TLDR: Efficient full-parameter fine-tuning of GPT-OSS-20B & Qwen3-14B models on a single NVIDIA GH200 and Llama3-70B on four NVIDIA GH200 Superchips, while delivering up to 600 TFLOPS training throughput.
Table of Contents
- SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
- SuperOffload Highlights
- Introduction
- How SuperOffload Works
- 1. Speculation-then-Validation (STV)
- 2. Heterogeneous Optimizer Computation
- 3. Superchip-Aware Casting
- 4. GraceAdam for Optimizer Efficiency
- Experience and Insights
- Getting Started
- Acknowledgements
SuperOffload Highlights
- Single GH200: Full fine-tuning of GPT-OSS-20B, Qwen3-14B, achieving up to 600 TFLOPS.
- Multi-GPU: Qwen3-30B-A3B & Seed-OSS-36B on 2× NVIDIA GH200; Llama-70B on 4× NVIDIA GH200.
- Faster Training: Up to 4× higher throughput compared to prior work such as ZeRO-Offload.
- Increased GPU Utilization: Boost GPU utilization from ~50% to >80%.
- Engineering & Composability: Works with ZeRO-3 and Ulysses; operational tips (e.g., NUMA binding, MPAM) are documented in the tutorial.
Introduction
The emergence of tightly coupled heterogeneous GPU/CPU architectures (a.k.a., Superchips), such as NVIDIA GH200, GB200, and AMD MI300A, offers new optimization opportunities for large-scale AI. Yet it remains under-explored in terms of how to make the best use of this new hardware for large-scale LLM training. Existing offloading solutions were designed for traditional loosely coupled architectures, and are suboptimal on Superchips, suffering high overheads and low GPU utilization. To address this gap and to make the best use of Superchips for efficient LLM training, we have developed and open-sourced SuperOffload.
SuperOffload introduces a set of novel techniques that make the best use of Hopper GPU, Grace CPU, and NVLink-C2C, simultaneously for LLM training. Unlike prior offloading solutions, which assume slow GPU-CPU interconnects (e.g., 64GB/sec for PCIe-Gen4), SuperOffload exploits the much faster interconnects (e.g., 900GB/sec for NVLink-C2C) to boost GPU and CPU utilization, and training throughput. With SuperOffload, models such as GPT-OSS-20B, Qwen3-14B, and Phi-4 can be fully fine-tuned on a single GH200, delivering up to 600 TFLOPS training throughput under modest settings (sequence length 4k, batch size 4). This delivers up to 4× higher throughput compared to prior work such as ZeRO-Offload. SuperOffload enables scaling to even larger models, including Qwen3-30B-A3B and Seed-OSS-36B on two GH200s and Llama-70B on four GH200s.
SuperOffload is built on top of DeepSpeed ZeRO Stage 3, and is available in DeepSpeed versions >= 0.18.0. To enable easy integration into LLM finetuning pipelines, SuperOffload is compatible with Hugging Face Transformers and does not require any changes to modeling code.
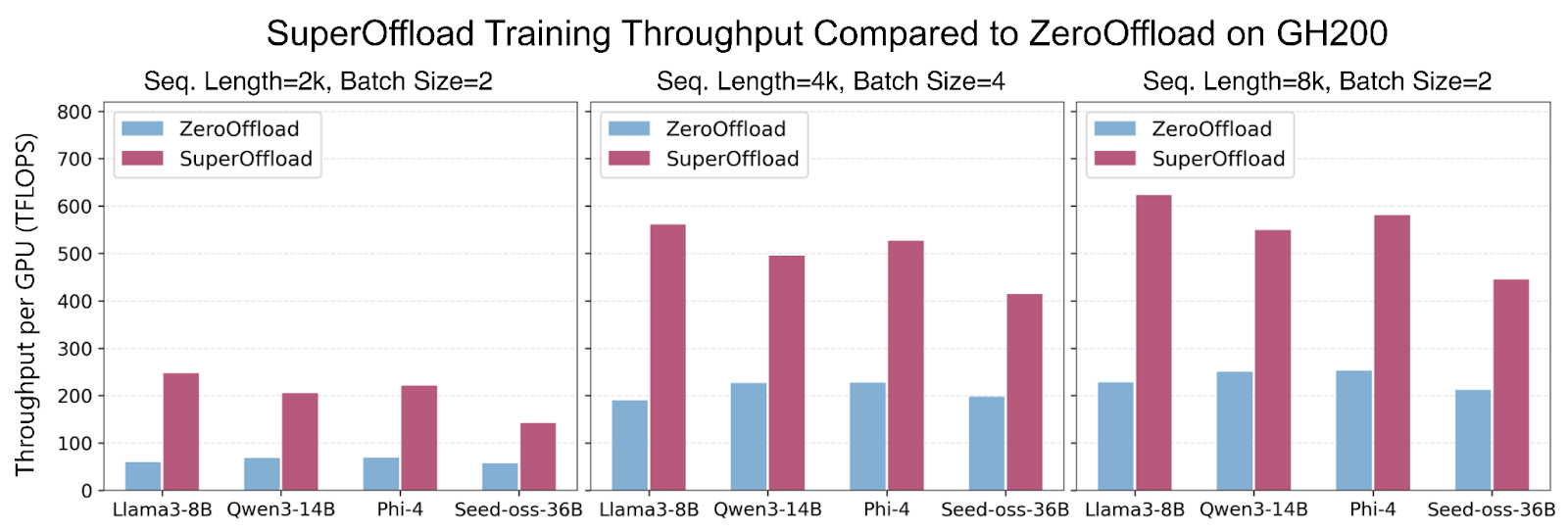
Figure 1: SuperOffload delivers up to 4× higher throughput than ZeRO-Offload for large-model fine-tuning across varying sequence lengths and batch sizes, achieving up to 600 TFLOPS throughput.
How SuperOffload Works
SuperOffload consists of four composable offloading optimization techniques: (1) Speculation-then-Validation, (2) GPU/CPU Optimizer Computation, (3) Superchip-Aware Casting, and (4) GraceAdam. We provide brief descriptions of these techniques below.
1. Speculation-then-Validation (STV)
In most offloading solutions, synchronizations between CPU and GPU are needed in the optimizer step to ensure numerical robustness. For example, clipping the gradient norm requires calculating the global gradient norm, and mixed precision training requires a global check of NaN and INF values. These operations require the CPU to wait until all gradients have been received before the optimizer step and weight updates. STV avoids this bottleneck by breaking this dependency, but still preserves the semantics of training by overlapping speculative optimizer computation on CPU with backward propagation on GPU. When gradient post-processing eventually completes, the speculative optimizer computations are either committed, discarded, or correctly replayed as appropriate. STV’s post-validation of training stability enables it to safely reduce the critical path compared to prior pre-validation approaches. The figure below illustrates how SuperOffload schedules backward propagation and optimizer computation differently from traditional approaches, such as ZeRO-Offload.
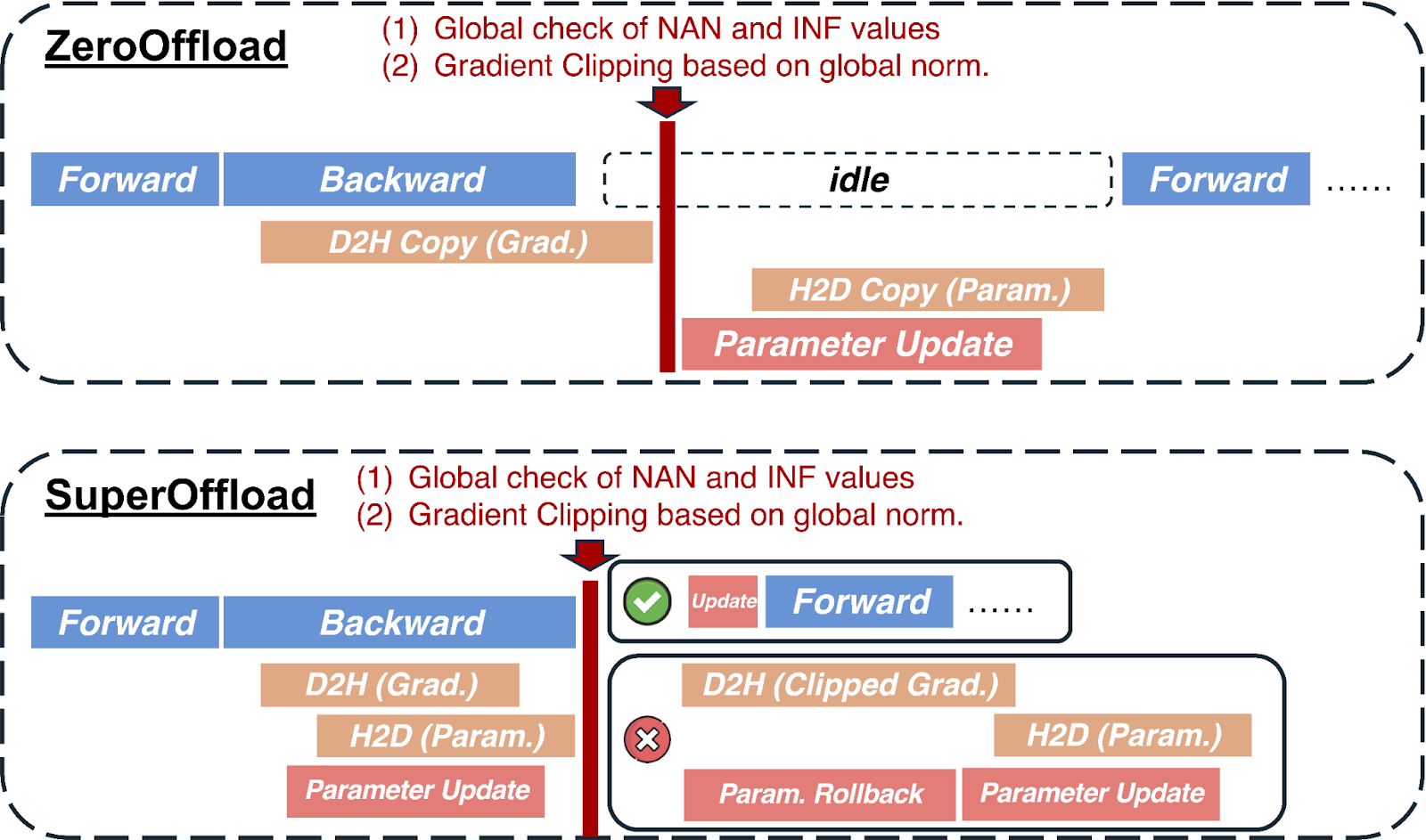
Figure 2: Previous offloading approach suffers from global gradient norm and global check of NAN and INF values, which expose the optimizer step to the critical path and prevent overlapping opportunities. In SuperOffload, we introduce a speculation-then-validation schedule to address this issue.
We evaluated the effectiveness of STV by measuring the frequency of undoing speculative optimizer computations in a pre-training run of a BLOOM-176B model. As shown in the figure below, such rollbacks (e.g., due to gradient clipping, etc.) are rare after warmup, making the associated overheads negligible over the entire training run. This makes STV practical for accelerating large-scale training.
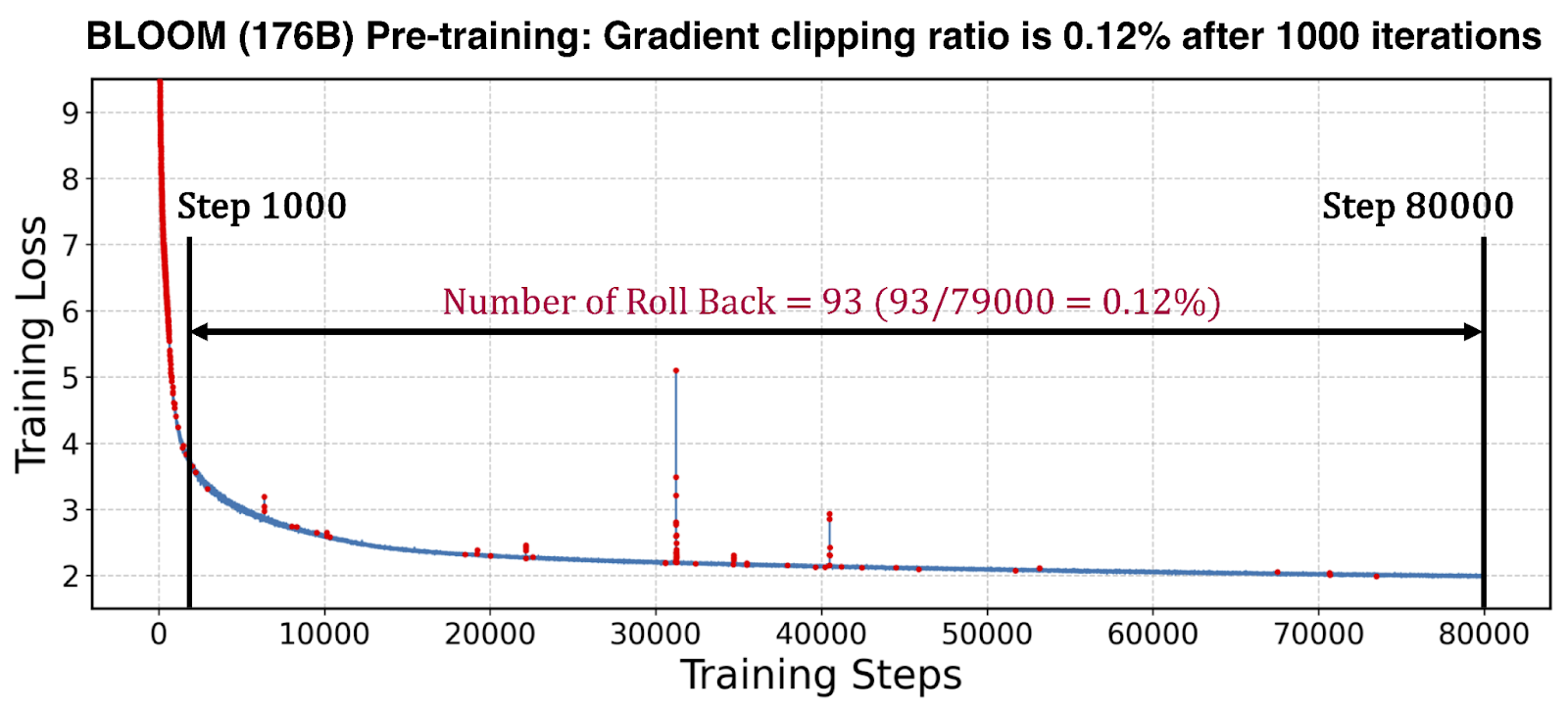
Figure 3: Red points indicate gradient clipping triggered during BLOOM pre-training — rare after warm-up, indicating that SuperOffload’s STV mechanism effectively eliminates stalls caused by gradient clipping and NaN/INF check-induced synchronizations.
2. Heterogeneous Optimizer Computation
SuperOffload improves optimizer efficiency beyond STV by partitioning optimizer computation across GPU and CPU. The GPU is used for optimizer computations of gradients created in the latter stages of the backward pass, while the CPU handles the rest. This partitioning scheme has multiple benefits. First, the GPU avoids idly waiting for optimizer computation to complete on the CPU. Second, optimizer computation is reduced by leveraging both GPU and CPU compute. Third, GPU-CPU transfers of parameters and gradients corresponding to GPU optimizer computations can be avoided.
3. Superchip-Aware Casting
In mixed precision training with offloading, tensor transfers between GPU and CPU require casting between the low-precision format on GPU (e.g., BF16, FP16, etc.) and the high-precision format on CPU (i.e., FP32). To address the bandwidth limitations of PCIe interconnects, prior offloading solutions transfer tensors in low-precision and type cast tensors on both GPU and CPU as appropriate. However, this is a suboptimal strategy on Superchip architectures because GPU compute throughput is ~100X higher than CPU, and high-bandwidth interconnects (e.g., NVLink-C2C) makes the transfer costs negligible. As an illustration, Figure 4 below shows that the optimal strategy on GH200 is tensor casting on the GPU and transferring in high-precision format.
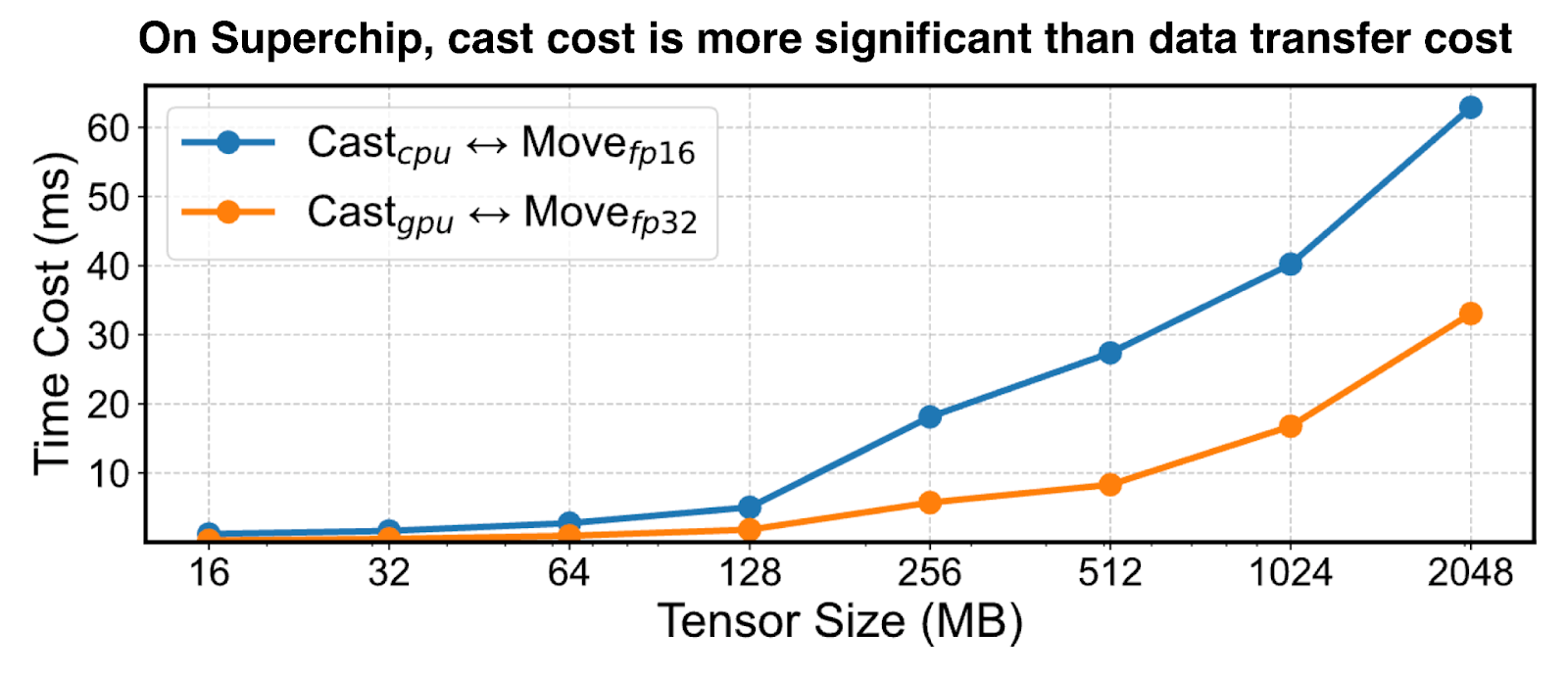
Figure 4: GH200: Tensor casting to lower/higher precision on GPU and transferring in higher precision is more efficient on Superchips.
4. GraceAdam for Optimizer Efficiency
Existing offloading solutions for LLM training require CPU implementations of the popular Adam optimizer, such as PyTorch Adam and DeepSpeed CPU-Adam. However, these are inadequate for Superchips because they are not optimized for the Grace CPU architecture. To address this issue, we created GraceAdam, a highly efficient Adam optimizer implementation for Grace CPUs. GraceAdam achieves high performance exploiting the underlying ARM architecture features such as Scalable Vector Extension (SVE), explicit memory hierarchy management, and instruction-level parallelism. Figure 5 below shows that on GH200 Superchip, GraceAdam is 3X faster than PyTorch Adam (PT-CPU) and 1.3X faster than CPU-Adam. To our knowledge, GraceAdam is the first open sourced Adam optimizer implementation for Grace CPU.
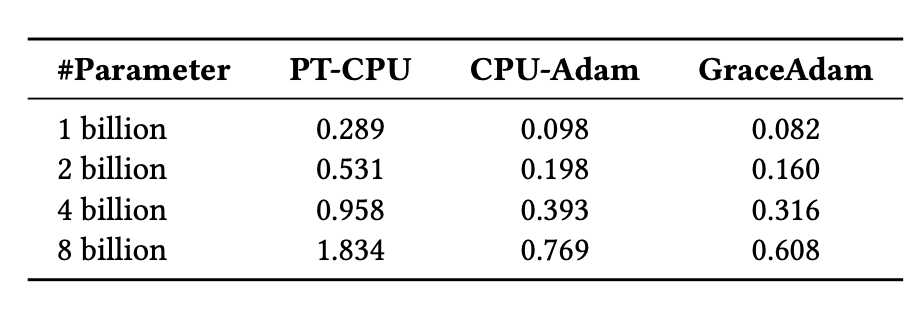
Figure 5: Using GraceAdam for efficient Adam optimizer computation on GH200.
Experience and Insights
- NUMA Binding: Pair each GPU with its directly associated CPU to maximize bandwidth. In DeepSpeed:
--bind_cores_to_rank
- MPAM (Memory System Resource Partitioning and Monitoring): Reduces interference between CPU and GPU.
How to enable MPAM on NVIDIA Superchips:
# i. Install the kernel from NVIDIA NV-Kernels. # ii. Check MPAM support: grep MPAM /boot/config-$(uname -r) # Expected output: CONFIG_ARM64_MPAM=y CONFIG_ACPI_MPAM=y CONFIG_ARM64_MPAM_DRIVER=y CONFIG_ARM64_MPAM_RESCTRL_FS=y # Verify resctrl filesystem: ls -ld /sys/fs/resctrl # iii. Mount resctrl: mount -t resctrl resctrl /sys/fs/resctrl # iv. Create partitions: mkdir /sys/fs/resctrl/p1 /sys/fs/resctrl/p2 # v. Set CPU cores & memory configs (example from experiments): /sys/fs/resctrl/p1/cpus_list: 0-6 /sys/fs/resctrl/p2/cpus_list: 7-71 /sys/fs/resctrl/p1/schemata: MB:1=100 L3:1=ff0 /sys/fs/resctrl/p2/schemata: MB:1=20 L3:1=f
Getting Started
End-to-end finetuning examples using SuperOffload are available in our tutorial/readme: DeepSpeedExamples: SuperOffload. To enable SuperOffload quickly, add the following switch to your DeepSpeed config (see tutorial for full context):
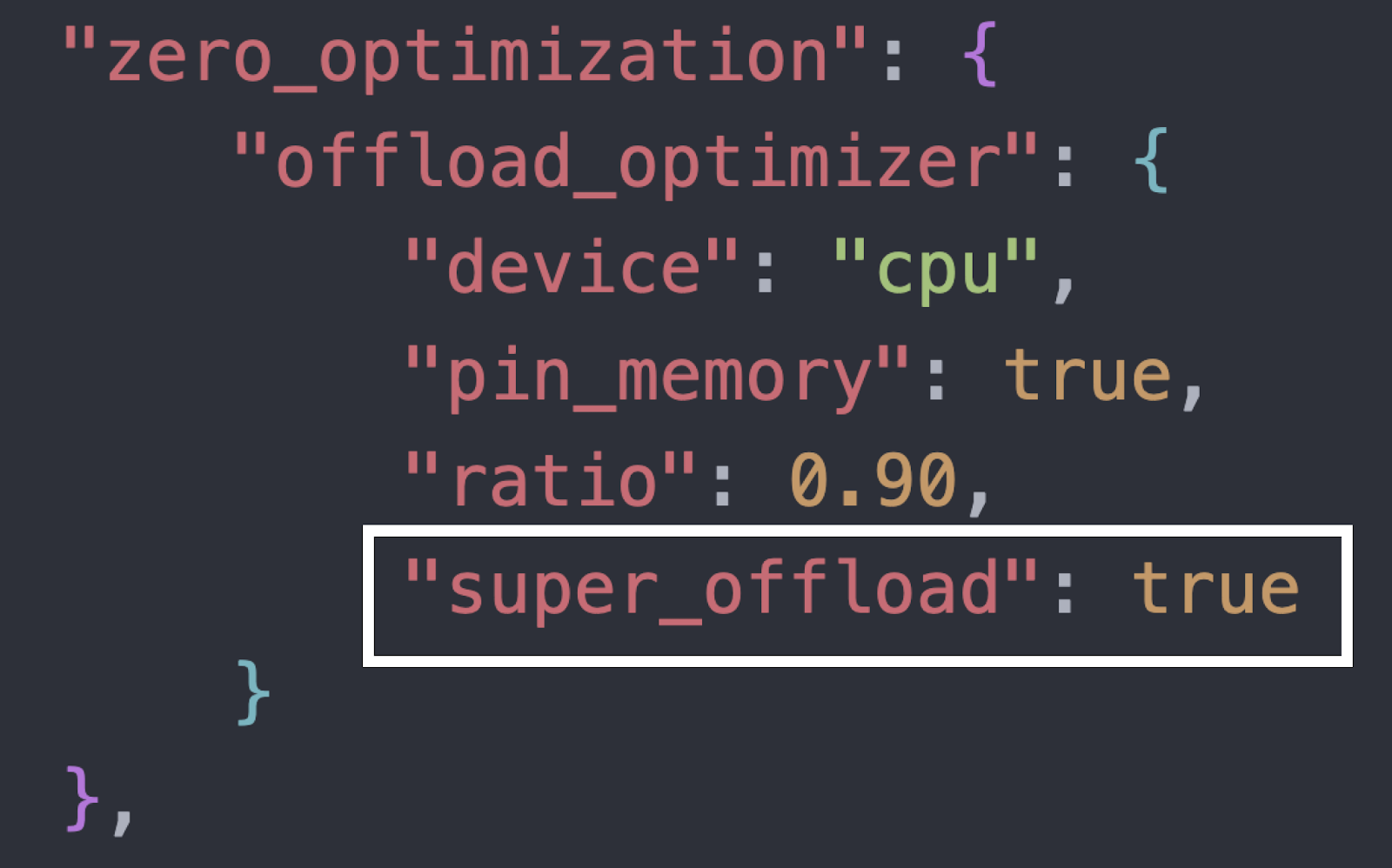
Figure 6: Enable SuperOffload with a single line in the DeepSpeed config.
Tip: On Superchip platforms (e.g., GH200/GB200/MI300A), combine NUMA binding and MPAM settings from “Experience and Insights” to stabilize bandwidth and improve end-to-end performance.
Acknowledgements
This work is a close collaboration among University of Illinois Urbana-Champaign (UIUC), Anyscale, and Snowflake.
We also gratefully acknowledge William Gropp, Brett Bode, and Gregory H. Bauer from the National Center for Supercomputing Applications (NCSA), as well as Dan Ernst, Ian Karlin, Giridhar Chukkapalli, Kurt Rago, and others from NVIDIA for their valuable discussions and guidance on MPAM support on Grace CPU.
Community feedback and contributions are welcome. For enablement and examples, see “Getting Started” above.
BibTeX
@inproceedings{superoffload, author = {Xinyu Lian and Masahiro Tanaka and Olatunji Ruwase and Minjia Zhang}, title = "{SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips}", year = {2026}, booktitle = {Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating System (ASPLOS'26)} }