Elastic Agent
Server
The elastic agent is the control plane of torchelastic. It is a process that launches and manages underlying worker processes. The agent is responsible for:
Working with distributed torch: the workers are started with all the necessary information to successfully and trivially call
torch.distributed.init_process_group().Fault tolerance: monitors workers and upon detecting worker failures or unhealthiness, tears down all workers and restarts everyone.
Elasticity: Reacts to membership changes and restarts workers with the new members.
The simplest agents are deployed per node and works with local processes. A more advanced agent can launch and manage workers remotely. Agents can be completely decentralized, making decisions based on the workers it manages. Or can be coordinated, communicating to other agents (that manage workers in the same job) to make a collective decision.
Below is a diagram of an agent that manages a local group of workers.
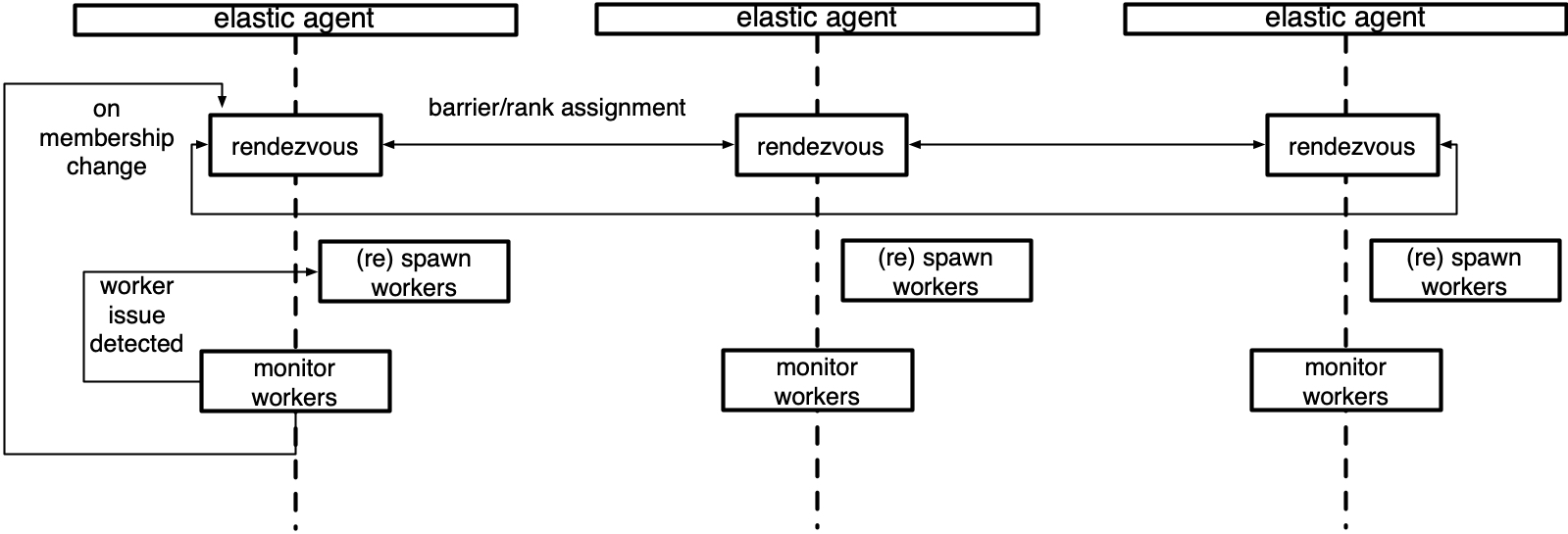
Concepts
This section describes the high-level classes and concepts that
are relevant to understanding the role of the agent in torchelastic.
-
class
torchelastic.agent.server.ElasticAgent[source] Agent process responsible for managing one or more worker processes. The worker processes are assumed to be regular distributed PyTorch scripts. When the worker process is created by the agent, the agent provides the necessary information for the worker processes to properly initialize a torch process group.
The exact deployment topology and ratio of agent-to-worker is dependent on the specific implementation of the agent and the user’s job placement preferences. For instance, to run a distributed training job on GPU with 8 trainers (one per GPU) one can:
Use 8 x single GPU instances, place an agent per instance, managing 1 worker per agent.
Use 4 x double GPU instances, place an agent per instance, managing 2 workers per agent.
Use 2 x quad GPU instances, place an agent per instance, managing 4 workers per agent.
Use 1 x 8 GPU instance, place an agent per instance, managing 8 workers per agent.
Usage
try: results = agent.run() return results[0] # return rank 0's results except WorkerGroupFailureException as e: exceptions = e.get_worker_exceptions() log.exception(f"worker 0 failed with: {exceptions[0]}") except Exception as e: log.exception(f"error while running agent")
-
abstract
get_worker_group(role: str = 'default') → torchelastic.agent.server.api.WorkerGroup[source] - Returns
The
WorkerGroupfor the givenrole. Note that the worker group is a mutable object and hence in a multi-threaded/process environment it may change state. Implementors are encouraged (but not required) to return a defensive read-only copy.
-
abstract
run(role: str = 'default') → Dict[int, Any][source] Runs the agent, retrying the worker group on failures up to
max_restarts.- Returns
The return values for each worker mapped by the worker’s global rank. Empty if workers have void signature.
- Raises
WorkerGroupFailureException - workers did not successfully run –
Exception - any other failures NOT related to worker process –
-
class
torchelastic.agent.server.WorkerSpec(role: str, local_world_size: int, fn: Callable, args: Tuple, rdzv_handler: torchelastic.rendezvous.api.RendezvousHandler, max_restarts: int = 100, monitor_interval: float = 5.0, master_port=None)[source] Contains blueprint information about a particular type of worker. For a given role, there must only exist a single worker spec. Worker spec is expected to be homogenous across all nodes (machine), that is each node runs the same number of workers for a particular spec.
-
class
torchelastic.agent.server.WorkerState[source] State of the
WorkerGroup. Workers in a worker group change state as a unit. If a single worker in a worker group fails the entire set is considered failed:UNKNOWN - agent lost track of worker group state, unrecoverable INIT - worker group object created not yet started HEALTHY - workers running and healthy UNHEALTHY - workers running and unhealthy STOPPED - workers stopped (interruped) by the agent SUCCEEDED - workers finished running (exit 0) FAILED - workers failed to successfully finish (exit !0)
A worker group starts from an initial
INITstate, then progresses toHEALTHYorUNHEALTHYstates, and finally reaches a terminalSUCCEEDEDorFAILEDstate.Worker groups can be interrupted and temporarily put into
STOPPEDstate by the agent. Workers inSTOPPEDstate are scheduled to be restarted in the near future by the agent. Some examples of workers being put intoSTOPPEDstate are:Worker group failure|unhealthy observed
Membership change detected
When actions (start, stop, rdzv, retry, etc) on worker group fails and results in the action being partially applied to the worker group the state will be
UNKNOWN. Typically this happens on uncaught/unhandled exceptions during state change events on the agent. The agent is not expected to recover worker groups inUNKNOWNstate and is better off self terminating and allowing the job manager to retry the node.
-
class
torchelastic.agent.server.Worker(local_rank: int)[source] Represents a worker instance. Contrast this with
WorkerSpecthat represents the specifications of a worker. AWorkeris created from aWorkerSpec. AWorkeris to aWorkerSpecas an object is to a class.The
idof the worker is interpreted by the specific implementation ofElasticAgent. For a local agent, it could be thepid (int)of the worker, for a remote agent it could be encoded ashost:port (string).
-
class
torchelastic.agent.server.WorkerGroup(spec: torchelastic.agent.server.api.WorkerSpec)[source] Represents the set of
Workerinstances for the givenWorkerSpecmanaged byElasticAgent. Whether the worker group contains cross instance workers or not depends on the implementation of the agent.
Implementations
Below are the agent implementations provided by torchelastic.
-
class
torchelastic.agent.server.local_elastic_agent.LocalElasticAgent(spec: torchelastic.agent.server.api.WorkerSpec, start_method='spawn')[source] An implementation of
torchelastic.agent.server.ElasticAgentthat handles host-local workers. This agent is deployed per host and is configured to spawnnworkers. When using GPUs,nmaps to the number of GPUs available on the host.The local agent does not communicate to other local agents deployed on other hosts, even if the workers may communicate inter-host. The worker id is interpreted to be a local process. The agent starts and stops all worker processes as a single unit.
The worker function and argument passed to the worker function must be python multiprocessing compatible. To pass multiprocessing data structures to the workers you may create the data structure in the same multiprocessing context as the specified
start_methodand pass it as a function argument.Example
def trainer(shared_queue): pass def main(): start_method="spawn" shared_queue= multiprocessing.get_context(start_method).Queue() spec = WorkerSpec( role="trainer", local_world_size=nproc_per_process, fn=trainer, args=(shared_queue,), ...<OTHER_PARAMS...>) agent = LocalElasticAgent(spec, start_method) agent.run()
Extending the Agent
To extend the agent you can implement `ElasticAgent directly, however
we recommend you extend SimpleElasticAgent instead, which provides
most of the scaffolding and leaves you with a few specific abstract methods
to implement.
-
class
torchelastic.agent.server.SimpleElasticAgent(spec: torchelastic.agent.server.api.WorkerSpec)[source] An
ElasticAgentthat manages workers (WorkerGroup) for a singleWorkerSpec(e.g. one particular type of worker role).-
_initialize_workers(worker_group: torchelastic.agent.server.api.WorkerGroup) → None[source] Starts a fresh set of workers for the worker_group. Essentially a rendezvous followed by a start_workers.
The caller should first call
_stop_workers()to stop running workers prior to calling this method.Optimistically sets the state of the worker group that just started as
HEALTHYand delegates the actual monitoring of state to_monitor_workers()method
-
abstract
_monitor_workers(worker_group: torchelastic.agent.server.api.WorkerGroup) → torchelastic.agent.server.api.MonitorResult[source] Checks on the workers for the
worker_groupand returns the new state of the worker group.
-
_rendezvous(worker_group: torchelastic.agent.server.api.WorkerGroup) → None[source] Runs rendezvous for the workers specified by worker spec. Assigns workers a new global rank and world size. Updates the rendezvous store for the worker group.
-
_restart_workers(worker_group: torchelastic.agent.server.api.WorkerGroup) → None[source] Restarts (stops, rendezvous, starts) all local workers in the group.
-
abstract
_start_workers(worker_group: torchelastic.agent.server.api.WorkerGroup) → Dict[int, Any][source] Starts
worker_group.spec.local_world_sizenumber of workers according to worker spec for the worker group .Returns a map of
local_rankto workerid.
-
abstract
_stop_workers(worker_group: torchelastic.agent.server.api.WorkerGroup) → None[source] Stops all workers in the given worker group. Implementors must deal with workers in all states defined by
WorkerState. That is, it must gracefully handle stopping non-existent workers, unhealthy (stuck) workers, etc.
-
get_worker_group() → torchelastic.agent.server.api.WorkerGroup[source] Returns: The
WorkerGroupfor the givenrole. Note that the worker group is a mutable object and hence in a multi-threaded/process environment it may change state. Implementors are encouraged (but not required) to return a defensive read-only copy.
-
run(role: str = 'default') → Dict[int, Any][source] Runs the agent, retrying the worker group on failures up to
max_restarts.- Returns
The return values for each worker mapped by the worker’s global rank. Empty if workers have void signature.
- Raises
WorkerGroupFailureException - workers did not successfully run –
Exception - any other failures NOT related to worker process –
-
-
class
torchelastic.agent.server.api.MonitorResult(state: torchelastic.agent.server.api.WorkerState, ret_vals: Dict[int, Any] = None, exceptions: Dict[int, Exception] = None)[source] Returned by the agent’s
_monitor_workersAPI. A holder object that holds information about the monitoring results. Theret_valsandexceptionsfield map each worker’s return value (output) and exceptions (if any) accordingly by the workers global rank.state = SUCCEEDEDwill haveret_val.state = FAILEDwill haveexceptions. For other states both these fields will be empty.
