Why Choose PyTorch for Recommendation System
PyTorch has emerged as the de facto framework in the AI community, with the majority of cutting-edge research, especially in areas like recommendation systems, retrieval, and ranking, being conducted with PyTorch. Developers are eager to bring the latest model advancements into production as quickly as possible. A PyTorch-based recommendation inference system is well-suited to this need, enabling both (1) high efficiency and (2) rapid model adoption in production environments.
In this blog, we will discuss the design of a high-performance recommendation inference system built with PyTorch. Approaches based on these design principles have been thoroughly validated and have successfully served extremely high volumes of traffic, demonstrating strong efficiency and reliability. Our PyTorch-based recommendation inference system serves as the backbone for Meta’s most critical machine learning workloads. Powering global surfaces, including Feed, Ads, Instagram, Reels, Stories, and Marketplace, the system manages a diverse array of ML architectures. These range from sophisticated extensions of the foundational Deep Learning Recommendation Model (DLRM) to cutting-edge, novel modeling techniques such as DHEN (Deep Hierarchical Ensemble Network), HSTU (Hierarchical Sequential Transducer Unit), Wukong, and more.
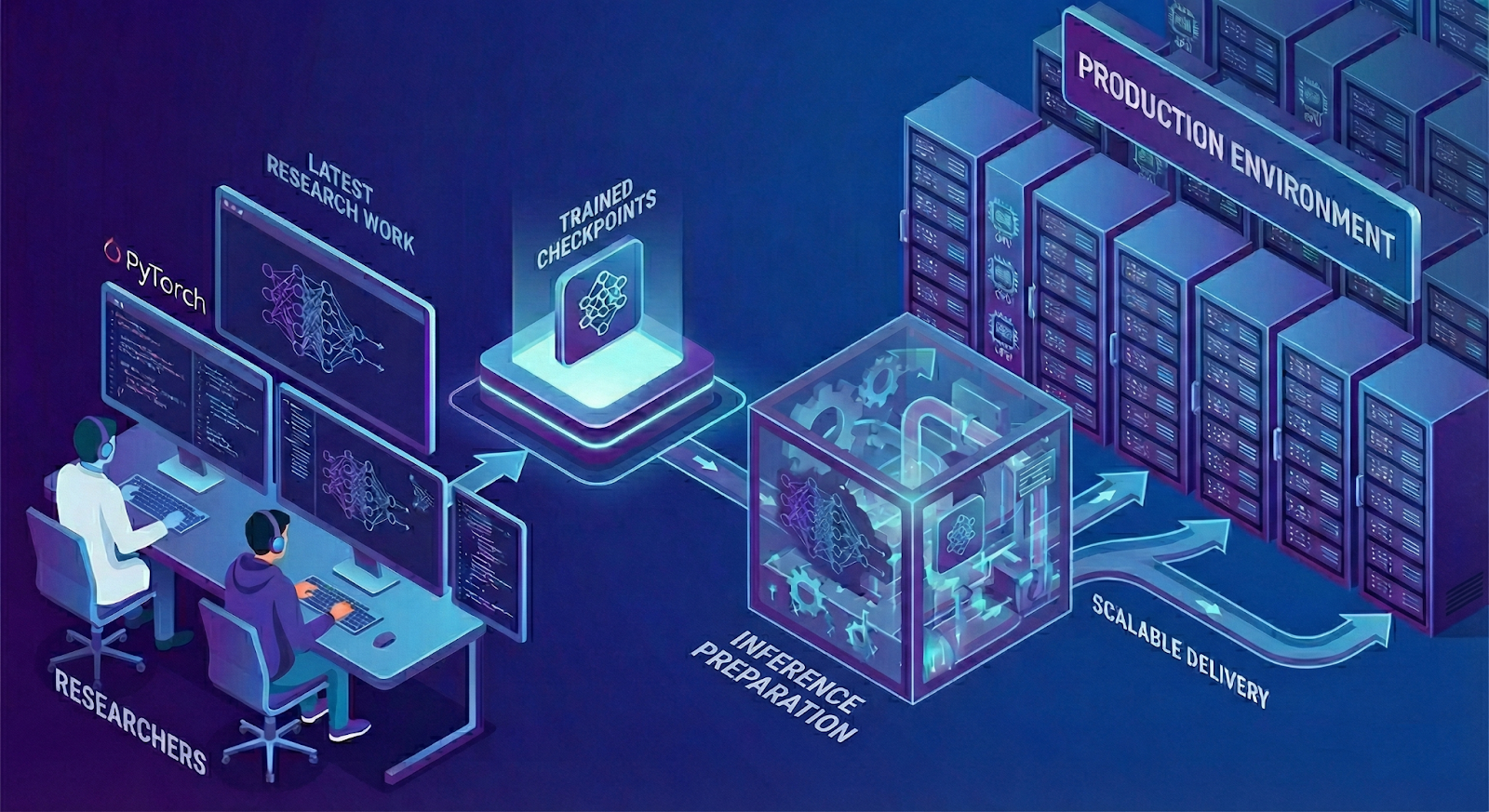
A Typical Recommendation Research to Production Inference Workflow
The Overall Workflow
After training, a model definition and its trained weights are delivered for inference, establishing a clear contract between the training and inference stages. However, running a training model directly in a production inference environment is highly inefficient and does not meet the performance requirements of real-world applications.
To address this, we need to rapidly and reliably ship trained models to production, while also supporting frequent updates as models are improved or retrained. This dynamic environment—with many models and many versions—demands a robust transformation pipeline that converts trained models into optimized inference models. Such a pipeline ensures that the resulting inference model files are tailored for efficient hardware utilization, enabling high throughput (QPS, i.e., queries per second) and meeting strict latency requirements. In summary, a dedicated system for transforming training models into production-ready inference models is essential for maintaining agility, scalability, and performance in our model deployment process.
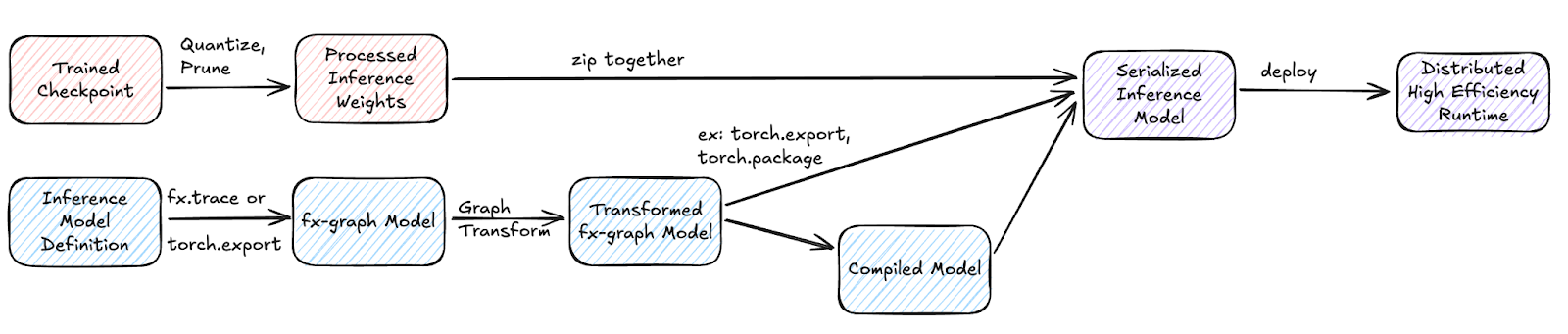
Trained Model to Production Inference Transformation Flow
Defining the Inference Model and Weights Mapping
The trained model often includes components that are only necessary during training, such as loss functions and certain regularization techniques. It is best practice to define a dedicated inference model that mirrors the forward logic of the training model, while also allowing for inference-only optimizations. Additionally, a mapping between the inference model’s parameters and the trained model weights (checkpoint) must be established, especially if fully qualified parameter names differ between training and inference. This mapping should be maintained and updated throughout the inference model preparation process.
Capturing the Computation Graph from Python Models
To enable efficient inference, a series of model transformations must be applied to the inference model. Applying these optimizations requires converting PyTorch models defined in Python into a graph representation. Capturing a PyTorch model’s computation graph is a challenging task. Using torch.fx to extract an FX graph is a common practice. This method assumes that the model architecture does not contain cyclic structures. For submodules with complex control flows, these can be marked as leaf nodes to simplify the graph extraction process.
Recently, torch.export has become a more mature tool for capturing computation graphs, offering improved support for models with control flow. However, the resulting PT2IR (a specialized FX graph) can be quite low-level, and decomposed, which may complicate certain model transformations.
Model Transformation and Optimization
After capturing the FX graph, a variety of optimizations can be applied through model transformation passes. Below are some common transformation passes:
- Model Splitting: For distributed inference scenarios, it is often necessary to split the full “forward” graph into smaller subgraphs. Each subgraph represents the forward pass of a submodule, enabling distributed execution across multiple devices or hosts. Additionally, these transformations can group similar computations together, further enhancing overall efficiency.
- Operator Fusion: Multiple operations can be replaced with a single, fused implementation to improve efficiency. This can be achieved by swapping submodules or applying graph-level transformations.
- Quantization: Similar to operator fusion, certain layers (e.g. linear layers) can be replaced with quantized versions to reduce memory usage and improve inference speed. TorchAO provides the support for linear quantization with PT2 support.
- Compilation (a.k.a. Lowering): Model compilation techniques are typically applied ahead of time as part of the transformation process. This step converts model code into lower-level representations that are better suited for the target inference devices. (See the AI Compiler section below for more details.)
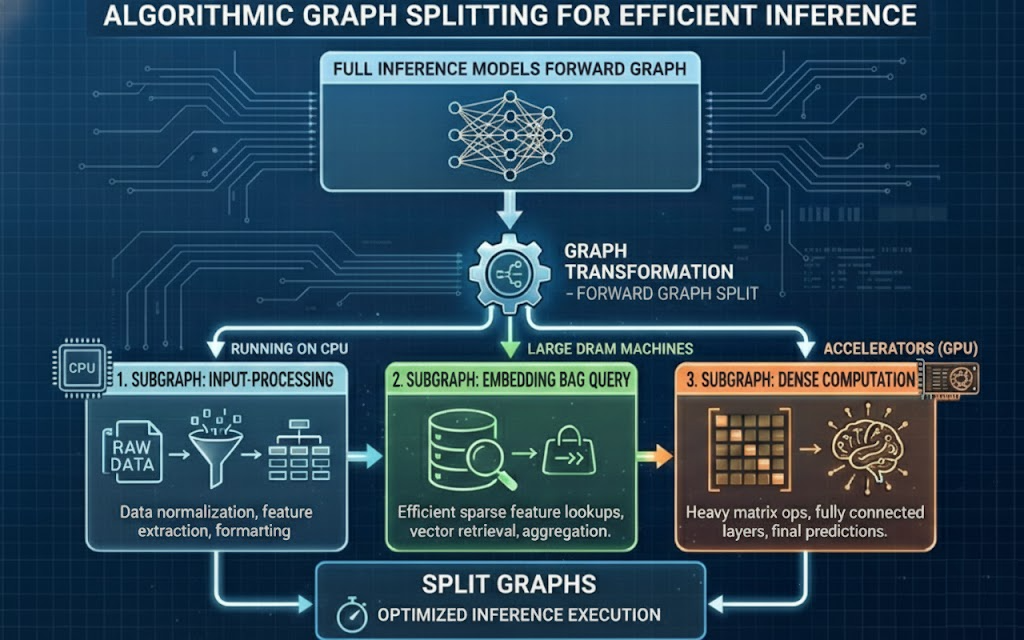
Graph Transformation Example: Full Forward Graph to Split Graph
Model Serialization
Standard PyTorch models use the pickle format for storage, but this approach is insufficient for production due to weak backward compatibility and Python dependency issues. To address these challenges, several serialization solutions are available:
| Solution | Description | Pros | Cons |
| TorchScript | Capture TorchScript IR through scripting or tracing, and save as TorchScript format. | 1) Mature and strong backward compatibility support
2) Solid control flow support |
1) Some constraints on model definition (e.g., no complex data structures)
2) Deprecated and not supported |
| torch.export | Export the PyTorch model as PT2IR. | 1) The official way to serialize models in PT2
2) Active development |
1) Control flow may need additional handling |
| torch.package | Directly export related Python modules as source code and pickle objects. | 1) Great flexibility | 1) May require manual effort to define module boundaries
2) Requires Python dependency |
Regardless of the serialization format, the resulting artifact should be a zip file. This allows for easy inspection and debugging by unzipping the contents. Processed weights can also be packaged within the zip file. We are prioritizing torch.export for new model development over older tools like TorchScript and torch.package. With TorchScript now being deprecated, torch.export provides a more robust path forward with active feature development, while also providing necessary superior performance compared to torch.package by allowing for a Python-independent runtime.
Model Loading and Execution
Once the inference models are prepared, you will have a set of inference model files. For extremely large models, it may be necessary to load the model structure and weights separately, which could require custom logic for saving and loading.
After loading the model files, the runtime begins processing inference requests. Since PyTorch does not natively provide serving capabilities beyond model execution, an additional server layer is required to manage inference serving. Below, we outline the key features of an efficient and scalable PyTorch inference server for recommendation systems:
Lightweight PyTorch Executor Wrapper
- The server converts requests to PyTorch model inputs. This wrapper should be minimal to ensure efficiency.
Efficient and Flexible API
- In a distributed environment, different components of the model communicate via APIs, which necessitates precise semantic definitions, such as specifying the batch dimension and other relevant parameters.
- Tensor-based APIs align well with the PyTorch model’s forward method.
- Zero-copy (in-place) APIs allow us to update models in-place, efficiently and seamlessly transitioning from serving one version of a model to the next without requiring significant additional capacity to load both model versions during the transition.
DAG Representation and Executor
- Modules with similar characteristics (e.g., all embedding bags) can be grouped into dedicated submodules for batch execution.
- After model splitting, the original forward function is represented as a Directed Acyclic Graph (DAG), with each node corresponding to a submodule. An executor is required to manage the execution of this DAG.
- DAG nodes may be deployed across multiple hosts, which necessitates support for remote execution. In such cases, an efficient communication library is essential to ensure seamless and performant interactions between distributed components.
Optimizations
In the previous section, we outlined the core principles for building a robust, efficient, and scalable recommendation inference system with PyTorch, one that can handle high traffic volumes and meet stringent production requirements. To further enhance system performance, we will now discuss several key optimization strategies below.
GPU (Accelerator) Inference
With the emergence of new model architectures, computational demands have increased significantly. CPUs often struggle to meet the latency requirements for running such models online, making accelerators like GPUs a natural choice. However, running the entire model on a single GPU can be inefficient, and models may not fit within the memory constraints of a single device. Therefore, splitting models into multiple segments and executing the most compute-intensive layers on GPUs is a practical approach.
Additionally, GPU kernel launch overhead can be substantial. To mitigate this, batching requests together reduces the number of kernel launches and improves overall throughput.
C++ Runtime
While the most straightforward way to run PyTorch models is via Python, the Python runtime introduces noticeable overhead, especially as QPS (queries per second) increases. Typically, Python overhead becomes significant at QPS ≥ 100, and can become a severe bottleneck at QPS ≥ 1000.
For high-QPS scenarios (≥ 100 per host), we recommend using a C++ (or Rust) runtime. Both TorchScript (for TorchScript models) and ExecuTorch (for models saved with torch.export) provide C++ runtimes. Recently, development has focused on a new runtime, torch.nativert, designed for executing torch.export models across servers, as an alternative to the TorchScript runtime, which has been deprecated as of the last PyTorch Conference.
Distributed Inference (DI)
Running the entire inference model as a monolith can be inefficient or even infeasible. Instead, splitting the model into multiple components and distributing them across different workers can both improve efficiency and enable scaling to larger model sizes. Common DI patterns include:
- CPU-GPU DI: Assign input processing and lightweight computations to CPUs, while offloading compute-heavy layers of the model to GPUs.
- Embedding-Dense DI: Group embedding tables into dedicated submodules that can be served on separate hosts (similar to traditional parameter servers). Dense layers, which are smaller but compute-intensive, can be grouped and executed together for improved efficiency.
- Dense Model Parallelism: Split a single dense network into multiple sub-networks that can be executed in parallel, either on different CUDA streams within the same device or across multiple devices, enabling selective lowering and parallel execution.
AI Compiler and High-Performance Kernel Libraries
To achieve maximum performance, developers may be tempted to rewrite model definitions in C++/CUDA and run them directly. However, this approach does not scale well. Instead, AI compilers can automate this process, generating highly optimized artifacts. Options include:
- AOTInductor (torch.compile)
- AITemplate
- TensorRT
These compilers generate new, compiled artifacts that are packaged alongside the serialized model. For production RecSys deployments, C++ runtimes are preferred for performance reasons. This precludes the use of Python-dependent JIT workflows like torch.compile; instead, Ahead-of-Time (AOT) Inductor is used to precompile models into static runtime artifacts deployable in C++.
AI compilers utilize high-performance kernel libraries to maximize computational efficiency on various hardware platforms, including:
- CUTLASS/CuTeDSL for Nvidia GPUs
- Composable Kernels / AITER for AMD GPUs
- ZenDNN for AMD CPUs
- OneDNN for Intel CPUs
Request Coalescing
To maximize efficiency, requests should be coalesced (batched) together. This requires understanding the semantics of each input, particularly which dimension represents the dynamic batch size, so that requests can be concatenated appropriately. The model’s forward method should be tagged with batch information to facilitate coalescing, and the runtime must support this feature.
Table Batched Embedding
Querying embedding tables in PyTorch can incur significant operator kernel launch overhead, especially when dealing with tens, hundreds, or even thousands of tables. Since embedding lookups are data-transfer-heavy (akin to hash map queries), batching embedding bags and querying all tables in a single call can greatly reduce overhead and improve data transfer efficiency.
Quantization
Both embedding and dense layers of the model can benefit significantly from quantization:
- Embeddings: Data types like bf16 and int8 are generally safe, and int4 is often acceptable. Different tables and rows may have varying numerical sensitivities. PyTorch supports per-table quantization, even for table-batched embeddings, allowing developers to customize quantization strategies. Some tables may even use int1 or int2 configurations.
- Dense Layers: Dense layers are more sensitive to quantization. Typically, fp16 and bf16 are acceptable for entire dense submodules, but exceptions exist, such as fp16 may lack sufficient range, and bf16 may not provide enough accuracy. For further efficiency, fp8 and fp4 can be applied at the layer level, though this often requires manual tuning.
All quantization strategies should be validated through accuracy evaluation. TorchAO provides support for Linear and Conv layers, good to start with.
Delta Update
Model freshness is critical for serving recommendation models. As models grow larger, loading the entire model becomes increasingly expensive. A balanced approach is to apply partial weight updates (delta updates). While implementing a protocol for data transfer is straightforward, tuning the weight loading pace is crucial to avoid disrupting serving. Embedding tables are generally more tolerant of partial updates, while dense modules are more sensitive. For dense modules, we recommend using a buffer module to support full module swaps, rather than updating weights individually.
Developer Experience
Python Runtime
To streamline the development and debugging of the inference flow, we recommend providing a lightweight Python runtime environment (versus using the C++ runtime). This approach allows developers to efficiently determine whether issues originate from the runtime or the model itself. Additionally, it simplifies the process of adding instrumentation for debugging purposes.
With the introduction of free-threaded Python, both runtime and communication overhead can be further minimized within the Python ecosystem. This advancement also makes deploying Python runtimes in production environments increasingly practical.
Module Swap-Based Transformations
Historically, graph-based transformations have been challenging for model authors to understand and debug, largely due to the complexity of graph manipulations and the loss of original stack trace information. To address these issues, we recommend shifting such optimizations earlier in the inference module authoring process. By adopting a holistic, native PyTorch module-based workflow, and leveraging eager mode transformations, we have found that the inference development experience is significantly improved.
Eval Flow
To ensure both model and runtime quality, we recommend implementing the following two evaluation flows:
- Accuracy Verification: Compare the inference model’s quality against training evaluation results.
- Performance Benchmarking: Replay production-like traffic to assess throughput and latency.
Conclusion
At Meta, we developed a highly efficient recommendation inference system built on PyTorch that is critical for translating cutting-edge research into production-grade services. This blog detailed a robust workflow, starting from a trained model definition and its weights, progressing through essential inference transformation steps, including graph capture, model splitting, optimizations (fusion, quantization, compilation, etc.), and finally serialization. We then outlined the requirements for a high-performance inference server, emphasizing a lightweight executor, flexible tensor-based APIs, and a DAG-based model execution model. Finally, we explored advanced optimization techniques crucial for high-QPS, low-latency performance, such as leveraging GPU/Accelerator inference, adopting a C++ runtime, implementing Distributed Inference patterns, utilizing AI compilers, and applying sophisticated methods like request coalescing, Table Batched Embeddings, and quantization. By adhering to these principles and utilizing the featured open-source libraries, developers can build scalable, performant, and agile PyTorch-based systems capable of serving the world’s most demanding ML recommendation workloads.
Related Libraries
TorchRec: A PyTorch domain library that powers Meta’s production recommender systems by providing the sparsity and parallelism primitives necessary to train and deploy models with massive embedding tables sharded across multiple GPUs.
TorchAO: TorchAO is an easy to use quantization library for native PyTorch. TorchAO works out-of-the-box with torch.compile() and FSDP2 across most HuggingFace PyTorch models.
AITemplate: An open-source Python framework that transforms deep neural networks into highly optimized C++ code for NVIDIA and AMD GPUs, delivering near-roofline inference performance through unified hardware support and comprehensive operator fusion.
TensorRT: NVIDIA TensorRT is a developer ecosystem comprising inference compilers, runtimes, and model optimizations designed to deliver high-performance, low-latency deep learning inference for production applications.
Generative Recommenders / HSTU: A library reformulates classical recommendation systems as generative models and introduces algorithms like HSTU and M-FALCON to drastically accelerate training and inference while establishing scaling laws for billion-user scale environments.
FBGEMM: Highly-optimized kernels used across deep learning applications, including recommendation systems.
Triton and Low-Level Extension (TLX): Triton is a Python-based language and compiler designed for writing highly efficient GPU kernels. TLX (Triton Low-Level Extensions) is an experimental add-on that provides fine-grained, hardware-specific control within Triton, enabling developers to further optimize performance on modern GPUs.
oneDNN: oneAPI Deep Neural Network Library is an open-source, cross-platform performance library of basic building blocks for deep learning applications, specifically optimized for Intel processors.
ZenDNN: ZenDNN (Zen Deep Neural Network) Library accelerates deep learning inference applications on AMD CPUs.
CUTLASS / CuTeDSL: CUTLASS is a collection of abstractions for implementing high-performance matrix-matrix multiplication (GEMM) and related computations at all levels and scales within CUDA. CuteDSL is a Python-based embedded domain-specific language for Cutlass.
AITER: AITER is AMD’s centralized repository that supports various high performance AI operators for AI workloads acceleration, where a good unified place for all the customer operator-level requests, which can match different customers’ needs.
CK: The Composable Kernel (CK) library provides a programming model for writing performance-critical kernels for machine learning workloads across multiple architectures (GPUs, CPUs, etc.). The CK library uses general purpose kernel languages, such as HIP C++.