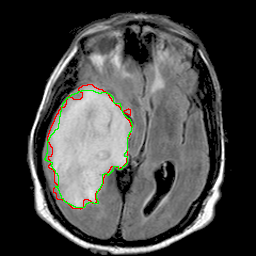
U-Net for brain MRI
import torch
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
Loads a U-Net model pre-trained for abnormality segmentation on a dataset of brain MRI volumes kaggle.com/mateuszbuda/lgg-mri-segmentation The pre-trained model requires 3 input channels, 1 output channel, and 32 features in the first layer.
Model Description
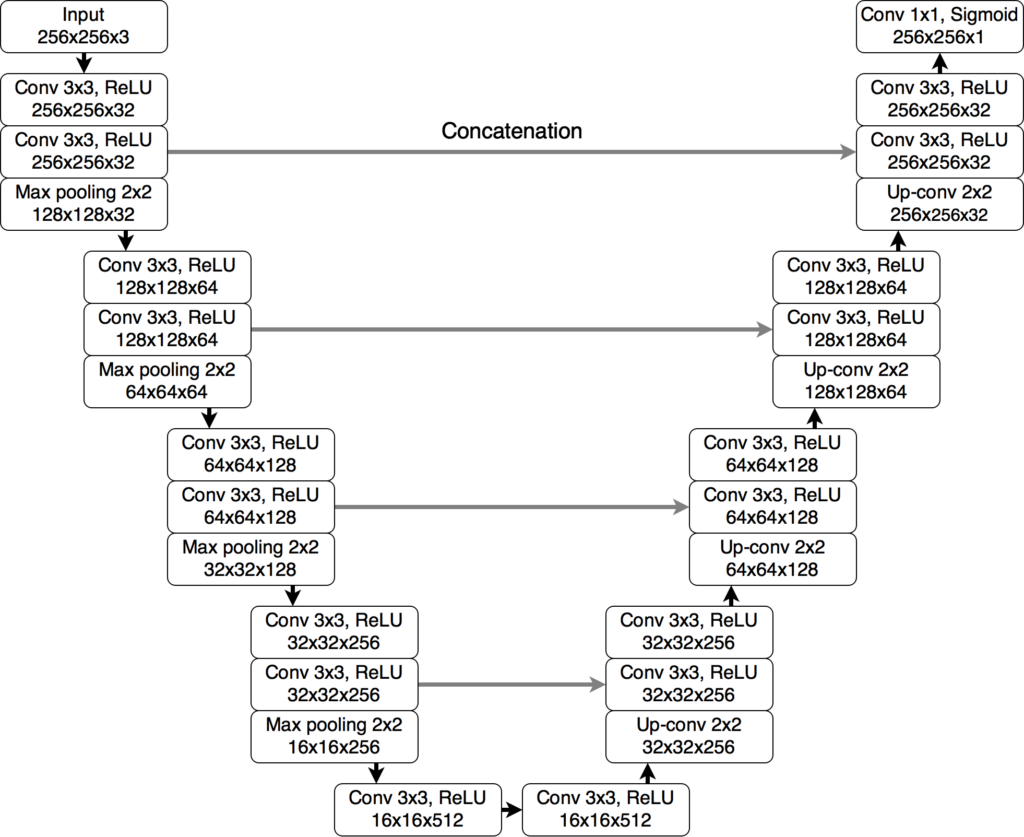
This U-Net model comprises four levels of blocks containing two convolutional layers with batch normalization and ReLU activation function, and one max pooling layer in the encoding part and up-convolutional layers instead in the decoding part. The number of convolutional filters in each block is 32, 64, 128, and 256. The bottleneck layer has 512 convolutional filters. From the encoding layers, skip connections are used to the corresponding layers in the decoding part. Input image is a 3-channel brain MRI slice from pre-contrast, FLAIR, and post-contrast sequences, respectively. Output is a one-channel probability map of abnormality regions with the same size as the input image. It can be transformed to a binary segmentation mask by thresholding as shown in the example below.
Example
Input images for pre-trained model should have 3 channels and be resized to 256×256 pixels and z-score normalized per volume.
# Download an example image
import urllib
url, filename = ("https://github.com/mateuszbuda/brain-segmentation-pytorch/raw/master/assets/TCGA_CS_4944.png", "TCGA_CS_4944.png")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
import numpy as np
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
m, s = np.mean(input_image, axis=(0, 1)), np.std(input_image, axis=(0, 1))
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=m, std=s),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model = model.to('cuda')
with torch.no_grad():
output = model(input_batch)
print(torch.round(output[0]))
References