Open-Unmix
# assuming you have a PyTorch >=1.6.0 installed
pip install -q torchaudio
import torch
# loading umxhq four target separator
separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq')
# generate random audio
# ... with shape (nb_samples, nb_channels, nb_timesteps)
# ... and with the same sample rate as that of the separator
audio = torch.rand((1, 2, 100000))
original_sample_rate = separator.sample_rate
# make sure to resample the audio to models' sample rate, separator.sample_rate, if the two are different
# resampler = torchaudio.transforms.Resample(original_sample_rate, separator.sample_rate)
# audio = resampler(audio)
estimates = separator(audio)
# estimates.shape = (1, 4, 2, 100000)
Model Description
Open-Unmix provides ready-to-use models that allow users to separate pop music into four stems: vocals, drums, bass and the remaining other instruments. The models were pre-trained on the freely available MUSDB18 dataset.
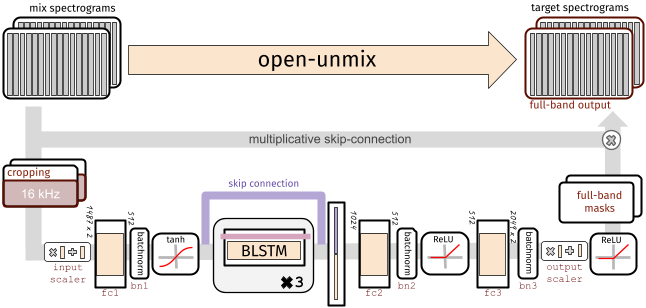
Each target model is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target source, like vocals, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error.
A Separator meta-model (as shown in the code example above) puts together multiple Open-unmix spectrogram models for each desired target, and combines their output through a multichannel generalized Wiener filter, before application of inverse STFTs using torchaudio. The filtering is differentiable (but parameter-free) version of norbert.
Pre-trained Separator models
umxhq(default) trained on MUSDB18-HQ which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz.umxis trained on the regular MUSDB18 which is bandwidth limited to 16 kHz due to AAC compression. This model should be used for comparison with other (older) methods for evaluation in SiSEC18.
Furthermore, we provide a model for speech enhancement trained by Sony Corporation
umxsespeech enhancement model is trained on the 28-speaker version of the Voicebank+DEMAND corpus.
All three models are also available as spectrogram (core) models, which take magnitude spectrogram inputs and ouput separated spectrograms. These models can be loaded using umxhq_spec, umx_spec and umxse_spec.
Details
For additional examples, documentation and usage examples, please visit this the github repo.
Furthermore, the models and all utility function to preprocess, read and save audio stems, are available in a python package that can be installed via
pip install openunmix