Introduction
Torchcomms is a new experimental, lightweight communication API intended for use with PyTorch Distributed (PTD). In addition to the core API, we are open-sourcing NCCLX, a new backend we developed to scale to over 100,000 GPUs.
With our first release of torchcomms, we’re delivering the foundational APIs and backends required for large-scale model training in PyTorch. This initial release focuses on core communication primitives that enable reliable and performant distributed training at scale. Over the next year, we’ll continue to mature the offering—introducing features that make it easier to prototype new collectives, scale seamlessly with built-in fault tolerance, and optimize device-centric communication patterns. Our roadmap is focused on empowering researchers and developers to move faster, test new ideas at scale, and build the next generation of large-scale AI systems.
Torchcomms is our first step toward proving out new communication paradigms at scale. To accelerate innovation, we’re developing the API fully in the open, inviting community feedback as it evolves. Because of this open development process, the API is still early and may undergo breaking changes as it matures. Over time, torchcomms will serve as a proving ground for next-generation distributed technologies, with the long-term goal of migrating all PyTorch Distributed functionality onto this new foundation. As torchcomms stabilizes, it will become the backbone of scalable, fault-tolerant, and device-centric distributed training in PyTorch.
Project Goals
With torchcomms, we’re laying the groundwork for the next generation of distributed communication in PyTorch. Our goal is to build a flexible, extensible foundation that enables developers and researchers to move faster, scale further, and target a wider variety of hardware. Specifically, we’re working toward the following objectives:
- Fast Prototyping of Communication Primitives – Machine learning researchers need to experiment rapidly with new communication paradigms. By decoupling communications from PyTorch’s core numeric primitives, torchcomms makes it possible to iterate on communication layers independently—adding new collectives, APIs, or backends without breaking existing functionality. This design also enables out-of-tree backends, allowing researchers and hardware vendors to easily integrate specialized communication stacks tailored to their devices and features.
- Scaling to 100K+ GPUs – Scaling modern training workloads to hundreds of thousands of GPUs requires rethinking how communication resources are managed. Current approaches, such as lazy initialization and limited concurrency semantics for point-to-point operations, constrain scalability within libraries like NCCL. Torchcomms introduces eager initialization (where backend resources are explicitly managed by the user) and model-specific hints to optimize how communicators, NVLink buffers, and RoCE resources are allocated and shared—paving the way for truly massive distributed jobs.
- Heterogeneous Hardware Support – Existing collective backends are typically optimized for a single vendor or hardware family. With torchcomms, we’re designing for heterogeneous systems from the ground up—enabling mixed deployments that span multiple hardware generations and vendors within a single training job. This flexibility is critical as the ecosystem evolves beyond homogeneous GPU clusters.
- Fault Tolerance at Scale – Today’s open-source PyTorch Distributed lacks robust fault-tolerant process groups, which limits the reliability of higher-level libraries like torchft. Torchcomms aims to close that gap by open-sourcing a fault-tolerant backend capable of supporting algorithms such as fault-tolerant HSDP and fault-tolerant Streaming DiLoCo at scale—delivering resilience without compromising performance.
- One-Sided Communication – One-sided communication (e.g., RDMA-style semantics) is increasingly essential for asynchronous workflows in reinforcement learning, checkpointing, and large language models. Torchcomms will provide first-class support for one-sided communication, enabling efficient, low-overhead message passing and data exchange between distributed processes.
- Device-Centric Collectives – To achieve ultra-low latency for inference and training, communication and computation must be tightly coupled. Torchcomms is developing device-centric collective APIs, which enable communication metadata and logic to live directly on the device (e.g. the GPU). This includes both direct RDMA operations from the GPU (e.g., IBGDA) and CPU proxy-based designs. These capabilities allow developers to fuse compute and communication operations seamlessly, unlocking new levels of performance.
Why a new API?
A common question we hear is: “Why a new API?”
With torchcomms, we’re pursuing a set of ambitious goals—introducing capabilities that don’t yet exist in any other communication library today. To move quickly, we need the freedom to iterate in the open and evolve the design without being constrained by existing interfaces. This means that, during its early stages, the API may experience breaking changes as we experiment and refine it in collaboration with the community.
The existing c10d APIs in PyTorch Distributed carry significant technical debt, making them difficult to extend or modernize. As the torchcomms API stabilizes, we plan to deprecate the old c10d::Backend interface and adopt torchcomms as the underlying implementation for PyTorch Distributed. This transition will be done gradually and with minimal disruption—most users and models will continue to work as they do today, while automatically benefiting from the performance, scalability, and flexibility of the new backends.
Quickstart
First, see the Installation instructions for how to install torchcomms.
For more documentation, check out: https://meta-pytorch.org/torchcomms/
Basic Usage
Torchcomms is a lightweight wrapper around the underlying backends and communicators. The core APIs map directly to the backend methods and are designed as a fully object-oriented API.
import torchcomms # Eagerly initialize a communicator using MASTER_PORT/MASTER_ADDR/RANK/WORLD_SIZE environment variables provided by torchrun. # This communicator is bound to a single device. comm = torchcomms.new_comm("ncclx", torch.device("cuda"), name="my_comm") print(f"I am rank {comm.get_rank()} of {comm.get_size()}!") t = torch.full((10, 20), value=comm.rank, dtype=torch.float) # run an all_reduce on the current stream comm.allreduce(t, torchcomms.ReduceOp.SUM, async_op=False) # run an all_reduce on the background stream work = comm.allreduce(t, torchcomms.ReduceOp.SUM, async_op=True) work.wait() # split a communicator into groups of 8 split_groups = torch.arange(comm.get_size()).view(-1, 8).tolist() tp_comm = comm.split(split_groups)
DeviceMesh
Torchcomms also supports compatibility with DeviceMesh for compatibility with PyTorch parallelism libraries such as FSDP2.
import torchcomms from torchcomms.device_mesh import init_device_mesh from torch.distributed.fsdp import fully_shard comm = torchcomms.new_comm("ncclx", torch.device("cuda:0"), name="global") mesh = init_device_mesh( mesh_dim_comms=(comm,), mesh_dim_names=("global",), ) fully_shard(model, device_mesh=mesh)
Initial Backends
Along with the new torchcomms APIs, we have released several backends for a variety of hardware platforms.
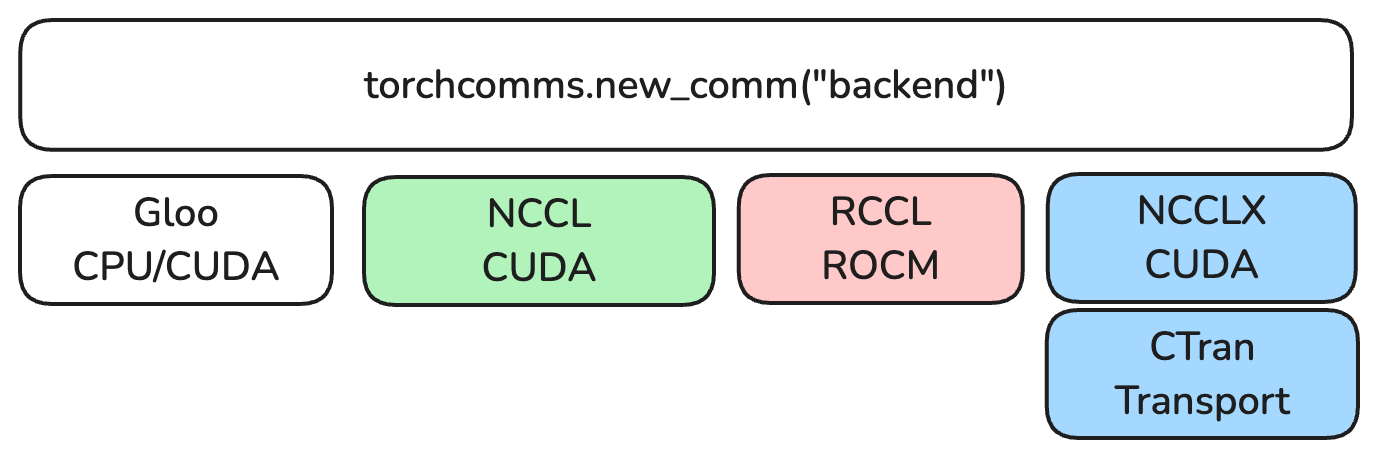
NCCLX
NCCLX contains the Meta extension to the popular NCCL library. NCCLX is production-tested – it is used for large scale training and inference for large language models (LLMs) such as Llama3 and Llama4. Today, all of Meta’s generative AI services are backed by NCCLX. Some key features of NCCLX include:
- Scalable initialization
- Zero-copy and SM-free communication
- Custom collective algorithms
- Network traffic load balancing
- One-sided communication
- GPU-resident and low latency collectives
- Fault analyzer and localization
In parallel with the upstream NCCL, we have developed a separate Custom Transport (CTran) stack to host these Meta in-house optimizations and custom features. CTran contains NVLink, IB/RoCE and TCP transports to support lower-level communication primitives via different hardware routines and build communication algorithms for various communication semantics (e.g., collectives, point-to-point, RMA) over the transports.
Both NCCLX and CTran are open sourced today, along with torchcomms. We will discuss more details of NCCLX/CTran in a white paper later this week.
NCCL and RCCL
In addition to NCCLX, torchcomms also supports upstream NCCL. Current PyTorch Distributed NCCL users can try out torchcomms easily without changing the underlying communication library setup.
The AMD RCCL support in the current PyTorch Distributed is through the NCCL process group. As part of torchcomms release, we have also included a native RCCL backend. This allows torchcomms to provide native multi-vendor GPU support from Day 1. It allows different libraries to evolve more independently.
Gloo
You may know of Gloo as the backend you use when you need to transfer CPU metadata between machines or for tests. That is the main use case but it also has some new advanced features such as infiniBand and one sided operations. We recently also added a new “lazy init” mode that allows Gloo to scale to 100k or more workers.
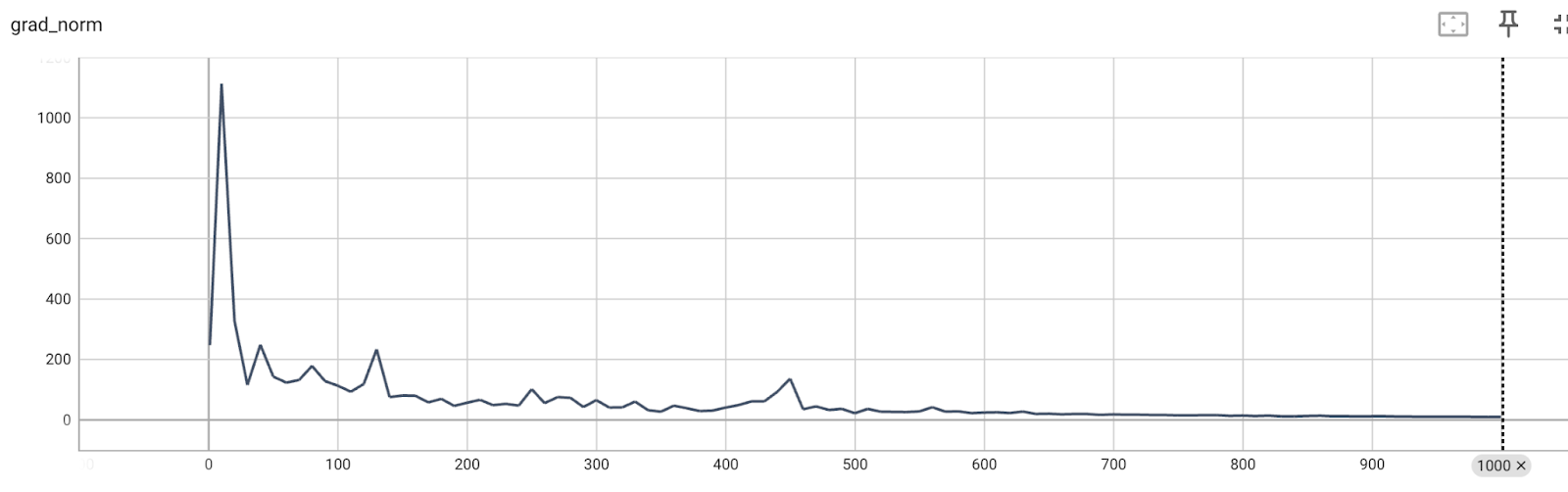
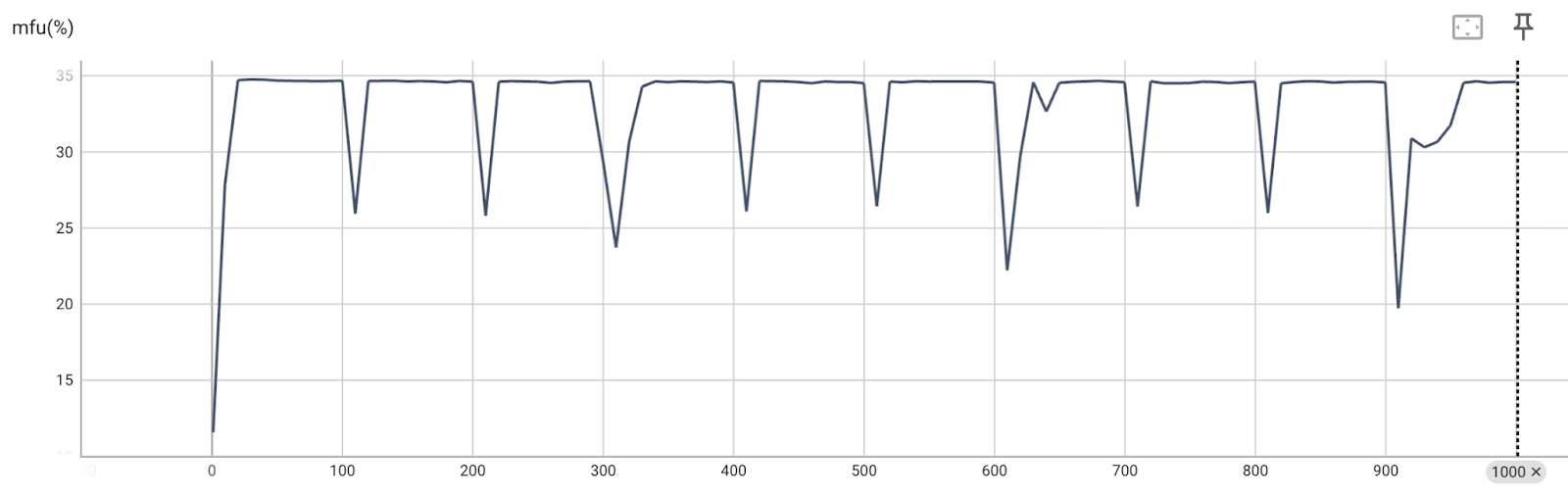
Composability: torchtitan
We’ve demonstrated compatibility and correctness of the new torchcomms API by integrating it in with torchtitan. This uses the device mesh integration to provide compatibility with the existing PyTorch technologies, such as FSDP2 and tensor parallelism.
Link to torchtitan integration, the integration code will be under path: torchtitan/experiments/torchcomms/.
Link to torchtitan loss/performance curves: (with FSDP2)
New APIs
Collective Semantic Changes
We’ve made a number of changes to the existing collectives that were inherited from the existing PyTorch Distributed APIs. These are intended to make the high level semantics better match the underlying device semantics and to improve flexibility.
- All operations are done through object oriented APIs rather than using the global dist.* APIs.
- Each torchcomm.TorchComm object maps to a single device and communicator.
- Backends are eagerly initiated and require a device to be passed in at creation time.
- All operations use the communicator ranks rather than “global” ranks.
- All operations execute in order they were issued and concurrent operations must be run using the batch API.
- send/recvs do not execute concurrently unless issued via the batch API.
Window APIs
We’re adding support for window APIs to allow for dynamic put/get operations on remote memory. For certain use cases including checkpointing, async operations this can be significantly more performant and easier to express since only one side needs to be involved unlike traditional collectives.
The window APIs enable users to create a memory buffer—either in GPU or CPU memory—across different ranks. Once created, the buffer is automatically registered and can be accessed via the provided Put and Get APIs, leveraging the underlying RDMA or NVL transport for zero-copy, one-sided communication. Additionally, the window APIs offer an atomic signaling mechanism, further enhancing asynchronous communication capabilities.
The window APIs are under active development and still experimental.
Transport APIs
We’re adding transport APIs that allow for doing point to point operations using the underlying transport directly. This provides a similar API to window APIs but not tied to a collective library. Initially we’re providing support just for RDMA over a dedicated Network which is intended for use in RPC like operations. This is internally supported by the IB backend in CTran.
The RdmaTransport provides a write API that allows users to directly write into the remote memory. Users would need to register the memory and exchange its handle between processes to facilitate the write. This is effectively a zero copy data transfer, and can be done for a CPU or GPU memory in a zero copy fashion. These APIs are only transport APIs and do no compute (no reduce, etc).
The transport APIs are under active development and are still experimental.
Fault Tolerance APIs
We’re working on creating a new backend that provides fault tolerant collectives. This new backend is built entirely on the CTran transport and provides failure detection, timeouts, error recovery and safe reconfiguration after errors.
Extensibility
Extending Backends with New Collectives
Torchcomms is designed to support direct access to the underlying backends. This allows for fast prototyping of new APIs before we standardize them and add them to the shared backend interface.
Here’s an example of adding a new custom operation:
class TorchCommMyBackend : public TorchCommBackend { public: std::shared_ptr<TorchWork> quantized_all_reduce( at::Tensor& tensor, ReduceOp op, bool async_op) { // your implementation } }; PYBIND11_MODULE(_comms_my_backend, m) { py::class_<TorchCommMyBackend, std::shared_ptr<TorchCommMyBackend>>( m, "TorchCommMyBackend") .def( "quantized_all_reduce", &TorchCommMyBackend::quantized_all_reduce, py::call_guard<py::gil_scoped_release>()); }
To use in your model, it’s as easy as callingunsafe_get_backend()and calling the new method.
import torchcomms comm = torchcomms.new_comm("my_backend") backend = comm.unsafe_get_backend() backend.quantized_all_reduce(t, ReduceOp.SUM, async_op=False)
Once prototyping is done, we’re happy to upstream new operations into the standard torchcomms API.
Writing a new torchcomm Backend
One of the key features of torchcomms is that it makes it much easier to write third-party backends. These backends no longer need to be built as part of PyTorch and can be simply installed like any other Python extension using pip.
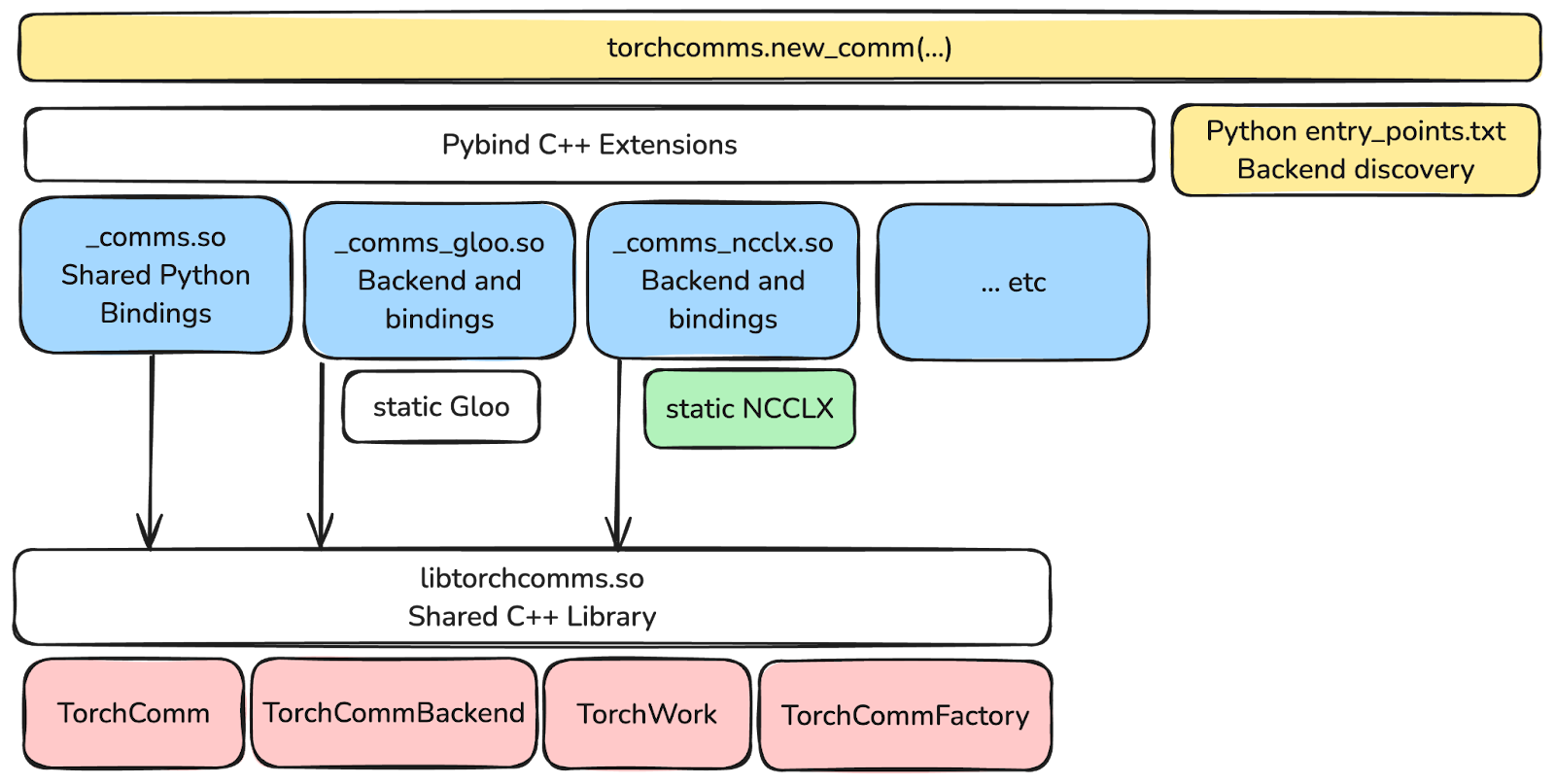
To write a new backend you need to implement the TorchCommBackend interface: https://github.com/meta-pytorch/torchcomms/blob/main/comms/torchcomms/TorchCommBackend.hpp
// MyBackend.hpp class MyBackend : public TorchCommBackend { public: ... }; // MyBackend.cpp namespace { class MyBackendRegistration { public: MyBackendRegistration() { TorchCommFactory::get().register_backend( "my_backend", []() { return std::make_shared<MyBackend>(); }); } }; static MyBackendRegistration registration{}; } // MyBackendPy.cpp PYBIND11_MODULE(_comms_my_backend, m) { py::class_<MyBackend, std::shared_ptr<MyBackend>>(m, "MyBackend"); }
Once you have your Python C extension building you then just need to add some metadata to the setup.py so torchcomms can find it.
setup( name="my_backend", entry_points={ "torchcomms.backends": [ "my_backend = my_backend._comms_my_backend", ] }, )
Then you can use it like any other backend after you pip installit.
import torchcomms comm = torchcomms.new_comm("my_backend", ...)
Next Steps
Torchcomms is a brand new API and is very much under active development. We’d love for you to get involved so please reach out if you’re interested in using it or want to help improve it.
We’re actively working on the features described in this blog post and hope to have them stabilized in the near future as well as improving hardware support for more devices.
For more documentation check out: https://meta-pytorch.org/torchcomms/
Acknowledgements
We would like to acknowledge the contributions of many current and former Meta employees who have played a crucial role in developing torchcomms and torchcomms-backends for large-scale training and inference in production. In particular, we would like to extend special thanks to Tristan Rice, Pavan Balaji, Subodh Iyengar, Qiye Tan, Rodrigo De Castro, Sudharssun Subramanian, Junjie Wang, Feng Tian, Saif Hasan, Min Si, Yifan Mao, Dingming Wu, Zhaoyang Han, Blake Matheny, Art Zhu, Denis Boyda, Regina Ren, Jingyi Yang, Bingzhe Liu, Shuqiang Zhang, Mingran Yang, Cen Zhao, Adi Gangidi, Ashmitha Jeevaraj Shetty, Bruce Wu, Ching-Hsiang Chu, Yulun Wang, Srinivas Vaidyanathan, Chris Gottbrath, Davide Italiano, Shashi Gandham, Omar Baldonado, James Hongyi Zeng