Featured projects

TL;DR: vLLM has been critical to democratizing access to our research community to the latest and greatest LLMs as they release.
Introduction
In mid-November 2024, IBM Research introduced the Research Inference & Tuning Service (RITS) Platform. RITS is an Infrastructure / Service Platform accessible to the entire IBM Research community, providing centralized deployment of and shared access to Model Inferencing Endpoints and “Ancillary” Tuning Service Endpoints. Since its inception, it has grown its research community user base to more than 1300 active users and hosts over 100 models at any given time.
The Business Challenge
RITS was introduced to ensure the IBM Research community has access to a shared operational Infrastructure / Service Platform, which could:
- Optimize the utilization of GPU resources across Research work streams by democratizing Model Inference Endpoints (and thereby reducing overall operating costs)
- Focus on providing access to exotic and experimental models in high demand, not available through other channels, which are typically needed for Research initiatives
When establishing RITS, Research leadership and the AI Platform Enablement team established the following high-level objectives:
- Develop an Infrastructure / Service Platform for Expert Users to leverage via API access
- Develop the Platform based on open standard interfaces -for example, Red Hat Openshift AI, vLLM Serving, and OpenAI API
- Prioritize support for Inference at Scale, optimizing GPU utilization with Serverless-based Auto-Scaling, Scaling based on custom metrics, and Throttling of User Requests
- Endpoint Security via the use of Self-managed API Keys governed via API Gateway technologies
- Support easy Model Endpoint Discovery and Model Endpoint Introspection (visibility to model deployment and model runtime configuration)
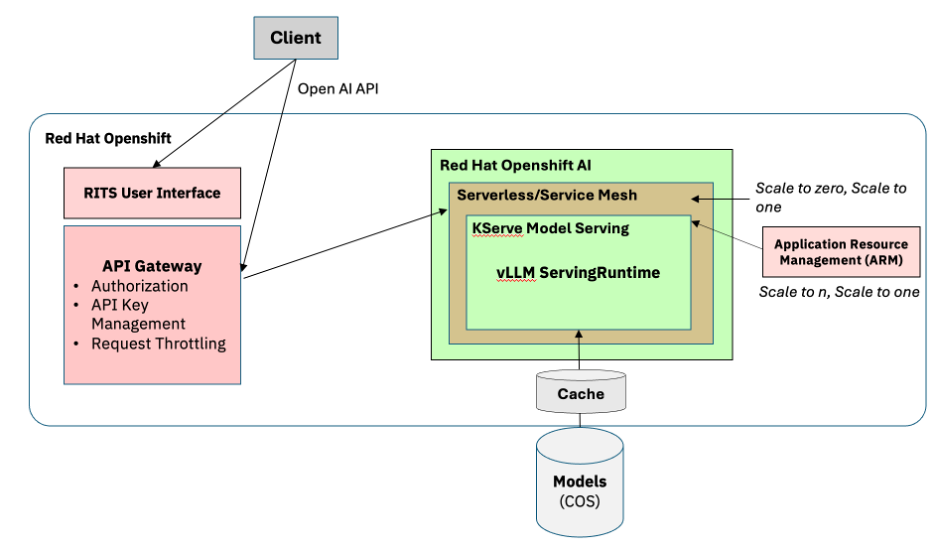
Figure 1: RITS Platform High-level Architecture
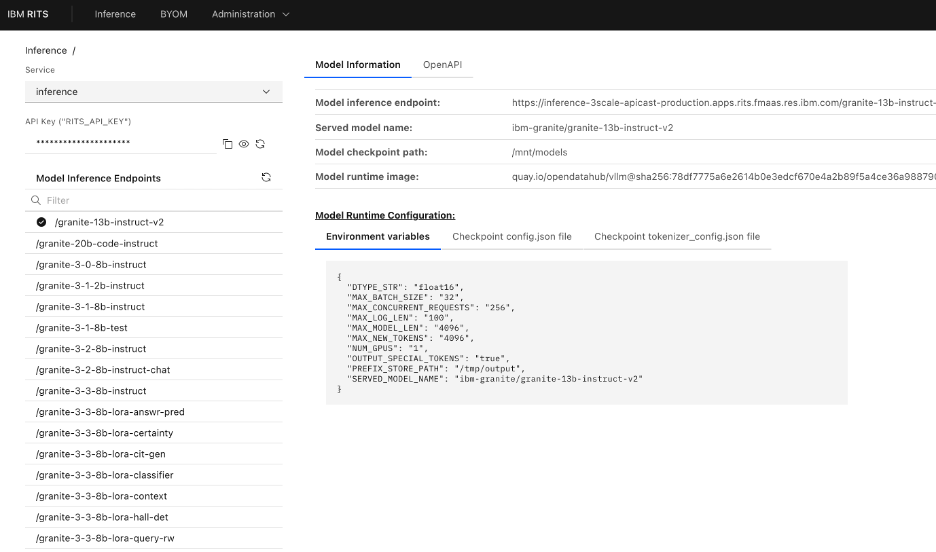
Figure 2: RITS Platform UI – Model Discovery & Introspection
How IBM Research Uses vLLM
vLLM is at the heart of the RITS Platform. All Models deployed to the RITS Platform utilize vLLM as a model serving runtime. vLLM integrates seamlessly into the Red Hat AI portfolio, with Red Hat AI Inference Server and OpenShift AI, which provide foundational capabilities to deploy, monitor, scale, and maintain large models that require specialized accelerator resources for model serving. Furthermore, because vLLM is a hosted project under the PyTorch Foundation, it guarantees a long-term, vendor-neutral open standard that aligns with IBM’s commitment to hybrid, open architectures.
Red Hat OpenShift AI integrates KServe, which orchestrates model serving by leveraging model-serving runtimes that implement the loading of various types of model servers, in our case, the runtime being vLLM. Given the fact that RITS runs 100s of different models, many of which are often new or experimental, Red Hat OpenShift AI allows us to register different versions of vLLM as custom Serving Runtimes (when custom images are required for a particular model deployment).
The Serving Runtime creates the environment for deploying and managing the model, creating the template for the vLLM pods that dynamically load and unload models, and exposes the service endpoint for inferencing requests.
Solving AI Challenges with vLLM
The efficient use of limited and costly GPU resources is always paramount for a Model as a Service Platform like RITS, especially when the platform is shared by 100s of active users at any given time, submitting varied workloads that are unknown and unpredictable to platform administrators. Serving performance is paramount, and vLLM as a Serving Runtime helps address our performance requirements while efficiently managing available compute resources.
vLLM is designed for inference serving efficiency. Features such as PagedAttention for efficient memory management, Continuous Batching for optimized serving performance, and Quantization Support allowing for the deployment of models of reduced size without sacrificing model accuracy are all features that contribute to RITS Platform adoption and success.
From an operations perspective, vLLM exposes a rich set of server-level and request-level metrics that can be utilized by both administrators and users to monitor model serving performance and stability. These metrics, exported to Prometheus, provide critical insight to platform administrators responsible for ensuring the operational stability of the platform and the performance SLOs of its hosted models, as well as providing the means to establish near real-time dashboards which allow end-users to monitor model performance to optimize batch job scheduling and configuration.
Autoscaling model deployments based on unknown and unpredictable load is critical for the success of RITS (where GPU resources need to be carefully managed). Performing model autoscaling based on basic metrics such as Requests per Second (RPS), which may be adequate for traditional CPU/Memory-intensive workloads, is not adequate for Model Serving workloads that require limited and expensive GPU Accelerator resources. Once again, vLLM and its exported metrics have made it possible for RITS to implement a hybrid autoscaling model. RITS leverages serverless technologies for 0 to 1 and 1 to 0 scaling, but then leverages Turbonomic, IBM’s Application Resource Management (ARM) product, to perform scaling from 1 to n and n to 1, using custom metrics emitted by the vLLM serving runtime (Requests Waiting being a much better scaling metric than RPS). This sophisticated, metric-driven approach to scaling and request routing directly anticipates the advanced orchestration features that are now becoming native in emerging distributed frameworks like llm-d.
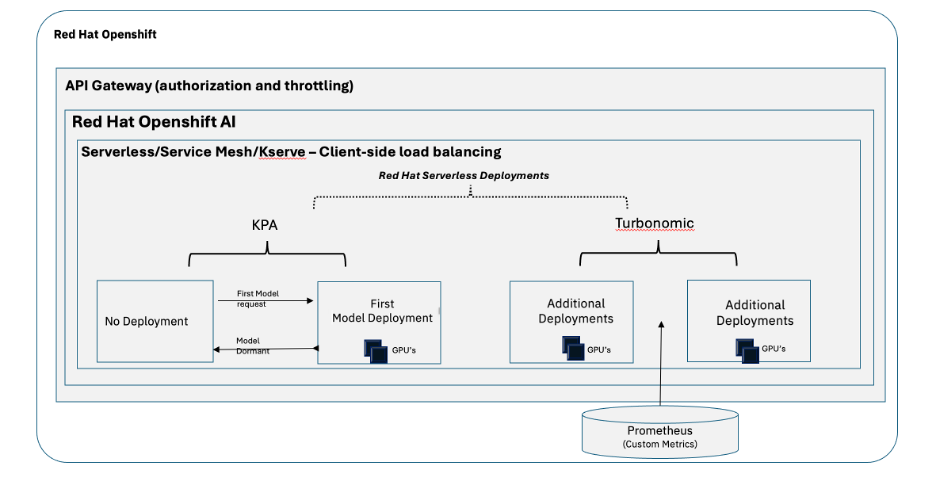
Figure 3: RITS Platform Hybrid Autoscaling Model
A Word from IBM
” The vLLM community is vibrant and responsive, and with collaborative expertise, we are able to do great things both upstream and internally by leveraging and contributing to this groundbreaking project. vLLM has been critical to democratizing access to our research community to the latest and greatest LLMs as they release.”
–Priya Nagpurkar, Vice President, AI Platform, IBM Research
The Benefits of Using vLLM
Leveraging vLLM as our core serving runtime has significantly contributed to the RITS Platform’s overall success and adoption. In addition to the performance optimizations, scalability, and stability benefits already mentioned, vLLM offers the end-user community an easy platform adoption path. vLLM’s support of OpenAI API has allowed our user community to leverage a simple, consistent HTTP-based inference API, as well as leveraging the user’s favorite client-side SDKs. In addition, vLLM’s broad adoption and integration with various open-source LLMs has allowed the RITS Administration team the ability to leverage a single and consistent serving runtime across all deployed models.
vLLM has been and will continue to be the core enabler of the RITS Platform, even as we evolve to optimized distributed runtime frameworks such as llm-d in the coming months. By pairing vLLM’s high-performance inference engine with llm-d’s cluster-wide orchestration, RITS will be able to leverage techniques like predicted-latency-based scheduling and cache-aware affinity routing to maximize prefix reuse. This ensures every GPU has work, driving predictable, cost-efficient scale while seamlessly supporting a wider variety of hardware accelerators. vLLM will also allow us to expand beyond using GPU Accelerators, establishing a heterogeneous compute environment within RITS; the IBM Spyre Accelerator will become a core Accelerator for various models leveraging the vLLM serving runtime. Stay Tuned – exciting times lie ahead!
Learn More
This is just one of the many ways that IBM leverages the power of vLLM. Learn more about how we combine vLLM with KServe for fast inference at scale, how to set up and run vLLM on IBM Power, and run Granite models with vLLM in a container.
vLLM is a PyTorch Foundation-hosted project. Learn more >>
llm-d is a Cloud Native Computing Foundation Sandbox project. Learn more >>