 6.25% (1 warp per scheduler), leaving every stall fully exposed. Beyond 42% of cycles waiting on global loads, 20% are spent waiting on WGMMA — stalls that cannot be hidden by the epilogue, and without persistence there is no next-tile load to overlap with. This is a challenging tradeoff: large tiles and deep pipelines are needed to keep tensor cores fed, but they consume most of the shared memory budget, leaving little room to hide latency through occupancy. Detailed result analysis in Appendix 6.
2.4 Warp-Specialized Multi-Stage Fusion with TLX
TLX (Triton Low-level Language Extensions) exposes Hopper’s warp specialization, TMA, mbarriers, and named barriers while preserving Triton’s Python DSL and autotuning infrastructure.
Using TLX, we address the occupancy limitation from Section 2.3 with warp specialization — hiding latency through functional partitioning rather than additional warps.
Sections 2.1 – 2.3 decomposed the original LCE into two independent computations: the user GEMM (Stage 1) and the candidate GEMM with fused broadcast-add epilogue (Stage 2). We first optimize latency hiding within Stage 2, the dominant bottleneck, then fuse both stages into a single persistent kernel.
Intra-Stage Latency Overlap
The candidate IKBO kernel is memory-bound — the design goal is to keep the memory pipeline continuously fed. Triton’s software pipelining (Section 2.3) already overlaps Loads with WGMMA, but the epilogue remains serialized — it blocks future Loads and exposes the WGMMA wait stalls. We resolve both by partitioning each CTA into specialized warp groups: a dedicated producer issues TMA loads continuously (Overlap #1, analogous to Triton’s software pipeline), while two consumers ping-pong tiles so one’s epilogue overlaps the other’s WGMMA (Overlap #2). With persistence, tiles flow continuously with no cross-tile gaps. See Fig. 4.
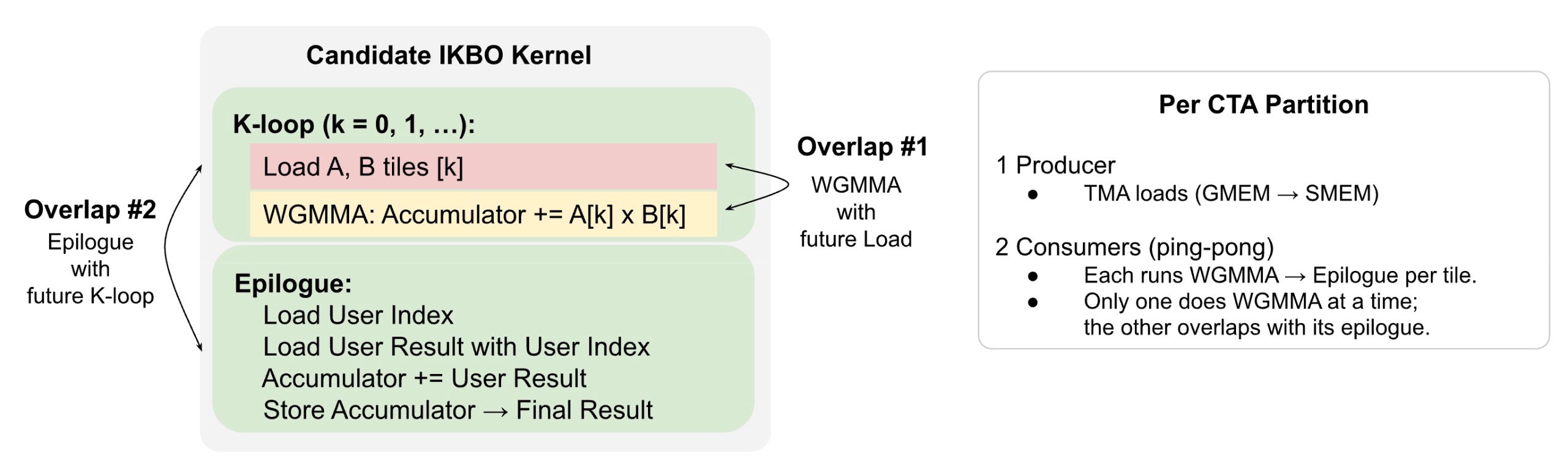
Fig. 4. Candidate IKBO kernel structure with two intra-stage latency overlaps and warp group role assignments.
Multi-Stage Fusion
We fuse user IKBO (Stage 1) and candidate IKBO (Stage 2) into a single mega-kernel to reduce wave quantization, eliminate kernel launch overhead, and improve L2 cache utilization. High candidate-to-user ratios amplify wave quantization in Stage 1. Since the candidate GEMM is independent of user results until its epilogue, we schedule both stages concurrently.
This concurrent scheduling unlocks two additional cross-stage overlaps, bringing the total overlaps to four. See Fig. 5.
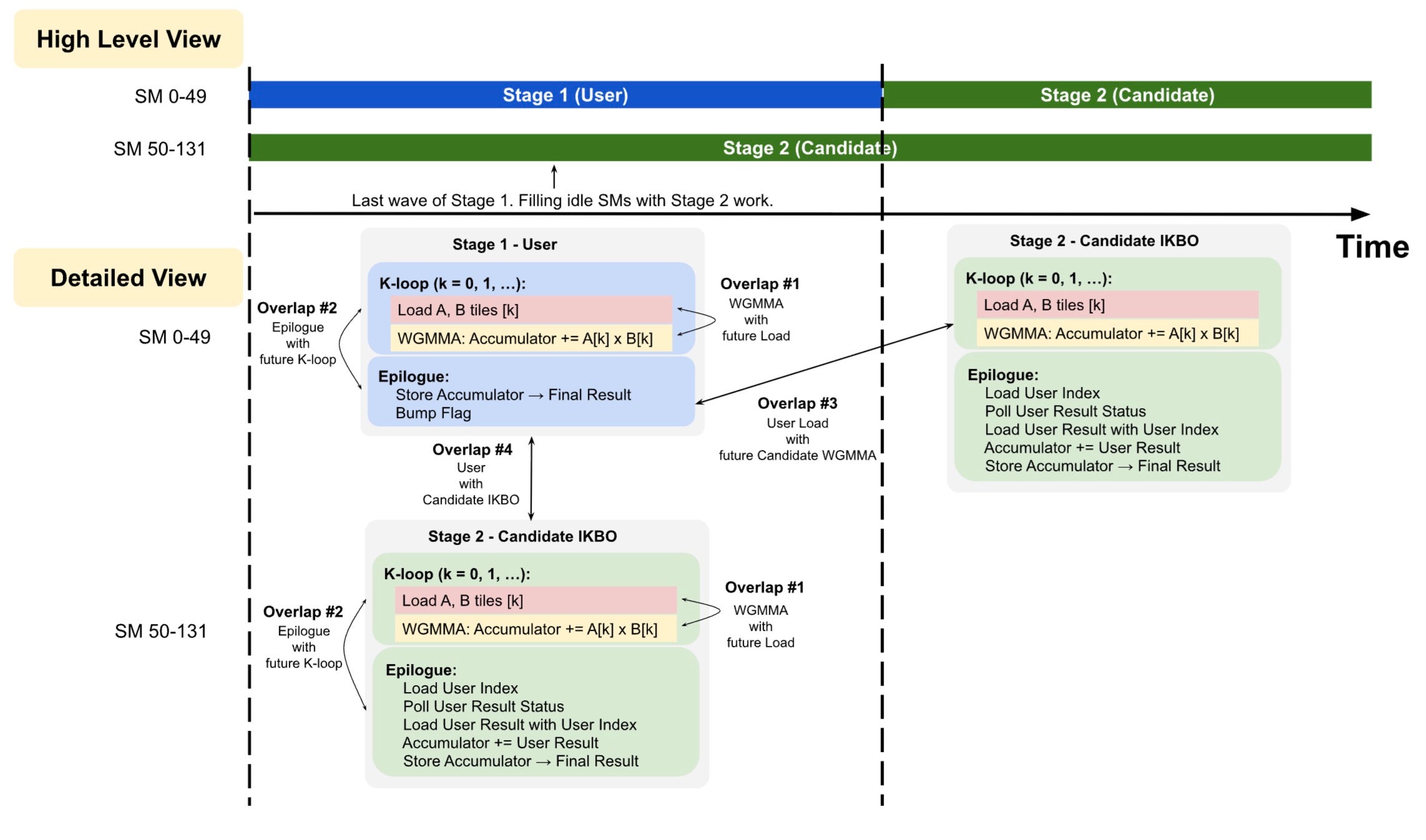
Fig. 5. Concurrent stage scheduling: SMs without user tiles enter Stage 2 immediately, overlapping with Stage 1’s partial wave. All four latency overlaps after multi-stage fusion, showing intra-stage (#1, #2) and cross-stage (#3, #4) overlap opportunities. SM 0-49, 50-131 are example numbers.
Warp Group Specialization & Synchronization Setup
To realize all four overlaps, each CTA is partitioned into one producer and two consumer warp groups. Critically, both stages share the same circular buffer and mbarrier infrastructure — no pipeline drain or barrier reinitialization occurs at the stage boundary. The last user K-block and the first candidate K-block coexist in different buffer slots simultaneously. See Fig. 6.
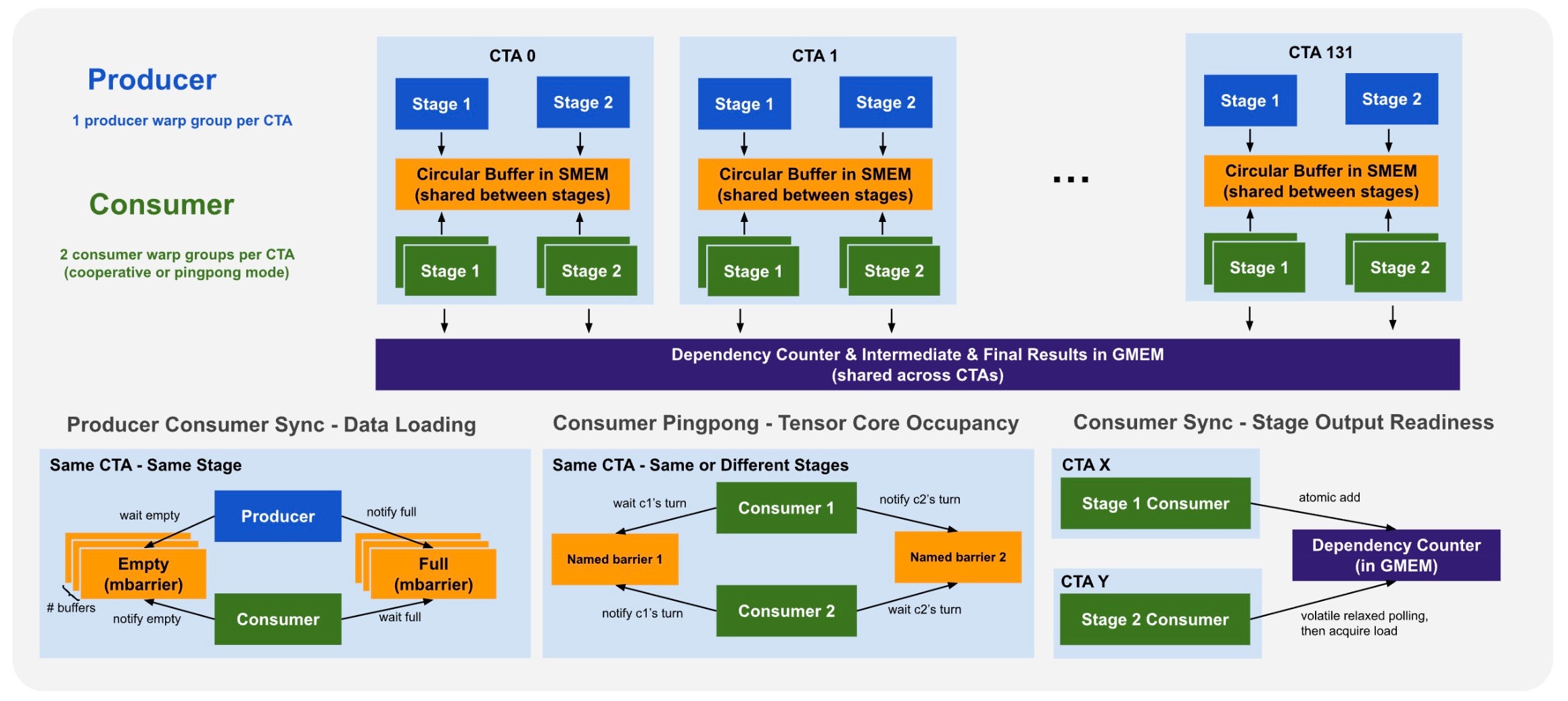
Fig. 6. Per-CTA warp group setup and the three synchronization mechanisms.
Bidirectional Stage-Alternating Tile Scheduling
When neither stage’s tile count divides evenly by the SM count, naive unidirectional dispatch causes workload imbalance. We reverse tile assignment direction between stages: Stage 1 starts at pid, Stage 2 at NUM_SM - 1 - pid. See Fig. 7.
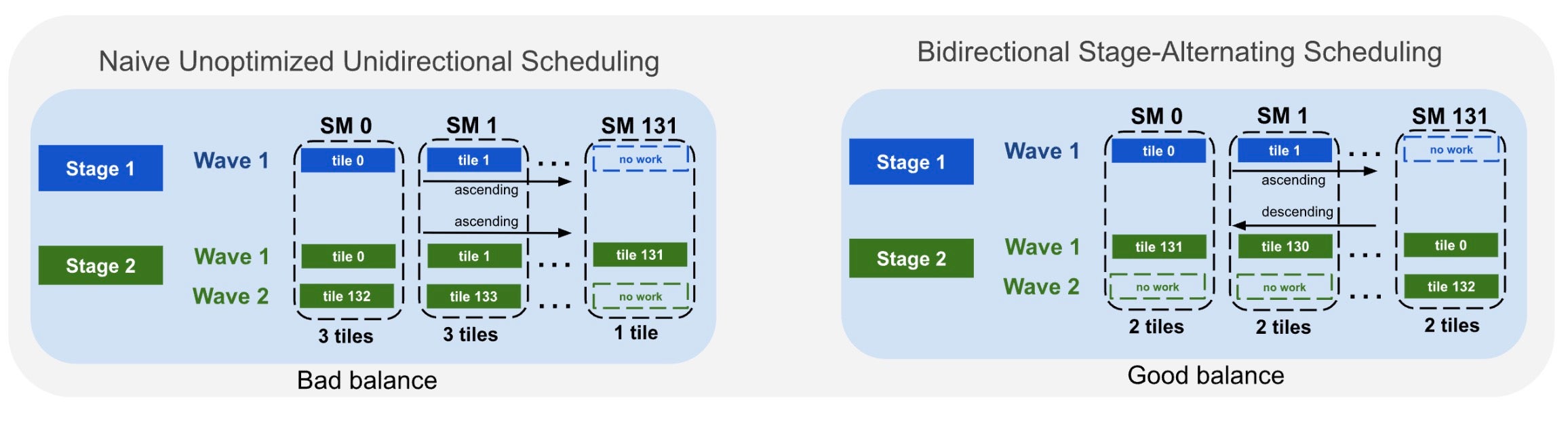
Fig. 7. Unidirectional (left) vs. bidirectional stage-alternating dispatch (right), balancing per-SM workload across partial waves.
Tile-Granularity Cross-CTA Synchronization
User and candidate tiles may execute on different CTAs, requiring cross-CTA synchronization — but a device-wide barrier would serialize all work and destroy the overlap. We synchronize at per-tile granularity using a three-step release-acquire protocol:
- A single thread per warp group spins on the tile flag with
ld.relaxed, minimizing memory traffic - Once set, a single
ld.acquireestablishes the happens-before edge - A named barrier broadcasts readiness to all 128 threads in the warp group
This avoids expensive fences during polling and lets candidate CTAs on different user tiles proceed fully independently. Details in Appendix 7.
Results
With all optimizations combined, latency improves from 0.580 ms to 0.482 ms (16.9% reduction). The clear intra-warp Proton tracer timeline confirms all four overlaps are realized in practice.
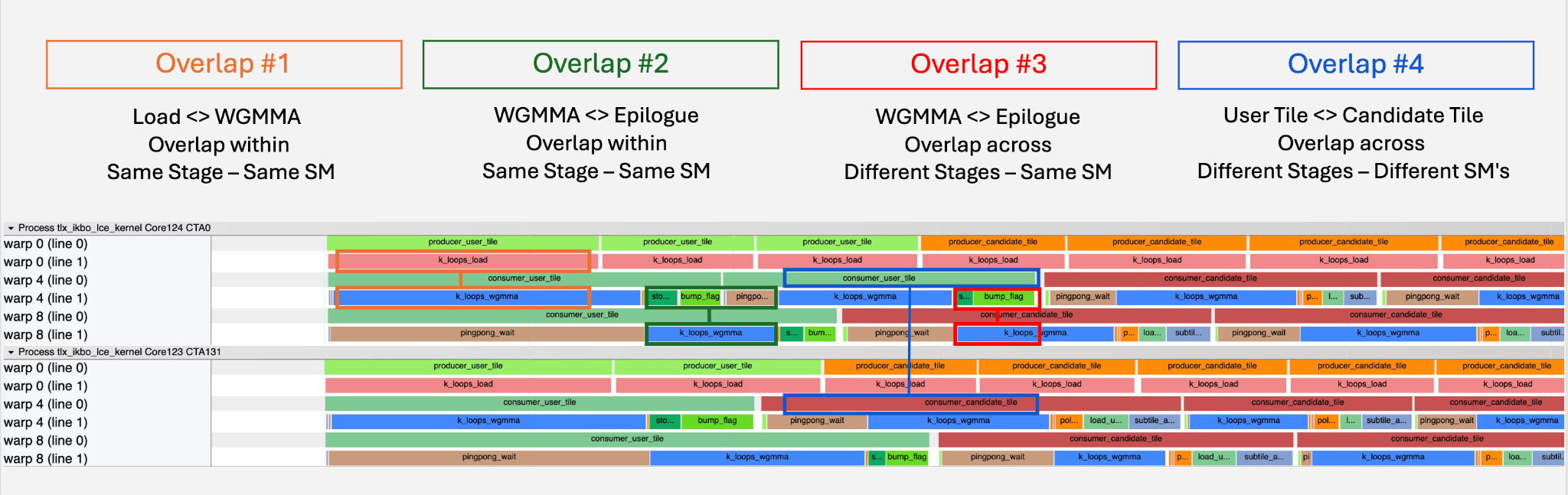 Fig. 8. Proton profiler timeline for two CTAs, with all four overlaps color-coded. The memory pipeline remains continuously fed.
Fig. 8. Proton profiler timeline for two CTAs, with all four overlaps color-coded. The memory pipeline remains continuously fed.
The primary gain comes from Overlap #2: ping-ponging consumers hide WGMMA and epilogue stalls on every tile — directly addressing the dominant wasted cycles from Section 2.3. Overlap #1 (Load↔WGMMA) carries forward from Triton’s existing software pipelining. Overlaps #3 and #4 hide idle time at the user-to-candidate stage transition. See Fig. 8.
NCU confirms: occupancy rises from 6.25% to 18.75% (3 warp groups vs. 1), DRAM throughput from 39% to 52%, and L2 — the bottleneck — from 74% to 84% of peak. This is not occupancy alone: the aggressive latency hiding across all four overlaps keeps the memory pipeline saturated, which is what pushes L2 past 80%. Detailed NCU metrics in Appendix 8.
We benchmark across batch sizes and candidate-to-user ratios, with the default (batch=1024, ratio=70) settings. See Fig. 9.
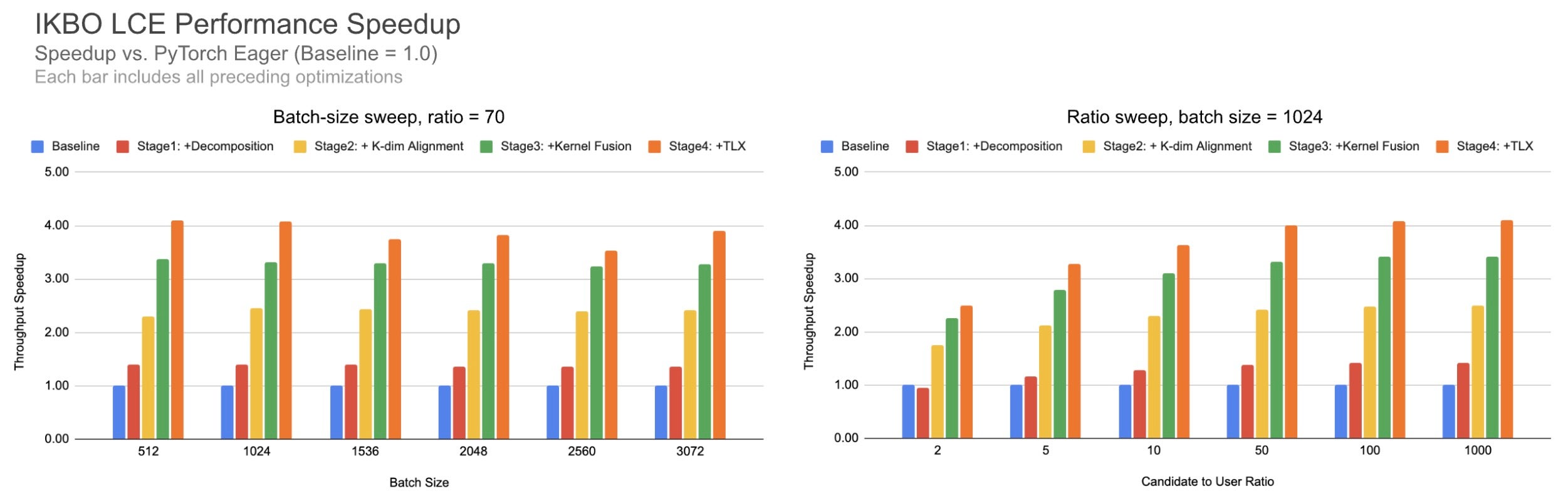
Fig. 9. Cumulative IKBO speedup across batch sizes (left, ratio=70) and candidate-to-user ratios (right, batch=1024).
The IKBO fusion delivers robust gains across scenarios: ~4x speedup across batch sizes (left) and candidate-to-user ratios (right). Even at low candidate-to-user ratios, the kernel still achieves meaningful speedup.
3. Kernel Deep Dive II: IKBO Flash Attention
As recommendation models scale to capture richer user sequential behavior, sequential architectures – including attention – have emerged as a critical compute bottleneck, accounting for approximately 40% of inference latency at 1K sequence lengths. This motivates our focus on IKBO-aware Flash Attention, co-designed with RecSys’s unique batching semantics.
Inspired by Transformers and Set Transformers [7, 8], two fundamental user history interaction modules have been widely adopted in RecSys:
- Target attention (analogous to cross-attention) captures the relationship between the prediction candidate and the user’s historical interactions.
- Self-attention models sequential dependencies within the user history itself
Since user history is a RO feature while the target operates on a distinct candidate (non-RO) batch dimension, this architectural asymmetry presents an opportunity for IKBO to improve model scalability and computational efficiency. Target attention will be our main focus for optimization, while with minor co-design, self attention could also be fused into IKBO target attention in Section. 3.3. As our model is encoder-driven, full attention is applied without causal masking.
The ultimate optimized target attention version leveraging e2e co-design achieves 2.4×/6.4× the throughput of non-co-designed CuTeDSL FA4-Hopper (attn kernel only / attn kernel + broadcasting cost), reducing latency by 0.320ms / 1.232ms respectively (Table. 2).
3.1 IKBO flash attention solves the IO bound issues under RecSys boundary conditions
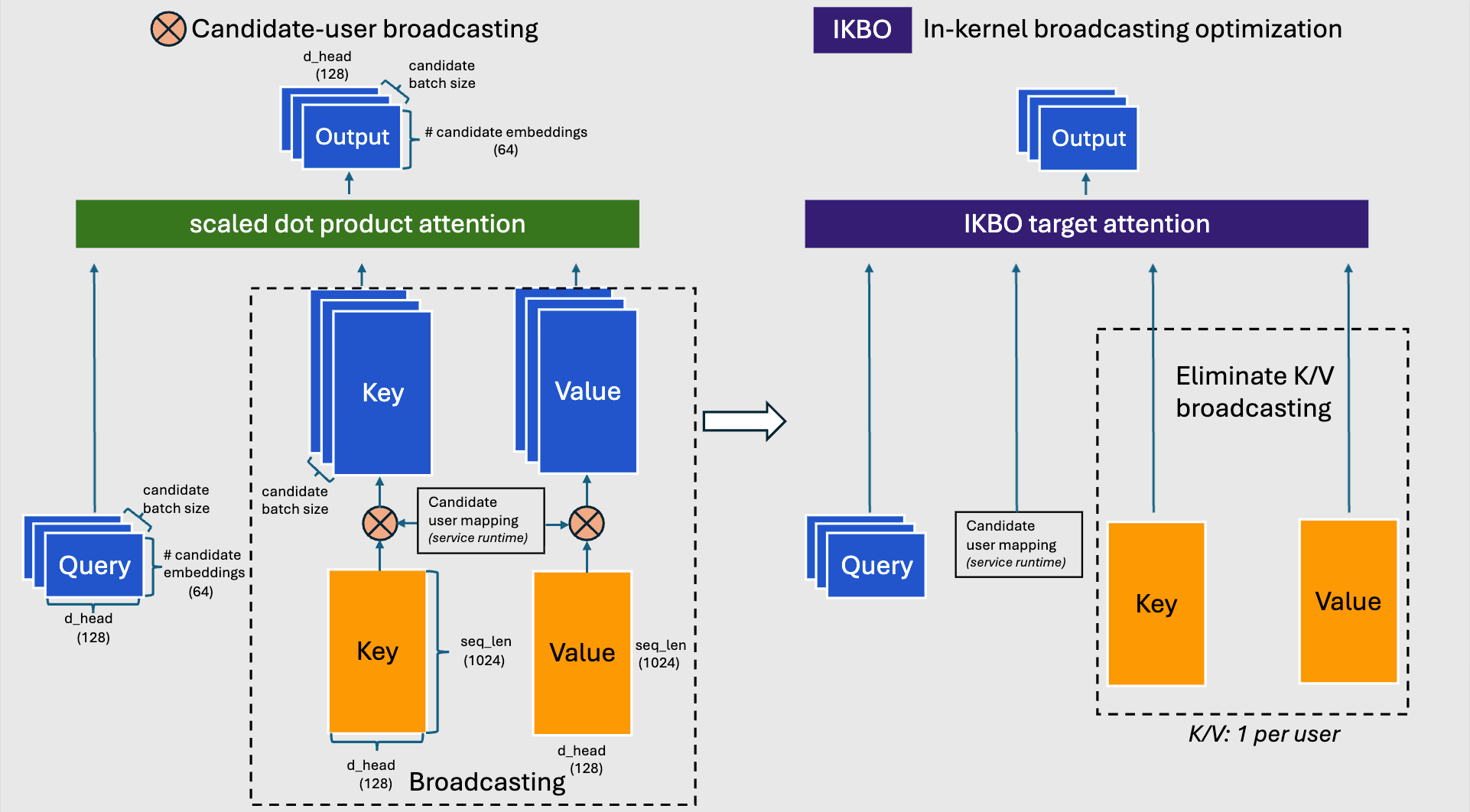 Fig. 10: Traditional SDPA with candidate-user broadcasting (left) vs. fused IKBO target attention (right).
Fig. 10: Traditional SDPA with candidate-user broadcasting (left) vs. fused IKBO target attention (right).
IKBO fuses K/V broadcasting into the attention kernel, maintaining mathematical equivalence via a candidate-user mapping tensor from the inference runtime that handles non-uniform candidate-to-user ratios. Fig. 10 contrasts the two approaches: the traditional SDPA path broadcasts K and V to the full candidate batch size before attention, while the IKBO path eliminates this materialization entirely — each candidate indexes into its user’s K/V on the fly.
Shifting IO-Bound to Compute-Bound by IKBO co-design
In RecSys boundary conditions, target attention uses a relatively small number of candidate embeddings to represent the candidate attributes compared to the user’s browsing history. Roofline analysis of standard attention reveals an arithmetic intensity of ~60 FLOPs/Byte – well below the H100 (SXM5 HBM2e version) peak of ~495 FLOPs/Byte (Appendix 2)—making even standard flash attention heavily IO-bound. IKBO addresses this by amortizing K/V memory accesses across multiple candidates sharing the same user context, improving arithmetic intensity from ~60 FLOPs/Byte to ~833 FLOPs/Byte (at B_candidate : B_user = 70:1) and shifting the kernel firmly into compute-bound territory.
To maximize this benefit, our implementation reorders the threadblock launch grid so that batch_size_candidate comes before num_heads. This ensures threadblocks processing different candidates — but sharing the same user K/V — are scheduled concurrently, improving L2 cache reuse.
| Grid dimension | Flash attention (SDPA) | IKBO target attention |
| x | num_q_seq_block | num_q_seq_block |
| y | num_heads | batch_size_candidate |
| z | batch_size_candidate | num_heads |
Table 1: Launch grid configuration comparison. SDPA prioritizes GQA optimization by placing num_heads in grid.y. IKBO swaps head and candidate dimensions, placing batch_size_candidate in grid.y to enable efficient K/V sharing across candidates.
Table 2 compares our IKBO Triton implementation (FA2 logic + IKBO) against state-of-the-art Flash Attention implementations on Hopper (without IKBO co-design). Throughput and IO are measured on attention only; the broadcasting latency for Key and Value is even larger than the attention cost itself.
| Throughput (TFLOPs/s) | IO (GB/s) | Latency (ms) | |
| Triton IKBO FA2 | 425 | 487 | 0.321 (broadcast fused) |
| TLX FA3 | 245 | 2152 | 0.561 + 0.912 (broadcast K&V) |
| CuTeDSL FA4 Hopper | 250 | 2193 | 0.550 + 0.912 (broadcast K&V) |
| TLX IKBO FA3 persistence generalized | 594 | 681 | 0.230 (broadcast fused) |
Table 2: Attention kernel comparison under RecSys boundary conditions (B_candidate = 2048, B_u = 32, uniform candidate-to-user ratio). Without co-design, even cutting-edge Hopper implementations remain IO-bound.
3.2 Adopting Modern Kernel Techniques (FA3, FA4) with IKBO on TLX
With IKBO shifting the kernel from IO-bound to compute-bound, the natural next step was to adopt the state-of-the-art compute optimizations from Flash Attention 3 (FA3 [10]) and Flash Attention 4 (FA4 [11]) on Hopper – specifically warp specialization and pipelining. However, our boundary conditions on the number of query embeddings (q_seq = 32 or 64) make it difficult to directly adopt FA3’s ping-pong or cooperative warp specialization.
Warp specialization on Hopper requires asynchronous WGMMA instructions, which impose a minimum BLOCK_M ≥ 64. Two consumer warp groups are also necessary to minimize bubbles between them. To satisfy these constraints, we customized the kernel to launch both B_candidate = i and B_candidate = i + 1 within a single threadblock, sharing the same B_user. In the discussion below, we assume all users rank an even number of candidates with q_seq = 64; odd-candidate handling follows afterward.
Performance improvement for IKBO FA3 kernel
Starting from FA3’s recipe — intra-warp pipelining, warpgroup specialization, and ping-pong scheduling — the initial TLX IKBO FA3 kernel performed similarly to the FA2 baseline (Fig. 12, blue vs. red, Appendix 11), with on-par throughput.
To diagnose the bottleneck, we visualized intra-warp pipelining using the Proton tracer with GPU cycles as the latency unit (Fig. 10). Table 3 summarizes the key bottlenecks before and after persistence, measured in GPU cycles via the Proton tracer.
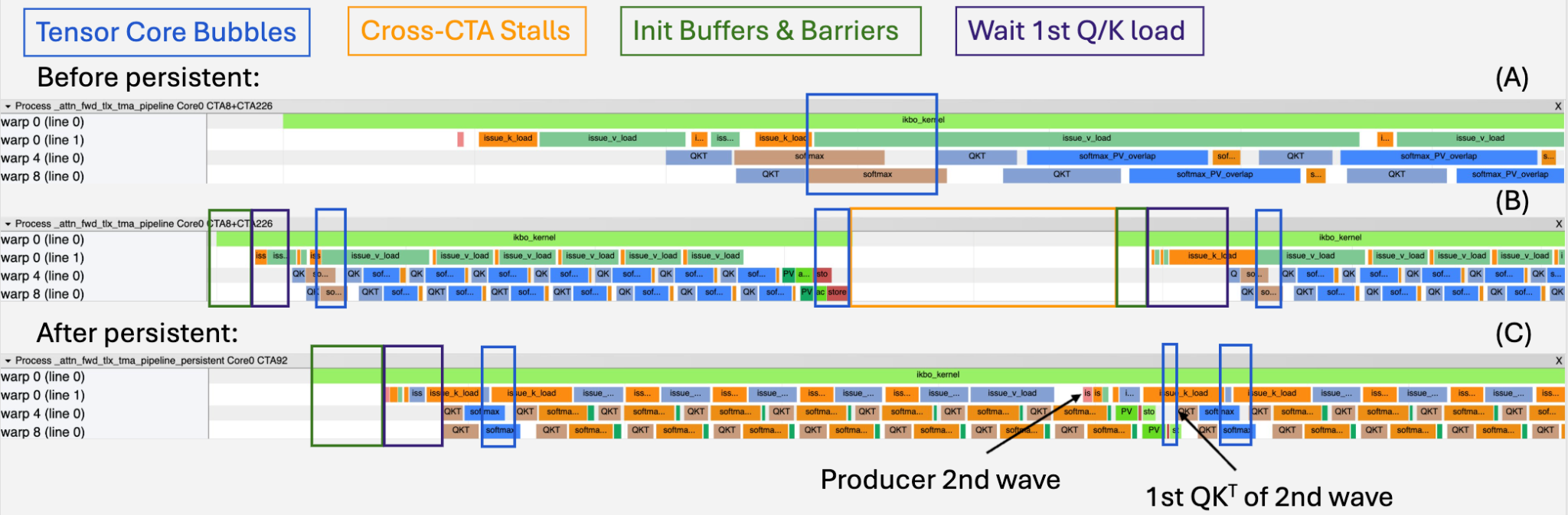 Fig. 11: Proton-based intra-warp profiling of the TLX IKBO FA3 kernel. Representative warps from each warp group are shown: warp 0 (producer), warp 4 (consumer 1), and warp 8 (consumer 2). The softmax_PV_overlap and pure softmax regions are marked separately to identify the tensor core bubbles. (A) Before persistence zoomed in view of B (B) Before persistence with 2 waves (C) After persistence with 2 waves
Fig. 11: Proton-based intra-warp profiling of the TLX IKBO FA3 kernel. Representative warps from each warp group are shown: warp 0 (producer), warp 4 (consumer 1), and warp 8 (consumer 2). The softmax_PV_overlap and pure softmax regions are marked separately to identify the tensor core bubbles. (A) Before persistence zoomed in view of B (B) Before persistence with 2 waves (C) After persistence with 2 waves
| Bottlenecks | Before | After | Key change |
| Tensor Core Bubbles (1st QKT per wave, Blue) | ~1,300 cycles (400 cycles from warp scheduler switching) | ~1,300 cycles | Unchanged |
| Tensor Core Bubbles (last PV per wave, Blue) | ~2,000 cycles | ~300 cycles | Async TMA store + reciprocal overlap with last PV |
| Cross-CTA Stalls (Orange) | ~14,000 cycles | Eliminated | Persistence removes CTA re-launch entirely |
| Init Buffers & Barriers (Green) | ~1,600 cycles/wave | ~1,600 cycles (1st wave only) | Persistence shared buffer and barrier amortized across waves |
| Wait 1st Q/K Load (Dark purple) | 2,100~4,000 cycles/wave (length varies depending on HBM bandwidth contention) | ~2,000 cycles (1st wave only) | Cross-wave pipelining; producer prefetches ~3K cycles ahead |
Table 3: Key bottlenecks before and after persistence + optimizations.
Key takeaway: cross-CTA stalls are the dominant bottleneck — not tensor core utilization – at these small query sequence lengths. Persistence is a must for this improvement. After persistence, the profiling results and its latency changes are presented in Fig. 11C and Table. 3.
HBM2e-Specific Optimizations
We further tuned the persistent kernel for the H100 SXM5’s HBM2e bandwidth constraints, trading shared memory capacity for reduced load/store blocking. (Table 4).
| Customized optimization/fix | Benefit |
| Decoupled SMEM buffer of O from Q/V with pipelined TMA async store | Decoupled O from Q/V SMEM sharing enable TMA async stores could overlap with next-wave compute, shortening store blocking time from 1,300 to 400 cycles/wave |
| Separate Q₀ and Q₁ buffers | Reduces per-Q loading time, allowing one consumer group starts earlier— beneficial when wave count greatly exceeds K/V sequence iterations (common in RecSys) |
| Instruction Cache Misses fix | Merges the peeled-out last-iteration code path back into the main loop, eliminating icache thrashing caused by excessive warp-specialized instructions (Appendix 12) |
Table 4: Customized optimizations for the HBM2e H100 SXM5. These still fit within the available SMEM budget under RecSys boundary conditions (Appendix 10).
We also implemented persistent V2, which iterates from the end of the K sequence to the front (matching FA3/FA4-Hopper’s approach) to simplify masking logic. Both persistent variants apply the Table 4 optimizations. As shown in Fig. 12, at low sequence lengths (512–4,096) the TLX FA3 persistent kernel outperforms all other candidates; beyond 8K the two persistent variants converge.
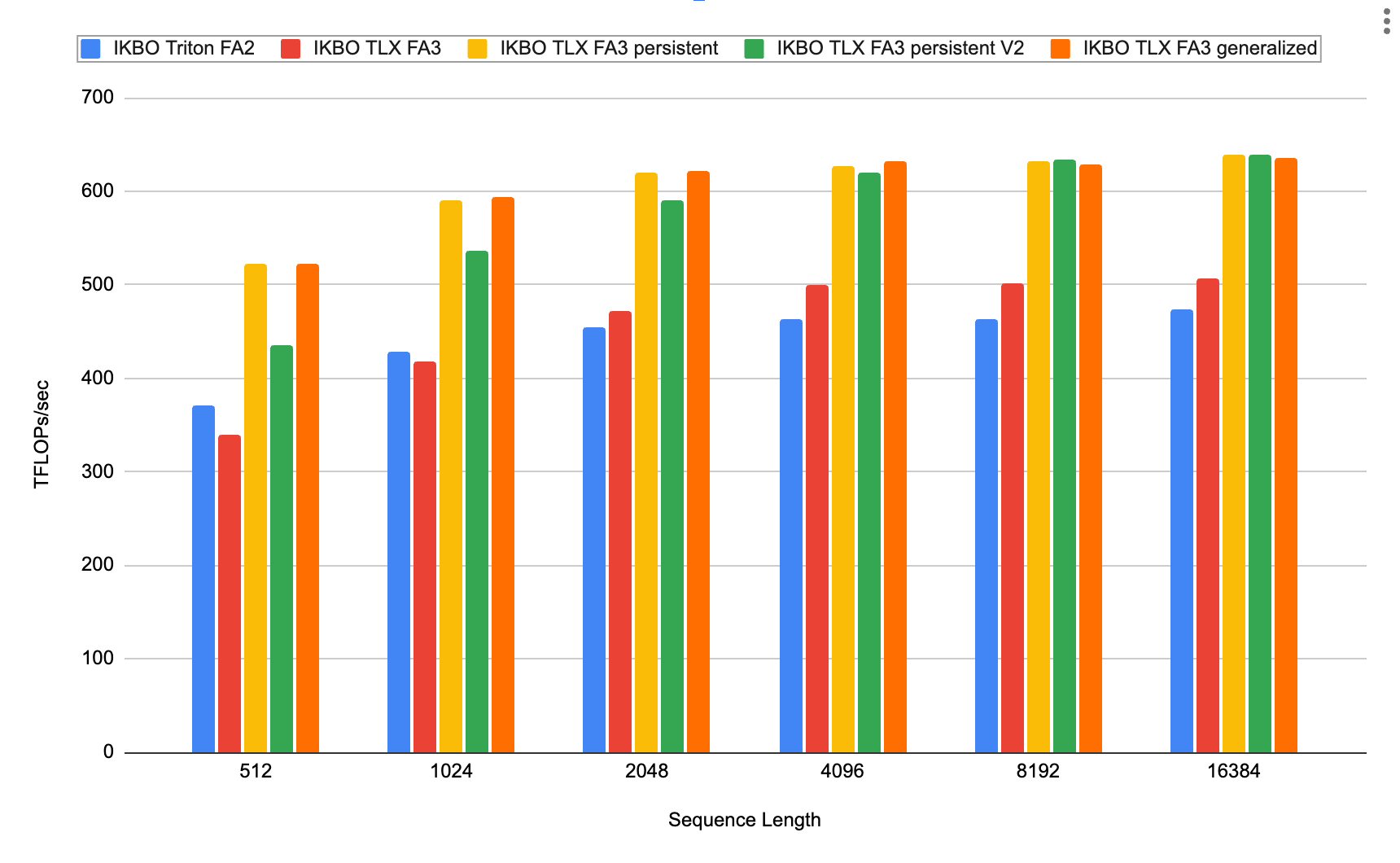 Fig. 12: IKBO implementation throughput vs. sequence length (B_candidate = 2,048; B_candidate : B_user = 64; num_head = 2; d_head = 128). Practical RecSys sequence lengths are under 4K [3]; longer lengths are included for comparison with LLM use cases. The generalized version handles non-even candidates per user with 50% odd-candidates per user probability
Fig. 12: IKBO implementation throughput vs. sequence length (B_candidate = 2,048; B_candidate : B_user = 64; num_head = 2; d_head = 128). Practical RecSys sequence lengths are under 4K [3]; longer lengths are included for comparison with LLM use cases. The generalized version handles non-even candidates per user with 50% odd-candidates per user probability
Generalizing IKBO FA3 for ranking Arbitrary Candidate Batch Sizes
Our IKBO FA3 kernel co-processes two candidate batches per CTA to meet WGMMA’s BLOCK_M ≥ 64 requirement. When a user has an odd number of candidates, one consumer warpgroup has no pairing partner. We handle this with idling logic (Fig. 13, left; Algorithm 1):
- The idle warpgroup drains K/V buffers via mbarrier signaling to prevent producer deadlock.
- The active warpgroup disables ping-pong synchronization (its partner no longer arrives at the named barriers).
At a ~70 : 1 candidate-to-user ratio, the idle path triggers less than 0.7% of the time with negligible overhead (Fig. 12, IKBO TLX FA3 generalized). This approach generalizes to q_seq_len = 32, where four candidate batches are bundled per CTA using analogous idling and masking logic.
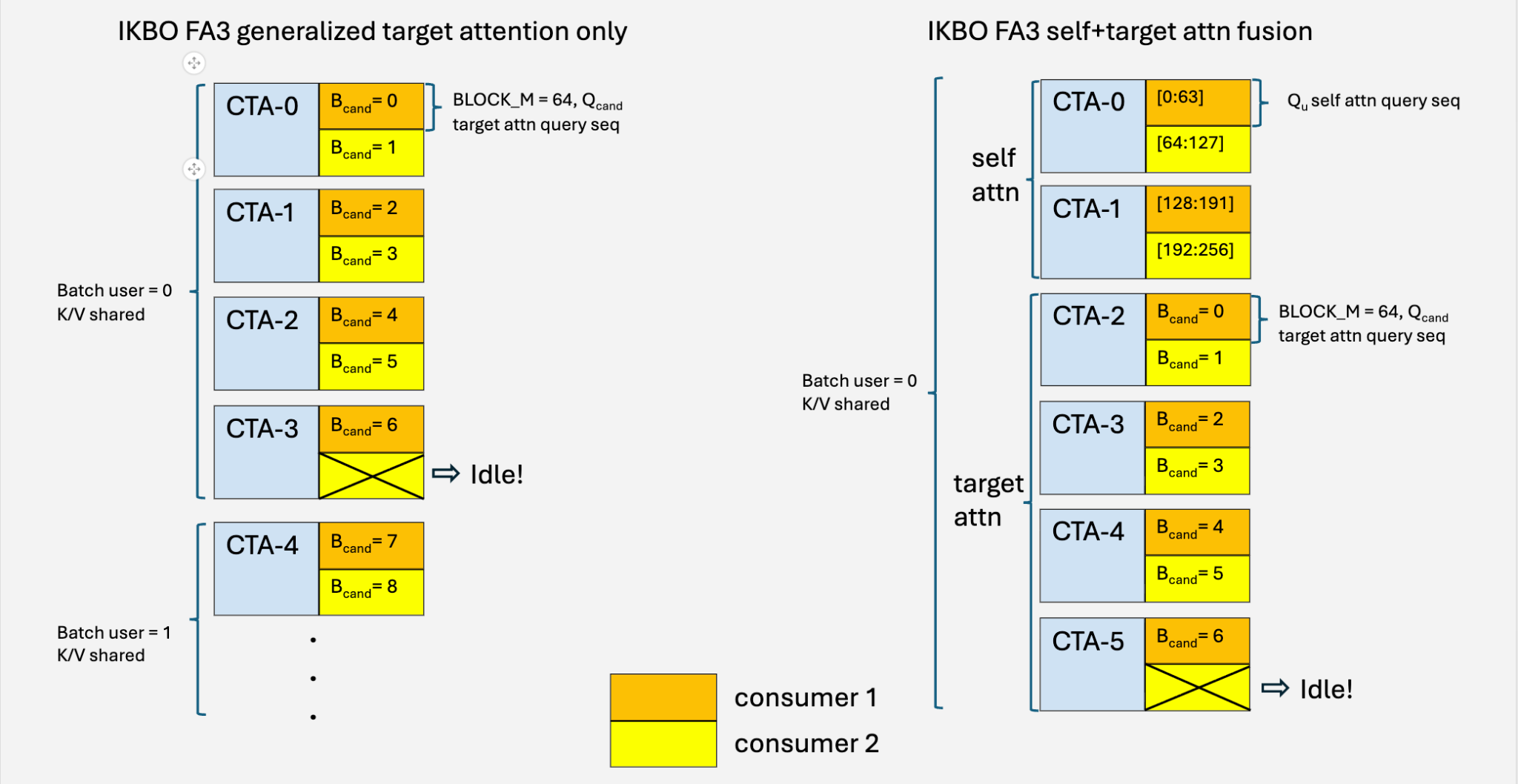 Fig. 13: CTA assignment for generalized target attention (left) and self + target attention fusion (right). Each CTA assigns two consumer warp groups sharing the same user K/V. When the candidate count is odd, the 2nd consumer idles and drains barriers.
Fig. 13: CTA assignment for generalized target attention (left) and self + target attention fusion (right). Each CTA assigns two consumer warp groups sharing the same user K/V. When the candidate count is odd, the 2nd consumer idles and drains barriers.

Algorithm 1: IKBO Attention Forward Pass with Odd Candidate Handling
3.3 Self + Target Attention Fusion via Model Co-Design
The previous sections focused on optimizing target (cross) attention. A natural question arises: can we fold self-attention into the same kernel?
The key insight is that both attention types share the same key-value source — the user sequence. The only difference is the query: self-attention queries come from the user side, while target-attention queries come from the candidate side. By sharing K/V projections between the two, we enable direct horizontal kernel fusion within a single launch. Fig. 13 (right) illustrates the fused CTA layout: the first CTAs handle self-attention query blocks, while the remaining CTAs handle target-attention candidate pairs — all reading from the same pipelined K/V stream.
Similar co-design ideas have been explored in XAI Phoenix, an open-source recommendation system from X [4].
We prototyped a fused kernel to quantify the fusion benefit, excluding K/V projection savings (Fig. 13, right):
- seq_len = 512: 6.6% improvement (514 vs. 482 TFLOPs/s)
- seq_len = 1,024: 4.1% improvement (581 vs. 558 TFLOPs/s)
- seq_len = 2,048: 0.3% improvement (612 vs. 610 TFLOPs/s) — self-attention saturates the SMs
The gains at short sequences stem from kernel fusion benefits: reduced launch overhead, shared buffer allocation savings, cross-kernel pipelining opportunities, and wave quantization mitigation — the same inefficiencies that megakernel techniques [12] target in LLM inference. In production, the shared K/V projections provide additional savings on linear projection cost, analogous to KV cache reuse.
4. Summary of Benchmarks and Results
We summarize the kernel-level benchmarks presented in this post alongside end-to-end deployment outcomes. All kernel benchmarks below are on H100 SXM5 (see details in Appendix 1).
- Linear Compression (Section 2). Four progressive co-design stages — matmul decomposition, memory alignment, broadcast fusion, and warp-specialized multi-stage fusion via TLX — yield a cumulative ~4× speedup (1.944 ms → 0.482 ms) at representative settings. Gains remain robust across batch sizes and candidate-to-user ratios (Fig. 9).
- Flash Attention (Section 3). IKBO shifts target attention from IO-bound (~60 FLOPs/Byte) to compute-bound (~833 FLOPs/Byte), achieving 2.4×/6.4× the throughput of non-co-designed CuTeDSL FA4-Hopper (kernel only / kernel + broadcasting) with 621 BF16 TFLOPs.
- End-to-end deployment. IKBO has been deployed broadly across Meta’s RecSys inference stack — from early-stage to late-stage ranking models, on both GPU and MTIA accelerators — delivering up to 2/3 reduction in compute-intensive net latency on co-designed models. IKBO has been validated across candidate-to-user broadcast ratios spanning from ~10,000 : 1 down to ~10 : 1, confirming both numerical stability and scalability across workloads.
5. Conclusion and Future Directions
IKBO demonstrates that broadcast — long treated as an unavoidable cost of user-candidate interaction — can be eliminated at the computational primitive layer through kernel-model-system co-design. By encoding broadcast semantics directly into kernels, no replicated tensors ever materialize, and savings scale naturally with the candidate-to-user ratio.
While the kernel implementations presented in this work target NVIDIA Hopper via Triton and TLX, the core idea — replacing materialized broadcasts with index-driven in-kernel lookups — is hardware-vendor independent. Adapting the IKBO kernels to CuTeDSL (for advanced NVIDIA backend support) and completing the AMD CK support are natural next steps.
Beyond the two-level user-candidate hierarchy presented here, some RecSys scenarios involve deeper hierarchies — for example, user → ads vendor → ads item, where each user sees multiple vendors and each vendor offers multiple items. This introduces two nested broadcast relationships with independent, non-uniform ratios. IKBO can handle this elegantly, and applying it to multi-level workloads is a natural direction for further reducing materialization overhead in production RecSys architectures.
Acknowledgements
We are grateful to Hongtao Yu, Yuanwei (Kevin) Fang, Daohang Shi, Yueming Hao, Srivatsan Ramesh and Manman Ren for their strong internal support of the Triton and TLX foundation, the powerful Triton profiling toolings, and for promptly resolving Triton-related issues throughout this work.
Thanks Chris Gottbrath for his insightful feedback, which significantly improved the clarity of this post. We also greatly appreciate his help in facilitating a smooth review process.
Thanks Santanu Kolay, Sandeep Pandey, Matt Steiner, GP Musumeci, Ashwin Kumar, Ian Barber, Aparna Ramani, CQ Tang for leadership support.
References
[1] Naumov, M., et al. “Deep Learning Recommendation Model for Personalization and Recommendation Systems,” arXiv:1906.00091, 2019.
[2] Wang, R., et al. “Deep & Cross Network for Ad Click Predictions,” ADKDD, 2017.
[3] Zhai, J., et al. “Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations,” ICML, 2024.
[4] xAI. “Phoenix: Recommendation System,” GitHub, 2026. https://github.com/xai-org/x-algorithm
[5] Guo, L., et al. “Request-Only Optimization for Recommendation Systems,” arXiv:2508.05640, 2025.
[6] Zhang, B., et al. “Wukong: Towards a Scaling Law for Large-Scale Recommendation,” ICML, 2024.
[7] Vaswani, A., et al. “Attention Is All You Need,” NeurIPS, 2017.
[8] Lee, J., et al. “Set Transformer: A Framework for Attention-based Permutation-Invariant Input,” ICML, 2019.
[9] Dao, T. “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,” ICLR, 2024.
[10] Shah, J., et al. “FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision,” NeurIPS, 2024.
[11] Zadouri, T., et al. “FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling,” arXiv:2603.05451, 2026.
[12] Spector, B., et al. “Look Ma, No Bubbles! Designing a Low-Latency Megakernel for Llama-1B,” Hazy Research Blog, 2025. https://hazyresearch.stanford.edu/blog/2025-05-27-no-bubbles
Appendix
Appendix 1. Benchmark Setup
All experiments are conducted on a single NVIDIA H100 SXM5 GPU (700 W TDP, 96 GB HBM2e) with the following software stack:
- CUDA: 12.4
- PyTorch: 2.11.0a0+fb (internal build)
- Triton: facebookexperimental/triton@
4059e79bf(#831)
Appendix 2. Arithmetic Intensity Analysis
2.1 Machine Balance Point of H100 SXM5 (700 W TDP, 96 GB HBM2E)
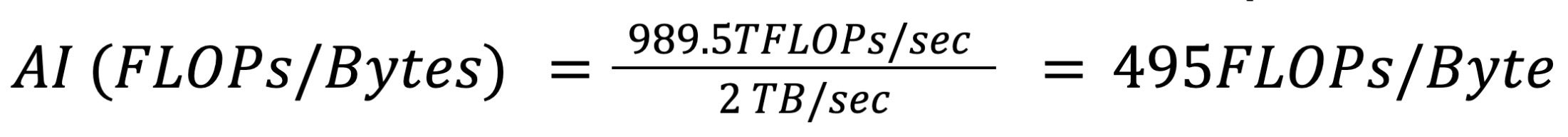
2.2 Arithmetic Intensity of the Baseline LCE
For a batched matmul (M, K) @ (B, K, N) → (B, M, N) in FP16, with B=1024, M=433, K=2044, N=256:
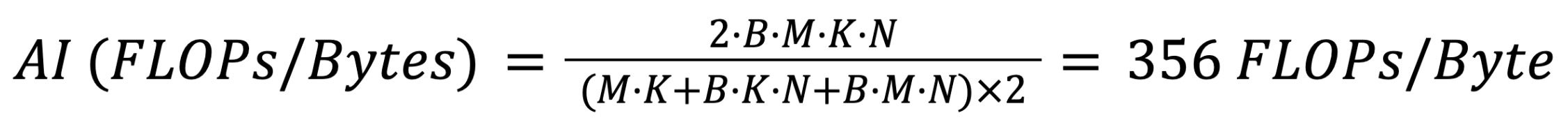
Appendix 3. Detailed Result Analysis for Section 2.1
Setup: H100 SXM5 (Appendix 1), PyTorch eager mode (no kernel fusion), inference. Shapes from a representative configuration.
| Version | Total
(ms) |
Kernels | Latency
(ms) |
DRAM
(GB) |
L1/TEX Sectors
(M) |
Compute
(GFLOPs)* |
Bottleneck
† |
| Baseline | 1.944 | 1 CUTLASS GEMM | 1.944 | 1.31 | 798 | 460 | L1/TEX (89%) |
| Decomposition | 1.389 | 2 CUTLASS GEMM (user + candidate matmul) | 0.984 | 0.68 | 351 | 200 | L1/TEX (84%) |
| 1 ATen Gather + 1 ATen add | 0.405 | 0.87 | 36 | 0.11 | DRAM (92%) |
*Total FLOPs executed, not throughput.
†Bottleneck identified via NCU Speed of Light analysis; methodology in Appendix 4.
Deduplication eliminates >98% of user-side work (batch 1024 → ~15), cutting L1/TEX sectors from 798M to 351M and GEMM latency from 1.944 ms to 0.984 ms. The post-GEMM broadcast and addition costs 0.405 ms (DRAM-bound), yielding a net saving of 0.555 ms.
Precision note. The baseline accumulates all K products in a single FP32/TF32 reduction. Decomposition accumulates K_user and K_cand separately, then sums the partial results in BF16/FP16. Training uses the same decomposition, so numerics match end-to-end. For exact inference parity, a fused kernel (Section 2.4) can perform the final summation in FP32.
Appendix 4. Bottleneck Analysis Methodology
For a closer look after roofline analysis, we use NCU’s Speed of Light analysis to identify hardware subsystem bottlenecks. The bottleneck is the subsystem with the highest utilization relative to its peak sustained throughput. For the analysis in Section 2.1, we monitor three metrics:
Compute is the peak SM pipeline utilization, reported directly by NCU (Compute (SM) Throughput). It measures how busy the most active execution pipeline (tensor cores for GEMMs) is relative to its peak instruction rate.
L1/TEX utilization is derived from the total sectors the L1/TEX unit must process as below, where num_L1_tex_sectors is l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum and _st.sum counter, is SM_active_cycles sm__cycles_active.avg counter, num_SM is 132 and num_sustained_peak_sectors_per_sm_per_cycle is 2.0 on H100.
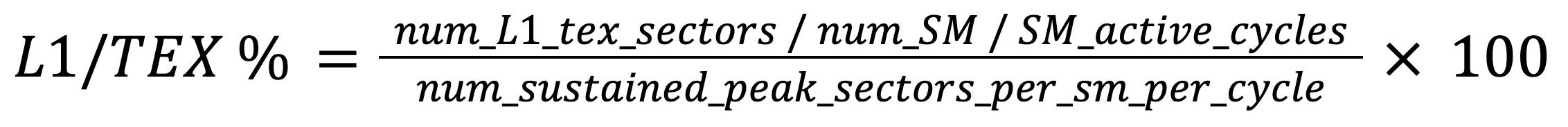
DRAM utilization is derived from total HBM bytes transferred as below, where dram_bytes_read_and_write is the dram__bytes_read.sum and dram__bytes_write.sum counter. peak_bandwidth is 2TB/s on the testing GPU server.
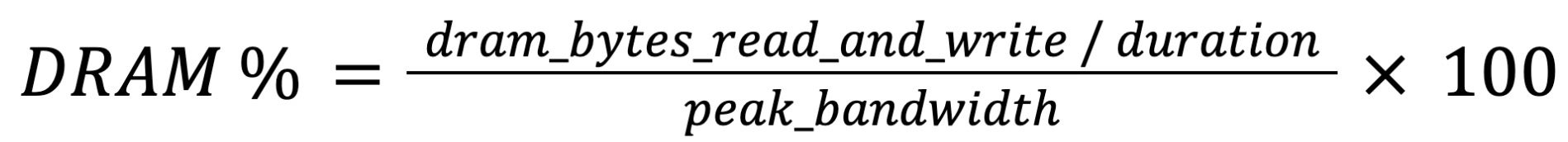
Appendix 5. Detailed Result Analysis for Section 2.2
Result. 1.389 ms → 0.798 ms (42.5% reduction).
| Version | Total Latency
(ms) |
Kernels | Latency
(ms) |
DRAM Traffic
(GB) |
Compute
(GFLOPs) *not speed |
L1/TEX Sectors
(M) |
Bottleneck
† |
| Decomposition
(unpadded) |
1.386 | 2 CUTLASS GEMM – user & candidate matmul | 0.984 | 0.68 | 200 | 351 | L1/TEX (84%) |
| 1 ATen Gather – broadcast
1 ATen Elementwise – add |
0.402 | 0.87 | 0.11 | 36 | DRAM (92%) | ||
| Decomposition
(padded K) |
0.798 | 2 CUTLASS GEMM – user & candidate matmul | 0.400 | 0.69 | 200 | 0 | Balanced |
| 1 ATen Gather – broadcast
1 ATen Elementwise – add |
0.398 | 0.87 | 0.11 | 36 | DRAM (92%) |
Two factors behind the large speedup.
- TMA. With aligned matrices, CUTLASS selects a TMA-based kernel, bypassing L1/TEX entirely (sectors → 0). The unpadded kernel also penalized matrix
Bunnecessarily: it applied 4-byte loads to both matrices, even thoughB(with alignedN) could have used 128-bit loads. - Bank conflicts. The unpadded kernel also uses sm80 MMA path whose swizzle pattern doesn’t protect against 4-byte cp.async writes, causing many shared memory bank conflicts. The padded kernel doesn’t have this issue.
Appendix 6. Detailed Result Analysis for Section 2.3
Result. Latency: 0.798 ms → 0.580 ms (27.4% reduction).
| Version | Total Latency
(ms) |
Kernels | Latency
(ms) |
DRAM Traffic
(GB) |
| Decomposition
(padded K) |
0.798 | 2 CUTLASS GEMM – user & candidate matmul | 0.400 | 0.68 |
| 1 ATen Gather – broadcast
1 ATen Elementwise – add |
0.398 | 0.87 | ||
| iKBO Fusion | 0.580 | user GEMM & candidate iKBO kernel | 0.580 | 0.68 |
The 0.87 GB of intermediate DRAM traffic is eliminated as expected. NCU profiling reveals further opportunity: occupancy is just 6.25% with 1 warp per scheduler, and PC sampling shows only 23% of cycles are productive:
| Stall Reason | Percentage | What it mainly refers in the kernel |
| Stall long scoreboard | 41.8% | Global memory loads |
| Selected (executing) | 23.1% | Productive work (good) – instructions actually issued |
| Stall wait | 20.1% | Wait WGMMA |
| Stall barrier | 5.7% | bar.sync between software-pipeline stages |
With 1 warp per scheduler, every stall is fully exposed: there is no other warp to switch to. Increasing occupancy by reducing pipeline depth would sacrifice K-loop latency hiding. This is a challenging situation for this kernel: large tiles and deep pipelines are needed to keep the tensor cores throughput, but they consume most of the shared memory budget, leaving little room to hide latency through occupancy.
Appendix 7. Release-Acquire Synchronization Protocol
Producer (user CTA). After storing a user tile to global memory, the CTA sets a per-tile flag with release semantics, ensuring data visibility before the flag write:
tl.atomic_add(user_tile_flag_ptr, 1, sem="release", scope="gpu")
Consumer (candidate CTA). A single thread per warp group polls the flag with ld.relaxed to minimize memory traffic during the spin. Once the flag transitions, a single ld.acquire establishes the happens-before edge, and a named barrier broadcasts readiness to all 128 threads in the warp group:
if tlx.thread_id(axis=0) % 128 == 0: # 1 thread per warp group (4 warps)
ready = tl.inline_asm_elementwise(
"ld.relaxed.gpu.global.b32 $0, [$1];", "=r,l",
[user_tile_flag_ptr], dtype=tl.int32, is_pure=False, pack=1)
while ready == 0:
ready = tl.inline_asm_elementwise(
"nanosleep.u32 50; ld.relaxed.gpu.global.b32 $0, [$1];", "=r,l",
[user_tile_flag_ptr], dtype=tl.int32, is_pure=False, pack=1)
tl.inline_asm_elementwise(
"ld.acquire.gpu.global.b32 $0, [$1];", "=r,l",
[user_tile_flag_ptr], dtype=tl.int32, is_pure=False, pack=1)
tlx.named_barrier_wait(12, 128)
Appendix 8. NCU Profiling Metrics for TLX vs. Triton
| Metric | Triton | TLX | Notes |
| Theoretical Occupancy | 6.25% | 18.75% | 3 warp groups per CTA vs. 1 |
| DRAM Throughput
(dram__cycles_active.avg.pct_of_peak_sustained_elapsed) |
38.51% | 52.39% | Higher utilization from continuous TMA loads |
| L2 Cache Throughput
(lts__throughput.avg.pct_of_peak_sustained_elapsed) |
73.69% | 83.86% | Bottleneck. TLX pushes closer to peak |
Appendix 9. Roofline analysis of normal flash attention vs IKBO flash attention
Arithmetic intensity (AI) is calculated given FP16/BF16 precision, user_seq_len = 1024, n_seed = 64, B_candidate (B in eq) : B_user (B/num_cand_user in eq) = 70: 1.

Appendix 10. SMEM consumption of IKBO TLX FA3
| SMEM buffer | Counts | Block dim | Total size |
| Query | 2 (1 for each consumer group) | 64 * 128 (2Bytes) | 32KB |
| Key | 2 | 128 * 128 (2Bytes) | 64KB |
| Value | 2 | 128 * 128 (2Bytes) | 64KB |
| Output | 2 (1 for each consumer group) | 64 * 128 (2Bytes) | 32KB |
| Total | 192KB |
Appendix 11. Benchmarking IKBO FA vs CuTeDSL FA4 Hopper and TLX FA3 Hopper kernel under RecSys boundary condition
IKBO kernel is basically enabling the user-candidate interaction mapping logic which shares a similar IO and computation pattern as GQA. During benchmarking, a stable B_candidate : B_user = 64 : 1 is applied for IKBO kernel and similar compute patterns for CuTeDSL FA4 Hopper GQA version (Q_seq_len = 128 to make sure 2-consumer warpgroup to work perfectly). Worth additional mentioning, IKBO kernel still needs to extra consume the candidate-user mapping tensor to handle a varied number of candidates to be ranked in real time.
| Kernel type | Throughput (TFLOPs/s) | IO (GB/s) |
| Triton IKBO FA2 | 425 | 519 |
| TLX IKBO FA3 | 418 | 510 |
| TLX IKBO FA3 persistent | 592 | 723 |
| TLX IKBO FA3 persistent V2 (reverse k,v order) | 537 | 655 |
| CuTeDSL FA4 Hopper GQA | 518 | 633 |
| TLX FA3 GQA | 576 | 703 |
IKBO FA benchmarked vs open-source GQA kernel. Q, K, V shape for IKBO kernel in the sequence of [Batch size, num head, seq, d_head] Q_ikbo [2048, 2, 64, 128], K/V_ikbo [32, 2, 1024, 128]. Q, K, V shape for GQA kernel Q_gqa [1024, 2, 128, 128], K/V_gqa [32, 2, 1024, 128]
| Kernel type | Throughput (TFLOPs/s) | IO (GB/s) |
| Triton IKBO FA2 | 449 | 329 |
| TLX IKBO FA3 | 470 | 345 |
| TLX IKBO FA3 persistent | 621 | 455 |
| TLX IKBO FA3 persistent V2 (reverse k,v order) | 587 | 430 |
| CuTeDSL FA4 Hopper GQA | 608 | 445 |
| TLX FA3 GQA | 628 | 460 |
IKBO FA benchmarked vs open-source GQA kernel. Q_ikbo [2048, 2, 64, 128], K/V_ikbo [32, 2, 2048, 128]. Q, K, V shape for GQA kernel Q_gqa [1024, 2, 128, 128], K/V_gqa [32, 2,2048, 128]
Note: Since standard Flash Attention kernels do not incorporate IKBO logic, we use a GQA configuration with similar IO cost and FLOPs consumption to simulate throughput results for cuteDSL versions.
Appendix 12: Instruction cache miss cause significant delay on the consumer-2 warpgroup
 Fig. A1
Fig. A1
Instruction cache miss result before and after the fix
Before instruction cache miss fix:
---------------------------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
---------------------------------------------------- ----------- ------------
gcc__cache_requests_type_instruction.sum 319,394
gcc__cache_requests_type_instruction_lookup_miss.sum 7,234
sm__icc_requests.sum cycle 6,049,376
sm__icc_requests_lookup_hit.sum cycle 5,438,421
sm__icc_requests_lookup_miss.sum cycle 610,955
---------------------------------------------------- ----------- ------------
After instruction cache miss fix:
---------------------------------------------------- ----------- ------------
Metric Name Metric Unit Metric Value
---------------------------------------------------- ----------- ------------
gcc__cache_requests_type_instruction.sum 33,008
gcc__cache_requests_type_instruction_lookup_miss.sum 769
sm__icc_requests.sum cycle 792,437
sm__icc_requests_lookup_hit.sum cycle 722,244
sm__icc_requests_lookup_miss.sum cycle 70,193
---------------------------------------------------- ----------- ------------