Summary
We introduce KernelFalcon, a deep agent architecture for generating GPU kernels that combines hierarchical task decomposition and delegation, a deterministic control plane with early-win parallel search, grounded tool use, and persistent memory/observability. KernelFalcon is the first known open agentic system to achieve 100% correctness across all 250 L1/L2/L3 KernelBench tasks.
KernelFalcon’s codebase is located at github.com/meta-pytorch/KernelAgent, alongside documentation and examples for getting started.
Introduction
Writing optimized GPU kernels remains a bottleneck in deploying machine learning models. Teams rarely have bandwidth to hand-tune operators for every shape, dtype, and hardware generation. The problem compounds as models evolve – patterns that worked for ResNet don’t map cleanly to Mamba’s selective states or MoE’s conditional routing.
Modern compilers have made real progress, but still struggle with the long tail. TorchInductor covers common patterns, TVM auto-schedules dense kernels, and XLA specializes for dynamic shapes. But unusual ops, dynamic control flow, and heterogeneous fusion patterns still escape optimal compilation. NVIDIA’s work earlier this year using DeepSeek-R1 with inference-time scaling achieved strong results on KernelBench L1/L2, demonstrating that LLM-based approaches with verification loops can match or exceed traditional methods – but stopped short of tackling full model architectures (L3).
What if we could automatically synthesize Triton kernels that preserve PyTorch semantics and push toward hand-tuned performance – without expanding rule libraries or hiring more GPU experts?
Enter KernelFalcon: a code-to-code system that preserves PyTorch semantics while generating optimized Triton kernels. Instead of one-shot generation, it uses parallel exploration with execution-based verification – delivering kernels that actually run on GPU and match the original model’s numerics.
Why KernelFalcon (and Why Deep Agents)?
Traditional static, graph-based compilers lean on IR transforms and per-pattern schedules. Tracing often freezes control flow to a single path and struggles with dynamic shapes. KernelFalcon takes a different route:
Preserve Python semantics. We stay code-to-code in PyTorch, so if/else, while,data-dependent routing and dynamic shapes remain valid.
Verifier-first loop. A KernelAgent compiles and tests candidate kernels; failures feed back locally; we early-exit on the first numerically correct kernel.
Compose and verify end-to-end. Fused kernels drop in for the original ops, followed by whole-model parity checks before acceptance.
Under the hood is a deep agent architecture – a multi-stage system designed to reduce LLM failure modes by structuring the problem:
- Explicit task decomposition turns vague goals into precise, tool-ready subproblems
- Deterministic orchestration keeps control logic in Python, letting LLMs focus on cognition
- Parallel search with early stop explores diverse solutions efficiently
- Grounded tool use validates every step with real compilers and hardware
- Structured state persists prompts, logs, and artifacts for auditability and resume
This isn’t just a cleaner implementation; it’s a different paradigm. Instead of “can the LLM solve this?”, we ask “how do we shape the task so the LLM is likely to succeed?” The result is broader coverage and more realistic performance—without ballooning rule sets or sacrificing semantics.
KernelFalcon Architecture
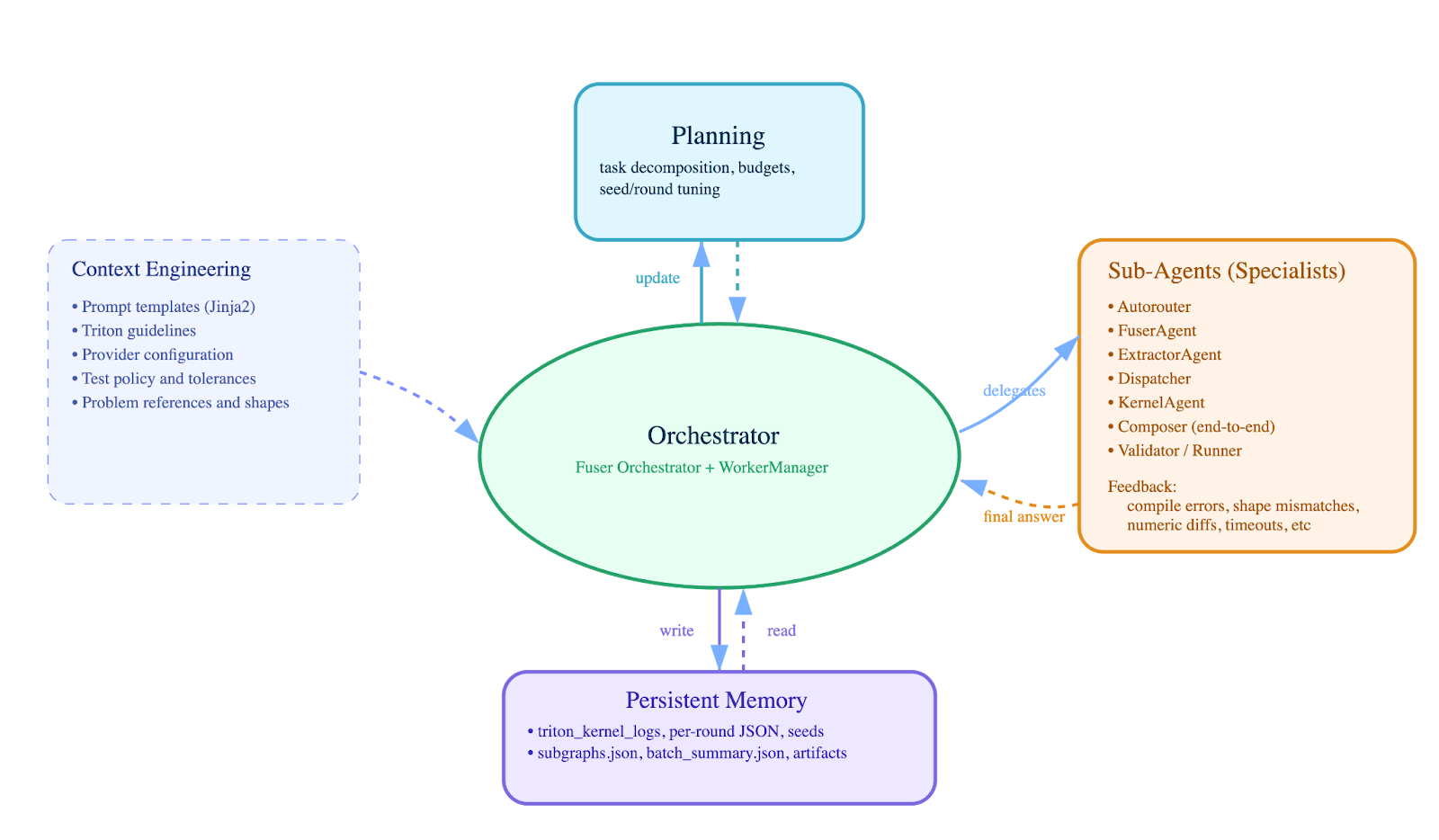
Figure 1: KernelFalcon’s deep agent architecture centers on the Orchestrator coordinating the entire workflow. Planning handles task decomposition and budget allocation. Context Engineering provides structural constraints (templates, guidelines). Sub-Agents handle specialized tasks, extracting fusion boundaries, generating Triton kernels, composing end-to-end modules, and executing validation. Persistent Memory stores artifacts for debugging and resume. The Orchestrator delegates to specialists, receives structured error feedback, and maintains state throughout execution.
This architecture embodies the deep agent principles:
- Hierarchical delegation: Orchestrator decomposes high-level tasks (fuse this model) into precise sub-problems (extract subgraphs, generate kernels, compose results) assigned to specialist agents
- Deterministic control: Planning and orchestration logic is explicit Python code, not LLM-driven—worker lifecycles, timeouts, and success conditions are programmatic
- Grounded execution: Every agent validates against real tools (Triton compiler, PyTorch reference, GPU execution) rather than simulated or LLM-judged results
- Persistent state: All intermediate results, prompts, logs, and artifacts persist to disk for auditability, debugging, and resume across sessions
- Structural constraints: Context engineering encodes rules as templates and policies, making correctness requirements structurally enforced rather than prompt-dependent
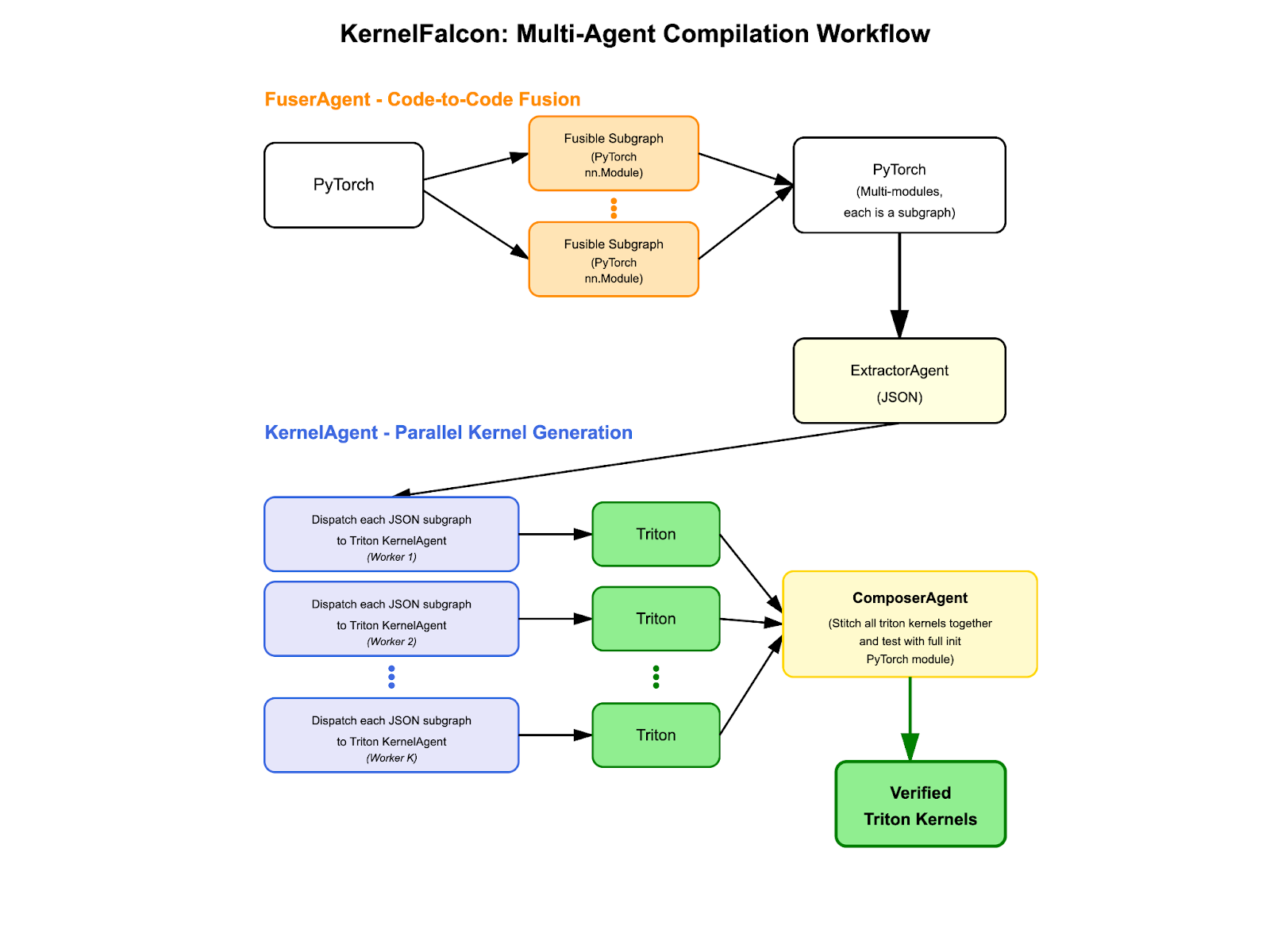
Figure 2: Multi-stage workflow diagram showing PyTorch input flowing through FuserAgent (creating fusible subgraphs), ExtractorAgent (generating JSON specs), parallel KernelAgent workers (three Triton boxes showing concurrent generation), and ComposerAgent (stitching to verified kernels). Arrows show data flow between stages with annotations for intermediate representations.
Pipeline: How Data Flows Through the System
The pipeline implements four distinct stages:
- FuserAgent – Code-to-code fusion preserving Python semantics
- ExtractorAgent – Shape inference and contract generation
- Dispatcher + KernelAgent – Coordinates Parallel Triton kernel synthesis with verification
- ComposerAgent – End-to-end integration and validation
Architecture: Stage-by-Stage Breakdown
Stage 1: FuserAgent – Code-to-Code Fusion
Traditional compilers lower PyTorch to static IRs during fusion analysis, losing information that makes debugging difficult and breaking on dynamic control flow. FuserAgent operates directly on PyTorch source code. The orchestrator manages the fusion workflow, producing clean PyTorch modules with explicit subgraph boundaries.
Input: Raw PyTorch model with arbitrary complexity
class Model(nn.Module): def forward(self, x): if x.sum() > 0: x = self.conv(x) x = self.bn(x) x = torch.tanh(x) x = F.max_pool2d(x, 2) return self.norm(x)
Process:
- Parse and analyze: Extract operation sequences, data dependencies, and control flow boundaries
- Identify fusion opportunities: Find groups of operations that can be fused while preserving semantics
- Generate fused modules: Create clean PyTorch functions with explicit tests
- Validate incrementally: Test each fused subgraph independently before proceeding
Output: Fused PyTorch module with subgraph functions
# Fused module with control flow preserved class FusedModel(nn.Module): def __init__(self, channels: int): super().__init__() self.branch = ConvBnTanhMaxPool(channels=channels) self.norm = ChannelwiseNorm(channels=channels) def forward(self, x: torch.Tensor) -> torch.Tensor: if x.sum() > 0: # Control flow intact x = self.branch(x) return self.norm(x)
Why this works: The orchestrator produces precise specifications that downstream stages can execute against. The control flow (if x.sum() > 0) stays in Python—we never try to compile it away.
By staying at the Python source level, we preserve variable names, comments, and full control flow context. Most traditional compiler-style fusers assume they’re optimizing a static dataflow graph, so dynamic Python-side control flow is either collapsed or must be rewritten before fusion happens:
So, unlike our prompt-driven approach that keeps thePython ifand just inserts fused submodules inside it, traditional compiler-based fusion tends to either specialize to a single branch during tracing or require significant manual effort to encode control flow explicitly. When TorchScript lowers to SSA form, your carefully named hidden_statesbecomest0. When torch.fx traces through a conditional, the untaken branch simply disappears. Even with TorchDynamo/torch.compile, while it handles control flow better through graph breaks and guards, it still specializes graphs for observed paths – your if x.sum() > 0 becomes a guard check that either reuses a cached graph or triggers recompilation. FuserAgent takes a different approach: we preserve the Python if statement but fuse operations within each branch. You still get kernel fusion benefits (the ops inside each branch become optimized Triton kernels), but the control flow itself stays readable Python.
This matters for modern ML patterns that are everywhere now: TreeLSTM recursing over parse trees, early-exit networks bailing out when confident, Mixture-of-Experts routing to different subnetworks. And crucially, when debugging goes wrong – when your kernel produces NaNs or fusion fails – you want to read Python, not IR. You want to see what the system actually tried to fuse, in the language you wrote it in.
Deep agent principle: Deterministic control plane
All orchestration – worker lifecycles, timeouts, artifact paths, and early-exit on success – is implemented in Python. LLMs generate candidate code and metadata (fused modules, subgraph JSON, Triton kernels, composed kernels); the controller executes and validates outputs, not the LLM.
The workflow:
- Orchestrator spawns N workers with typed
WorkerConfigstreams logs, waits for winner on a queue, cancels others, and packages artifacts - Worker iterates: render prompt → stream LLM → extract Python block → dedup by SHA → execute candidate → if PASS, signal winner; else save error and retry
- No manual AST parsing or rule-based fusion detection—the LLM proposes fused code directly via prompts, then Python validates by execution
Reference: Fuser/orchestrator.py, Fuser/worker.py, Fuser/runner.py, Fuser/prompting.py
Stage 2: ExtractorAgent – Subgraph Boundary Inference
The extractor uses the LLM to analyze fused code and identify precise subgraph boundaries with shape contracts.
Input: Fused PyTorch module from Stage 1
Extraction Process:
- Run orchestrator: First, obtain the fused code from Stage 1
- Prompt LLM: Ask LLM to identify distinct subgraph functions, infer shapes, and catalog operations
- Generate JSON specs: LLM produces typed specifications with operation sequences, shapes, and weight metadata
- Dedup and merge: Group subgraphs by stable signature (ops + shapes + weights), aggregate counts
Output: JSON array of subgraph specifications
[ { "id": "sg_conv_bn_tanh_pool_1", "type": "Conv2d_BN_Tanh_MaxPool", "data_layout": "NCHW", "dtype": "float32", "ops": [ {"op": "conv2d", "kernel_size": [3, 3], "stride": [1, 1], "padding": [1, 1], "dilation": [1, 1], "groups": 1, "bias": false}, {"op": "batch_norm", "eps": 1e-5, "momentum": 0.1}, {"op": "tanh"}, {"op": "max_pool2d", "kernel_size": [2, 2], "stride": [2, 2]} ], "input_shape": ["B", "C_in", "H", "W"], "output_shape": ["B", "C_out", "H_out", "W_out"], "weights_original": { "conv.weight": ["C_out", "C_in", 3, 3], "batch_norm.weight": ["C_out"], "batch_norm.bias": ["C_out"], "running_mean": ["C_out"], "running_var": ["C_out"] }, "weights_fused": null, "count": 1, "where": "Model.forward conditional branch", "source": { "module": "FusedConvBnTanhPool", "code": "def forward(self, x):\n x = F.conv2d(x, self.conv_w, stride=1, padding=1)\n x = F.batch_norm(x, self.bn_rm, self.bn_rv, self.bn_w, self.bn_b, training=False, eps=self.eps)\n x = torch.tanh(x)\n return F.max_pool2d(x, 2)" } } ]
This JSON becomes the contract for KernelAgent—explicit, typed, and verifiable. Each subgraph includes:
- Operation sequence with op-specific parameters
- Shape contracts for inputs and outputs
- Weight metadata tracking both fused and original parameters
- Location info (where in the model, source module)
- Count for deduped subgraphs
The orchestrator controls the workflow; the LLM generates the shape-aware metadata; deduplication handles identical patterns across the model.
Reference: Fuser/subgraph_extractor.py
Stage 3: Dispatcher + KernelAgent – Parallel Triton Generation
Dispatcher coordinates parallel Triton kernel generation for each subgraph specification. For each subgraph, it creates a fresh TritonKernelAgent with a worker pool (default 4 workers).
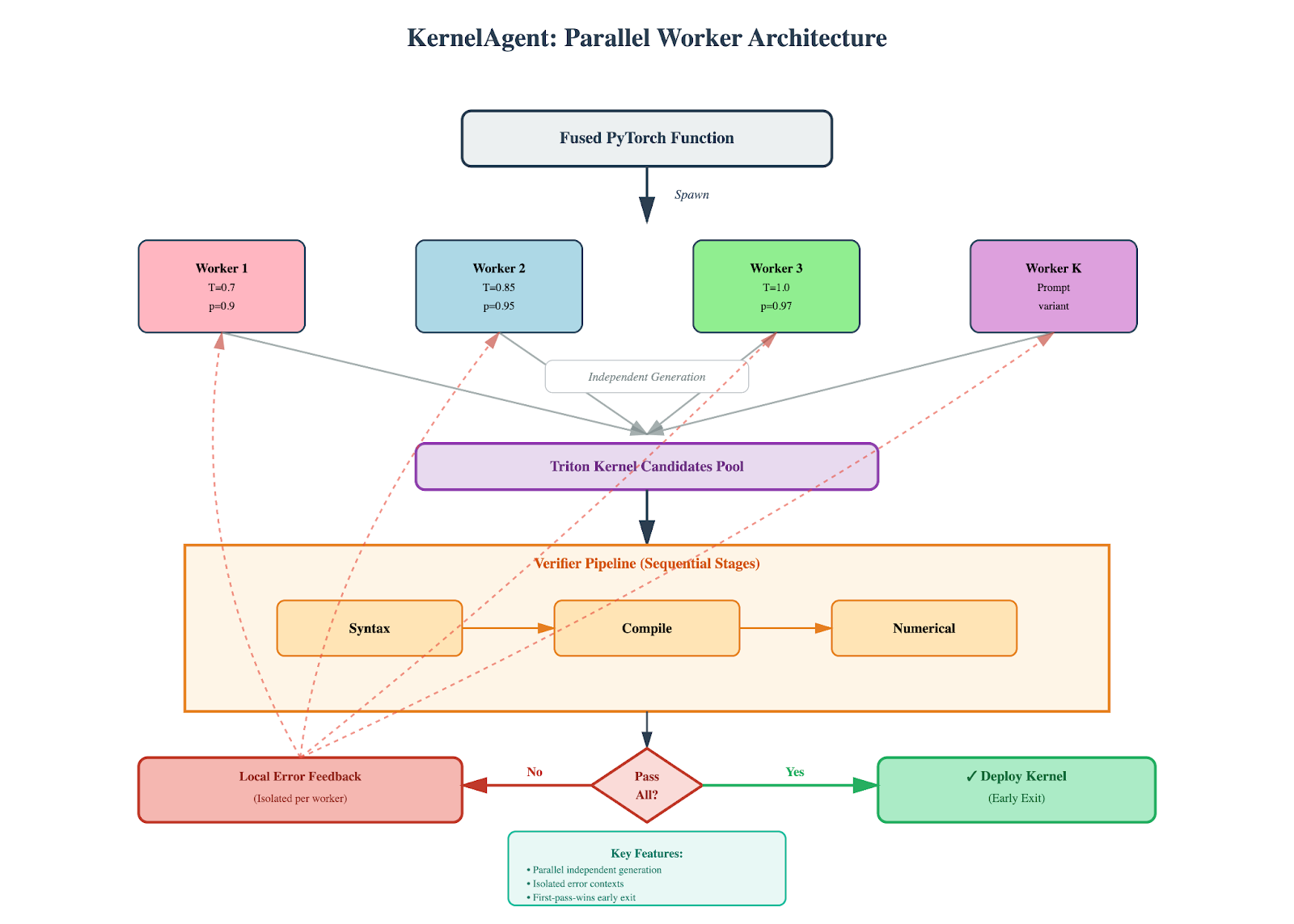
Figure 3: KernelAgent spawns parallel workers with diverse sampling parameters to generate Triton kernels. Each candidate goes through verification stages (Syntax, Compile, Numerical). Failed candidates trigger isolated error feedback to their originating worker only – no context pollution. The first candidate to pass all stages deploys immediately and cancels remaining workers. This achieves parallel exploration with isolated contexts and early exit.
The parallel approach:
Generate N kernel seeds with the same prompt but diverse temperature settings (0.8, 0.9, 1.0, etc.). Spawn N workers (default 4), each running an isolated refinement loop in its own working directory. Different temperatures lead workers to explore different optimization strategies—some conservative, some exploratory.
Key mechanisms:
1. Local error feedback prevents context pollution
Each worker maintains its own working directory and per-round history. When Worker 2 hits a compile error, only Worker 2’s next iteration sees it – error context stays local. Workers write kernel.pyandtest_kernel.pyto their own workdir, execute the test via subprocess, and track results independently. Other workers continue with clean contexts.
2. Early termination saves compute
A centralized manager monitors a result queue for completion events. The moment any worker reports success (exit code 0 from test subprocess), the manager sets a shared success event to signal all workers to stop, then joins/terminates them. The first kernel to pass all verification stages wins; remaining workers are terminated immediately.
Deep agent principle: Grounded tool use
Workers execute real Python/Triton code in isolated subprocesses. Each worker generates both the Triton kernel implementation and its validation harness, then runs the validation as an independent subprocess. Triton’s JIT compiler automatically compiles the kernel to PTX when the test harness first calls it – compilation happens implicitly during test execution, so any syntax or compilation errors surface as test failures with non-zero exit codes.
The validation harness compares kernel output against the PyTorch reference implementation. Success means exit code 0 from the subprocess; failure captures stderr for the next refinement round. The framework doesn’t judge correctness – it simply executes the code and reports what happened. This grounding in actual execution eliminates the “simulated judging” problem where an LLM might hallucinate that broken code works.
Reference: Fuser/dispatch_kernel_agent.py, triton_kernel_agent/manager.py, triton_kernel_agent/worker.py, triton_kernel_agent/agent.py
Stage 4: ComposerAgent – End-to-End Kernel Stitching
The composer uses the LLM to take verified Triton kernels and integrate them into a complete, testable module.
Input: Collection of verified Triton kernels from Stage 3, subgraphs.json, and original problem
Composition Process:
- Prompt LLM: Provide original problem code, compact subgraph summary, and successful kernel files
- Generate integration: LLM synthesizes end-to-end Triton implementation with required structure
- Optional verification: Execute composed kernel and validate via PASS/sentinel detection
- Package artifacts: Write the composed implementation and verification metadata to the output directory
Generated Structure:
The LLM produces a complete Python module containing:
One or more Triton kernels: Each decorated with @triton.jit, implementing the fused operations. For example, one kernel might handle conv-bn-tanh-pool fusion, while another handles normalization.
A top-level wrapper function: Named kernel_function(...)that matches the original model’s inputs. This wrapper allocates output tensors, configures grid dimensions, and launches the Triton kernels in sequence, orchestrating data flow between them.
A self-test harness: The test function seeds random number generators, constructs the original PyTorch reference, calls the composed kernel function, and validates parity using torch.allclosewith tolerances from prompt guidance. These dtype-specific tolerances account for accumulation of rounding errors inherent to each precision level, matching PyTorch’s own internal testing standards. On success, it prints “PASS” and exits with code 0.
Validation Process:
The composer ensures that individually correct kernels compose correctly – verifying that the whole equals the sum of parts. Python validates by executing the composed module as a subprocess and checking for “PASS” in stdout, plus exit code 0. This grounds the verification in actual execution rather than simulated or LLM-judged correctness.
Output Artifacts:
Success is recorded with verification status, timing, and artifact paths. The complete composed module becomes the final deliverable, ready for deployment or further
Reference: Fuser/compose_end_to_end.py
Deep Agent Principles in Practice
Contracts and Interfaces Enable Automation
The core insight: rigid contracts unlock autonomous operation. When every interaction point has a typed interface – operation types, shapes, dtypes, expected outputs – the system can run without human oversight. Ambiguity kills automation.
We encode these contracts everywhere. Subgraph specifications flow from the extractor to the dispatcher to individual kernel agents, each knowing exactly what the next expects. Critical Triton constraints get baked into templates rather than hoping the LLM remembers them. This moves correctness from “hope the prompt works” to “structurally impossible to violate.”
The magic happens when you compose these contracts. A kernel that passes its individual test still needs to compose correctly with others. The final verification isn’t just “does this kernel work?” but “does the entire pipeline produce the same output as the original PyTorch?” That end-to-end contract is what makes the system trustworthy.
Durable State and Memory
Every attempt persists to disk for debugging. We keep logs, prompts, generated code, error traces, and timing data. Each worker writes per-round snapshots capturing its local evolution. The orchestrator streams events in real-time. This level of robust logging is required for the stability to run 250 tasks overnight and understand what happened to each one.
More importantly, persistence enables debugging. Failed attempts aren’t thrown away – engineers can grep through logs to identify patterns and adjust the system accordingly. The learning is currently manual (analyzing logs, updating prompts) rather than automatic, though the roadmap includes future retrieval of successful patterns.
Reliability Through Isolation
Production systems need boundaries. Each worker runs in its own directory, executes tests in subprocess isolation, and maintains local error context. When Worker 2 hits a compilation error, that error stays local to Worker 2’s refinement loop. Workers 0, 1, and 3 continue exploring with clean contexts.
This isolation extends beyond error handling. Resource limits prevent runaway processes. Timeouts catch infinite loops. Cleanup handlers ensure no leaked GPU memory. These aren’t features you add later—they’re fundamental to making the system work at scale.
The beautiful thing about isolation: it makes debugging tractable. When something fails, you know exactly which worker, which round, which prompt led to that failure. The error didn’t cascade through shared state or pollute other attempts. You can replay that exact sequence and understand what went wrong.
Observability Without Overwhelm
The system generates a lot of data—prompts, code, errors, timings. The trick is making this data useful without drowning in it. We use structured logging (JSONL for streaming, JSON for snapshots) that’s both human-readable and machine-parsable.
You can grep for specific events, aggregate error types, trace a single worker’s journey, or compute success rates across different temperature settings. The logs tell a story: how the system explored the solution space, what worked, what didn’t, and why.
Batch summaries provide the 30,000-foot view—pass rates, average rounds, worker utilization. Detailed logs give you the microscope when you need it. This layered observability means you can quickly assess overall health, then drill down into specific failures without getting lost in the noise.
Self-Evaluation That Actually Helps
Refinement isn’t about generic “try again” prompts. When a worker’s test fails, the actual error output – compilation messages, numerical mismatches, timeout indicators – becomes part of the next prompt. This structured feedback guides the LLM toward specific fixes rather than random exploration.
The framework doesn’t judge correctness abstractly. It runs the code, captures what happened, and feeds that reality back. A compilation error about tensor devices gets different treatment than a numerical mismatch in the output. Workers maintain local history so each refinement builds on previous attempts, creating a learning trajectory within each worker’s context.
The key is keeping feedback concrete and actionable. Instead of “the kernel doesn’t work,” the worker sees “compilation failed at line 23: tensor dimension mismatch.” Instead of “wrong output,” it sees “max error: 0.0023 at position [15, 7].” This specificity turns debugging from guesswork into targeted problem-solving.
Results
Coverage
We measure success simply: does the generated code actually work? A task passes when the Triton kernel compiles, runs without crashing, and produces outputs numerically equivalent to PyTorch within bounded tolerances.
| Level | Tasks | Description | Coverage |
| L1 | 100 | Single operators | ✅ 100% |
| L2 | 100 | Fusion patterns | ✅ 100% |
| L3 | 50 | Full architectures | ✅ 100% |
Performance metrics (speedup, latency) will be covered in our follow-up post. This work establishes correctness first.
How We Validate
No simulations. No “the LLM thinks this works.” We execute real code.
Two levels of validation:
Every worker writes both a Triton kernel and its test harness to disk, then runs the test in a subprocess within a fresh working directory. For individual kernels, exit code 0 means success. For the full pipeline, we need exit code 0 AND “PASS” in output. When tests fail, we capture stderr and try again. The test compares against PyTorch with tolerances appropriate for the dtype – tighter for fp32, looser for fp16.
What prevents cheating?
Enforcement happens mainly through Triton’s compiler: @triton.jit functions cannot contain PyTorch operations – they’ll fail to compile. This prevents high-level API usage in kernels. We add wrapper-side checks too. For testing, we rely on random inputs and subprocess execution. However, we trust the LLM-generated test harness itself—we don’t statically analyze it for cheating.
The compositional validation matters: individual kernel correctness doesn’t guarantee the full pipeline works. Integration exposes shape mismatches, accumulating errors, and semantic misunderstandings that individual tests miss.
Everyone’s Learning the Same Lesson
Verification beats one-shot generation, but architecture is the multiplier. This system wires executable feedback into every stage and lets the first passing path end the search. Multiple workers explore in parallel, execute candidates, and cancel peers the instant one passes. Less context burn, lower latency, more robustness. The numbers matter, but the loop matters more: execute, read the error, fix, stop the moment something works.
This isn’t just about kernel generation. It’s about what happens when you stop asking “can the LLM do this?” and start asking “how do we structure this so the LLM can’t fail?” KernelFalcon achieves 100% correctness on KernelBench, not because we have a better model, but because we built a better loop.
Structure the problem, don’t prompt harder. That’s the real lesson. Deep agents aren’t about deeper models – they’re about deeper systems.
Acknowledgements
This work was done in collaboration with Sijia Chen, Bert Maher, Joe Isaacson, Lu Fang, Wenyuan Chi, Jie Liu, Alec Hammond, Zacharias Fisches, Mark Saroufim, Warren Hunt, Richard Li, Jacob Kahn, Emad El-Haraty and Ajit Mathews.
Citation
Please cite this work as:
Wang, Laura et al., "KernelFalcon: Deep Agent Architecture for Autonomous GPU Kernel Generation", PyTorch Blog, Nov 2025.