Audio-Visual Speech Recognition (AV-ASR, or AVSR) is the task of transcribing text from audio and visual streams, which has recently attracted a lot of research attention due to its robustness to noise. The vast majority of work to date has focused on developing AV-ASR models for non-streaming recognition; studies on streaming AV-ASR are very limited.
We have developed a compact real-time speech recognition system based on TorchAudio, a library for audio and signal processing with PyTorch. It can run locally on a laptop with high accuracy without accessing the cloud. Today, we are releasing the real-time AV-ASR recipe under a permissive open license (BSD-2-Clause license), enabling a broad set of applications and fostering further research on audio-visual models for speech recognition.
This work is part of our approach to AV-ASR research. A promising aspect of this approach is its ability to automatically annotate large-scale audio-visual datasets, which enables the training of more accurate and robust speech recognition systems. Furthermore, this technology has the potential to run on smart devices since it achieves the latency and memory efficiency that such devices require for inference.
In the future, speech recognition systems are expected to power applications in numerous domains. One of the primary applications of AV-ASR is to enhance the performance of ASR in noisy environments. Since visual streams are not affected by acoustic noise, integrating them into an audio-visual speech recognition model can compensate for the performance drop of ASR models. Our AV-ASR system has the potential to serve multiple purposes beyond speech recognition, such as text summarization, translation and even text-to-speech conversion. Moreover, the exclusive use of VSR can be useful in certain scenarios, e.g. where speaking is not allowed, in meetings, and where privacy in public conversations is desired.
AV-ASR
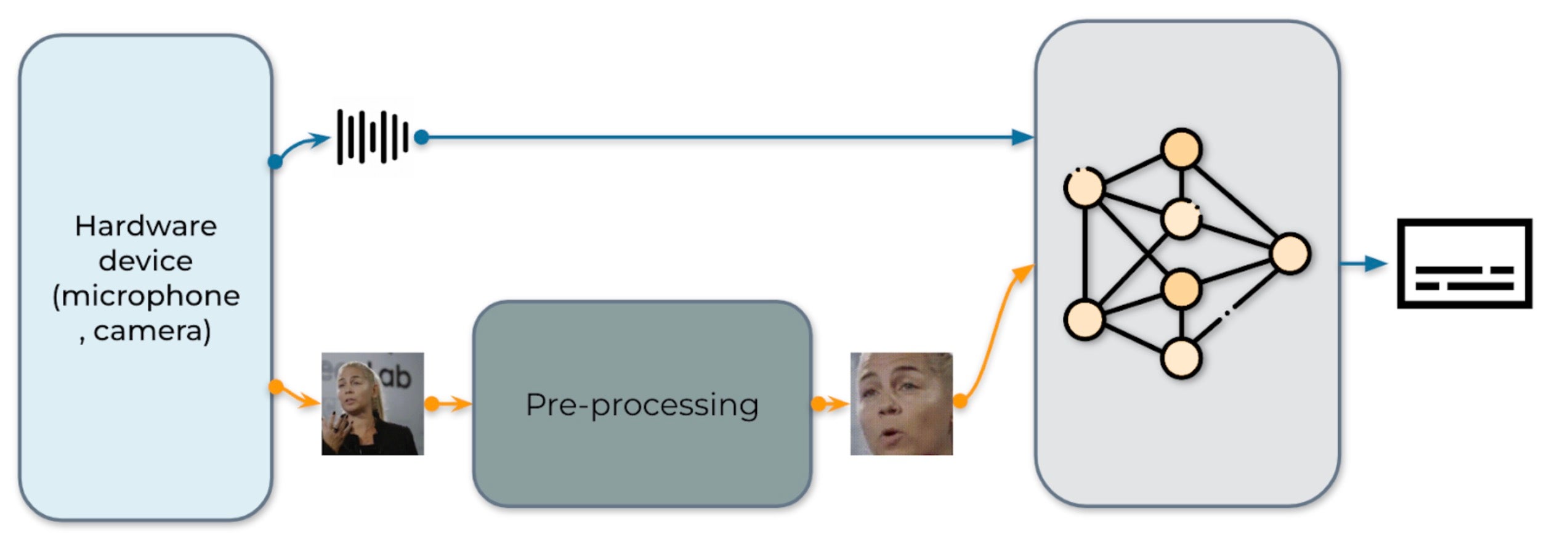
Fig. 1: The pipeline for audio-visual speech recognition system
Our real-time AV-ASR system is presented in Fig. 1. It consists of three components, a data collection module, a pre-processing module and an end-to-end model. The data collection module comprises hardware devices, such as a microphone and camera. Its role is to collect information from the real world. Once the information is collected, the pre-processing module location and crop out face. Next, we feed the raw audio stream and the pre-processed video stream into our end-to-end model for inference.
Data collection
We use torchaudio.io.StreamReader to capture audio/video from streaming device input, e.g. microphone and camera on laptop. Once the raw video and audio streams are collected, the pre-processing module locates and crops faces. It should be noted that data is immediately deleted during the streaming process.
Pre-processing
Before feeding the raw stream into our model, each video sequence has to undergo a specific pre-processing procedure. This involves three critical steps. The first step is to perform face detection. Following that, each individual frame is aligned to a referenced frame, commonly known as the mean face, in order to normalize rotation and size differences across frames. The final step in the pre-processing module is to crop the face region from the aligned face image. We would like to clearly note that our model is fed with raw audio waveforms and pixels of the face, without any further preprocessing like face parsing or landmark detection. An example of the pre-processing procedure is illustrated in Table 1.
 |  |  |  |
| 0. Original | 1. Detection | 2. Alignment | 3. Crop |
Table 1: Preprocessing pipeline.
Model
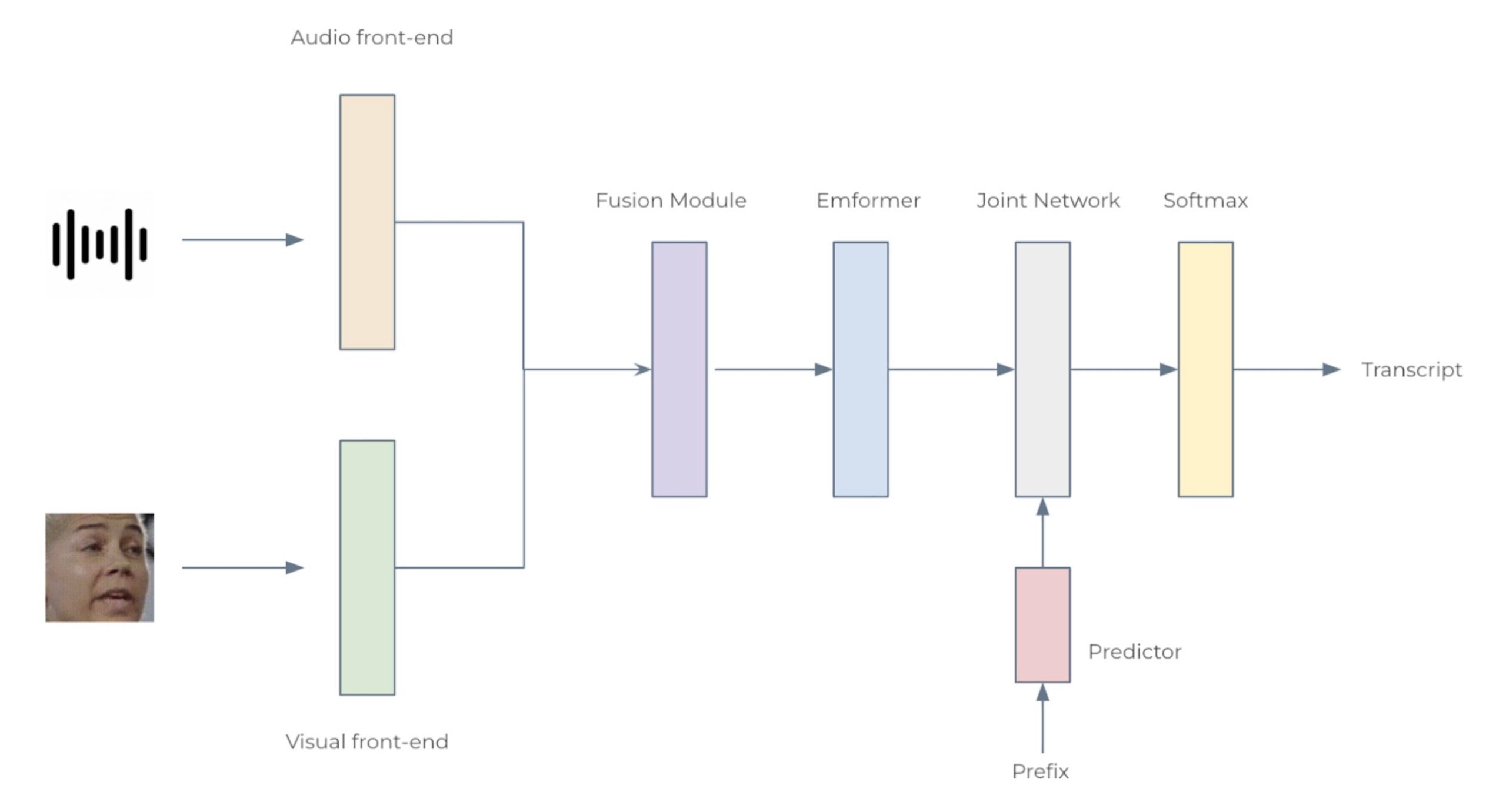
Fig. 2: The architecture for the audio-visual speech recognition system
We consider two configurations: Small with 12 Emformer blocks and Large with 28, with 34.9M and 383.3M parameters, respectively. Each AV-ASR model composes front-end encoders, a fusion module, an Emformer encoder, and a transducer model. To be specific, we use convolutional frontends to extract features from raw audio waveforms and facial images. The features are concatenated to form 1024-d features, which are then passed through a two-layer multi-layer perceptron and an Emformer transducer model. The entire network is trained using RNN-T loss. The architecture of the proposed AV-ASR model is illustrated in Fig. 2.
Analysis
Datasets. We follow Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels to use publicly available audio-visual datasets including LRS3, VoxCeleb2 and AVSpeech for training. We do not use mouth ROIs or facial landmarks or attributes during both training and testing stages.
Comparisons with the state-of-the-art. Non-streaming evaluation results on LRS3 are presented in Table 2. Our audio-visual model with an algorithmic latency of 800 ms (160ms+1280msx0.5) yields a WER of 1.3%, which is on par with those achieved by state-of-the-art offline models such as AV-HuBERT, RAVEn, and Auto-AVSR.
| Method | Total Hours | WER (%) |
| ViT3D-CM | 90, 000 | 1.6 |
| AV-HuBERT | 1, 759 | 1.4 |
| RAVEn | 1, 759 | 1.4 |
| AutoAVSR | 3, 448 | 0.9 |
| Ours | 3, 068 | 1.3 |
Table 2: Non-streaming evaluation results for audio-visual models on the LRS3 dataset.
Noisy experiments. During training, 16 different noise types are randomly injected to audio waveforms, including 13 types from Demand database, ‘DLIVING’,’DKITCHEN’, ‘OMEETING’, ‘OOFFICE’, ‘PCAFETER’, ‘PRESTO’, ‘PSTATION’, ‘STRAFFIC’, ‘SPSQUARE’, ‘SCAFE’, ‘TMETRO’, ‘TBUS’ and ‘TCAR’, two more types of noise from speech commands database, white and pink and one more type of noise from NOISEX-92 database, babble noise. SNR levels in the range of [clean, 7.5dB, 2.5dB, -2.5dB, -7.5dB] are selected from with a uniform distribution. Results of ASR and AV-ASR models, when tested with babble noise, are shown in Table 3. With increasing noise level, the performance advantage of our audio-visual model over our audio-only model grows, indicating that incorporating visual data improves noise robustness.
| Type | ∞ | 10dB | 5dB | 0dB | -5dB | -10dB |
| A | 1.6 | 1.8 | 3.2 | 10.9 | 27.9 | 55.5 |
| A+V | 1.6 | 1.7 | 2.1 | 6.2 | 11.7 | 27.6 |
Table 3: Streaming evaluation WER (%) results at various signal-to-noise ratios for our audio-only (A) and audio-visual (A+V) models on the LRS3 dataset under 0.80-second latency constraints.
Real-time factor. The real-time factor (RTF) is an important measure of a system’s ability to process real-time tasks efficiently. An RTF value of less than 1 indicates that the system meets real-time requirements. We measure RTF using a laptop with an Intel® Core™ i7-12700 CPU running at 2.70 GHz and an NVIDIA 3070 GeForce RTX 3070 Ti GPU. To the best of our knowledge, this is the first AV-ASR model that reports RTFs on the LRS3 benchmark. The Small model achieves a WER of 2.6% and an RTF of 0.87 on CPU (Table 4), demonstrating its potential for real-time on-device inference applications.
| Model | Device | Streaming WER [%] | RTF |
| Large | GPU | 1.6 | 0.35 |
| Small | GPU | 2.6 | 0.33 |
| CPU | 0.87 |
Table 4: Impact of AV-ASR model size and device on WER and RTF. Note that the RTF calculation includes the pre-processing step wherein the Ultra-Lightweight Face Detection Slim 320 model is used to generate face bounding boxes.
Learn more about the system from the published works below:
- Shi, Yangyang, Yongqiang Wang, Chunyang Wu, Ching-Feng Yeh, Julian Chan, Frank Zhang, Duc Le, and Mike Seltzer. “Emformer: Efficient memory transformer based acoustic model for low latency streaming speech recognition.” In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6783-6787. IEEE, 2021.
- Ma, Pingchuan, Alexandros Haliassos, Adriana Fernandez-Lopez, Honglie Chen, Stavros Petridis, and Maja Pantic. “Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels.” In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5. IEEE, 2023.