Introduction: Empowering the Next Generation of AI Builders
We are excited to announce a partnership between the PyTorch Team at Meta, leading Monarch, and Lightning AI, that combines the power of large-scale training with the familiarity and ease of local development – integrated directly into Lightning Studio notebooks. This collaboration sets a new precedent for cluster-scale development, empowering the next generation of AI builders to iterate quickly and at scale from a single familiar tool.
The Opportunity: Seamless Distributed Training, Reimagined
Imagine harnessing the power of massive GPU clusters—all from the comfort and familiarity of an interactive notebook, without compromising on the rapid iteration cycles it enables. Monarch makes this vision a reality, enabling new workflows and creative possibilities.
Historically, development on large-scale clusters involves a lengthy iteration process. Each code change requires users to re-allocate, rebuild, and redeploy their workflows from scratch. Monarch directly attacks these iteration bottlenecks with a generic language for distributed computing. This new framework enables users to not only stay connected and develop directly on their clusters, but also reason about their workflows from a single local training script.
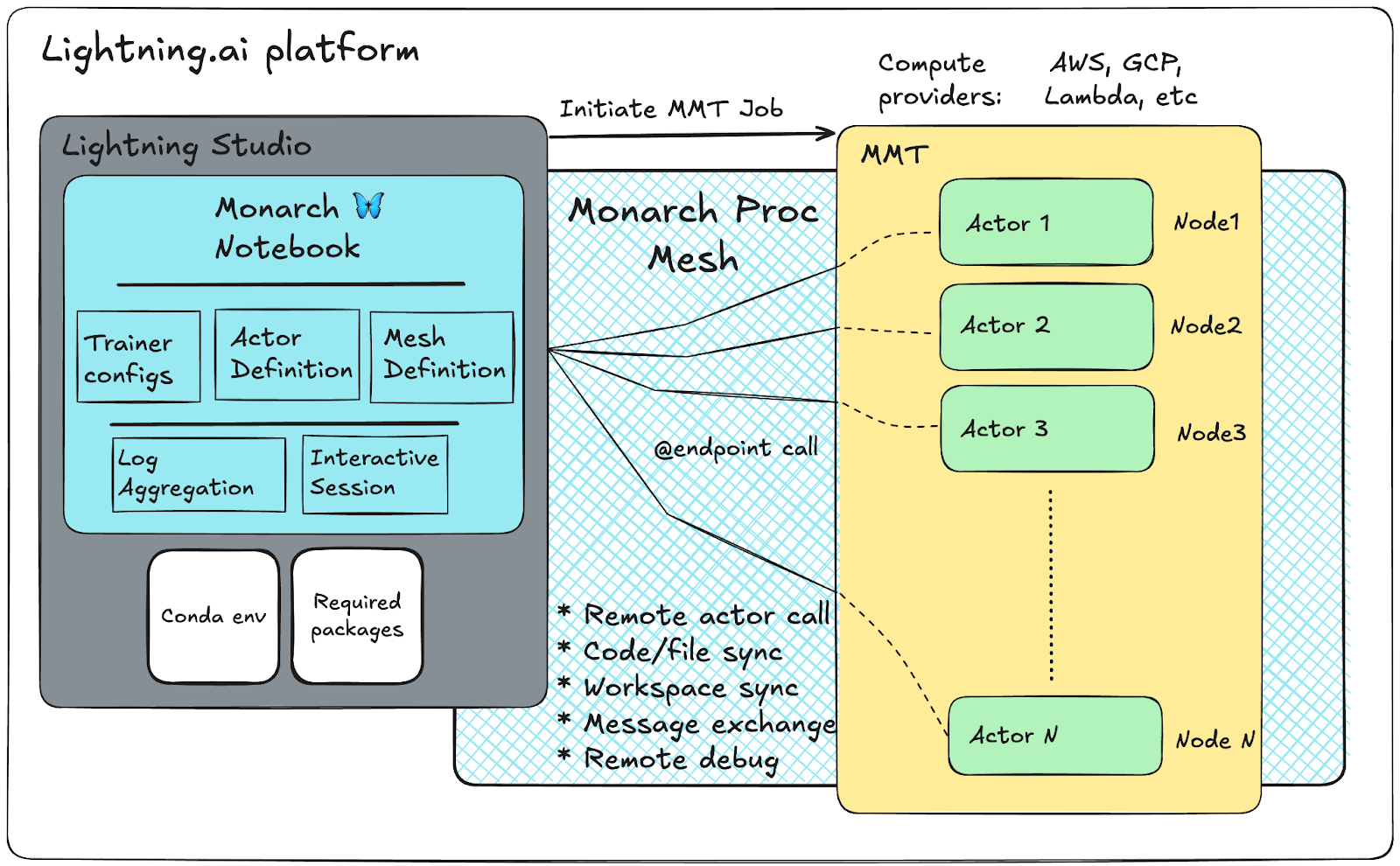
In this collaboration with Lightning AI, we showcase the power of such a script by integrating directly with the Lightning AI platform and its Multi-Machine Training (MMT) app. Lightning MMT allows users to schedule large-scale jobs asynchronously, taking care of provisioning and configuring training-optimized computing environments from multiple cloud vendors such as AWS, Google Cloud Platform, Voltage Park, Nebius, and Lambda. Utilizing Monarch’s API’s, we bring the interactive development experience of Lightning Studios to the power of large-scale compute of Lightning MMT.
In this new workflow, resources are provisioned a single time through Lightning MMT. From there, users have direct control over the job’s lifecycle with the use of Monarch API’s. Since users are now in direct control of the cluster’s execution, code changes and unseen exceptions no longer require users to re-allocate a new cluster. Users can add in forgotten print statements, change model configurations, or even the execution flow, all from the familiarity of an interactive notebook and within the context of a single allocation. Monarch’s API provides an interface built around remote actors with scalable messaging. Actors are grouped into collections called meshes, where messages can be broadcast to all members.
This simple and powerful API allows users to imperatively describe how to create processes and actors, making distributed programming intuitive and accessible.
from monarch.actor import Actor, endpoint, this_host # spawn 8 trainer processes one for each gpu training_procs = this_host().spawn_procs({"gpus": 8}) # define the actor to run on each process class Trainer(Actor): @endpoint def train(self, step: int): ... # create the trainers trainers = training_procs.spawn("trainers", Trainer) # tell all the trainers to to take a step fut = trainers.train.call(step=0) # wait for all trainers to complete fut.get()
Monarch and Lightning: Three Game-Changing Capabilities
1. Persistent Compute & Effortless Iteration
With Monarch, your compute resources persist—even as you iterate, experiment, or step away. You can pick up right where you left off, every time.
When deployed with Monarch, compute nodes are run using Monarch’s process allocator. This process allocator has two simple jobs. First, routing any messages passed within the monarch ecosystem, and next spawning arbitrary process meshes of any shape. This simplification of a cluster’s responsibilities allows us to encapsulate the responsibilities of a node, creating a separation between the hardware that runs computation and the user’s runtime environment. As opposed to traditional methods of launching cluster scale workflows, the process allocator (and thus your allocation) survives any exceptions or disconnects from the user code, meaning it can be re-used across multiple iterations. Even if the client program finishes or crashes, the compute environment can remain alive, reducing manual intervention and improving reliability for interactive and long-running workloads.
Monarch’s core abstraction starts with the ability to allocate Process Meshes. Once processes are allocated, users can then utilize Monarch’s Actor model to deploy encapsulated units of python code. These actors behave much as servers themselves, which expose endpoints as communication primitives. These endpoints can be called asynchronously from other actors, or an arbitrary python process. This interface can easily be orchestrated to create multi-machine training programs.
import asyncio from monarch.actor import Actor, current_rank, endpoint, proc_mesh NUM_ACTORS = 4 class ToyActor(Actor): def __init__(self): self.rank = current_rank().rank @endpoint async def hello_world(self, msg): print(f"Identity: {self.rank}, {msg=}") # Note: Meshes can be also be created on different nodes, but we're ignoring that in this example async def create_toy_actors(): local_proc_mesh = proc_mesh(gpus=NUM_ACTORS) # This spawns 4 instances of 'ToyActor' toy_actor = await local_proc_mesh.spawn("toy_actor", ToyActor) return toy_actor, local_proc_mesh # Once actors are spawned, we can call all of them simultaneously with Actor.endpoint.call async def call_all_actors(toy_actor): await toy_actor.hello_world.call("hey there, from script!!")
2. Notebook-Native Cluster Management
Scale up to hundreds of GPUs and orchestrate complex distributed jobs—all within your Studio notebook. Monarch brings the power of the cluster to your fingertips, with the simplicity you expect from Lightning Studios.
Reserve your cluster through Lightning MMT by simply defining the required GPUs, number of nodes, and GPUs per node. After that, you can call your training actors through the defined process mesh.
from lightning_sdk import Machine, MMT, Studio studio = Studio() NUM_NODES = 16 NUM_GPUS = 8 # Install the MMT plugin befor running the actual job studio.install_plugin("multi-machine-training") # Machine with T4 GPUs # machine_type = getattr(Machine, f"T4_X_{NUM_GPUS}") # Machine with L40S GPUs # machine_type = getattr(Machine, f"L40S_X_{NUM_GPUS}") # Machine with H100 GPUs machine_type = getattr(Machine, f"H100_X_{NUM_GPUS}") job = MMT.run( command=process_allocator, name="Multi-Nodes-Monarch-Titan", machine=machine_type, studio=studio, num_machines=NUM_NODES, env={ "CUDA_VISIBLE_DEVICES": "0,1,2,3,4,5,6,7", }, )
Once your training task is complete, you don’t have to worry about losing your resources. Monarch enables a notebook-native experience for managing your cluster. You can change configurations and files as needed; Monarch handles code and file sharing between your notebook and worker nodes. There’s no need to re-initiate your MMT job—just call your Actor with new configurations. Monarch reduces the multi-machine training experience from minutes per iteration to virtually no waiting time for consecutive launches.
3. Real-Time, Interactive Debugging
Debug live distributed jobs interactively, without interrupting your workflow. Monarch unlocks a new level of insight and control, accelerating discovery and innovation.
Monarch supports pdb debugging for Python actor meshes. Set up your actors with Python’s built-in breakpoints (breakpoint()) for debugging. When you run your Monarch program, you’ll see a table listing all actors currently stopped at a breakpoint, along with details such as actor name, rank, coordinates, hostname, function, and line number. From the monarch_dbg> prompt, you can dive into a specific actor/breakpoint using the attach command, specifying the actor’s name and rank.
from monarch.actor import Actor, current_rank, endpoint, this_host def _bad_rank(): raise ValueError("bad rank") def _debugee_actor_internal(rank): if rank % 4 == 0: breakpoint() # noqa rank += 1 return rank elif rank % 4 == 1: breakpoint() # noqa rank += 2 return rank elif rank % 4 == 2: breakpoint() # noqa rank += 3 _bad_rank() elif rank % 4 == 3: breakpoint() # noqa rank += 4 return rank class DebugeeActor(Actor): @endpoint async def to_debug(self): rank = current_rank().rank return _debugee_actor_internal(rank) if __name__ == "__main__": # Create a mesh with 4 "hosts" and 4 gpus per "host" process_mesh = this_host().spawn_procs(per_host={"host": 4, "gpu": 4}) # Spawn the actor you want to debug on the mesh debugee_mesh = process_mesh.spawn("debugee", DebugeeActor) # Call the endpoint you want to debug print(debugee_mesh.to_debug.call().get()) ~ $ monarch debug ************************ MONARCH DEBUGGER ************************ Enter 'help' for a list of commands. Enter 'list' to show all active breakpoints. monarch_dbg> list monarch_dbg> attach debugee 13 Attached to debug session for rank 13 (your.host.com) > /path/to/debugging.py(16)to_debug() -> rank = _debugee_actor_internal(rank) (Pdb)
Unlocking New Workflows and Collaboration
Monarch and Lightning AI together unlock new opportunities:
- Run long, exploratory experiments with confidence.
- Seamlessly transition from prototyping to large-scale training.
- Collaborate and debug in real time, directly in the notebook environment.
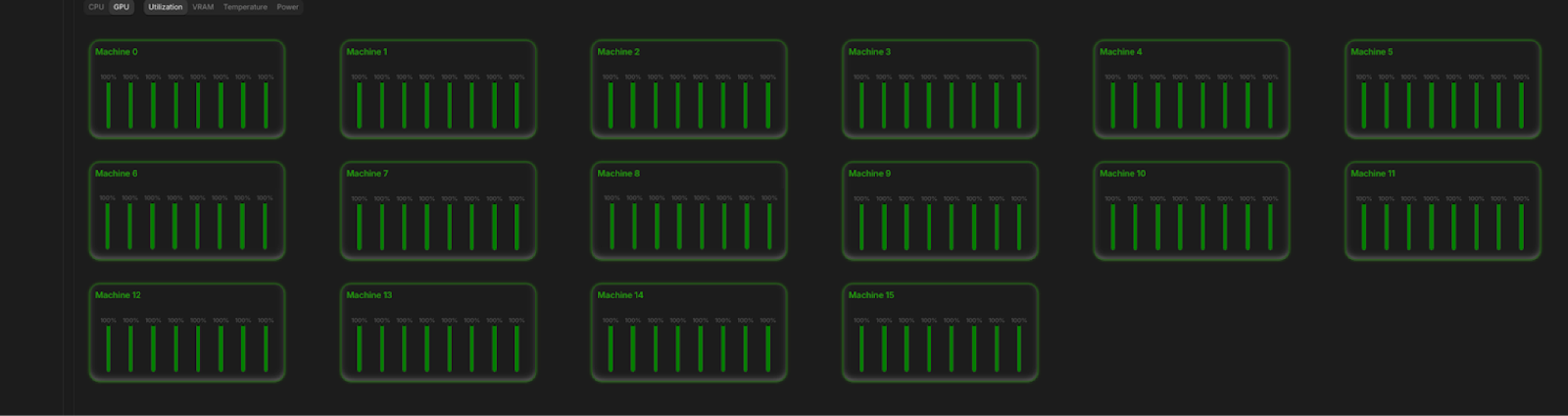
Hero Demo: 128 GPUs, One Notebook
See Monarch in action as we launch a 128-GPU training job from a single Studio notebook, powered by Torchtitan. Experience seamless scaling, persistent resources, and interactive debugging—all in one place.
Users can easily request the GPU requirements for the cluster, adjusting the number of nodes and GPUs per node as needed. Monarch takes care of the rest through Lightning MMT.
# Configuration for 128 GPUs NUM_NODES = 16 NUM_GPUS = 8
In this example, we wrap the classic SPMD (Single Program, Multiple Data) TorchTitan workload as an Actor within Monarch to enable pre-training LLMs (Llama3, Llama4, etc.) inside an interactive notebook at a scale of 128 GPUs. Once resources are reserved, the Titan Trainer is defined as a class inheriting from Actor.
from monarch.actor import ProcMesh, Actor, endpoint, current_rank from torchtitan.tools.logging import init_logger, logger from torchtitan.train import Trainer class TitanTrainerWrapper(Actor): def __init__(self, job_config: JobConfig): self.rank = current_rank().rank self.job_config = job_config @endpoint def init(self): logging.getLogger().addHandler(logging.StreamHandler(sys.stderr)) print(f"Initializing actor: {self.rank} {current_rank()=} {socket.gethostname()=}") @endpoint def train(self): logger.info("Starting training") config = self.job_config trainer: Optional[Trainer] = None try: trainer = Trainer(config) trainer.train() if config.checkpoint.create_seed_checkpoint: trainer.checkpointer.save(curr_step=0, ) logger.info("Created seed checkpoint") else: trainer.train() finally: if trainer: trainer.close() if torch.distributed.is_initialized(): torch.distributed.destroy_process_group() logger.info("Process group destroyed.") print("Done training")
Created actors are spawned on a process mesh—a group of actors with access to the reserved resources. The process mesh uses Monarch’s process allocator to communicate with all nodes in the cluster.
from monarch._rust_bindings.monarch_hyperactor.alloc import AllocConstraints, AllocSpec from monarch.actor import ProcMesh alloc = allocator.allocate( AllocSpec(AllocConstraints(), hosts=NUM_NODES, gpus=NUM_GPUS) ) proc_mesh = await ProcMesh.from_alloc(alloc) async def async_main(job_config: JobConfig): torch.use_deterministic_algorithms(True) await setup_env_for_distributed(proc_mesh) await proc_mesh.logging_option(stream_to_client=True, aggregate_window_sec=3) trainer_actor = await proc_mesh.spawn("trainer_actor", TitanTrainerWrapper, job_config) await trainer_actor.init.call() await trainer_actor.train.call()
Users simply define the training configuration and initiate the trainer, triggering the Trainer Actor on the process mesh. Logs are reported on Rank_0 in the notebook cell, and are also accessible through the MMT logs, as well as LitLogger, the native logger on Lightning, or WandB, as Titan pushes logs to WandB.
from torchtitan.config import ConfigManager, JobConfig config_manager = ConfigManager() job_name = get_job_name(NUM_NODES, NUM_GPUS) manual_args = [ "--job.config_file", os.path.expanduser("/torchtitan/torchtitan/models/llama3/train_configs/llama3_8b.toml"), "--model.tokenizer-path", "/teamspace/studios/this_studio/torchtitan/assets/hf/Llama-3.1-8B", "--training.steps", "1000000", "--training.dataset_path", "/teamspace/studios/this_studio/torchtitan/tests/assets/c4", "--job.dump_folder", "/teamspace/studios/this_studio/torchtitan/outputs/" + job_name ] config = config_manager.parse_args(manual_args) await async_main(config)

After training, users can change the Titan Trainer configuration or define new actors and re-launch new processes on the same resources without waiting. Additionally, users can place Python breakpoints (breakpoint()) inside methods defined by the @endpoint decorator for more interactivity during development. For example, you may want to check configuration parameters for the Titan Trainer before the actual run or place breakpoints inside the trainer.
class TitanTrainerWrapper(Actor): def __init__(self, job_config: JobConfig): self.rank = current_rank().rank self.job_config = job_config @endpoint def init(self): logging.getLogger().addHandler(logging.StreamHandler(sys.stderr)) breakpoint() # noqa print(f"Initializing actor: {self.rank} {current_rank()=} {socket.gethostname()=}") @endpoint def train(self): logger.info("Starting training") config = self.job_config trainer: Optional[Trainer] = None try: trainer = Trainer(config) breakpoint() # noqa trainer.train()
Get Started: Experience Monarch in Lightning Studio
- How to access Monarch in Studio notebooks.
- Get started today by cloning the Monarch Studio templates available at https://lightning.ai/studios, and the Meta AI org on Lightning https://lightning.ai/meta-ai
- Links to quickstart guides, documentation, and community forums.