


Note
Click here to download the full example code
Accelerated video encoding with NVENC¶
Author: Moto Hira
This tutorial shows how to use NVIDIA’s hardware video encoder (NVENC) with TorchAudio, and how it improves the performance of video encoding.
Note
This tutorial requires FFmpeg libraries compiled with HW acceleration enabled.
Please refer to Enabling GPU video decoder/encoder for how to build FFmpeg with HW acceleration.
Note
Most modern GPUs have both HW decoder and encoder, but some highend GPUs like A100 and H100 do not have HW encoder. Please refer to the following for the availability and format coverage. https://developer.nvidia.com/video-encode-and-decode-gpu-support-matrix-new
Attempting to use HW encoder on these GPUs fails with an error
message like Generic error in an external library.
You can enable debug log with
torchaudio.utils.ffmpeg_utils.set_log_level() to see more
detailed error messages issued along the way.
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
import io
import time
import matplotlib.pyplot as plt
from IPython.display import Video
from torchaudio.io import StreamReader, StreamWriter
2.1.1
2.1.2
Check the prerequisites¶
First, we check that TorchAudio correctly detects FFmpeg libraries that support HW decoder/encoder.
from torchaudio.utils import ffmpeg_utils
FFmpeg Library versions:
libavcodec: 60.3.100
libavdevice: 60.1.100
libavfilter: 9.3.100
libavformat: 60.3.100
libavutil: 58.2.100
Available NVENC Encoders:
- av1_nvenc
- h264_nvenc
- hevc_nvenc
print("Avaialbe GPU:")
print(torch.cuda.get_device_properties(0))
Avaialbe GPU:
_CudaDeviceProperties(name='NVIDIA A10G', major=8, minor=6, total_memory=22515MB, multi_processor_count=80)
We use the following helper function to generate test frame data. For the detail of synthetic video generation please refer to StreamReader Advanced Usage.
def get_data(height, width, format="yuv444p", frame_rate=30000 / 1001, duration=4):
src = f"testsrc2=rate={frame_rate}:size={width}x{height}:duration={duration}"
s = StreamReader(src=src, format="lavfi")
s.add_basic_video_stream(-1, format=format)
s.process_all_packets()
(video,) = s.pop_chunks()
return video
Encoding videos with NVENC¶
To use HW video encoder, you need to specify the HW encoder when
defining the output video stream by providing encoder option to
add_video_stream().
pict_config = {
"height": 360,
"width": 640,
"frame_rate": 30000 / 1001,
"format": "yuv444p",
}
frame_data = get_data(**pict_config)
w = StreamWriter(io.BytesIO(), format="mp4")
w.add_video_stream(**pict_config, encoder="h264_nvenc", encoder_format="yuv444p")
with w.open():
w.write_video_chunk(0, frame_data)
Similar to the HW decoder, by default, the encoder expects the frame
data to be on CPU memory. To send data from CUDA memory, you need to
specify hw_accel option.
buffer = io.BytesIO()
w = StreamWriter(buffer, format="mp4")
w.add_video_stream(**pict_config, encoder="h264_nvenc", encoder_format="yuv444p", hw_accel="cuda:0")
with w.open():
w.write_video_chunk(0, frame_data.to(torch.device("cuda:0")))
buffer.seek(0)
video_cuda = buffer.read()
Video(video_cuda, embed=True, mimetype="video/mp4")
Benchmark NVENC with StreamWriter¶
Now we compare the performance of software encoder and hardware encoder.
Similar to the benchmark in NVDEC, we process the videos of different resolution, and measure the time it takes to encode them.
We also measure the size of resulting video file.
The following function encodes the given frames and measure the time it takes to encode and the size of the resulting video data.
def test_encode(data, encoder, width, height, hw_accel=None, **config):
assert data.is_cuda
buffer = io.BytesIO()
s = StreamWriter(buffer, format="mp4")
s.add_video_stream(encoder=encoder, width=width, height=height, hw_accel=hw_accel, **config)
with s.open():
t0 = time.monotonic()
if hw_accel is None:
data = data.to("cpu")
s.write_video_chunk(0, data)
elapsed = time.monotonic() - t0
size = buffer.tell()
fps = len(data) / elapsed
print(f" - Processed {len(data)} frames in {elapsed:.2f} seconds. ({fps:.2f} fps)")
print(f" - Encoded data size: {size} bytes")
return elapsed, size
We conduct the tests for the following configurations
Software encoder with the number of threads 1, 4, 8
Hardware encoder with and without
hw_acceloption.
def run_tests(height, width, duration=4):
# Generate the test data
print(f"Testing resolution: {width}x{height}")
pict_config = {
"height": height,
"width": width,
"frame_rate": 30000 / 1001,
"format": "yuv444p",
}
data = get_data(**pict_config, duration=duration)
data = data.to(torch.device("cuda:0"))
times = []
sizes = []
# Test software encoding
encoder_config = {
"encoder": "libx264",
"encoder_format": "yuv444p",
}
for i, num_threads in enumerate([1, 4, 8]):
print(f"* Software Encoder (num_threads={num_threads})")
time_, size = test_encode(
data,
encoder_option={"threads": str(num_threads)},
**pict_config,
**encoder_config,
)
times.append(time_)
if i == 0:
sizes.append(size)
# Test hardware encoding
encoder_config = {
"encoder": "h264_nvenc",
"encoder_format": "yuv444p",
"encoder_option": {"gpu": "0"},
}
for i, hw_accel in enumerate([None, "cuda"]):
print(f"* Hardware Encoder {'(CUDA frames)' if hw_accel else ''}")
time_, size = test_encode(
data,
**pict_config,
**encoder_config,
hw_accel=hw_accel,
)
times.append(time_)
if i == 0:
sizes.append(size)
return times, sizes
And we change the resolution of videos to see how these measurement change.
360P¶
Testing resolution: 640x360
* Software Encoder (num_threads=1)
- Processed 120 frames in 0.65 seconds. (183.45 fps)
- Encoded data size: 381331 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 0.23 seconds. (533.18 fps)
- Encoded data size: 381307 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 0.19 seconds. (643.00 fps)
- Encoded data size: 390689 bytes
* Hardware Encoder
- Processed 120 frames in 0.05 seconds. (2271.43 fps)
- Encoded data size: 1262979 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.05 seconds. (2608.24 fps)
- Encoded data size: 1262979 bytes
720P¶
Testing resolution: 1280x720
* Software Encoder (num_threads=1)
- Processed 120 frames in 2.22 seconds. (53.97 fps)
- Encoded data size: 1335451 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 0.80 seconds. (149.30 fps)
- Encoded data size: 1336418 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 0.66 seconds. (181.30 fps)
- Encoded data size: 1344063 bytes
* Hardware Encoder
- Processed 120 frames in 0.25 seconds. (474.10 fps)
- Encoded data size: 1358969 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.15 seconds. (803.62 fps)
- Encoded data size: 1358969 bytes
1080P¶
Testing resolution: 1920x1080
* Software Encoder (num_threads=1)
- Processed 120 frames in 4.60 seconds. (26.09 fps)
- Encoded data size: 2678241 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 1.70 seconds. (70.71 fps)
- Encoded data size: 2682028 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 1.53 seconds. (78.47 fps)
- Encoded data size: 2685086 bytes
* Hardware Encoder
- Processed 120 frames in 0.56 seconds. (215.88 fps)
- Encoded data size: 1705900 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.32 seconds. (371.31 fps)
- Encoded data size: 1705900 bytes
Now we plot the result.
def plot():
fig, axes = plt.subplots(2, 1, sharex=True, figsize=[9.6, 7.2])
for items in zip(time_360, time_720, time_1080, "ov^X+"):
axes[0].plot(items[:-1], marker=items[-1])
axes[0].grid(axis="both")
axes[0].set_xticks([0, 1, 2], ["360p", "720p", "1080p"], visible=True)
axes[0].tick_params(labeltop=False)
axes[0].legend(
[
"Software Encoding (threads=1)",
"Software Encoding (threads=4)",
"Software Encoding (threads=8)",
"Hardware Encoding (CPU Tensor)",
"Hardware Encoding (CUDA Tensor)",
]
)
axes[0].set_title("Time to encode videos with different resolutions")
axes[0].set_ylabel("Time [s]")
for items in zip(size_360, size_720, size_1080, "v^"):
axes[1].plot(items[:-1], marker=items[-1])
axes[1].grid(axis="both")
axes[1].set_xticks([0, 1, 2], ["360p", "720p", "1080p"])
axes[1].set_ylabel("The encoded size [bytes]")
axes[1].set_title("The size of encoded videos")
axes[1].legend(
[
"Software Encoding",
"Hardware Encoding",
]
)
plt.tight_layout()
plot()
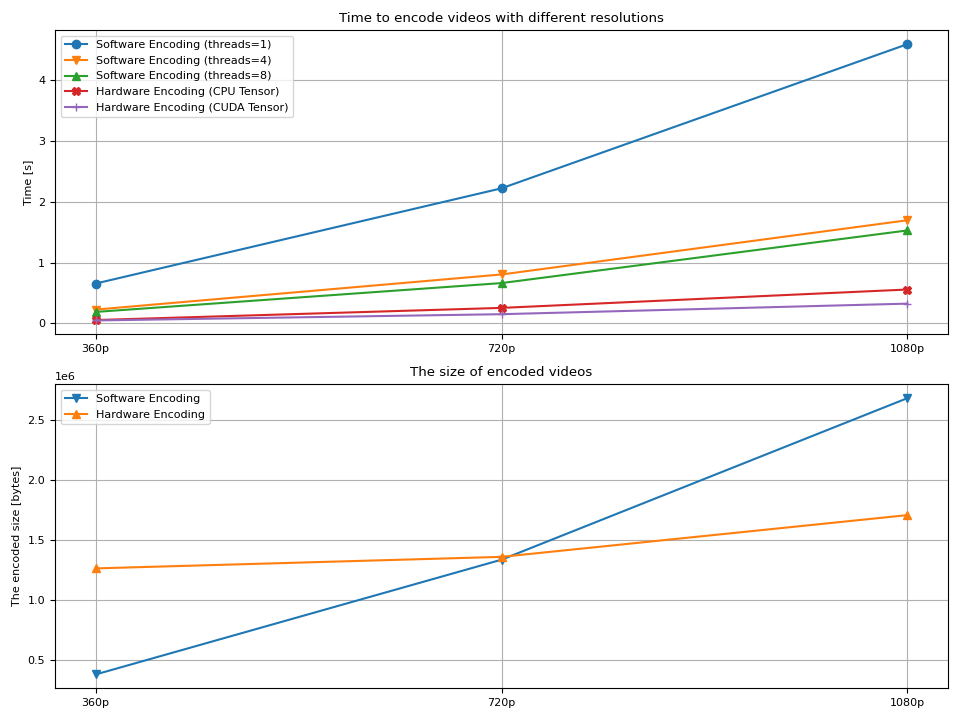
Result¶
We observe couple of things;
The time to encode video grows as the resolution becomes larger.
In the case of software encoding, increasing the number of threads helps reduce the decoding time.
The gain from extra threads diminishes around 8.
Hardware encoding is faster than software encoding in general.
Using
hw_acceldoes not improve the speed of encoding itself as much.The size of the resulting videos grow as the resolution becomes larger.
Hardware encoder produces smaller video file at larger resolution.
The last point is somewhat strange to the author (who is not an expert in production of videos.) It is often said that hardware decoders produce larger video compared to software encoders. Some says that software encoders allow fine-grained control over encoding configuration, so the resulting video is more optimal. Meanwhile, hardware encoders are optimized for performance, thus does not provide as much control over quality and binary size.
Quality Spotcheck¶
So, how are the quality of videos produced with hardware encoders? A quick spot check of high resolution videos uncovers that they have more noticeable artifacts on higher resolution. Which might be an explanation of the smaller binary size. (meaning, it is not allocating enough bits to produce quality output.)
The following images are raw frames of videos encoded with hardware encoders.
360P¶

720P¶

1080P¶

We can see that there are more artifacts at higher resolution, which are noticeable.
Perhaps one might be able to reduce these using encoder_options
arguments.
We did not try, but if you try that and find a better quality
setting, feel free to let us know. ;)
Tag: torchaudio.io
Total running time of the script: ( 0 minutes 21.560 seconds)
