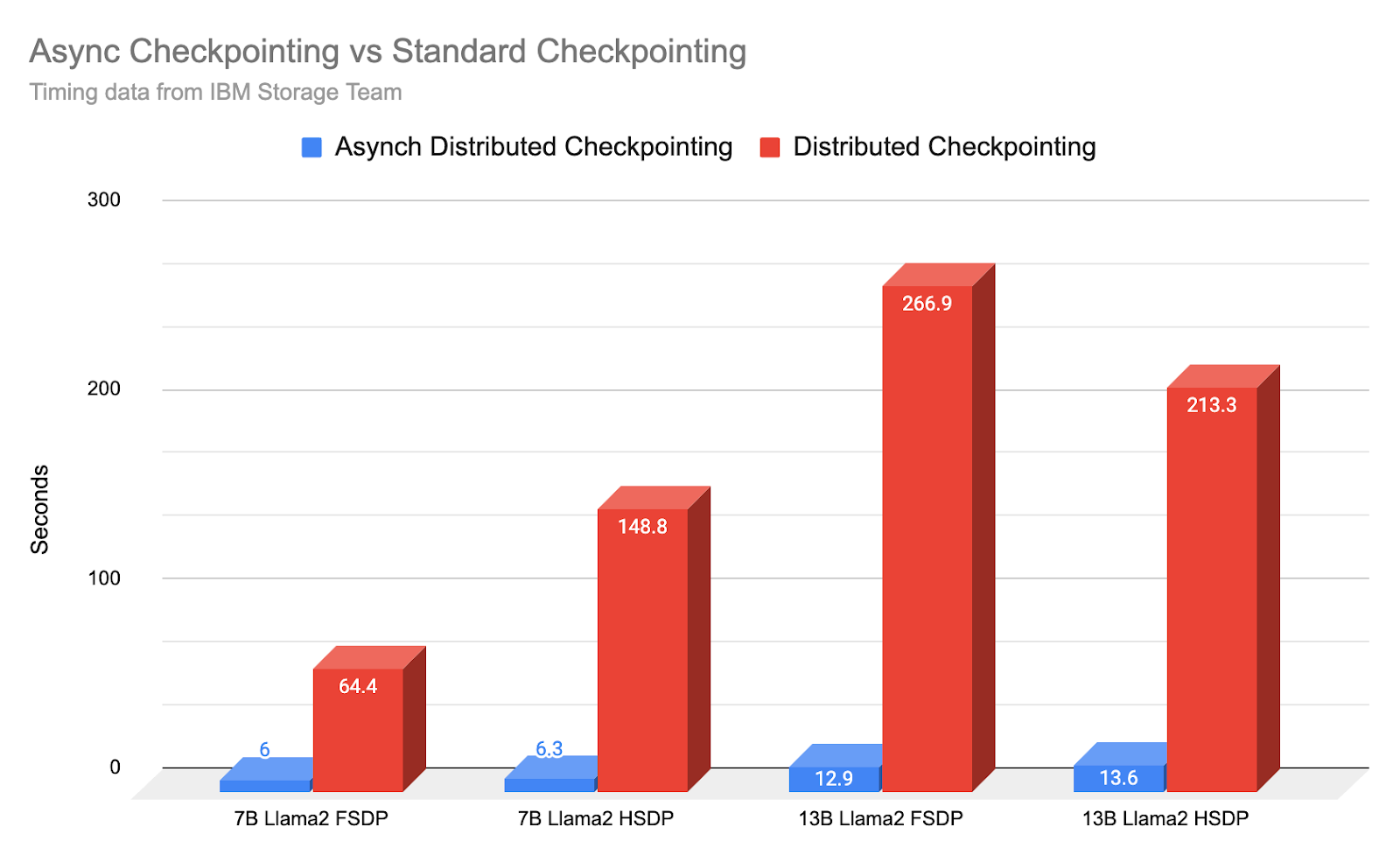
Summary: With PyTorch distributed’s new asynchronous checkpointing feature, developed with feedback from IBM, we show how IBM Research Team is able to implement and reduce effective checkpointing time by a factor of 10-20x. Example: 7B model ‘down time’ for a checkpoint goes from an average of 148.8 seconds to 6.3 seconds, or 23.62x faster.
This directly translates into either more net training progress for every given 24 hour period while continuing to robustly checkpoint or more frequent checkpoints to shorten recovery window/time.
In this note, we showcase the usage code and architecture that makes asynchronous checkpointing possible, along with timing results verified by IBM’s Research team.
Model checkpointing is a vital part of large model training, but checkpointing is an expensive process as each checkpoint process involves blocking training progress in order to save out the latest model weights. However, not checkpointing or reducing checkpointing frequency can result in a significant loss in training progress. For example, failures such as a deadlock, straggler, and gpu errors require the training process to be restarted. In order to restart from a failure, all (training) workers must stop their training process and be restarted from the last saved checkpoint.
Thus, the inherent tension between robustness to failures vs training progress plays out as a tradeoff, but now with asynchronous checkpointing, PyTorch Distributed is able to significantly reduce this tension and enable frequent checkpoint with minimal impact to the overall training time.
For background, it was almost exactly a year ago that we showcased how distributed checkpointing had massively sped up checkpointing times from the original torch.save() functionality. As IBM Research had noted, torch.save could take up to 30 minutes to checkpoint a single 11B model (PyTorch 1.13).
With advancements in distributed checkpointing, checkpoints could be done in under 4 minutes for up to 30B model sizes.
With asynchronous checkpointing, the training time lost due to checkpointing now moves to under 30 seconds, and often as short as 6 seconds.
To be clear, asynchronous checkpointing does not compress the actual serialization checkpointing time as the previous update showcased. Rather it moves the final checkpointing process off the critical path (to cpu threads) to allow GPU training to continue while finalizing the checkpoint under separate threads.
However, to the user, the effect is nearly the same in that down time for training due to checkpointing is substantially reduced, in many cases by 10x or even 20x.
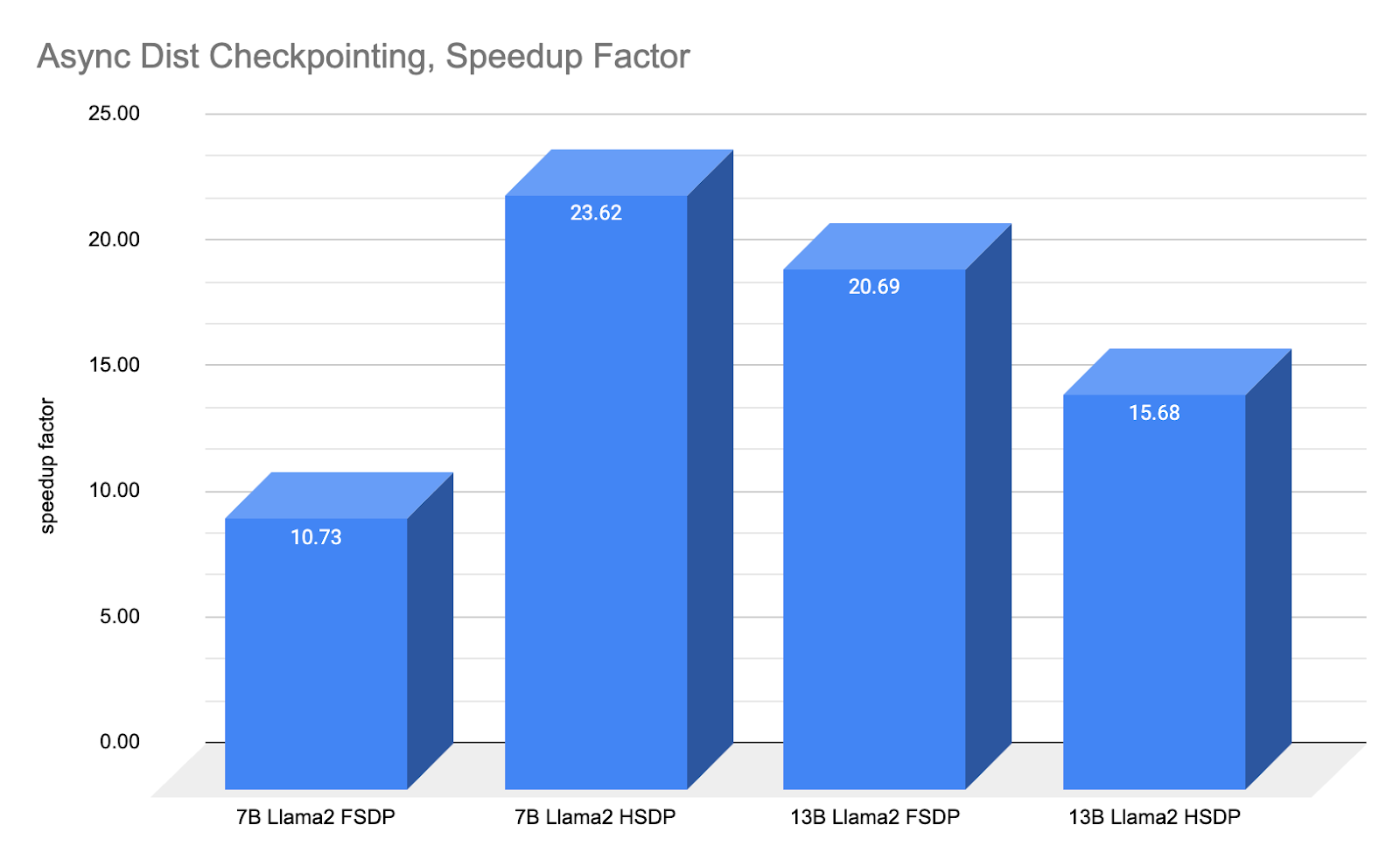
As the above speedup chart shows, asynchronous checkpointing produces a 10x to 23x further improvement over the previous large improvements from a year ago.
How does Asynchronous Checkpointing work?
Asynchronous checkpointing modularizes the checkpointing process into two parts rather than one monolithic process. The first phase copies the data from each gpu/rank from GPU to CPU. This is the visible downtime to the user and can take from 6 – 14 seconds for 7B-13B model sizes. The second phase asynchronously copies the data from CPU memory to disk to persist the checkpoint.
Once data is copied to CPU in the first phase, the GPU is free to immediately resume training. Hence with asynchronous checkpointing the downtime for checkpointing is simply the time needed to copy over the latest model states to CPU.
At the same time that training resumes, non-blocking CPU threads work with the freshly arrived data in memory to complete the full checkpointing/serialization process to disk (i.e. persistent save).

Note that PyTorch’s Distributed Checkpointer relies on collective communication calls for per-rank metadata necessary to optimize saves, as well as a final synchronization which marks checkpointing as complete and makes the action atomic. This can interfere with distributed training (as distributed training also relies upon similar calls to synchronize training across multiple GPUs) if the Checkpointing thread utilizes the same process group used for training.
Specifically, a race condition between the calls could potentially cause training and asynch checkpointing save threads to wait on collective calls at the same time, resulting in a true collective hang.
We avoided this scenario by initializing a separate process group for async checkpointing. This separates the checkpointing collectives into their own logical process group, which thus ensures it will not interfere with collective calls in the main training threads.
How do I use Asynchronous Checkpointing in my training?
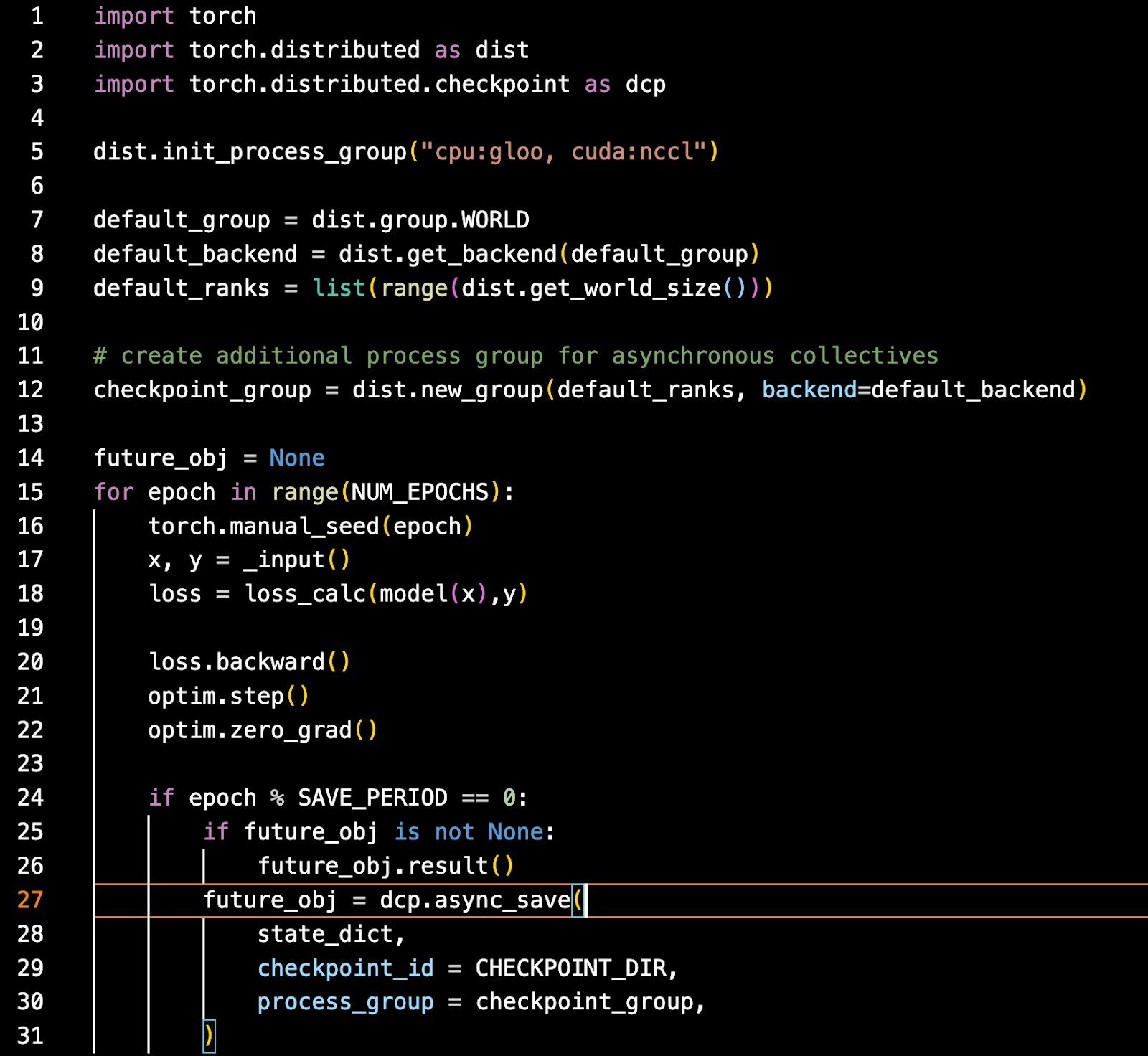
Usage of Asynchronous checkpointing is relatively straightforward. Using the latest nightly version of PyTorch, you will want to initialize your process group with both nccl and gloo. Gloo is required for the cpu threads portion.
From there, create a duplicate process group which the asynchronous checkpointing will utilize. Then train as usual but at the point when you want to checkpoint, use the asynchronous save api, passing in the states to save, the checkpoint id and the checkpoint process group.
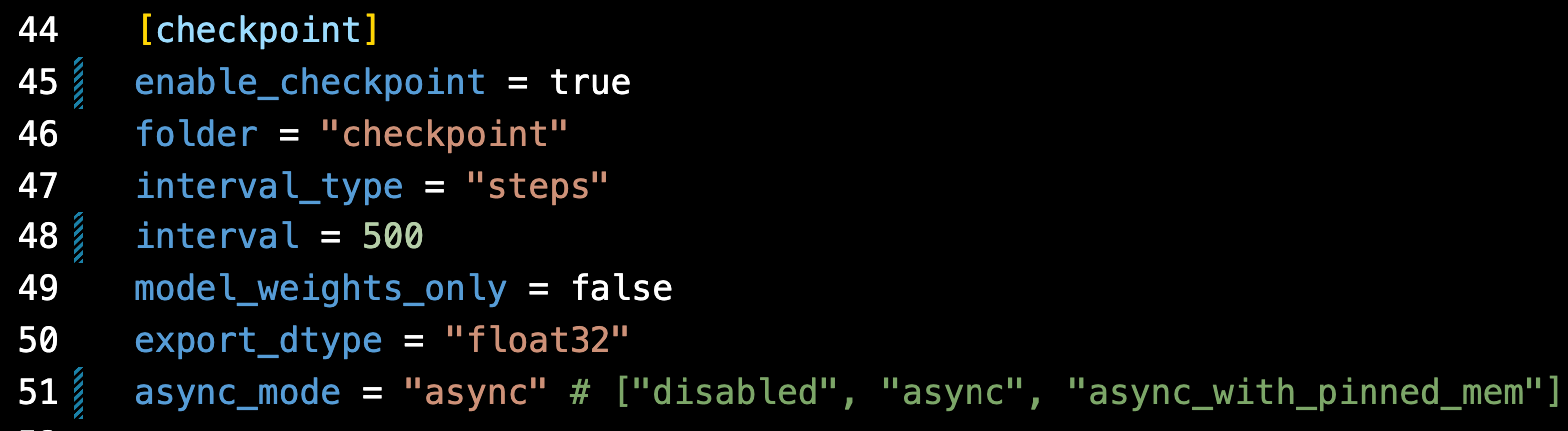
Asynchronous checkpointing is also fully implemented in torchtitan. Here, it is implemented for use with pre-training your own Llama2 or Lllama3 model. Using it is as simple as updating the toml config file:
Future work
Checkpointing has made huge strides over the past year. Moving from almost half an hour checkpoints to under 5 minutes with distributed checkpointing and now to under 30 seconds with asynchronous checkpointing.
The last frontier – zero overhead checkpointing where even the < 30 seconds is eliminated by streaming the updated weights during the backward pass such that checkpoint data is already on cpu at the point asynchronous checkpointing would kick in.
This would effectively move large model training to where checkpointing has no disruption or downtime enabling both more robustness (as checkpoints could be taken more frequently) and faster training progress due to no downtime for checkpointing.
Source code link: https://github.com/pytorch/pytorch/blob/main/torch/distributed/checkpoint/state_dict_saver.py