Silero Voice Activity Detector
# this assumes that you have a proper version of PyTorch already installed
pip install -q torchaudio
import torch
torch.set_num_threads(1)
from IPython.display import Audio
from pprint import pprint
# download example
torch.hub.download_url_to_file('https://models.silero.ai/vad_models/en.wav', 'en_example.wav')
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_timestamps,
_, read_audio,
*_) = utils
sampling_rate = 16000 # also accepts 8000
wav = read_audio('en_example.wav', sampling_rate=sampling_rate)
# get speech timestamps from full audio file
speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=sampling_rate)
pprint(speech_timestamps)
Model Description
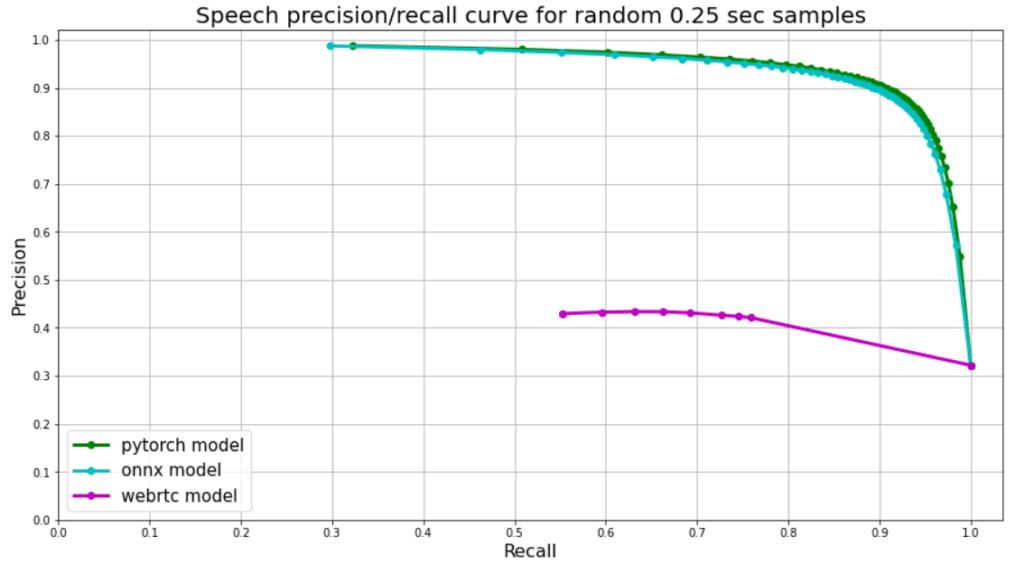
Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD). Enterprise-grade Speech Products made refreshingly simple (see our STT models). Each model is published separately.
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link). WebRTC though starts to show its age and it suffers from many false positives.
(!!!) Important Notice (!!!) – the models are intended to run on CPU only and were optimized for performance on 1 CPU thread. Note that the model is quantized.
Additional Examples and Benchmarks
For additional examples and other model formats please visit this link and please refer to the extensive examples in the Colab format (including the streaming examples).
References
VAD model architectures are based on similar STT architectures.