We demonstrate how to finetune a 7B parameter model on a typical consumer GPU (NVIDIA T4 16GB) with LoRA and tools from the PyTorch and Hugging Face ecosystem with complete reproducible Google Colab notebook.
Introduction
Large Language Models (LLMs) have shown impressive capabilities in industrial applications. Often, developers seek to tailor these LLMs for specific use-cases and applications to fine-tune them for better performance. However, LLMs are large by design and require a large number of GPUs to be fine-tuned.
Let’s focus on a specific example by trying to fine-tune a Llama model on a free-tier Google Colab instance (1x NVIDIA T4 16GB). Llama-2 7B has 7 billion parameters, with a total of 28GB in case the model is loaded in full-precision. Given our GPU memory constraint (16GB), the model cannot even be loaded, much less trained on our GPU. This memory requirement can be divided by two with negligible performance degradation. You can read more about running models in half-precision and mixed precision for training here.
What makes our Llama fine-tuning expensive?
In the case of full fine-tuning with Adam optimizer using a half-precision model and mixed-precision mode, we need to allocate per parameter:
- 2 bytes for the weight
- 2 bytes for the gradient
- 4 + 8 bytes for the Adam optimizer states
→ With a total of 16 bytes per trainable parameter, this makes a total of 112GB (excluding the intermediate hidden states). Given that the largest GPU available today can have up to 80GB GPU VRAM, it makes fine-tuning challenging and less accessible to everyone. To bridge this gap, Parameter Efficient Fine-Tuning (PEFT) methods are largely adopted today by the community.
Parameter Efficient Fine-Tuning (PEFT) methods
PEFT methods aim at drastically reducing the number of trainable parameters of a model while keeping the same performance as full fine-tuning.
They can be differentiated by their conceptual framework: does the method fine-tune a subset of existing parameters, introduce new parameters, introduce trainable prompts, etc.? We recommend readers to have a look at the paper shared below that extensively compares existing PEFT methods.
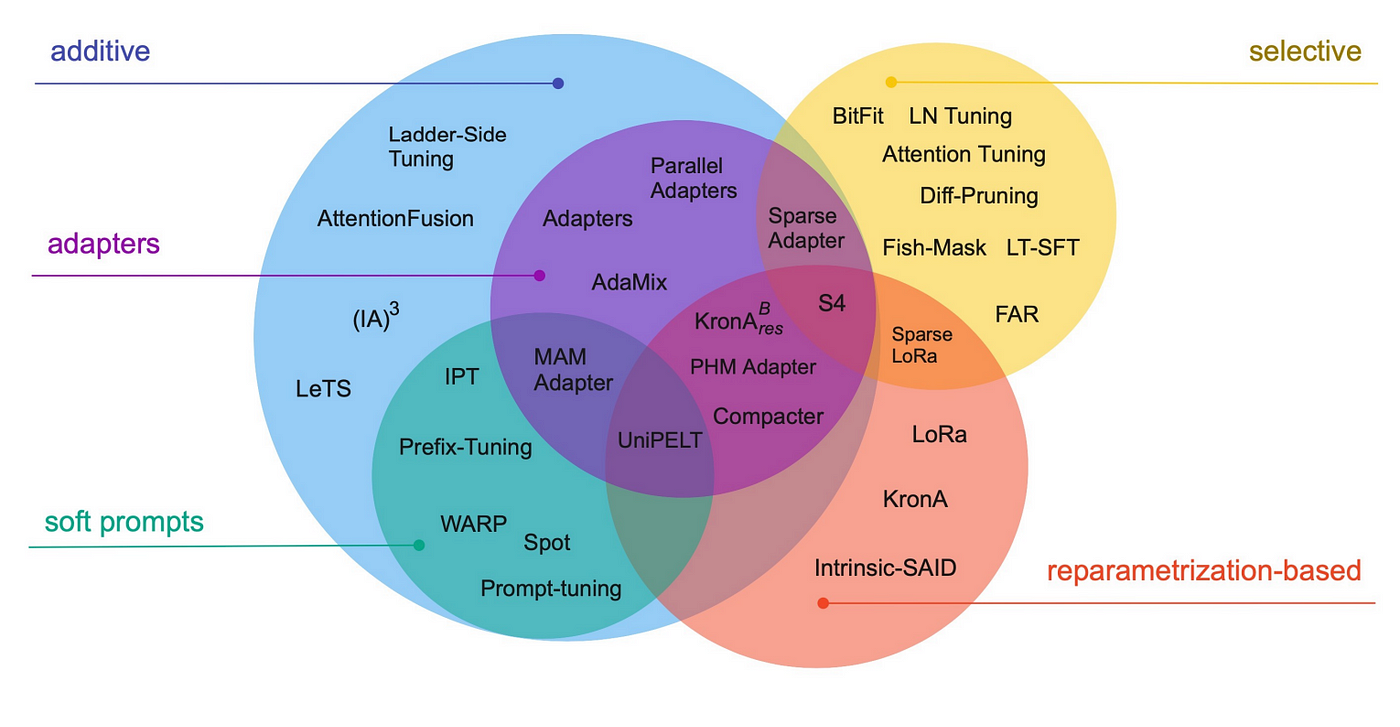
Image taken from the paper: Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
For this blog post, we will focus on Low-Rank Adaption for Large Language Models (LoRA), as it is one of the most adopted PEFT methods by the community.
Low-Rank Adaptation for Large Language Models (LoRA) using 🤗 PEFT
The LoRA method by Hu et al. from the Microsoft team came out in 2021, and works by attaching extra trainable parameters into a model(that we will denote by base model).
To make fine-tuning more efficient, LoRA decomposes a large weight matrix into two smaller, low-rank matrices (called update matrices). These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
This approach has several advantages:
- LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
- The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
- LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
- The performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
- LoRA does not add any inference latency when adapter weights are merged with the base model
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, in Transformer models LoRA is typically applied to attention blocks only. The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
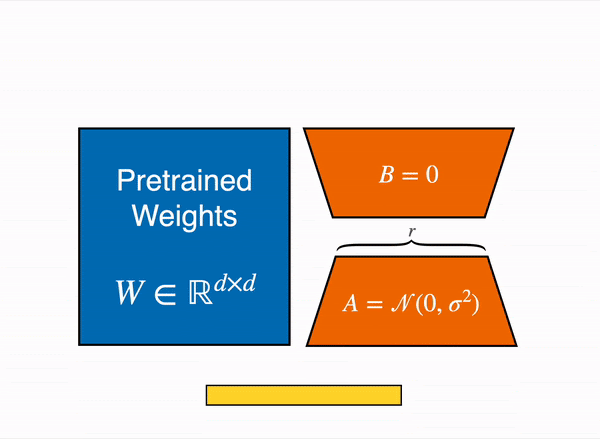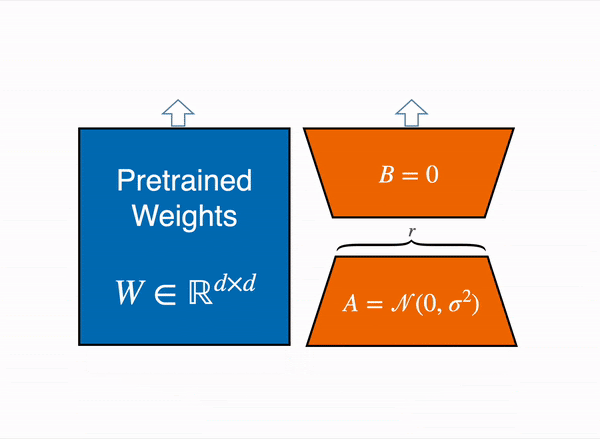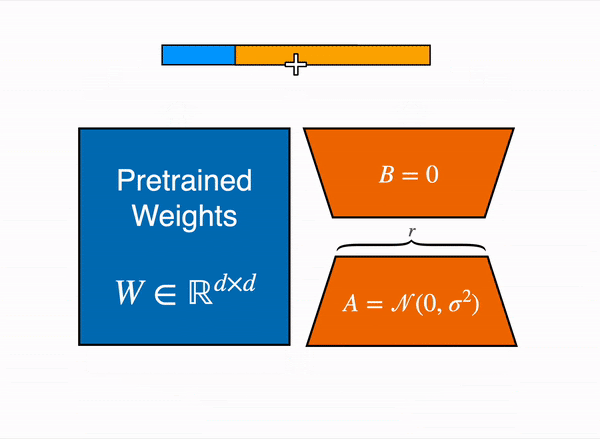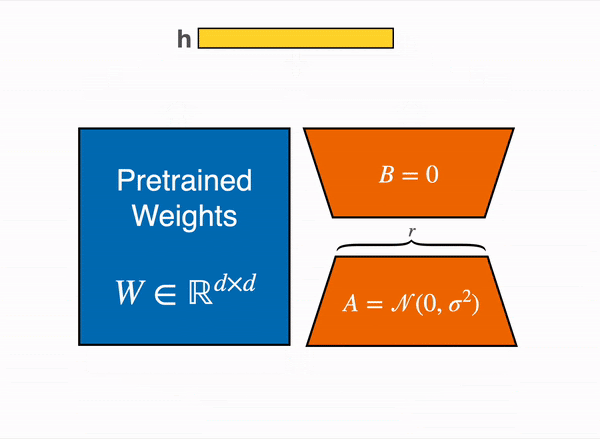
Animated diagram that show how LoRA works in practice – original content adapter from the figure 1 of LoRA original paper
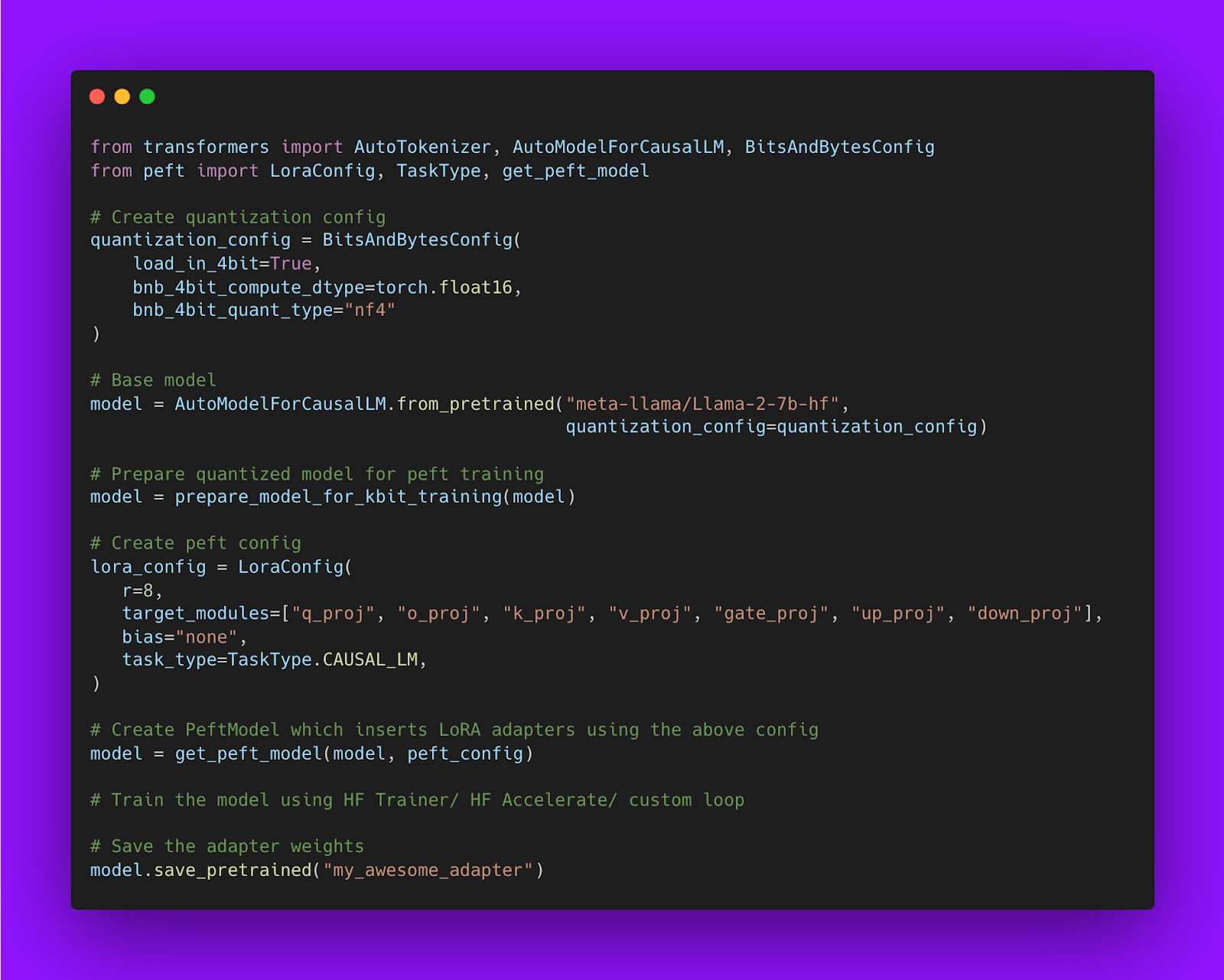
Below is a code snippet showing how to train LoRA model using Hugging Face PEFT library:
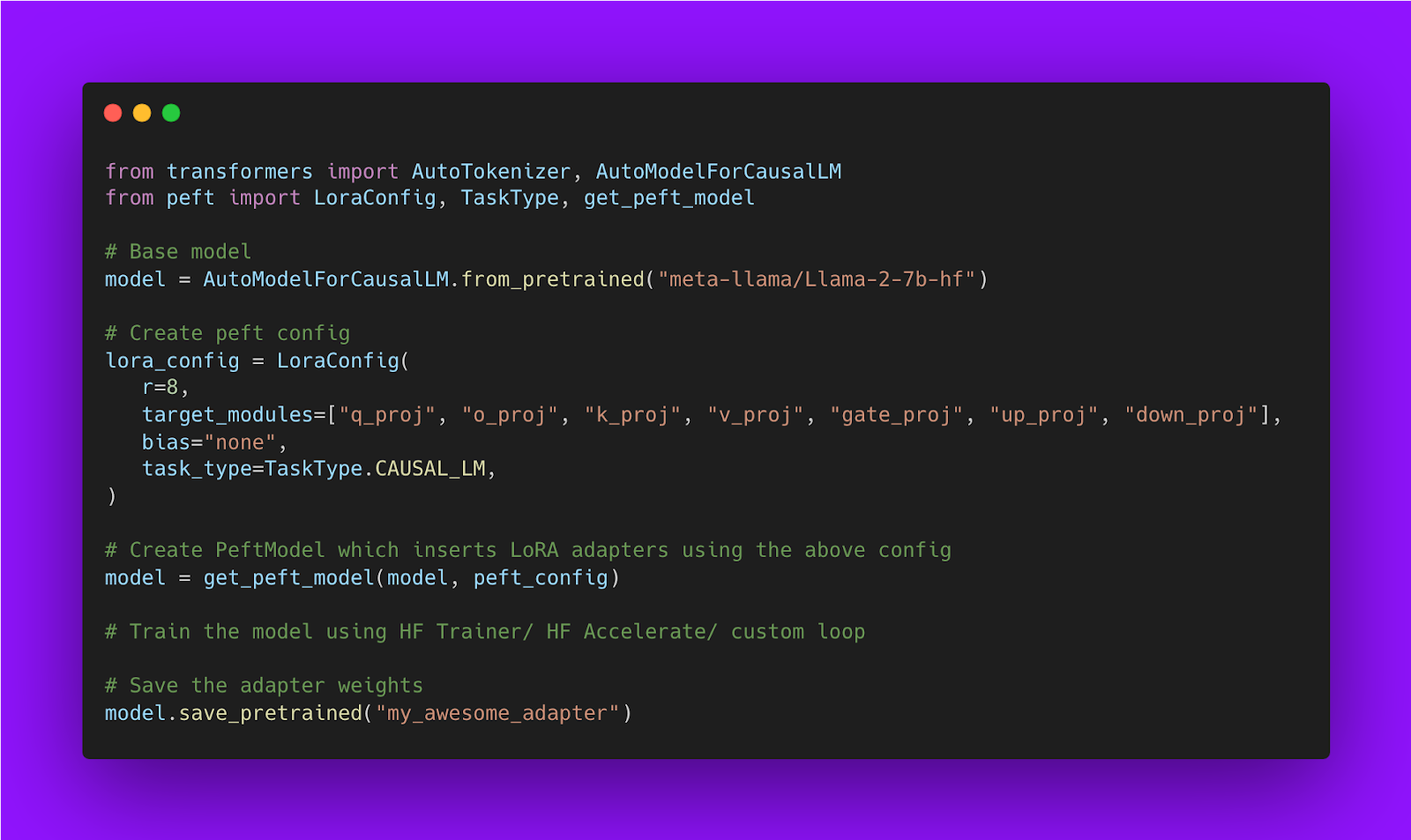
The base model can be in any dtype: leveraging SOTA LLM quantization and loading the base model in 4-bit precision
According to the LoRA formulation, the base model can be compressed in any data type (‘dtype’) as long as the hidden states from the base model are in the same dtype as the output hidden states from the LoRA matrices.
Compressing and quantizing large language models has recently become an exciting topic as SOTA models become larger and more difficult to serve and use for end users. Many people in the community proposed various approaches for effectively compressing LLMs with minimal performance degradation.
This is where the bitsandbytes library comes in. Its purpose is to make cutting-edge research by Tim Dettmers, a leading academic expert on quantization and the use of deep learning hardware accelerators, accessible to the general public.
QLoRA: One of the core contributions of bitsandbytes towards the democratization of AI
Quantization of LLMs has largely focused on quantization for inference, but the QLoRA (Quantized model weights + Low-Rank Adapters) paper showed the breakthrough utility of using backpropagation through frozen, quantized weights at large model scales.
With QLoRA we are matching 16-bit fine-tuning performance across all scales and models, while reducing fine-tuning memory footprint by more than 90%— thereby allowing fine-tuning of SOTA models on consumer-grade hardware.
In this approach, LoRA is pivotal both for purposes of fine-tuning and the correction of minimal, residual quantization errors. Due to the significantly reduced size of the quantized model it becomes possible to generously place low-rank adaptors at every network layer, which together still make up just 0.2% of the original model’s weight memory footprint. Through such usage of LoRA, we achieve performance that has been shown to be equivalent to 16-bit full model finetuning.
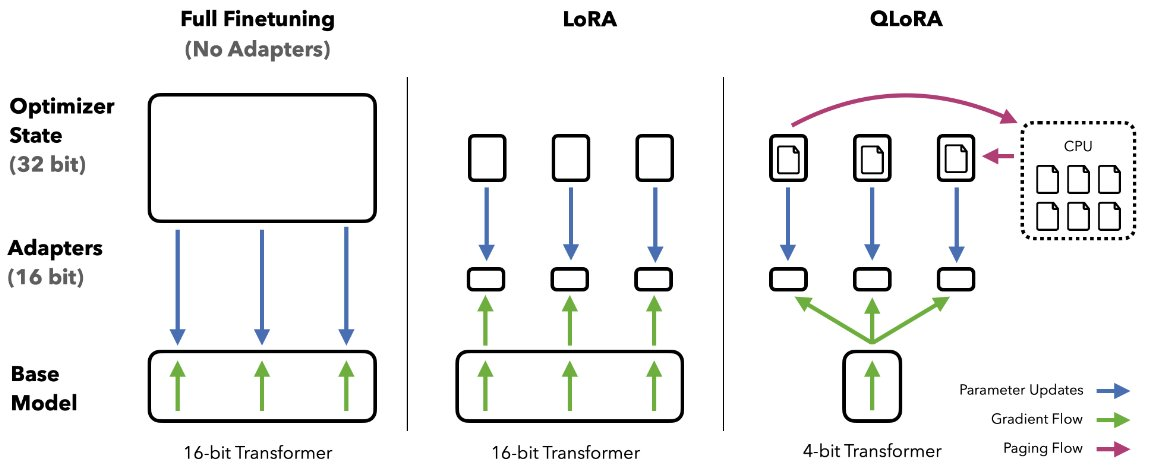
In addition to generous use of LoRA, to achieve high-fidelity fine-tuning of 4-bit models, QLoRA uses 3 further algorithmic tricks:
- 4-bit NormalFloat (NF4) quantization, a custom data type exploiting the property of the normal distribution of model weights and distributing an equal number of weights (per block) to each quantization bin—thereby enhancing information density.
- Double Quantization, quantization of the quantization constants (further savings).
- Paged Optimizers, preventing memory spikes during gradient checkpointing from causing out-of-memory errors.
An interesting aspect is the dequantization of 4-bit weights in the GPU cache, with matrix multiplication performed as a 16-bit floating point operation. In other words, we use a low-precision storage data type (in our case 4-bit, but in principle interchangeable) and one normal precision computation data type. This is important because the latter defaults to 32-bit for hardware compatibility and numerical stability reasons, but should be set to the optimal BFloat16 for newer hardware supporting it to achieve the best performance.
To conclude, through combining these refinements to the quantization process and generous use of LoRA, we compress the model by over 90% and retain full model performance without the usual quantization degradation, while also retaining full fine-tuning capabilities with 16-bit LoRA adapters at every layer.
Using QLoRA in practice
These SOTA quantization methods come packaged in the bitsandbytes library and are conveniently integrated with HuggingFace 🤗 Transformers. For instance, to use LLM.int8 and QLoRA algorithms, respectively, simply pass load_in_8bit and load_in_4bit to the from_pretrained method.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-125m"
# For LLM.int8()
# model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True)
# For QLoRA
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
You can read more about quantization features in this specific section of the documentation: https://huggingface.co/docs/transformers/main_classes/quantization
When using QLoRA with Adam optimizer using a 4-bit base model and mixed-precision mode, we need to allocate per parameter:
- ~0.5 bytes for the weight
- 2 bytes for the gradient
- 4 + 8 bytes for the Adam optimizer states
Giving a total of 14 bytes per trainable parameter times 0.0029 as we end up having only 0.29% trainable parameters with QLoRA, this makes the QLoRA training setup cost around 4.5GB to fit, but requires in practice ~7-10GB to include intermediate hidden states which are always in half-precision (7 GB for a sequence length of 512 and 10GB for a sequence length of 1024) in the Google Colab demo shared in the next section.
Below is the code snippet showing how to train QLoRA model using Hugging Face PEFT:
Using TRL for LLM training
Models such as ChatGPT, GPT-4, and Claude are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them. The finetuning goes through 3 steps:
- Supervised Fine-tuning (SFT)
- Reward / preference modeling (RM)
- Reinforcement Learning from Human Feedback (RLHF)
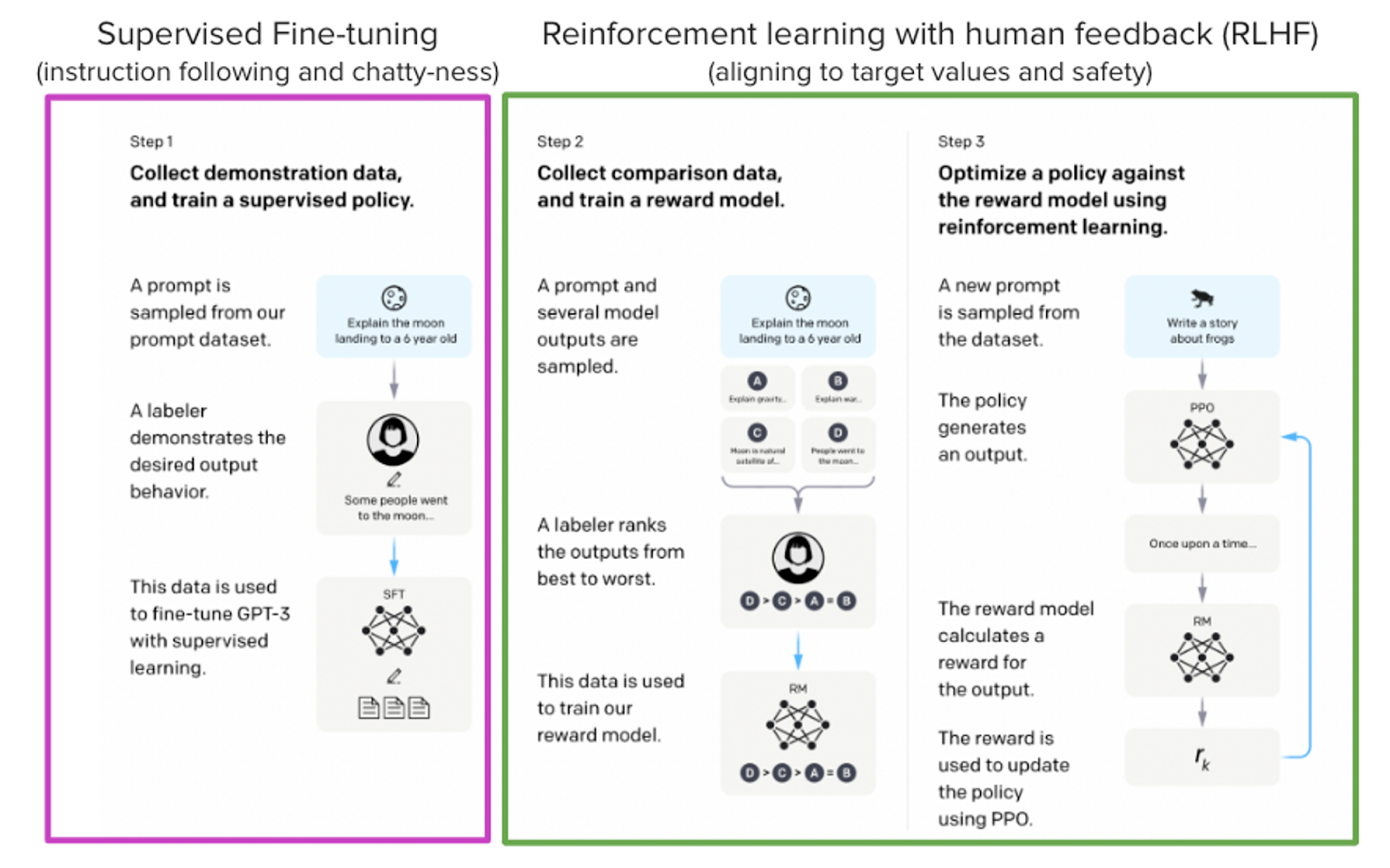
From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
Here, we will only focus on the supervised fine-tuning step. We train the model on the new dataset following a process similar to that of pretraining. The objective is to predict the next token (causal language modeling). Multiple techniques can be applied to make the training more efficient:
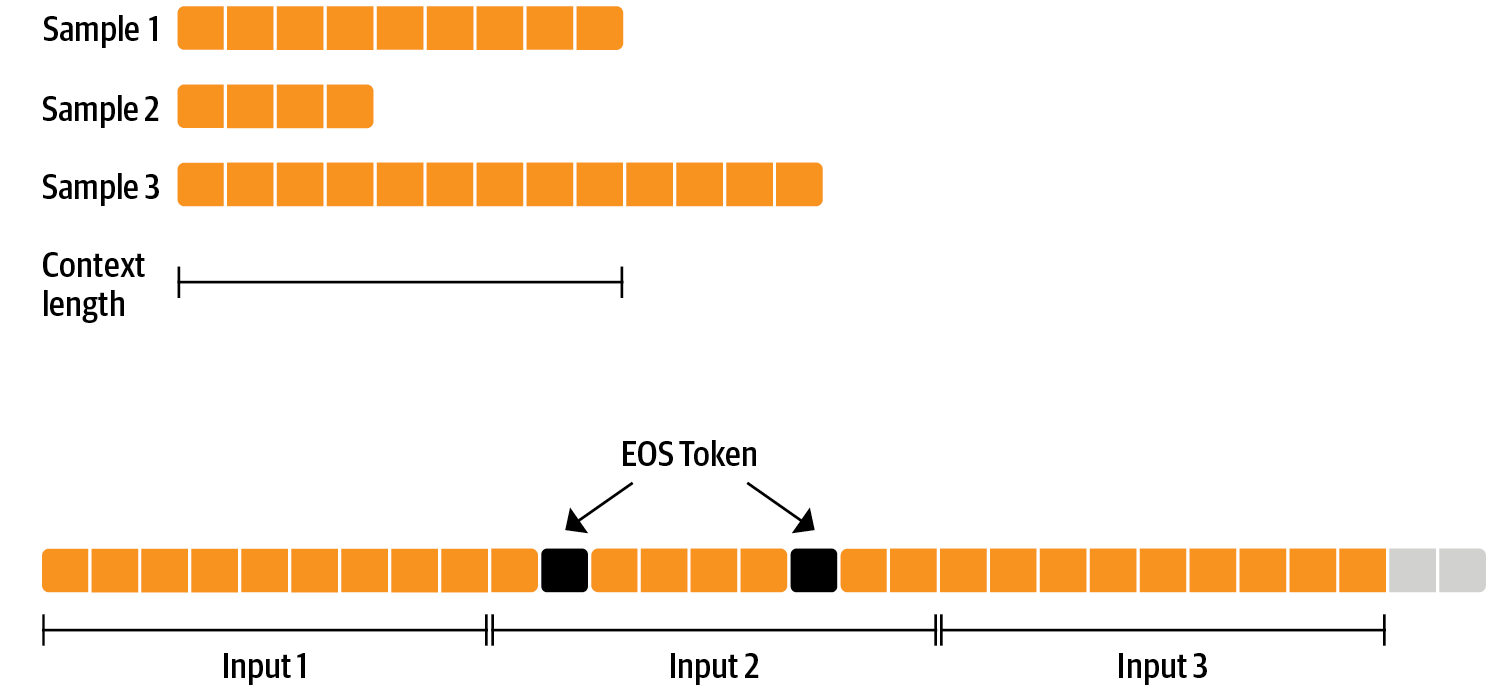
- Packing: Instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with an End-Of-Sentence (EOS) token in between and cut chunks of the context size to fill the batch without any padding. This approach significantly improves training efficiency as each token processed by the model contributes to training.
- Train on completion only: We want the model to be able to understand the prompt and generate an answer/. Instead of training the model on the whole input (prompt + answer), the training will be more efficient if we only train the model on completion.
You can perform supervised fine-tuning with these techniques using SFTTrainer:
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
packing=True,
)
Since SFTTrainer back-end is powered by 🤗accelerate, you can easily adapt the training to your hardware setup in one line of code!
For example, with you have 2 GPUs, you can perform Distributed Data Parallel training with using the following command:
accelerate launch --num_processes=2 training_llama_script.py
Putting all the pieces together
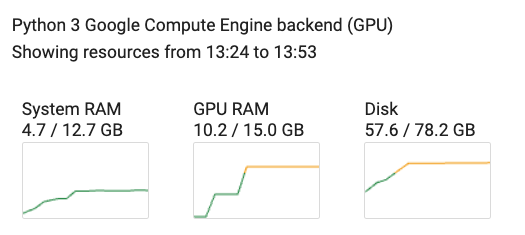
We made a complete reproducible Google Colab notebook that you can check through this link. We use all the components shared in the sections above and fine-tune a llama-7b model on UltraChat dataset using QLoRA. As it can be observed through the screenshot below, when using a sequence length of 1024 and a batch size od 4, the memory usage remains very low (around 10GB).