Introduction and Agenda
Large language models are now running into the scaling limits of attention. Even with highly optimized implementations, KV cache memory grows linearly with sequence length, and prefill latency rises quadratically. As workloads demand contexts of 128k tokens and beyond, new architectural approaches are needed.
Hybrid models like Qwen3-Next, Nemotron Nano 2, MiniMax-Text-01, Granite 4.0 are architectures that combine attention with alternatives such as Mamba or linear attention, offering a path forward. By mixing mechanisms, they preserve modeling quality while enabling efficient long-sequence inference. Recent work in the vLLM community has elevated hybrid models from experimental hacks in V0 to fully supported first-class citizens in V1.
This article explains how that transformation happened, why it matters, and what performance improvements developers can expect when deploying hybrid models on vLLM V1.
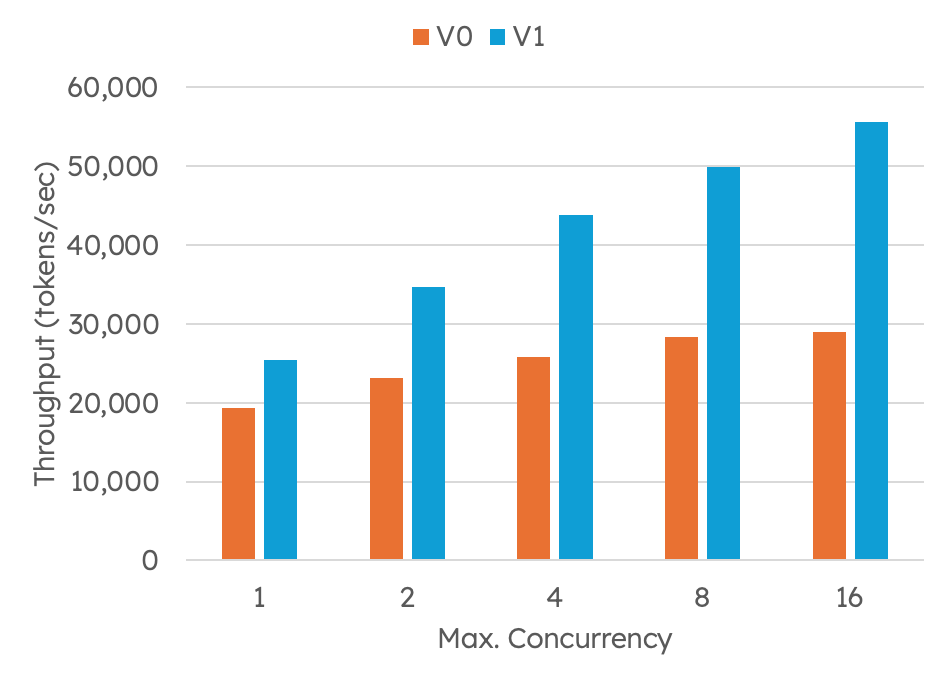
[FIGURE 1: Throughput improvement when moving from vLLM V0 to V1 for a representative hybrid model: granite-4.0-h-tiny, which is a 7B parameter model with 1B active]
Attention is All You Need?
Attention has become the backbone of large language models and remains exceptionally effective at capturing dependencies in natural language. Inference engines such as vLLM and its dependencies, including FlashInfer and FlashAttention, have optimized attention aggressively on modern GPUs. These optimizations include the paged KV cache, tiled and online softmax kernels, exploitation of tensor cores, integration of the Tensor Memory Accelerator (TMA), and extensive use of quantization to compress memory and increase throughput.
Despite these engineering advances, attention faces two fundamental limitations when scaling to very long sequences. First, the KV cache grows linearly with sequence length and batch size. Every generated token appends new key and value vectors, and as sequences extend to hundreds of thousands of tokens, this cache quickly becomes one of the largest memory consumers on the GPU. Second, the prefill stage, measured as the time-to-first-token (TTFT), is quadratic in prompt length. For prompts of 128k tokens or more, prefill latency increases dramatically, sometimes to the point of making inference impractical.
Attention remains state-of-the-art in many respects, but these scaling bottlenecks are the primary reason researchers and practitioners are exploring hybrid models.
Why Long Sequences Matter
Long sequences are not an abstract research goal but a requirement of real-world workloads.
One clear example is retrieval-augmented generation (RAG). In this pattern, a user query is paired with multiple retrieved documents, which are appended to the prompt. Depending on how many documents are retrieved and their size, prompt length can easily balloon from a few thousand tokens to tens or even hundreds of thousands.
Another driver comes from agentic patterns. In these workloads, the model operates in a loop where it generates some output, interacts with tools or systems, and then incorporates the result back into the context for further reasoning. Each turn extends the prompt, and as the number of tool calls grows, the sequence length can quickly reach very large scales.
Finally, reasoning patterns explicitly encourage long sequences. Prompts that instruct the model to “think step by step” or to generate intermediate reasoning chains leave all of those intermediate tokens in the context. This structured reasoning improves accuracy but greatly expands prompt size.
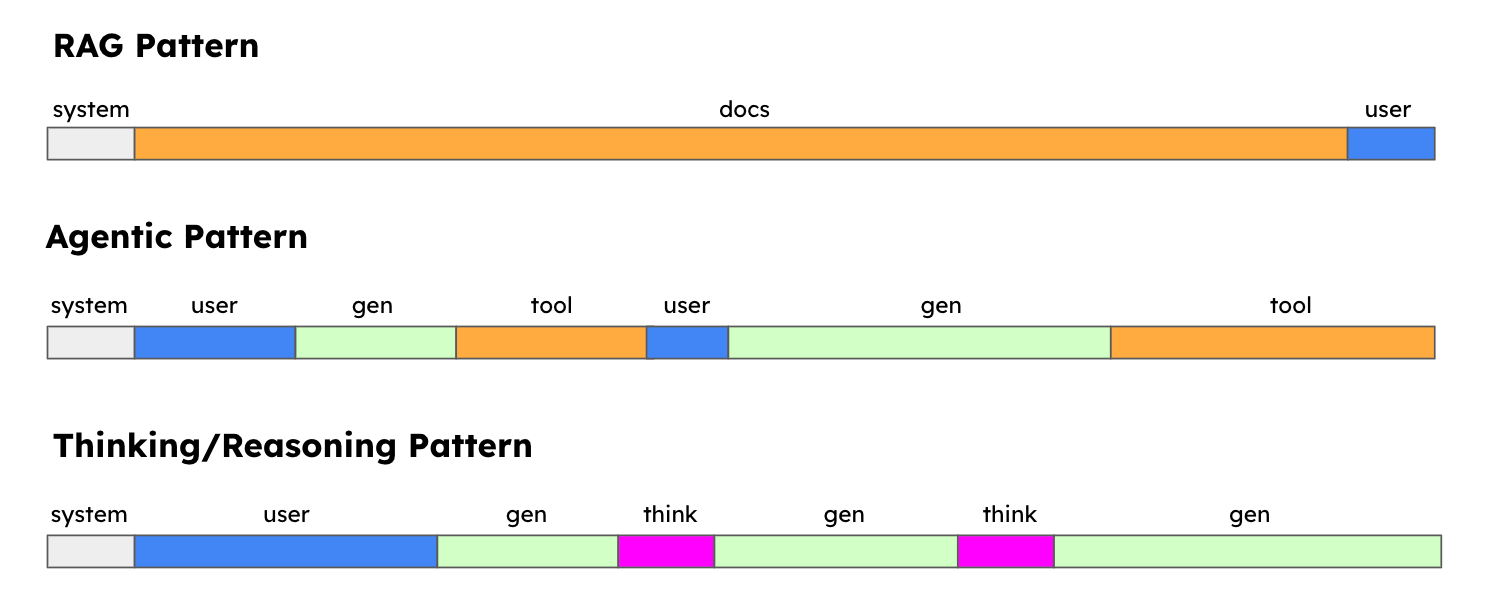
[FIGURE 2: Illustrations of RAG queries, agentic tool loops, and reasoning traces, each showing how the context length expands in different ways.]
Across these scenarios, hybrid models aim to deliver efficiency by combining attention layers with alternatives that scale better in memory and time, such as Mamba or linear attention.
A Brief History of State Space Models
State space models (SSMs) have a long and rich history, having found success in fields like control theory and dynamical systems. While they are historically formulated in the continuous-time domain, they also admit a discretized form that can be applied to sequences of tokens, as we are typically dealing with in LLM inference.
We’ll start from the discrete form of S4: a canonical SSM from 2021. The algorithm is illustrated in Figure 3. S4 maps an input sequence x of length T to an output sequence y through an internal latent state h. Unlike attention, which requires quadratic work for prefill, S4 is linear in sequence length, requiring only T updates for a sequence of length T. Just as importantly, the latent state h has fixed dimensionality N, which does not grow with sequence length. This makes S4 efficient to represent, particularly for long sequences where KV cache costs explode.
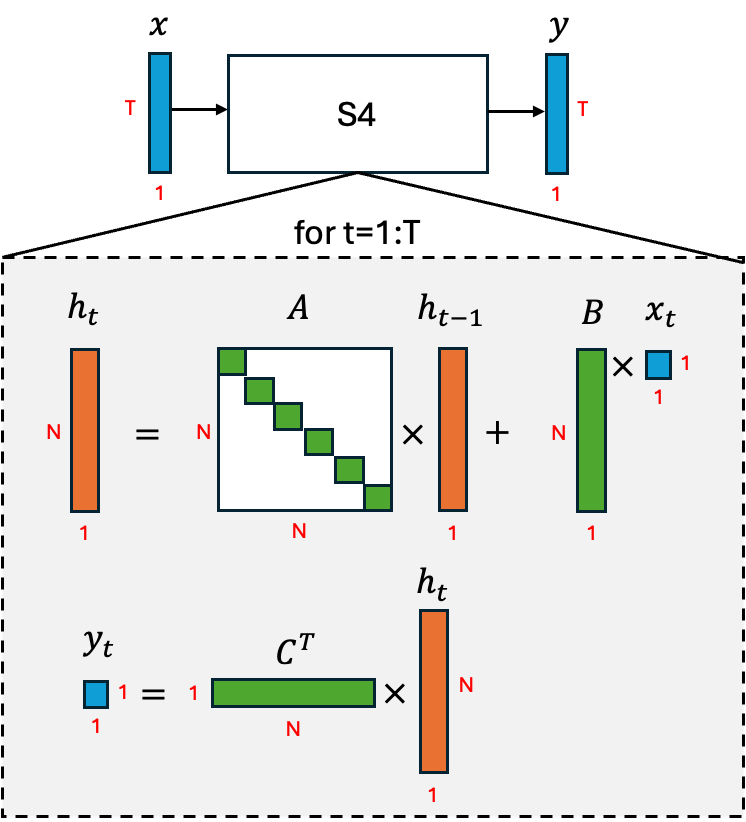
[FIGURE 3: S4 recurrence diagram showing per-timestep update with matrices A, B, C, and latent state h.]
However, S4 struggled on tasks requiring selective copying of tokens or in-context reasoning. The recurrence structure captured dependencies but did not provide enough flexibility to handle these capabilities.
Enter Mamba-1 in 2023, which extended the S4 formulation by allowing matrices A, B, and C to vary at each timestep. This introduced the ability to selectively attend to different tokens, greatly improving performance on selective copying and reasoning tasks. Despite this, the inference performance of Mamba-1 still lagged behind that of attention on modern GPUs, because its parallel implementation did not make extensive use of matrix multiplications and thus could not exploit tensor cores effectively.
The tensor cores problem was solved when Dao and Gu dropped the landmark Mamba-2 paper in 2024. This paper showed that (a) SSMs can in fact be formulated as a matrix transformation from input sequence to output sequence (as opposed to the for loop in Figure 3) and (b) introducing even more structure into the matrix A can lead to very efficient implementations, and (c) Mamba-2 is in fact equivalent to another type of attention variant: linear attention.
Linear attention was described by Katharopoulos et al. in 2020. The authors showed that approximating the softmax as a linear dot-product of kernel feature maps leads to a different type of attention mechanism: one that no longer scales quadratically with the sequence length. This observation kicked off a lot of research and led to many variants and twists on the core idea. Some noteworthy recent linear attention variants are Lightning Attention and Gated Delta Net, which are used by the Minimax-Text-01 models and Qwen3-Next models, respectively.
Hybrid Models: The Landscape in vLLM V1
With these mechanisms in place, the field has seen a surge of hybrid architectures that combine full attention with Mamba or linear attention variants. The rationale is clear: keep full attention for its modeling strength, while inserting Mamba or linear layers to improve efficiency at scale.
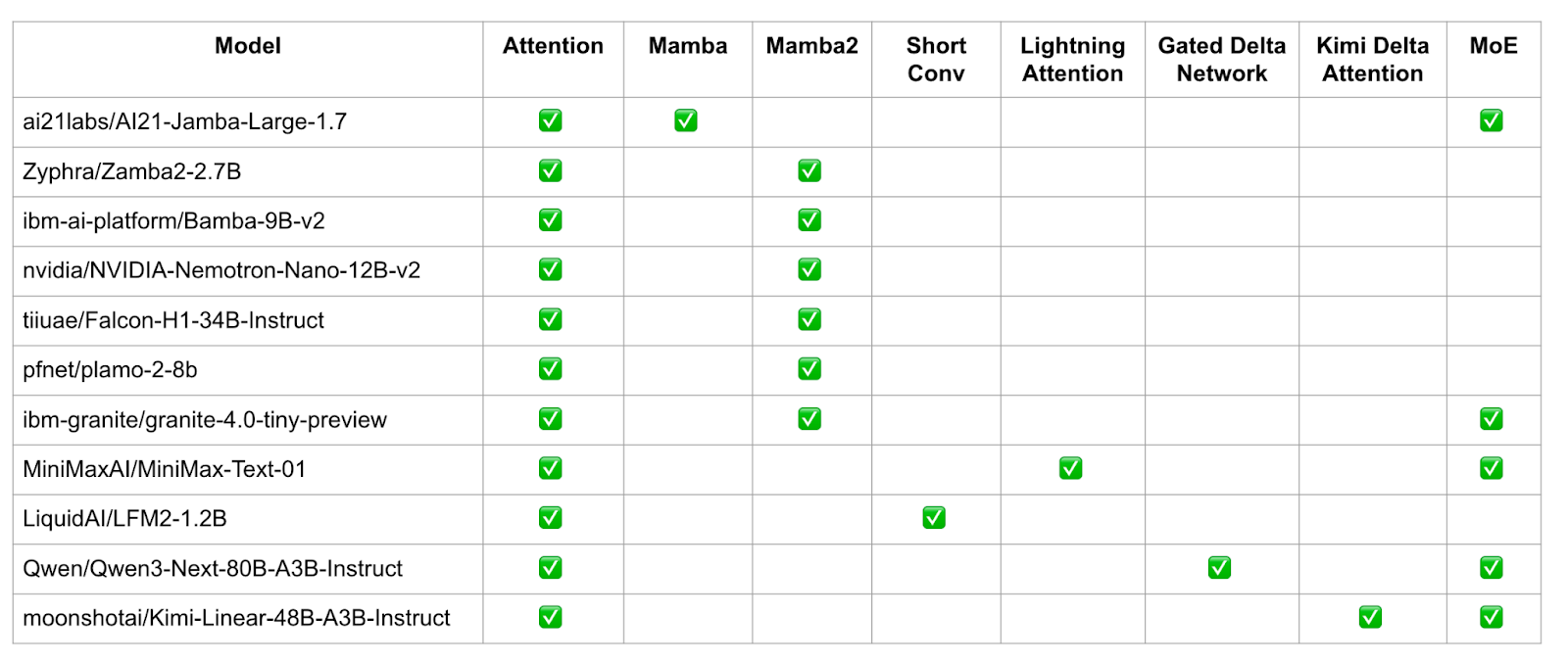
[FIGURE 4: Table of hybrid models supported in vLLM V1, highlighting attention, Mamba variants, linear attention, and MoE usage.]
In Figure 4, we provide the full list of hybrid models that are supported today in vLLM V1, indicating which kind of SSM or linear attention mechanism is used by each model. These models demonstrate that hybridization is not a niche experiment but an active design choice across organizations.
State Management for Hybrid Models
Supporting hybrid models in vLLM requires careful treatment of the state. Attention layers rely on a paged KV cache, organized into 16-token blocks, each consuming about 64 KiB. Mamba layers, by contrast, maintain a large, fixed-size state for each sequence, around 2.57 MiB, which is updated in place rather than appended to.
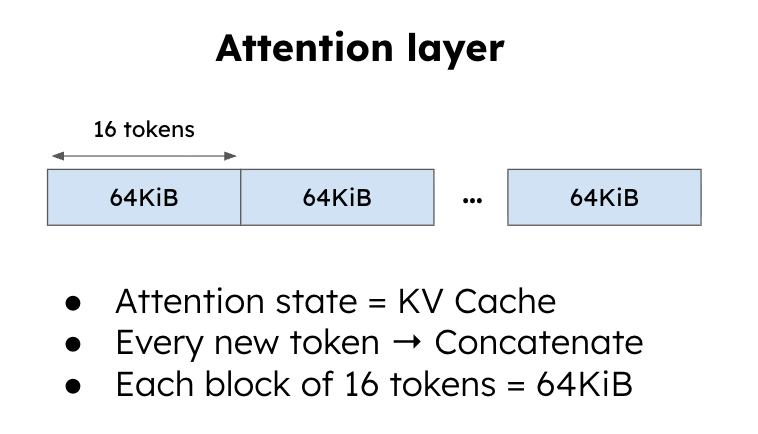
[FIGURE 5: KV cache blocks in attention, showing 16-token groups of ~64 KiB each. Numbers computed based on NVIDIA-Nemotron-Nano-12B-v2]

[FIGURE 6: Mamba state structure, showing one large per-sequence state updated in place. Numbers computed based on NVIDIA-Nemotron-Nano-12B-v2]
Although a single block of KV cache is smaller than a Mamba state, the relationship reverses at long contexts. For a 128k sequence, the KV cache can be nearly 200 times larger than the Mamba state, illustrating why hybrid approaches are so attractive.
Hybrid State Management in vLLM V0
In vLLM V0, hybrid support was achieved through a pragmatic but fragile hack. KV cache allocation was managed efficiently as blocks, but the Mamba state was allocated separately. Each Mamba layer had a state tensor per active sequence, sized by the user-defined parameter max_num_seqs.
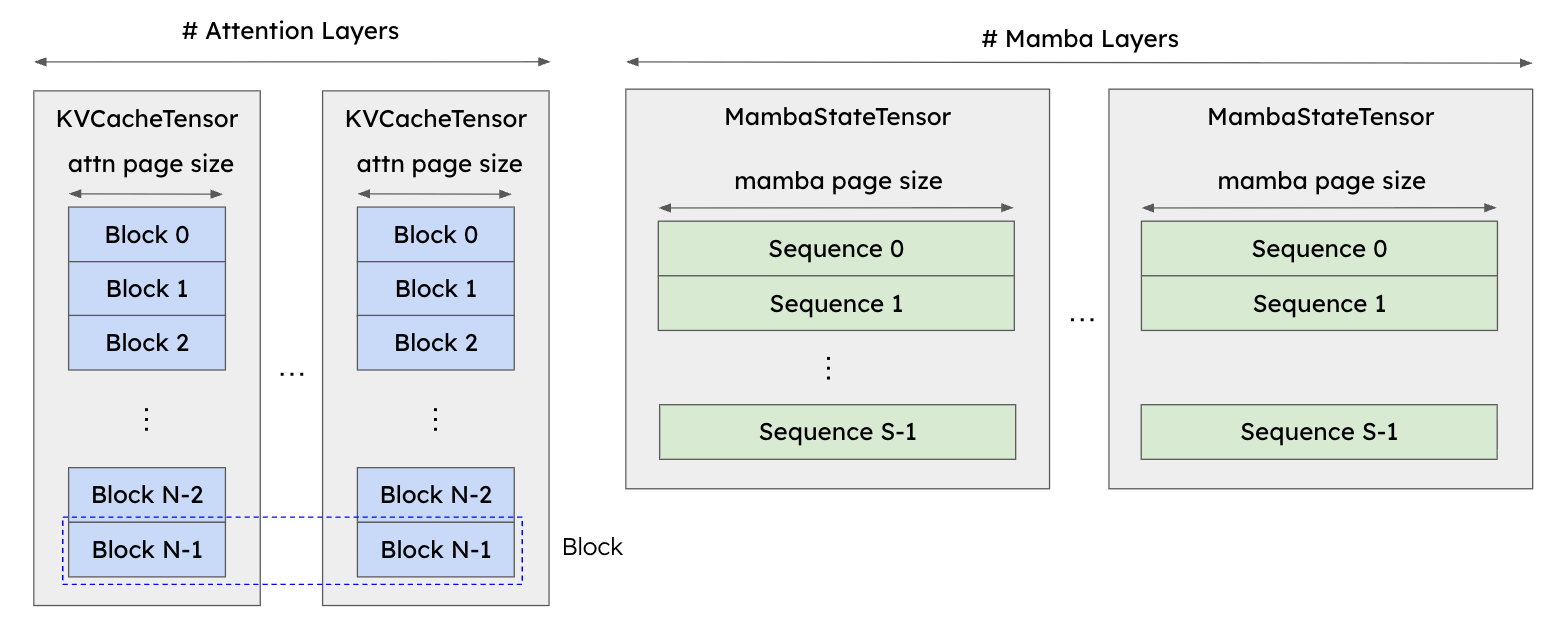
[FIGURE 7: V0 architecture showing paged KV cache for attention and separate per-sequence Mamba state tensors.]
This approach forced users to guess the right value of this parameter to avoid crashes. Setting it too high risked CUDA out of memory errors, while setting it too low reduced concurrency. The result was poor usability and frequent complaints from developers working with new hybrid models.
Unified State Management in vLLM V1
In V1, hybrid model support was rebuilt around a unified allocator that manages both KV cache and Mamba state. This design is not just elegant, but it also enables advanced features like prefix caching, KV cache transfer, and prefill/decode disaggregation. By bringing hybrid model support into the V1, they can now also benefit from new optimizations such as torch.compile and improved scheduling.
But unified state management did not work out of the box for Mamba-based hybrid models. While support for “hybrid” state did already exist in V1, through the hybrid memory allocator, it only supported models like Gemma 3, Llama 4, and gpt-oss that mix full attention layers with sliding window attention layers.
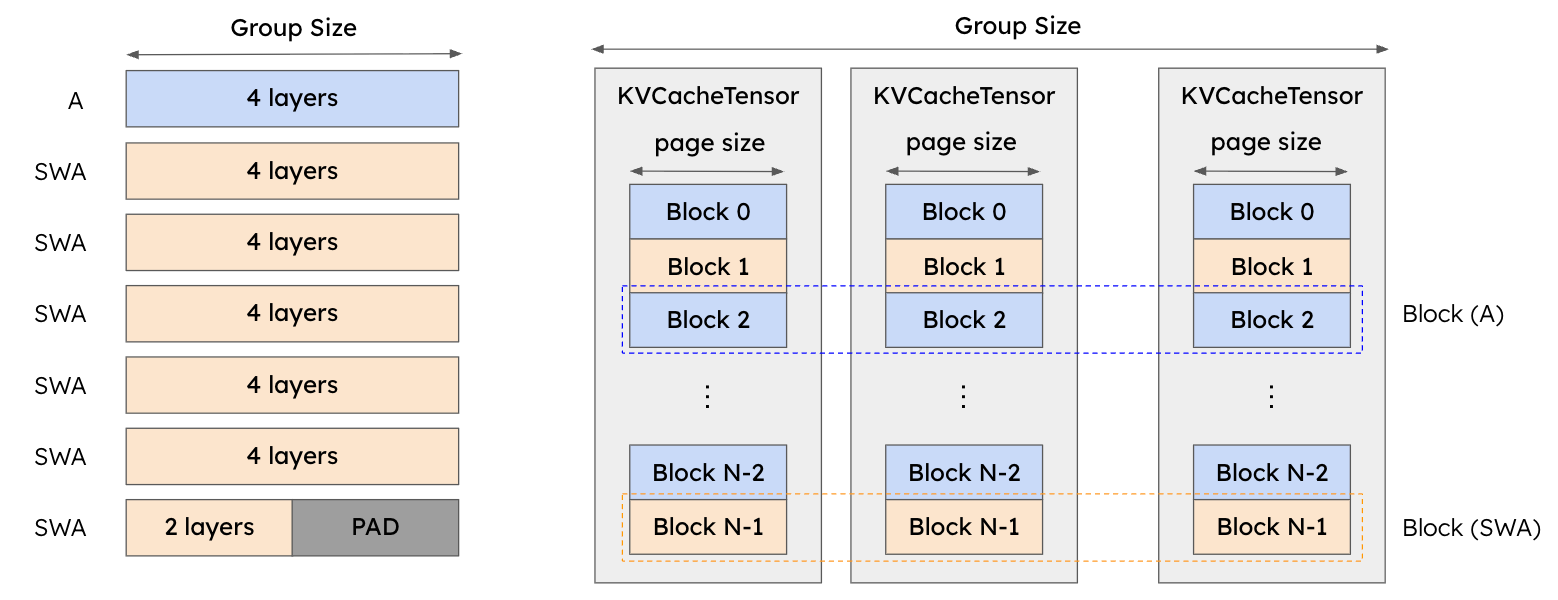
[FIGURE 8: Example of KVCacheGroups in V1, where groups of similar layers share cache tensors to simplify memory management.]
The behaviour of the hybrid memory allocator is illustrated in Figure 13 for a model with full attention (A) and sliding window attention (SWA). The allocator groups layers of the same type into KVCacheGroups. The state of eachKVCacheGroupsis stored in an interleaved way across several KVCacheTensors, forming a block. Crucially, blocks corresponding to different groups share the same KVCacheTensors. In order to facilitate simple memory management, we must ensure that the block size (in tokens) and thus the page size is the same for all KVCacheGroups.
Adapting the Allocator for Mamba
Mamba complicates things because the size of its state pages is much larger than that of attention blocks. To unify them, we needed to relax the requirement that all groups use the same block size. Instead, attention block sizes are automatically increased until they align with Mamba’s page size. At the same time, Mamba pages are padded slightly in order to make the page sizes exactly equal. This process of page alignment is illustrated in Figure 9 and Figure 10 for a representative model: NVIDIA-Nemotron-Nano-12B-v2.

[FIGURE 9: Before page alignment – attention page size is dramatically smaller than mamba page size]
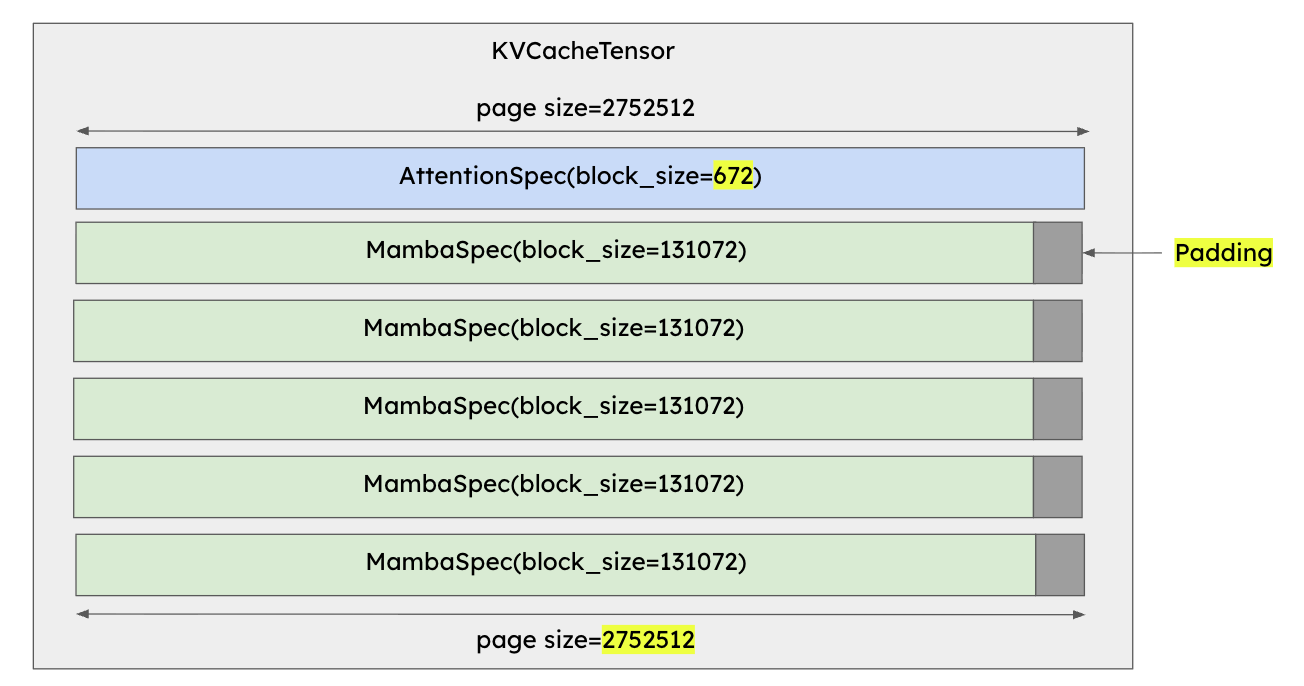
[FIGURE 10: After page alignment – attention page size and mamba page size are exactly equal]
While unusual block sizes (such as 672 tokens per attention block) might appear inefficient, empirical testing shows little impact on performance, likely because attention contributes less to runtime when Mamba or linear layers dominate.
While some attention kernels support arbitrary block sizes (e.g., the kernels provided by the Triton attention backend), others, such as the TRT-LLM kernels provided by FlashInfer, do not. To overcome this limitation, we recently landed the capability to decouple the block size used by the KV cache management from the block size seen by the kernel. This allows managing hybrid state in a clean way, while still using TRT-LLM kernels to get the best performance on Blackwell GPUs.
Striding For Perfection
When debugging the initial V1 integration, we discovered a subtle problem that arises due to the Mamba KVCacheGroups sharing the same KVCacheTensors as the attention KVCacheGroups. Each group uses a different view into the same tensor, and these views look quite different, as illustrated in Figure 11.
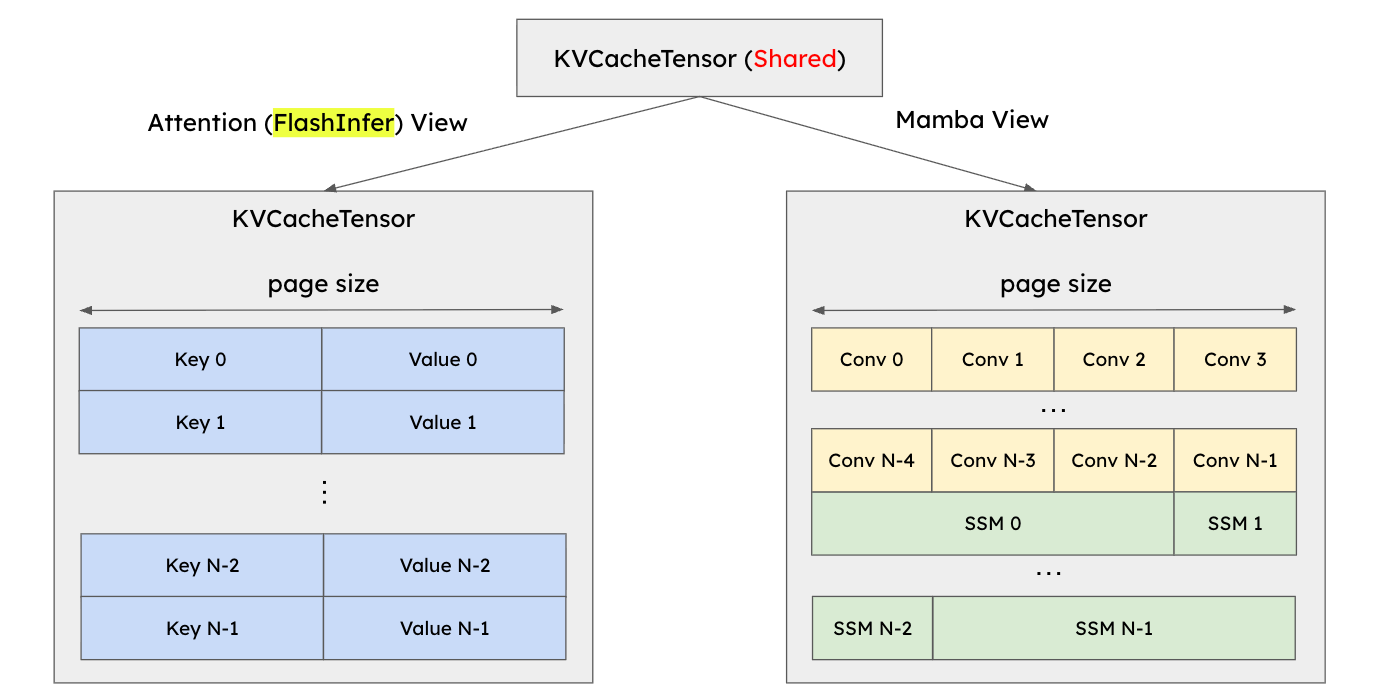
[FIGURE 11: Before changing strides: attention and Mamba views are not compatible]
Each attention page comprises the key tensor and the value tensor, and when using the FlashInfer backend, the keys and values are interleaved in GPU VRAM such that the data is stored in a block-by-block manner. On the other hand, Mamba pages comprise the convolution state (Conv) and the state-space model state (SSM), and by default they are *not* interleaved. Thus, we store the Conv state for all blocks, followed by the SSM state for all blocks. This meant that writing to one block via the Mamba view would lead to data corruption for a different block in the attention view.
To solve this, we changed the way the Mamba state tensors are strided to ensure that the two views are entirely compatible. This approach is shown in Figure 12. We can see that attention blocks and Mamba blocks are now perfectly aligned, and no data corruption can occur.
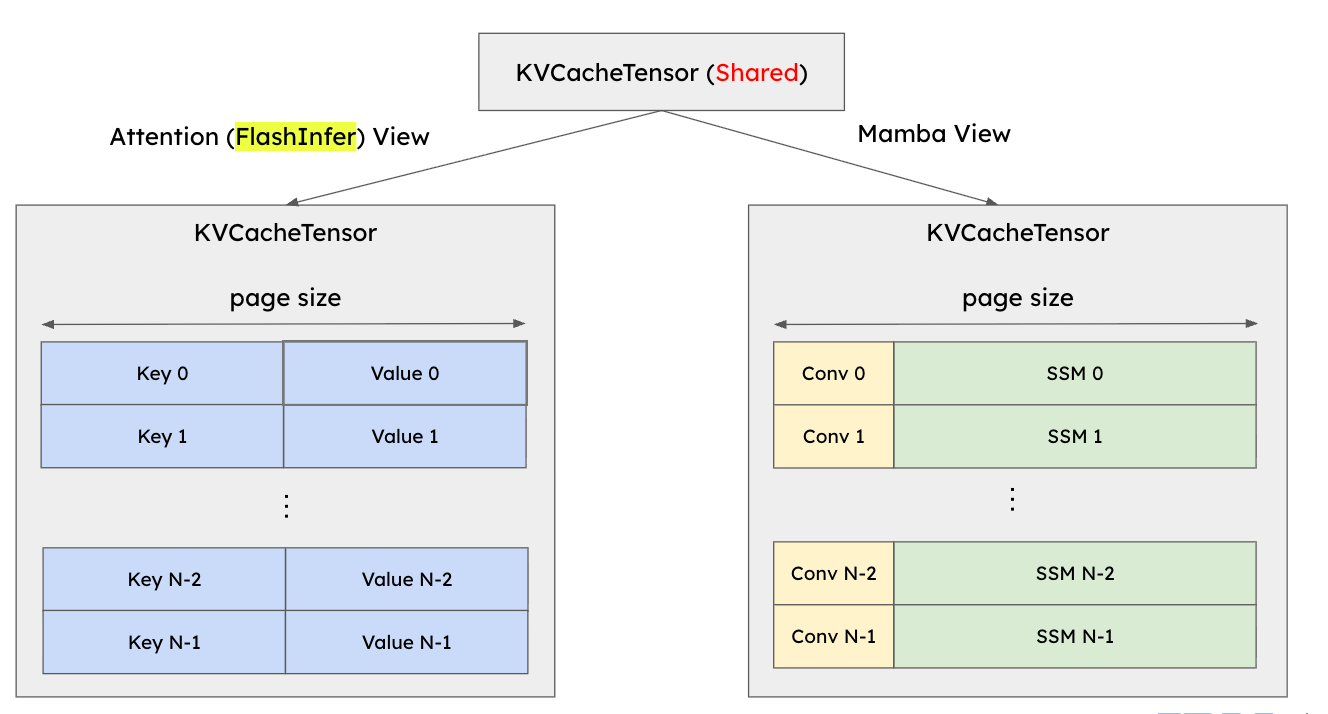
[FIGURE 12: After changing strides: attention and Mamba views are not compatible]
Some attention backends like FlashAttention actually do not store the keys and values in the block-by-block way that is illustrated above. However, we found that it was possible to change the strides again, but this time for the attention view, to ensure that FlashAttention can also be used as a backend for hybrid models. FlashAttention is the default attention backend for vLLM in many situations, so this was another important step towards being able to deprecate V0.
Performance Engineering to Deprecate V0
Several other changes were required to fully deprecate V0 for hybrid models. A lot of modeling code was refactored, and a number of performance optimizations were needed to ensure that we could beat V0 performance.
In particular, many of the Mamba and linear attention variants are implemented using Triton kernels. Triton is great for developing these new models because it increases productivity and works well across different platforms, but it has a known issue with CPU launch overheads. These overheads can severely affect performance in the low-latency regime (e.g., inter-token latencies for small batches and/or models with a small number activated parameters).
To overcome this, we implemented staged support for CUDA Graphs in the Mamba backends: beginning with eager execution, then piecewise graphs, followed by full graphs for decode-only batches, and eventually a hybrid scheme that combines full graphs for decode with piecewise graphs for mixed batches (FULL_AND_PIECEWISE). This final optimization allowed us to recover V0 performance and significantly beat it in some scenarios. By enabling FULL_AND_PIECEWISEby default, we were able to finally enable V1 by default for hybrid models, and start to strip out the V0 code.
Finally, prefix caching is also now supported for hybrid models that use Mamba-2, although it is currently in an experimental state. If you are interested, please give it a try and open an issue if you encounter problems.
Benchmark Setup
Benchmarks were performed on vLLM v0.10.2, the last release supporting hybrid models in both V0 and V1, allowing direct comparison. The server ran on H100 GPUs, and clients generated random inputs of 32k length with 128-token outputs, sweeping concurrency levels.
vllm serve $MODEL --trust-remote-code vllm bench serve \ --model $MODEL \ --dataset-name random \ --random-input-len 32768 \ --random-output-len 128 \ --max-concurrency $MAX_CONCURRENCY \ --num-prompts $((10 * $MAX_CONCURRENCY)) \ --ignore-eos --seed $MAX_CONCURRENCY
We ran benchmarks for two models: NVIDIA Nemotron-Nano-12B-v2 and IBM granite-4.0-h-tiny. We choose these models because they are supported by both vLLM V0 and V1, whereas models that were added more recently (like Qwen3-Next and Kimi Linear) are only supported in V1. Please see Figure 4 for a full list of hybrid models supported in V1.
Results: NVIDIA Nemotron-Nano-12B-v2
For this dense hybrid model, V1 generally outperformed V0 in both TTFT and ITL, although different scheduling dynamics between the two versions sometimes led to trade-offs. Throughput improvements were consistent though, except at very low concurrency, where CPU overhead in Mamba kernels caused V1 with PIECEWISE to actually perform worse than V0. However, we can see that V1 with FULL_AND_PIECEWISE resolves this issue. Overall, throughput gains ranged from 2 percent to 18 percent.
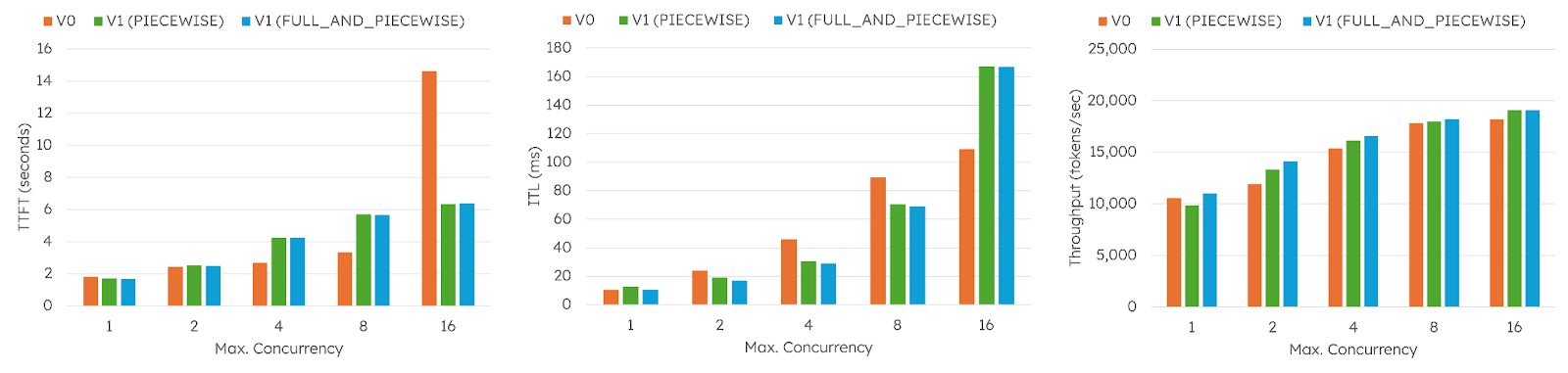
[FIGURE 13: Nemotron-Nano-12B-v2 benchmark results comparing V0 and V1 with PIECEWISE and FULL_AND_PIECEWISE CUDA Graphs.]
Results: granite-4.0-h-tiny
granite-4.0-h-tiny is a 7B MoE model with 1B active parameters. Models like this can operate at relatively low-latency, making CUDA Graphs even more critical. At low concurrency, V1 PIECEWISE is significantly worse than V0, but V1 FULL_AND_PIECEWISE consistently delivered large throughput improvements, up to 91 percent in some cases, while also lowering latency across TTFT and ITL.
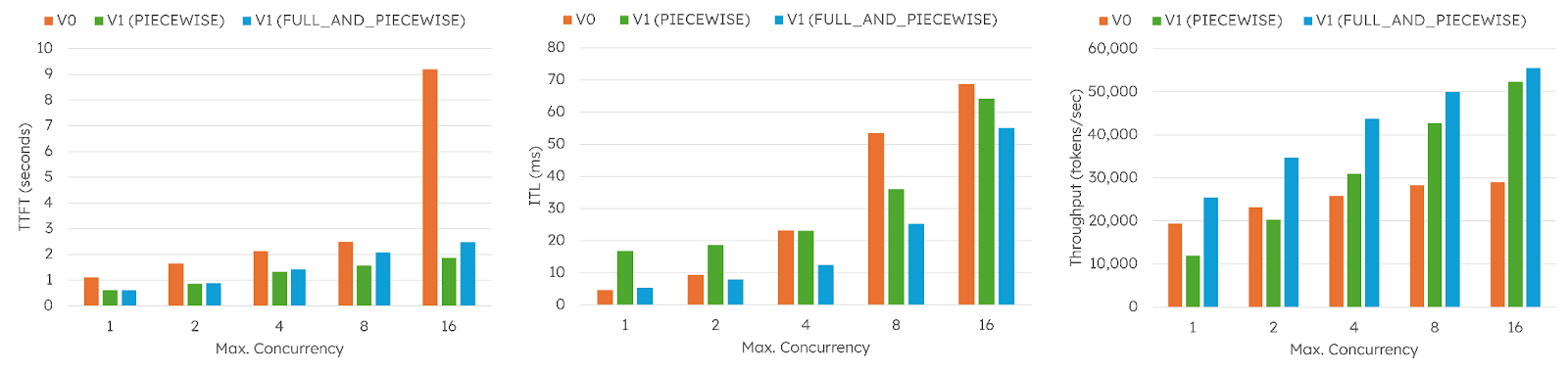
[FIGURE 14: granite-4.0-h-tiny benchmark results showing substantial throughput gains when using FULL_AND_PIECEWISE]
Conclusion
Hybrid models are no longer an edge case. With vLLM V1, they are fully integrated into the inference engine, benefiting from unified memory allocation, CUDA Graph optimizations, and compatibility with advanced features like prefix caching and KV transfer.
For developers, the results are clear: hybrid architectures scale to longer contexts without exhausting memory, and by graduating them to V1, we were able to reduce prefill and decode latency, and achieve significant throughput gains, especially for models with MoE layers.
Hybrid models are now practical tools for building enterprise-ready AI systems. By making hybrid models first-class citizens, vLLM ensures that the open source community can keep pace with the next generation of large-scale, long-context workloads.