We are pleased to officially announce torchcodec, a library for decoding videos into PyTorch tensors. It is fast, accurate, and easy to use. When running PyTorch models on videos, torchcodec is our recommended way to turn those videos into data your model can use.
Highlights of torchcodec include:
- An intuitive decoding API that treats a video file as a Python sequence of frames. We support both index-based and presentation-time-based frame retrieval.
- An emphasis on accuracy: we ensure you get the frames you requested, even if your video has variable frame rates.
- A rich sampling API that makes it easy and efficient to retrieve batches of frames.
- Best-in-class CPU decoding performance.
- CUDA accelerated decoding that enables high throughput when decoding many videos at once.
- Support for all codecs available in your installed version of FFmpeg.
- Simple binary installs for Linux and Mac.
Easy to Use
A simple, intuitive API was one of our main design principles. We start with simple decoding and extracting specific frames of a video:
from torchcodec.decoders import VideoDecoder
from torch import Tensor
decoder = VideoDecoder("my_video.mp4")
# Index based frame retrieval.
first_ten_frames: Tensor = decoder[10:]
last_ten_frames: Tensor = decoder[-10:]
# Multi-frame retrieval, index and time based.
frames = decoder.get_frames_at(indices=[10, 0, 15])
frames = decoder.get_frames_played_at(seconds=[0.2, 3, 4.5])
All decoded frames are already PyTorch tensors, ready to be fed into models for training.
Of course, more common in ML training pipelines is sampling multiple clips from videos. A clip is just a sequence of frames in presentation order—but the frames are often not consecutive. Our sampling API makes this easy:
from torchcodec.samplers import clips_at_regular_timestamps
clips = clips_at_regular_timestamps(
decoder,
seconds_between_clip_starts=10,
num_frames_per_clip=5,
seconds_between_frames=0.2,
)
The above call yields a batch of clips where each clip starts 10 seconds apart, each clip has 5 frames, and those frames are 0.2 seconds apart. See our tutorials on decoding and sampling for more!
Fast Performance
Performance was our other main design principle. Decoding videos for ML training has different performance requirements than decoding videos for playback. A typical ML video training pipeline will process many different videos (sometimes in the millions!), but only sample a small number of frames (dozens to hundreds) from each video.
For this reason, we’ve paid particular attention to our decoder’s performance when seeking multiple times in a video, decoding a small number of frames after each seek. We present experiments with the following four scenarios:
- Decoding and transforming frames from multiple videos at once, inspired by what we have seen in data loading for large-scale training pipelines:a. Ten threads decode batches of 50 videos in parallel.
b. For each video, decode 10 frames at evenly spaced times.
c. For each frame, resize it to a 256×256 resolution. - Decoding 10 frames at random locations in a single video.
- Decoding 10 frames at evenly spaced times of a single video.
- Decoding the first 100 frames of a single video.
We compare the following video decoders:
- Torchaudio, CPU decoding only.
- Torchvision, using the video_reader backend which is CPU decoding only.
- Torchcodec, GPU decoding with CUDA.
- Torchcodec, CPU decoding only.
Using the following three videos:
- A synthetically generated video using FFmpeg’s mandelbrot generation pattern. The video is 10 seconds long, 60 frames per second and 1920×1080.
- Same as above, except the video is 120 seconds long.
- A promotional video from NASA that is 206 seconds long, 29.7 frames per second and 960×540.
The experimental script is in our repo. Our experiments run on a Linux system with an Intel processor that has 22 available cores and an NVIDIA GPU. For CPU decoding, all libraries were instructed to automatically determine the best number of threads to use.
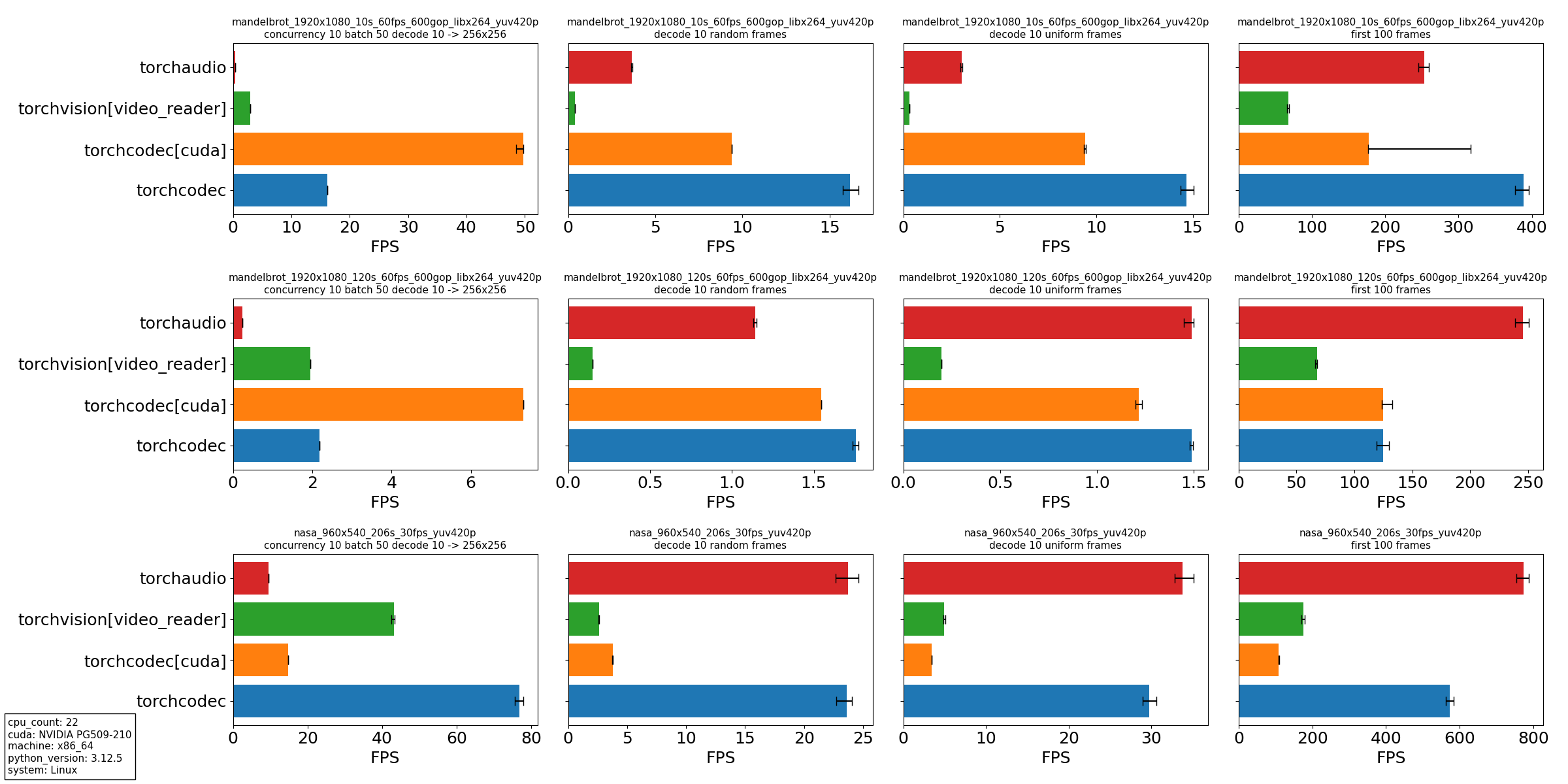
From our experiments, we draw several conclusions:
- Torchcodec is consistently the best-performing library for the primary use case we designed it for: decoding many videos at once as a part of a training data loading pipeline. In particular, high-resolution videos see great gains with CUDA where decoding and transforms both happen on the GPU.
- Torchcodec is competitive on the CPU with seek-heavy use cases such as random and uniform sampling. Currently, torchcodec’s performance is better with shorter videos that have a smaller file size. This performance is due to torchcodec’s emphasis on seek-accuracy, which involves an initial linear scan.
- Torchcodec is not as competitive when there is no seeking; that is, opening a video file and decoding from the beginning. This is again due to our emphasis on seek-accuracy and the initial linear scan.
Implementing an approximate seeking mode in torchcodec should resolve these performance gaps, and it’s our highest priority feature for video decoding.
What’s Next?
As the name implies, the long-term future for torchcodec is more than just video decoding. Our next big feature is audio support—both decoding audio streams from video, and from audio-only media. In the long term, we want torchcodec to be the media decoding library for PyTorch. That means as we implement functionality in torchcodec, we will deprecate and eventually remove complementary features from torchaudio and torchvision.
We also have video decoding improvements lined up, such as the previously mentioned approximate seeking mode for those who are willing to sacrifice accuracy for performance.
Most importantly, we’re looking for feedback from the community! We’re most interested in working on features that the community finds valuable. Come share your needs and influence our future direction!