Overview
Memory formats has significant impact on performance when running vision models, generally Channels Last is a more favorable from performance perspective due to better data locality.
This blog will introduce fundamental concepts of memory formats and demonstrate performance benefits using Channels Last on popular PyTorch vision models on Intel® Xeon® Scalable processors.
Memory Formats Introduction
Memory format refers to data representation that describes how a multidimensional (nD) array is stored in linear (1D) memory address space. The concept of memory format has two aspects:
- Physical Order is the layout of data storage in physical memory. For vision models, usually we talk about NCHW, NHWC. These are the descriptions of physical memory layout, also referred as Channels First and Channels Last respectively.
- Logical Order is a convention on how to describe tensor shape and stride. In PyTorch, this convention is NCHW. No matter what the physical order is, tensor shape and stride will always be depicted in the order of NCHW.
Fig-1 is the physical memory layout of a tensor with shape of [1, 3, 4, 4] on both Channels First and Channels Last memory format (channels denoted as R, G, B respectively):

Fig-1 Physical memory layout of Channels First and Channels Last
Memory Formats Propagation
The general rule for PyTorch memory format propagation is to preserve the input tensor’s memory format. Which means a Channels First input will generate a Channels First output and a Channels Last input will generate a Channels Last output.
For Convolution layers, PyTorch uses oneDNN (oneAPI Deep Neural Network Library) by default to achieve optimal performance on Intel CPUs. Since it is physically impossible to achieve highly optimized performance directly with Channels Frist memory format, input and weight are firstly converted to blocked format and then computed. oneDNN may choose different blocked formats according to input shapes, data type and hardware architecture, for vectorization and cache reuse purposes. The blocked format is opaque to PyTorch, so the output needs to be converted back to Channels First. Though blocked format would bring about optimal computing performance, the format conversions may add overhead and therefore offset the performance gain.
On the other hand, oneDNN is optimized for Channels Last memory format to use it for optimal performance directly and PyTorch will simply pass a memory view to oneDNN. Which means the conversion of input and output tensor is saved. Fig-2 indicates memory format propagation behavior of convolution on PyTorch CPU (the solid arrow indicates a memory format conversion, and the dashed arrow indicates a memory view):
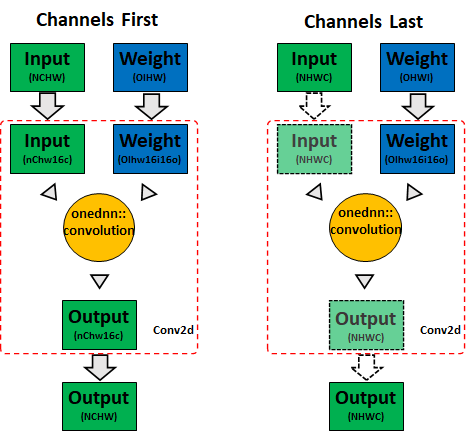
Fig-2 CPU Conv memory format propagation
On PyTorch, the default memory format is Channels First. In case a particular operator doesn’t have support on Channels Last, the NHWC input would be treated as a non-contiguous NCHW and therefore fallback to Channels First, which will consume the previous memory bandwidth on CPU and result in suboptimal performance.
Therefore, it is very important to extend the scope of Channels Last support for optimal performance. And we have implemented Channels Last kernels for the commonly use operators in CV domain, applicable for both inference and training, such as:
- Activations (e.g., ReLU, PReLU, etc.)
- Convolution (e.g., Conv2d)
- Normalization (e.g., BatchNorm2d, GroupNorm, etc.)
- Pooling (e.g., AdaptiveAvgPool2d, MaxPool2d, etc.)
- Shuffle (e.g., ChannelShuffle, PixelShuffle)
Refer to Operators-with-Channels-Last-support for details.
Native Level Optimization on Channels Last
As mentioned above, PyTorch uses oneDNN to achieve optimal performance on Intel CPUs for convolutions. The rest of memory format aware operators are optimized at PyTorch native level, which doesn’t require any third-party library support.
- Cache friendly parallelization scheme: keep the same parallelization scheme for all the memory format aware operators, this will help increase data locality when passing each layer’s output to the next.
- Vectorization on multiple archs: generally, we can vectorize on the most inner dimension on Channels Last memory format. And each of the vectorized CPU kernels will be generated for both AVX2 and AVX512.
While contributing to Channels Last kernels, we tried our best to optimize Channels First counterparts as well. The fact is some operators are physically impossible to achieve optimal performance on Channels First, such as Convolution, Pooling, etc.
Run Vision Models on Channels Last
The Channels Last related APIs are documented at PyTorch memory format tutorial. Typically, we can convert a 4D tensor from Channels First to Channels Last by:
# convert x to channels last
# suppose x’s shape is (N, C, H, W)
# then x’s stride will be (HWC, 1, WC, C)
x = x.to(memory_format=torch.channels_last)
To run models on Channels Last memory format, simply need to convert input and model to Channels Last and then you are ready to go. The following is a minimal example showing how to run ResNet50 with TorchVision on Channels Last memory format:
import torch
from torchvision.models import resnet50
N, C, H, W = 1, 3, 224, 224
x = torch.rand(N, C, H, W)
model = resnet50()
model.eval()
# convert input and model to channels last
x = x.to(memory_format=torch.channels_last)
model = model.to(memory_format=torch.channels_last)
model(x)
The Channels Last optimization is implemented at native kernel level, which means you may apply other functionalities such as torch.fx and torch script together with Channels Last as well.
Performance Gains
We benchmarked inference performance of TorchVision models on Intel® Xeon® Platinum 8380 CPU @ 2.3 GHz, single instance per socket (batch size = 2 x number of physical cores). Results show that Channels Last has 1.3x to 1.8x performance gain over Channels First.
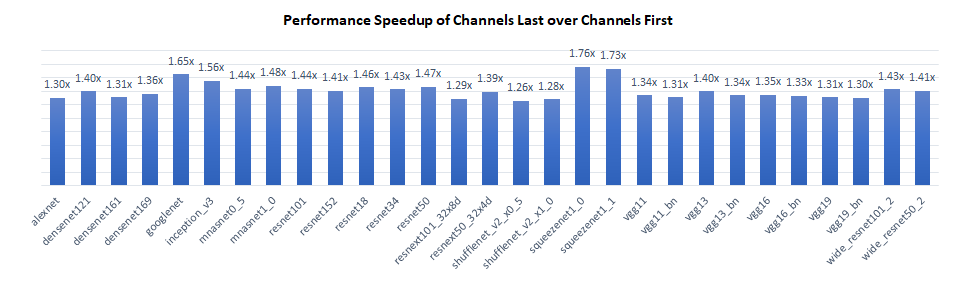
The performance gain primarily comes from two aspects:
- For Convolution layers, Channels Last saved the memory format conversion to blocked format for activations, which improves the overall computation efficiency.
- For Pooling and Upsampling layers, Channels Last can use vectorized logic along the most inner dimension, e.g., “C”, while Channels First can’t.
For memory format non aware layers, Channels Last and Channels First has the same performance.
Conclusion & Future Work
In this blog we introduced fundamental concepts of Channels Last and demonstrated the performance benefits of CPU using Channels Last on vision models. The current work is limited to 2D models at the current stage, and we will extend the optimization effort to 3D models in near future!
Acknowledgement
The results presented in this blog is a joint effort of Meta and Intel PyTorch team. Special thanks to Vitaly Fedyunin and Wei Wei from Meta who spent precious time and gave substantial assistance! Together we made one more step on the path of improving the PyTorch CPU eco system.